基于paddlex图像分类模型训练(一):图像分类数据集切分:文件夹转化为imagenet训练格式
背景
在使用paddlex GUI训练图像分类时,内部自动对导入的分类文件夹进行细分,本文主要介绍其图像分类数据切分源码,或可作为其他项目储备代码:https://github.com/PaddlePaddle/PaddleX/blob/develop/paddlex/tools/dataset_split/imagenet_split.py
数据集形式
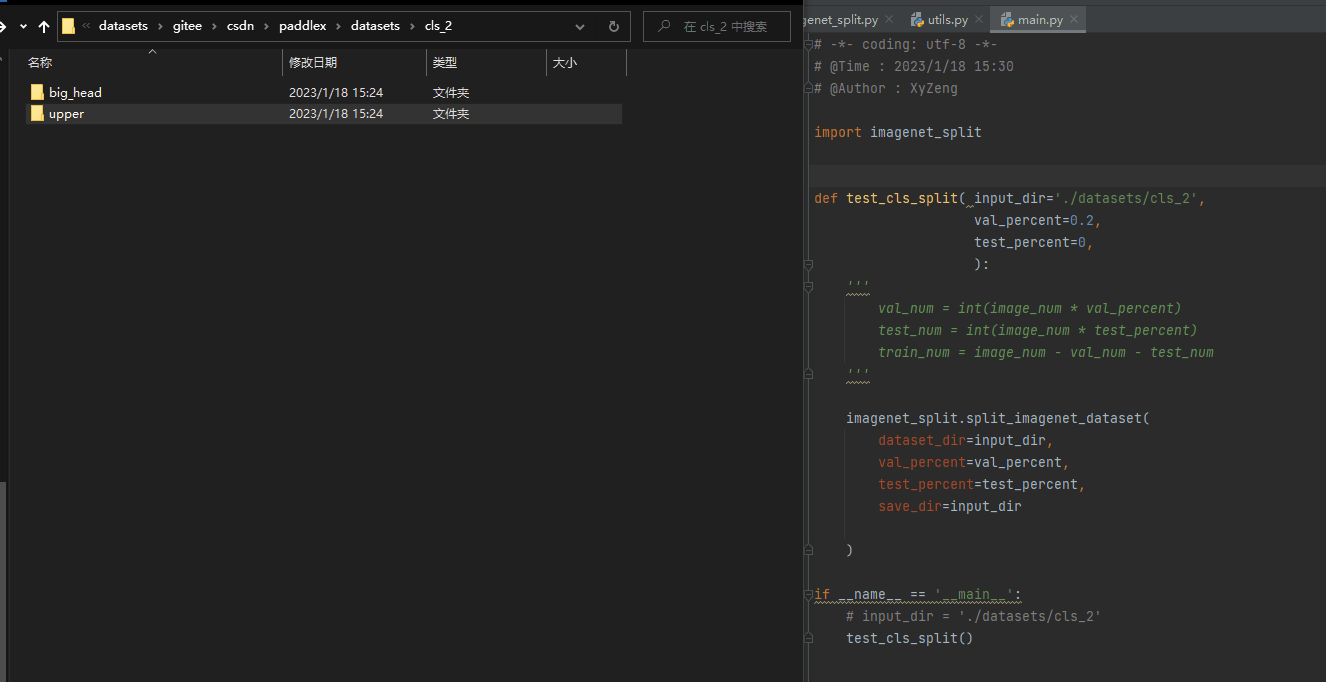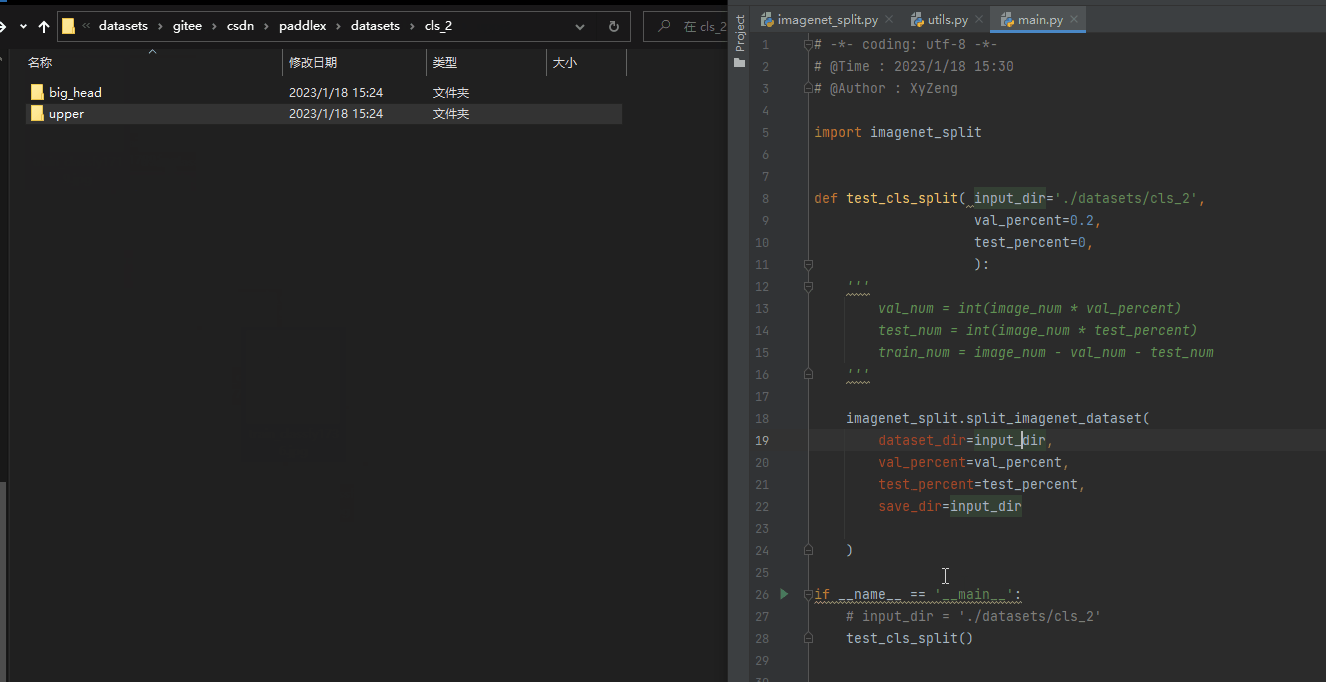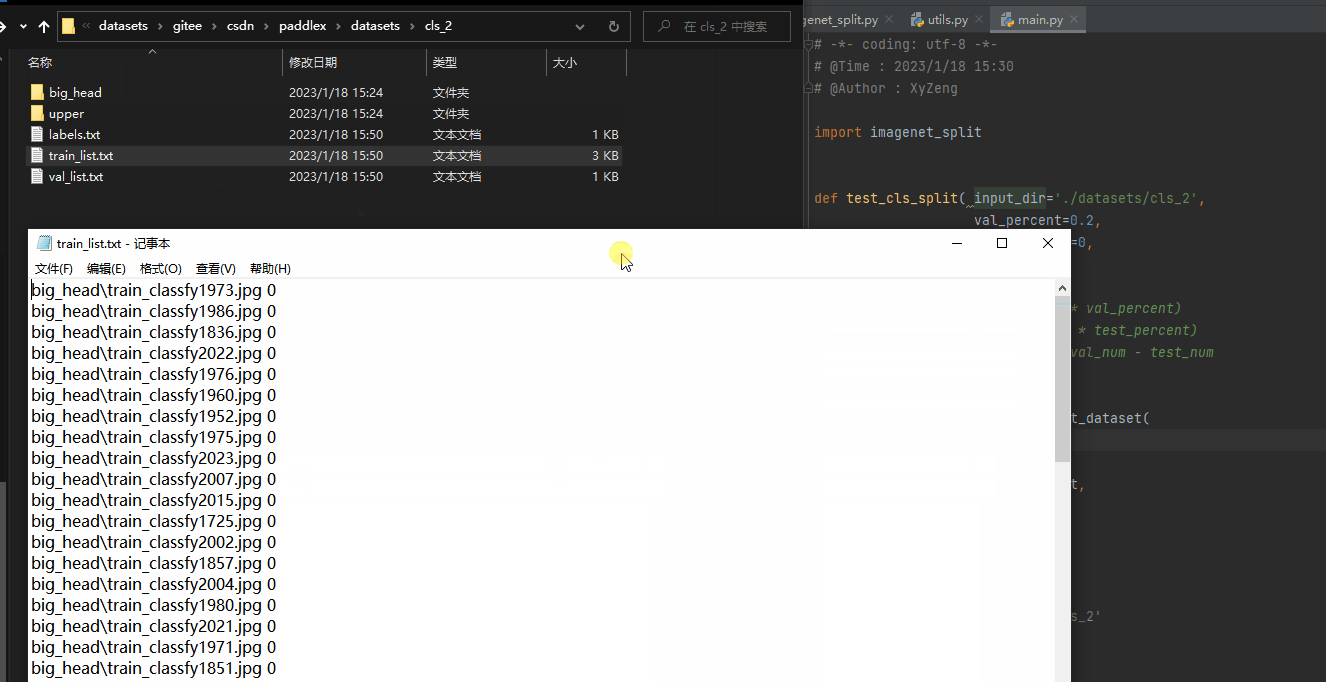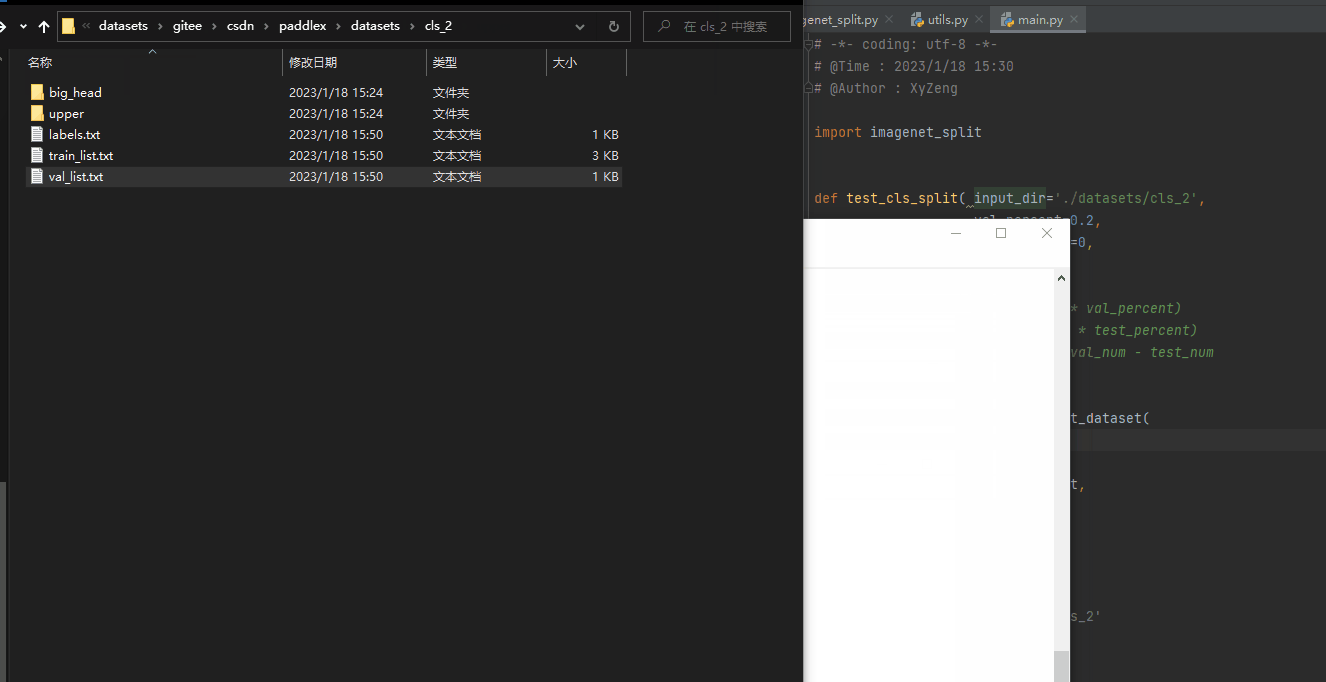
PaddleClas 数据切分说明 使用 txt 格式文件指定训练集和测试集,以 ImageNet1k 数据集为例,其中 train_list.txt 和 val_list.txt 的格式形如:
# 每一行采用"空格"分隔图像路径与标注
# 下面是 train_list.txt 中的格式样例
train/n01440764/n01440764_10026.JPEG 0
...
# 下面是 val_list.txt 中的格式样例
val/ILSVRC2012_val_00000001.JPEG 65
...
切分前:分类好的文件夹
切分后:train_list.txt,text_list.txt,val_list.txt,labels.txt
相关代码 (mian.py,imagenet_split.py, utils.py)
# -*- coding: utf-8 -*-
# @Time : 2023/1/18 15:30
# @Author : XyZeng
import imagenet_split
def test_cls_split( input_dir='./datasets/cls_2',
val_percent=0.2,
test_percent=0,
):
'''
val_num = int(image_num * val_percent)
test_num = int(image_num * test_percent)
train_num = image_num - val_num - test_num
'''
imagenet_split.split_imagenet_dataset(
dataset_dir=input_dir,
val_percent=val_percent,
test_percent=test_percent,
save_dir=input_dir
)
if __name__ == '__main__':
# input_dir = './datasets/cls_2'
test_cls_split()
imagenet_split.py
用于将文件夹整理好的分类图像,转换为可用于训练的txt
import random
from utils import *
def split_imagenet_dataset(dataset_dir, val_percent, test_percent, save_dir):
all_files = list_files(dataset_dir)
label_list = list()
train_image_anno_list = list()
val_image_anno_list = list()
test_image_anno_list = list()
for file in all_files:
if not is_pic(file):
continue
label, image_name = osp.split(file)
if label not in label_list:
label_list.append(label)
label_list = sorted(label_list)
for i in range(len(label_list)):
image_list = list_files(osp.join(dataset_dir, label_list[i]))
image_anno_list = list()
for img in image_list:
image_anno_list.append([osp.join(label_list[i], img), i])
random.shuffle(image_anno_list)
image_num = len(image_anno_list)
val_num = int(image_num * val_percent)
test_num = int(image_num * test_percent)
train_num = image_num - val_num - test_num
train_image_anno_list += image_anno_list[:train_num]
val_image_anno_list += image_anno_list[train_num:train_num + val_num]
test_image_anno_list += image_anno_list[train_num + val_num:]
with open(
osp.join(save_dir, 'train_list.txt'), mode='w',
encoding='utf-8') as f:
for x in train_image_anno_list:
file, label = x
f.write('{} {}\n'.format(file, label))
with open(
osp.join(save_dir, 'val_list.txt'), mode='w',
encoding='utf-8') as f:
for x in val_image_anno_list:
file, label = x
f.write('{} {}\n'.format(file, label))
if len(test_image_anno_list):
with open(
osp.join(save_dir, 'test_list.txt'), mode='w',
encoding='utf-8') as f:
for x in test_image_anno_list:
file, label = x
f.write('{} {}\n'.format(file, label))
# 创建label标签
with open(
osp.join(save_dir, 'labels.txt'), mode='w', encoding='utf-8') as f:
for l in sorted(label_list):
f.write('{}\n'.format(l))
return len(train_image_anno_list), len(val_image_anno_list), len(
test_image_anno_list)
utils.py
后续可以添加自己各种功能函数
import os
import os.path as osp
def is_pic(filename):
""" 判断文件是否为图片格式
Args:
filename: 文件路径
"""
suffixes = {'JPEG', 'jpeg', 'JPG', 'jpg', 'BMP', 'bmp', 'PNG', 'png'}
suffix = filename.strip().split('.')[-1]
if suffix not in suffixes:
return False
return True
def list_files(dirname):
""" 列出目录下所有文件(包括所属的一级子目录下文件)
Args:
dirname: 目录路径
"""
def filter_file(f):
if f.startswith('.'):
return True
return False
all_files = list()
dirs = list()
for f in os.listdir(dirname):
if filter_file(f):
continue
if osp.isdir(osp.join(dirname, f)):
dirs.append(f)
else:
all_files.append(f)
for d in dirs:
for f in os.listdir(osp.join(dirname, d)):
if filter_file(f):
continue
if osp.isdir(osp.join(dirname, d, f)):
continue
all_files.append(osp.join(d, f))
return all_files