Cassandra入门教程
文章目录
- 一、数据存储方式和NoSQL
- 1.1 数据存储方式
- 1.2 NoSQL概述
- 1.3 NoSQL的分类
- 二、Cassandra的介绍
- 2.1、Cassandra概述
- 2.1.1 来自百科的介绍
- 2.1.2 Cassandra的Logo
- 2.2、Cassandra特点
- 2.3、Cassandra使用场景
- 2.3.1 特征
- 2.3.2 场景举例
- 三、Cassandra下载、安装、访问
- 3.1 Cassandra 3.11.4下载
- 3.2 Windows下安装
- 3.2.1 解压文件
- 3.2.2 配置环境变量
- 3.2.3 配置Cassandra
- 3.2.4 启动Cassandra
- 3.2.5 Cassandra客户端连接Cassandra服务器
- 3.2.6 Cassandra的端口
- 3.2.7 Cassandra.yaml内容
- 四、Cassandra的基本概念
- 4.1 数据模型
- 4.1.1 列(Column)
- 4.1.2 列族( Column Family)
- 4.1.3 键空间 (KeySpace)
- 4.1.4 副本 (Replication)
- 4.1.5 节点(Node)
- 4.1.6 数据中心(DateCenter)
- 4.1.7 集群(Cluster)
- 4.1.8 超级列
- 4.2 数据类型
- 4.2.1 数值类型
- 4.2.2 文本类型
- 4.2.3 时间类型
- 4.2.4 标识符类型
- 4.2.5 集合类型
- 4.2.6 其他基本类型
- 4.2.7 用户自定义类型
- 4.3 CQL Shell 客户端
- 4.3.1 启动cqlsh
- 4.3.2 cqlsh的基本命令
- 4.4 CQL-Cassandra查询语言
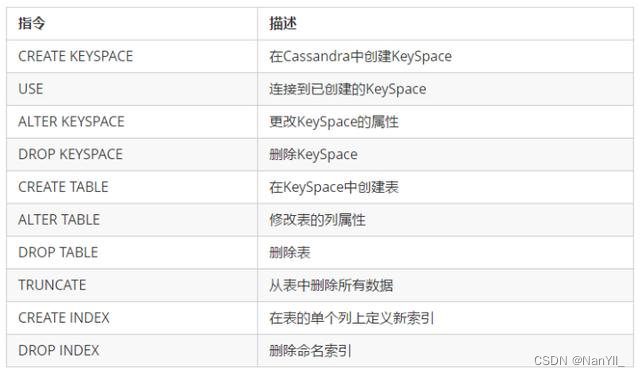
- 4.4.1 数据定义命令
- 4.4.2 数据操作指令
- 4.4.3 查询指令
- 五、Cassandra的基本操作
- 5.1 操作键空间
- 5.1.1 创建Keyspace
- 5.1.2连接Keyspace
- 5.1.3修改键空间
- 5.1.4 删除键空间
- 5.2 操作表、索引
- 5.2.1 查看键空间下所有表
- 5.2.2 创建表
- 5.2.3 cassandra的索引(KEY)
- 5.2.4 修改表结构
- 5.2.5 删除表
- 5.2.6 清空表
- 5.2.7 创建索引
- 5.2.8 删除索引
- 5.3 查询数据
- 5.3.1 查询数据
- 5.3.2 查询时使用索引
- 5.3.3 查询时排序
- 5.4 分页查询
- 5.5 更新列数据
- 5.5.1 更新简单数据
- 5.5.2 更新set类型数据
- 5.5.3 更新list类型数据
- 5.5.4 更新map类型数据
- 5.6 删除行
- 5.7 批量操作
一、数据存储方式和NoSQL
1.1 数据存储方式
互联网时代各种数据存储方式层出不穷,有传统的关系性数据库如:MySQL、Oracle等,;有全文检索框架如:ElasticSearch、Solr;有NoSQL如:Cassandra、Redis
这些存储方式的特点:
- 关系型数据库:支持事务,二级索引,SQL语句,支持主从架。
- 全文检索:分布式,p2p架构,不支持事务,采用倒排索引提供全文检索。
- NoSQL:一般基于内存,支持分布式,面向列,不支持SQL。
1.2 NoSQL概述
NoSQL,泛指非关系型的数据库,NoSQL去掉关系数据库的关系型特性,数据之间无关系,非常容易扩展。
-
易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展,在架构的层面上带来了可扩展的能力。
-
大数据量,高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下。一般MySQL使用Query Cache。NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说性能就要高很多。 -
灵活的数据模型
NoSQL无须事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。 -
高可用
NoSQL在不太影响性能的情况,就可以方便地实现高可用的架构。比如Cassandra、HBase模型,通过复制模型也能实现高可用。
1.3 NoSQL的分类
-
键值(Key-Value)存储数据库
这一类数据库主要使用[哈希表],这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型的优势在于简单、易部署。代表为: Redis
-
列存储数据库
这类数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。这些列是由列家组来安排的。如:Cassandra, HBase
-
图形(Graph)数据库
图形结构的数据库同其他行列以及关系型数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。如:Neo4j
二、Cassandra的介绍
2.1、Cassandra概述
2.1.1 来自百科的介绍
Cassandra是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,集GoogleBigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身Facebook于2008将 Cassandra 开源,此后,由于Cassandra良好的可扩展性,被Digg、Twitter等知名Web 2.0网站所采纳,成为了一种流行的分布式结构化数据存储方案。
代码如下(示例):
2.1.2 Cassandra的Logo

Cassandra的名称来源于希腊神话,是特洛伊的一位悲剧性的女先知的名字,因此项目的Logo是一只放光的眼睛。
2.2、Cassandra特点
- 弹性可扩展性 - Cassandra是高度可扩展的; 它允许添加更多的硬件以适应更多的客户和更多的数据根据要求。
- 始终基于架构 - Cassandra没有单点故障,它可以连续用于不能承担故障的关键业务应用程序。
- 快速线性性能 - Cassandra是线性可扩展性的,即它为你增加集群中的节点数量增加你的吞吐量。因此,保持一个快速的响应时间。
- 灵活的数据存储 - Cassandra适应所有可能的数据格式,包括:结构化,半结构化和非结构化。它可以根据您的需要动态地适应变化的数据结构。
- 便捷的数据分发 - Cassandra通过在多个数据中心之间复制数据,可以灵活地在需要时分发数据。
事务支持 - Cassandra支持属性,如原子性,一致性,隔离和持久性(ACID)。 - 快速写入 - Cassandra被设计为在廉价的商品硬件上运行。 它执行快速写入,并可以存储数百TB的数据,而不牺牲读取效率。
2.3、Cassandra使用场景
2.3.1 特征
- 数据写入操作密集
- 数据修改操作很少
- 通过主键查询
- 需要对数据进行分区存储
2.3.2 场景举例
- 存储日志型数据
- 类似物联网的海量数据
- 对数据进行跟踪
三、Cassandra下载、安装、访问
3.1 Cassandra 3.11.4下载
打开官网,选择下载频道https://cassandra.apache.org/download/
3.2 Windows下安装
注意:Cassandra使用JAVA语言开发,首先保证当前机器中已经安装JDK
3.2.1 解压文件
找一个不包含中文的目录,把刚才下载的安装文件复制过去。然后解压到当前文件夹
D:\software\cassandra-3.11.14
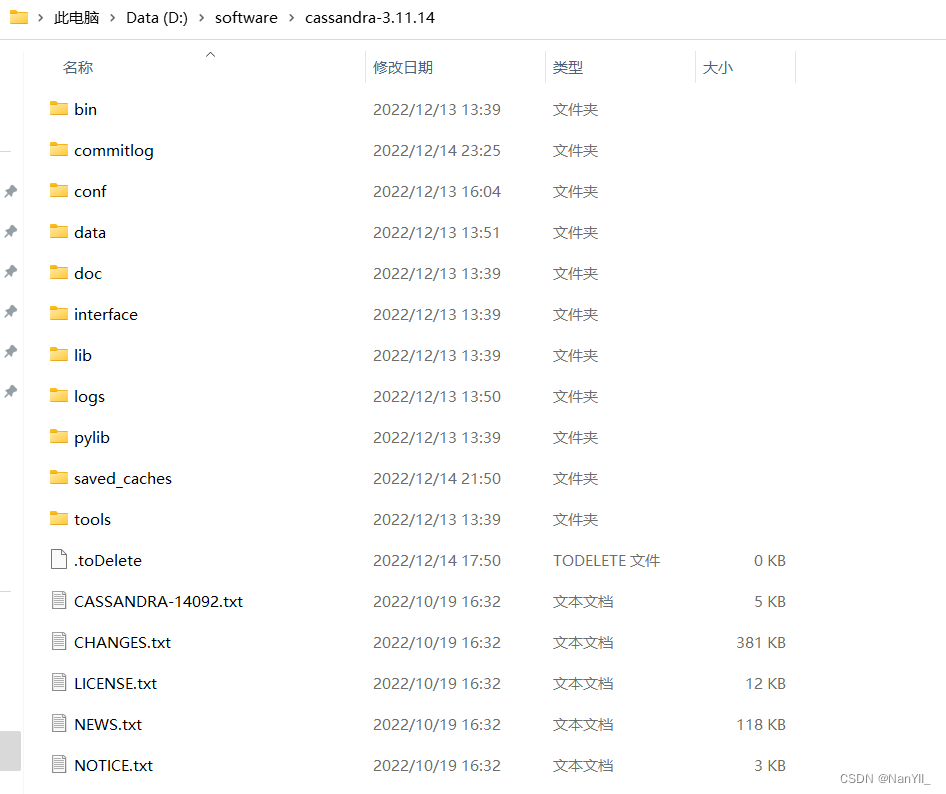
3.2.2 配置环境变量
- 新建CASSANDRA_HOME
在环境变量中新建一个CASSANDRA_HOME变量,值为:D:\software\cassandra-3.11.14
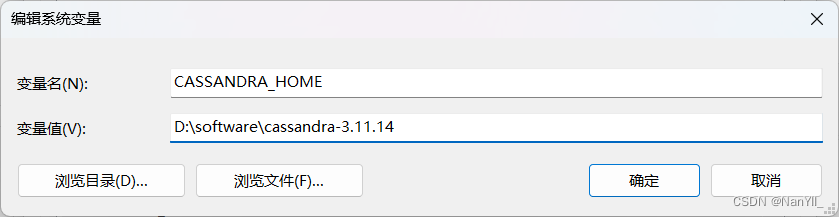
- 在Path中添加
在Path环境变量中在末尾添加:%CASSANDRA_HOME%\bin
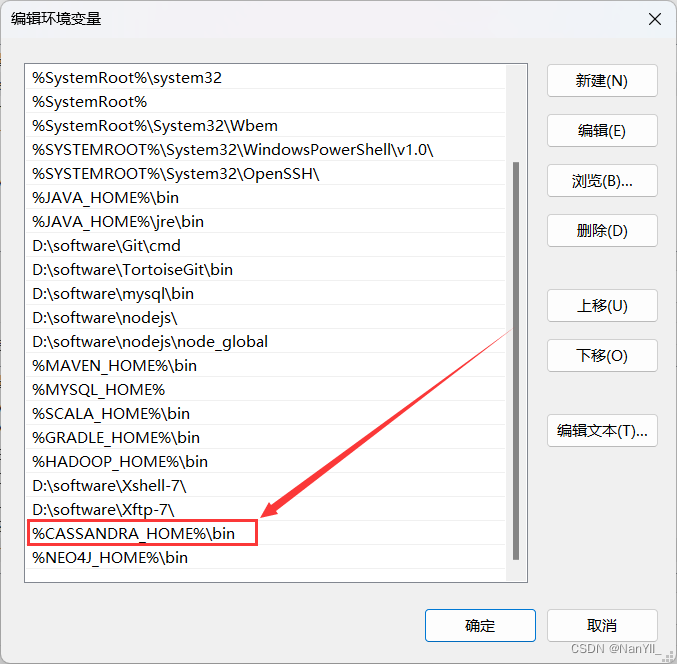
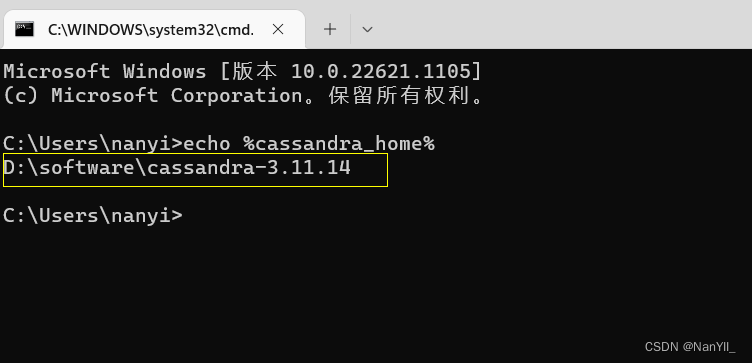
- 验证环境变量
快捷键 Win+R 打开cmd窗口可以查看是否设置成功。输入echo %cassandra_home%,显示如下内容说环境变量值设置成功
3.2.3 配置Cassandra
1)cassandra的数据分为3类,这3类数据的存储位置都可以在配置文件中修改
-
data目录:
用于存储真正的数据文件,即后面将要讲到的SSTable文件。如果服务器有多个磁盘,可以指定多个目录,每一个目录都在不同的磁盘中。这样Cassandra就可以利用更多的硬盘空间。
在data目录下,Cassandra 会将每一个 Keyspace 中的数据存储在不同的文件目录下,并且 Keyspace 文件目录的名称与 Keyspace 名称相同。
假设有两个 Keyspace,分别为 ks1 和 ks2,但在 data目录下,将看到3个不同的目录:ks1,ks2和 system。其中 ks1 和 ks2 用于存储系统定义的两个 Keyspace 的数据,另外一个 system 目录是 Cassandra 系统默认的一个 Keyspace,叫做 system,它用来存储 Cassandra 系统的相关元数据信息以及 HINT 数据信息。
-
commitlog目录:
用于存储未写人SSTable中的数据,每次Cassandra系统中有数据写入,都会先将数据记录在该日志文件中,以保证Cassandra在任何情况下宕机都不会丢失数据。如果服务器有足够多的磁盘,可以将本目录设置在一个与data目录和cache目录不同的磁盘中,以提升读写性能。
-
cache目录:
用于存储系统中的缓存数据。可以在cassandra. yaml文件中定义Column Family的属性中定义与缓存相关的信息,如缓存数据的大小(对应配置文件中的keys_cached和rOws_ cached)、 持久化缓存数据的时间间隔(对应配置文件中的row cache_save_ period in. seconds 和key. cache save period in seconds)等。当Cassandra系统重启的时候,会从该目录下加载缓存数据。如果服务器有足够多的磁盘空间,可以将本目录设置在一个与data目录和commitlog目录不同的磁盘中,以提升读写性能。
2)创建三个目录文件
① 新建数据存储目录,data目录
- D:\software\cassandra-3.11.14 目录中新建一个data目录;
- 找到D:\software\cassandra-3.11.14\conf目录下的cassandra.yaml配置data目录;
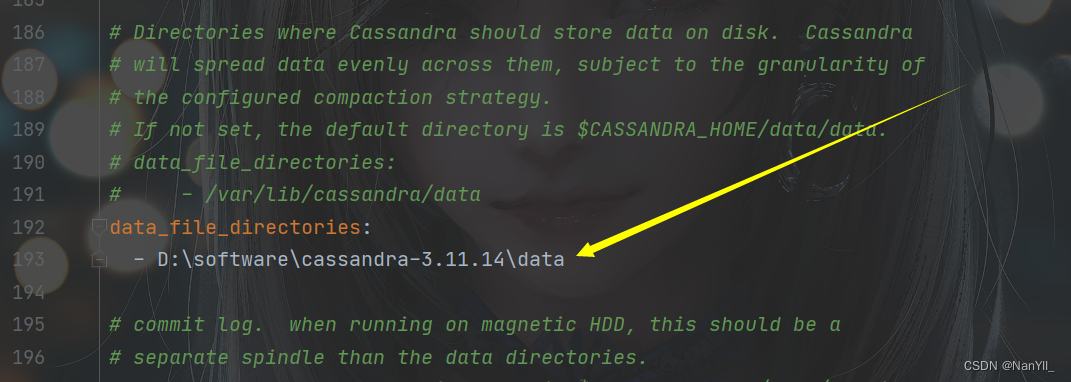
data_file_directories:
- D:\software\cassandra-3.11.14\data
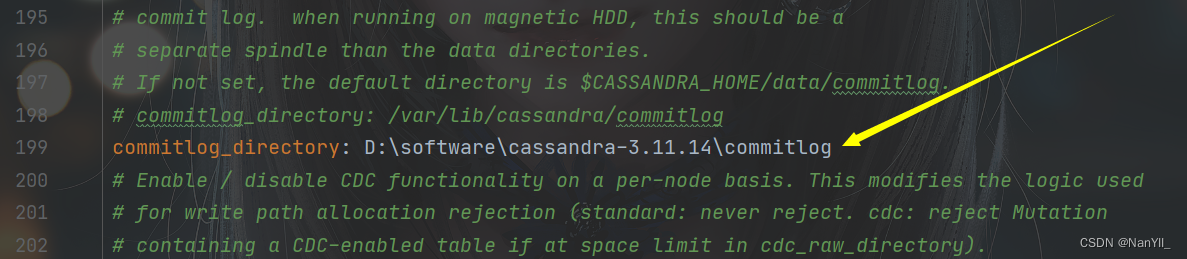
② 新建日志目录,commitlog目录
commitlog_directory: D:\software\cassandra-3.11.14\commitlog
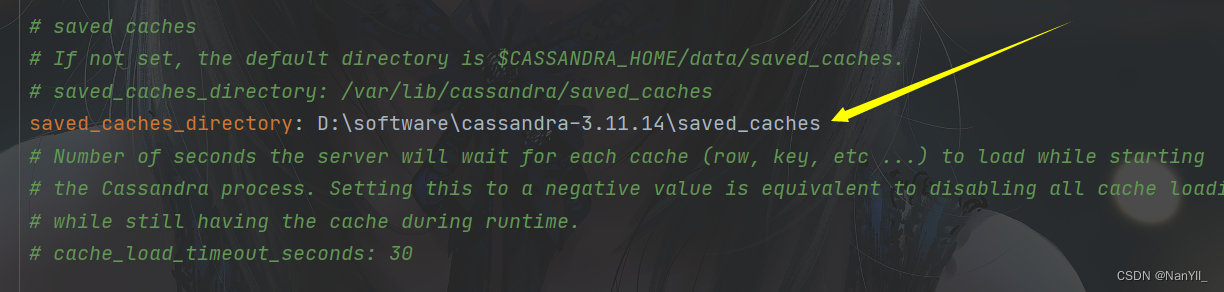
③ 新建缓存目录,saved_caches目录
saved_caches_directory: D:\software\cassandra-3.11.14\saved_caches
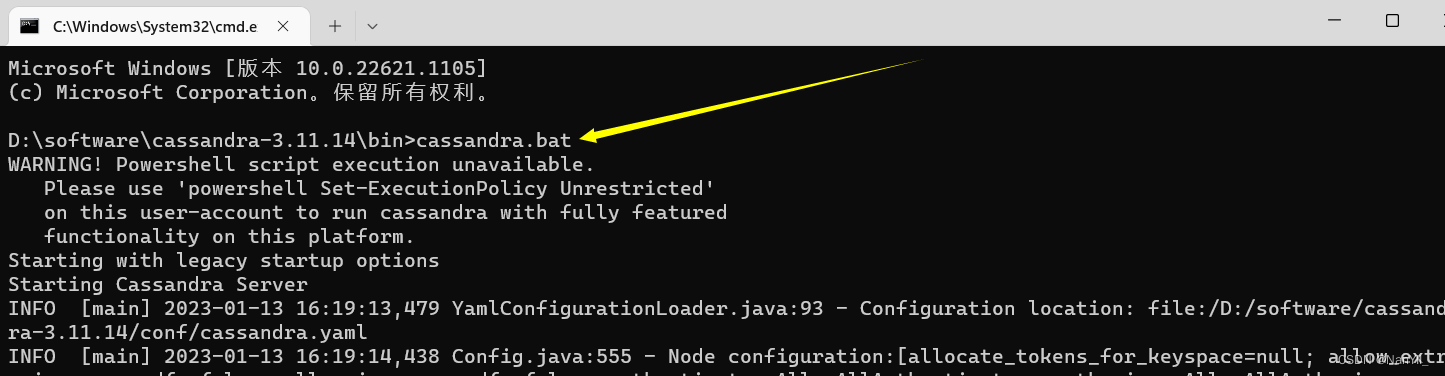
3.2.4 启动Cassandra
快捷键 Win+R 打开cmd窗口,进入D:\software\cassandra-3.11.14\bin目录,执行cassandra.bat文件,看到下入图,说明启动成功。 注意:这个CMD窗口不要关闭,一旦关闭,Cassandra服务就会关闭了!!!
3.2.5 Cassandra客户端连接Cassandra服务器
注意:Cassandra的客户端的使用需要用的Python2.X版本。需要先安装Python2.X
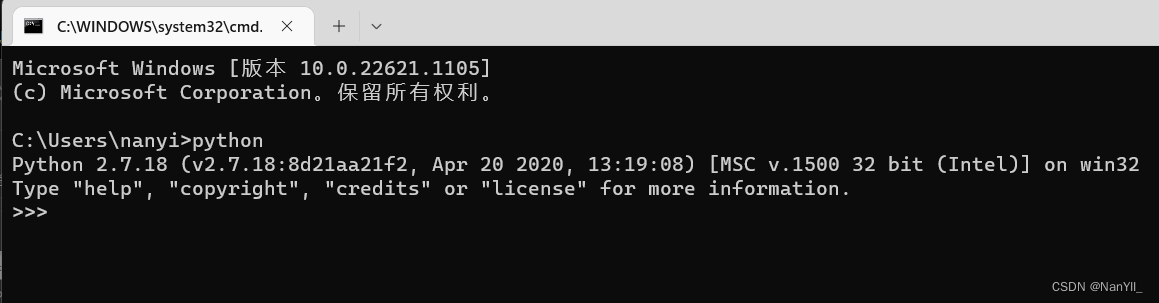
1)安装2.7.18的过程略,安装成功后把Python2.7。18安装后的目录设置到环境变量的path中
新打开CMD窗口,输入命令 python,如果现实如下内容,说明python安装成功
2)使用Cassandra客户端连接服务器
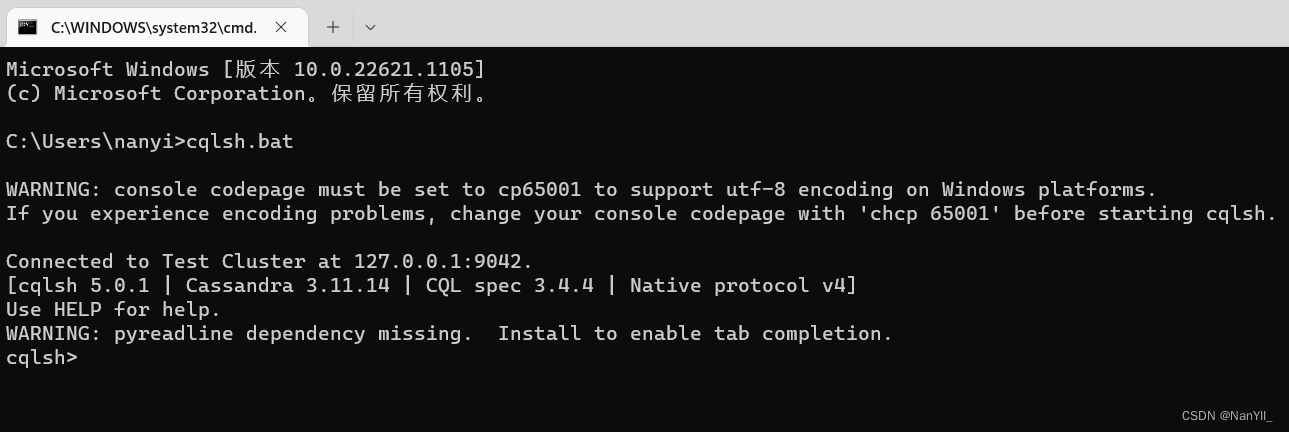
新打开CMD窗口,进入Cassandra的bin目录,连接本地服务器可直接输入:
C:\Users\nanyi>cqlsh.bat
连接指定服务器需输入:
C:\Users\nanyi>cqlsh.bat 12.1.11.1 9042
回车,看到如图所示,说明已经连接到服务器
3.2.6 Cassandra的端口
7199 - JMX
7000 - 节点间通信(如果启用了TLS,则不使用)
7001 - TLS节点间通信(使用TLS时使用)
9160 - Thrift客户端API
9042 - CQL本地传输端口
3.2.7 Cassandra.yaml内容
cluster_name
集群的名字,默认情况下是TestCluster。对于这个属性的配置可以防止某个节点加入到其他集群中去,所以一个集群中的节点必须有相同的cluster_name属性。
listen_address
Cassandra需要监听的IP或主机名,默认是localhost。建议配置私有IP,不要用0.0.0.0。
commitlog_directory
commit
log的保存目录,压缩包安装方式默认是/var/lib/cassandra/commitlog。通过前面的了解,我们可以知道,把这个目录和数据目录分开存放到不同的物理磁盘可以提高性能。data_file_directories
数据文件的存放目录,压缩包安装方式默认是/var/lib/cassandra/data。为了更好的效果,建议使用RAID 0或SSD。
save_caches_directory
保存表和行的缓存,压缩包安装方式默认是/var/lib/cassandra/saved_caches。
通常使用:用得比较频繁的属性
在启动节点前,需要仔细评估你的需求。
commit_failure_policy
提交失败时的策略(默认stop):
stop:关闭gossip和Thrift,让节点挂起,但是可以通过JMX进行检测。
sto_commit:关闭commit log,整理需要写入的数据,但是提供读数据服务。
ignore:忽略错误,使得该处理失败。
disk_failure_policy
设置Cassandra如何处理磁盘故障(默认stop)。
stop:关闭gossip和Thrift,让节点挂起,但是可以通过JMX进行检测。
stop_paranoid:在任何SSTable错误时就闭gossip和Thrift。
best_effort:这是Cassandra处理磁盘错误最好的目标。如果Cassandra不能读取磁盘,那么它就标记该磁盘为黑名单,可以继续在其他磁盘进行写入数据。如果Cassandra不能从磁盘读取数据,那个这些SSTable就标记为不可读,其他可用的继续堆外提供服务。所以就有可能在一致性水平为ONE时会读取到过期的数据。
ignore:用于升级情况。
endpoint_snitch
用于设置Cassandra定位节点和路由请求的snitch(默认org.apache.cassandra.locator.SimpleSnitch),必须设置为实现了IEndpointSnitch的类。
rpc_address 一般填写本机ip
用于监听客户端连接的地址。可用的包括:
- 0.0.0.0监听所有地址
- IP地址
- 主机名
- 不设置:使用hosts文件或DNS
seed_provider
需要联系的节点地址。Cassandra使用-seeds集合找到其他节点并学习其整个环中的网络拓扑。class_name:(默认org.apache.cassandra.locator.SimpleSeedProvider),可用自定义,但通常不必要。
– seeds:(默认127.0.0.1)逗号分隔的IP列表。
compaction_throughput_mb_per_sec
限制特定吞吐量下的压缩速率。如果插入数据的速度越快,越应该压缩SSTable减少其数量。推荐16-32倍于写入速度(MB/s)。如果是0表示不限制。
memtable_total_space_in_mb
指定节点中memables最大使用的内存数(默认1/4heap)。
concurrent_reads
(默认32)读取数据的瓶颈是在磁盘上,设置16倍于磁盘数量可以减少操作队列。
concurrent_writes
(默认32)在Cassandra里写很少出现I/O不稳定,所以并发写取决于CPU的核心数量。推荐8倍于CPU数。
incremental_backups
(默认false)最后一次快照发生时备份更新的数据(增量备份)。当增量备份可用时,Cassandra创建一个到SSTable的的硬链接或者流式存储到本地的备份/子目录。删除这些硬链接是操作员的责任。
snapshot_before_compaction
(默认false)启用或禁用在压缩前执行快照。这个选项在数据格式改变的时候来备份数据是很有用的。注意使用这个选项,因为Cassandra不会自动删除过期的快照。
phi_convict_threshold
(默认8)调整失效检测器的敏感度。较小的值增加了把未响应的节点标注为挂掉的可能性,反之就会降低其可能性。在不稳定的网络环境下(比如EC2),把这个值调整为10或12有助于防止错误的失效判断。大于12或小于5的值不推荐!
性能调优
commit_sync
(默认:periodic)Cassandra用来确认每毫秒写操作的方法。
- periodic:和commitlog_sync_period_in_ms(默认10000 – 10 秒)一起控制把commit
log同步到磁盘的频繁度。周期性的同步会立即确认。- batch:和commitlog_sync_batch_window_in_ms(默认disabled)一起控制Cassandra在执行同步前要等待其他写操作多久时间。当使用该方法时,写操作在同步数据到磁盘前不会被确认。
commitlog_periodic_queue_size
(默认1024*CPU的数量)commit
log队列上的等待条目。当写入非常大的blob时,请减少这个数值。比如,16倍于CPU对于1MB的Blob工作得很好。这个设置应该至少和concurrent_writes一样大。commitlog_segment_size_in_mb
(默认32)设置每个commit log文件段的大小。一个commit
log段在其所有数据刷新到SSTable后可能会被归档、删除或回收。数据的总数可以潜在的包含系统中所有表的commit
log段。默认值适合大多数情况,当然你也可以修改,比如8或16MB。commitlog_total_space_in_mb
(默认32位JVM为32,64位JVM为1024)commit
log使用的总空间。如果使用的空间达到以上指定的值,Cassandra进入下一个临近的部分,或者把旧的commit
log刷新到磁盘,删除这些日志段。该个操作减少了在启动时加载过多数据引起的延迟,防止了把无限更新的表保存到有限的commit log段中。compaction_preheat_key_cache
(默认true)当设置为true的时候,缓存的row
key在压缩期间被跟踪,并且重新缓存其在新压缩的SSTable中的位置。如果有极其大的key要缓存,把这个值设为false。concurrent_compactors
(默认每个CPU一个)设置每个节点并发压缩处理的值,不包含验证修复逆商。并发压缩可以在混合读写工作下帮助保持读的性能——通过减缓把一堆小的SSTable压缩而进行的长时间压缩。如果压缩运行得太慢或太快,请首先修改compaction_throughput_mb_per_sec的值。
in_memory_compaction_limit_in_mb
(默认64)针对数据行在内存中的压缩限制。超大的行会溢出磁盘并且使用更慢的二次压缩。当这个情况发生时,会对特定的行的key记录一个消息。推荐5-10%的Java对内存大小。
multithreaded_compaction
(默认false)当设置为true的时候,每个压缩操作使用一个线程,一个线程用于合并SSTable。典型的,这个只在使用SSD的时候有作用。使用HDD的时候,受限于磁盘I/O(可参考compaction_throughput_mb_per_sec)。
preheat_kernel_page_cache
(默认false)
启用或禁用内核页面缓存预热压缩后的key缓存。当启用的时候会预热第一个页面(4K)用于由每个数据行的顺序访问。对于大的数据行通常是有危害的。file_cache_size_in_mb
(小于1/4堆内存或512)用于SSTable读取的缓存内存大小。
memtable_flush_queue_size
(默认4)等待刷新的满的memtable的数量(等待写线程的memtable)。最小是设置一个table上索引的最大数量。
memtable_flush_writers
(默认每数据目录一个)设置用于刷新memtable的线程数量。这些线程是磁盘I/O阻塞的,每个线程在阻塞的情况下都保持了memtable。如果有大的堆内存和很多数据目录,可以增加该值提升刷新性能。
column_index_size_in_kb
(默认64)当数据到达这个值的时候添加列索引到行上。这个值定义了多少数据行必须被反序列化来读取列。如果列的值很大或有很多列,那么就需要增加这个值。
populate_io_cache_on_flush
(默认false)添加新刷新或压缩的SSTable到操作系统的页面缓存。
reduce_cache_capacity_to
(默认0.6)设置由reduce_cache_sizes_at定义的Java对内存达到限制时的最大缓存容量百分比。
reduce_cache_sizes_at
(默认0.85)当Java对内存使用率达到这个百分比,Cassandra减少通过reduce_cache_capacity_to定义的缓存容量。禁用请使用1.0。
stream_throughput_outbound_megabits_per_sec
(默认200)限制所有外出的流文件吞吐量。Cassandra在启动或修复时使用很多顺序I/O来流化数据,这些可以导致网络饱和以及降低RPC的性能。
trickle_fsync
(默认false)当使用顺序写的时候,启用该选项就告诉fsync强制操作系统在trickle_fsync_interval_in_kb设定的间隔刷新脏缓存。建议在SSD启用。
trickle_fsync_interval_in_kb
(默认10240)设置fsync的大小
四、Cassandra的基本概念
本章介绍Cassandra的基本入门概念
4.1 数据模型
4.1.1 列(Column)
列是Cassandra的基本数据结构单元,具有三个值:名称,值、时间戳
在Cassandra中不需要预先定义列(Column),只需要在KeySpace里定义列族,然后就可以开始写数据了。

4.1.2 列族( Column Family)
列族相当于关系数据库的表(Table),是包含了多行(Row)的容器
ColumnFamily的结构举例,如图:
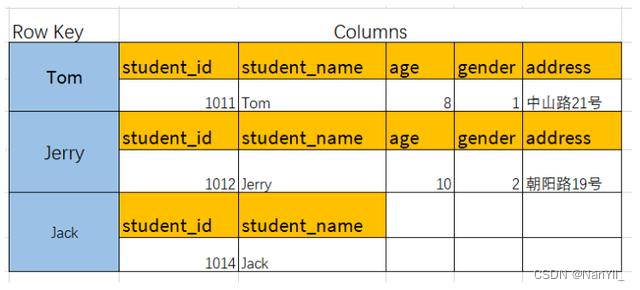
可以理解为Java结构
-
静态column family(static column family)
静态的column family,字段名是固定的,比较适合对于这些column都有预定义的元数据
-
动态column family(dynamic column family)
动态的column family,字段名是应用程序计算出来并且提供的,所以column family只能定义这些字段的类型,无法不可以指定这些字段的名字和值,这些名字和值是由应用程序插入某字段才得出的
2)Row key
ColumnFamily 中的每一行都用Row Key(行键)来标识,这个相当于关系数据库表中的主键,并且总是被索引的
3)主键
Cassandra可以使用PRIMARY KEY 关键字创建主键,主键分为2种 -
Single column Primary Key
如果 Primary Key 由一列组成,那么称为 Single column Primary Key -
Composite Primary Key
如果 Primary Key 由多列组成,那么这种情况称为 Compound Primary Key 或 Composite Primary Key
3)列族具有的属性 -
keys_cached - 它表示每个SSTable保持缓存的位置数。
-
rows_cached - 它表示其整个内容将在内存中缓存的行数。
-
preload_row_cache -它指定是否要预先填充行缓存。
4.1.3 键空间 (KeySpace)
Cassandra的键空间(KeySpace)相当于关系型数据库的数据库,我们创建一个键空间就是创建了一个数据库。
键空间包含一个或多个列族(Column Family)
注意:一般将有关联的数据放到同一个 KeySpace 下面
键空间 (KeySpace) 创建的时候可以指定一些属性:副本因子,副本策略,Durable_writes(是否启用 CommitLog 机制)
-
副本因子(Replication Factor)
副本因子决定数据有几份副本。例如:副本因子为1表示每一行只有一个副,。副本因子为2表示每一行有两个副本,每个副本位于不同的节点上。在实际应用中为了避免单点故障,会配置为3以上。
注意:所有的副本都同样重要,没有主从之分。可以为每个数据中心定义副本因子。副本策略设置应大于1,但是不能超过集群中的节点数。
- 副本放置策略 (Replica placement strategy)
描述的是副本放在集群中的策略
目前有2种策略,内容如下:
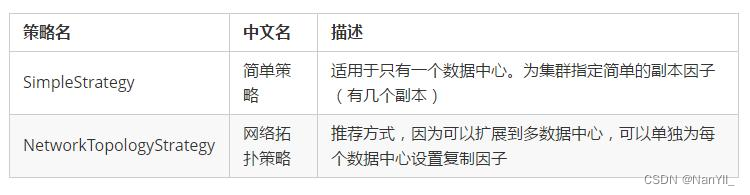
- Durable_writes
否对当前KeySpace的更新使用commitlog,默认为true
4.1.4 副本 (Replication)
副本就是把数据存储到多个节点,来提高容错性
4.1.5 节点(Node)
存储数据的机器
4.1.6 数据中心(DateCenter)
数据中心指集群中所有的机器,组成了一个数据中心。
4.1.7 集群(Cluster)
Cassandra数据库是为跨越多条主机共同工作,对用户呈现为一个整体的分布式系统设计的。Cassandra最外层容器被称为群集。Cassandra将集群中的节点组织成一个环(ring),然后把数据分配到集群中的节点(Node)上。
4.1.8 超级列
超级列是一个特殊列,因此,它也是一个键值对。但是超级列存储了子列的地图。
通常列族被存储在磁盘上的单个文件中。因此,为了优化性能,重要的是保持您可能在同一列族中一起查询的列,并且超级列在此可以有所帮助。下面是超级列的结构。
4.2 数据类型
CQL提供了一组丰富的内置数据类型,用户还可以创建自己的自定义数据类型。 CQL是Cassandra提供的一套查询语言
4.2.1 数值类型
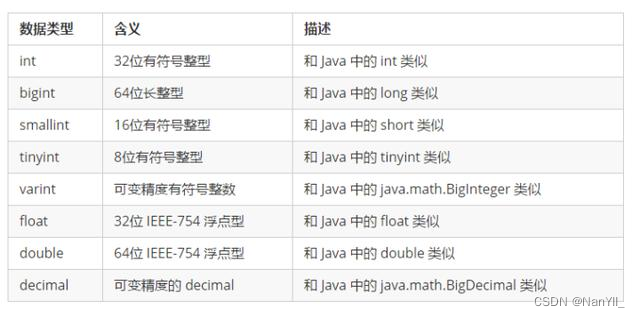
4.2.2 文本类型
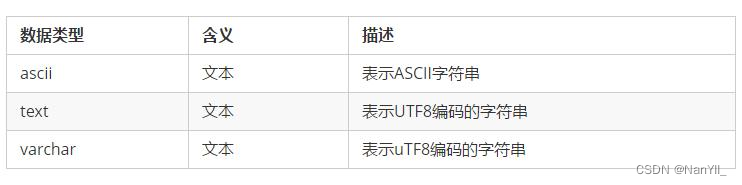
CQL提供2种类型存放文本类型,text和varchar基本一致
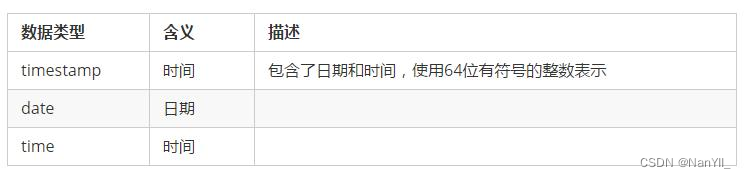
4.2.3 时间类型
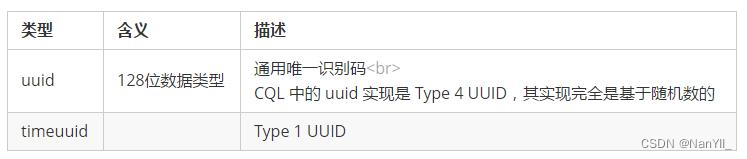
4.2.4 标识符类型
4.2.5 集合类型
-
set
集合数据类型,set 里面的元素存储是无序的。
set 里面可以存储前面介绍的数据类型,也可以是用户自定义数据类型,甚至是其他集合类型。
-
list
list 包含了有序的列表数据,默认情况下,数据是按照插入顺序保存的。
-
map 数据类型包含了 key/value 键值对。key 和 value 可以是任何类型,除了 counter 类型
使用集合类型要注意:
1、集合的每一项最大是64K。
2、保持集合内的数据不要太大,免得Cassandra 查询延时过长,Cassandra 查询时会读出整个集合内的数据,集合在内部不会进行分页,集合的目的是存储小量数据。
3、不要向集合插入大于64K的数据,否则只有查询到前64K数据,其它部分会丢失。
4.2.6 其他基本类型

4.2.7 用户自定义类型
如果内置的数据类型无法满足需求,可以使用自定义数据类型
4.3 CQL Shell 客户端
CQL Shell 简称cqlsh,是一个可以和Cassandra数据库通信的客户端,使用这个cqlsh客户端可以执行Cassandra查询语言(CQL)。
4.3.1 启动cqlsh
-
Windows启用
新打开CMD窗口,进入Cassandra的bin目录,连接本地服务器可直接输入:D:\software\cassandra-3.11.14\bin>cqlsh.bat
连接指定服务器需输入:
C:\Users\nanyi>cqlsh.bat 1**.1*.1**.1* 9042
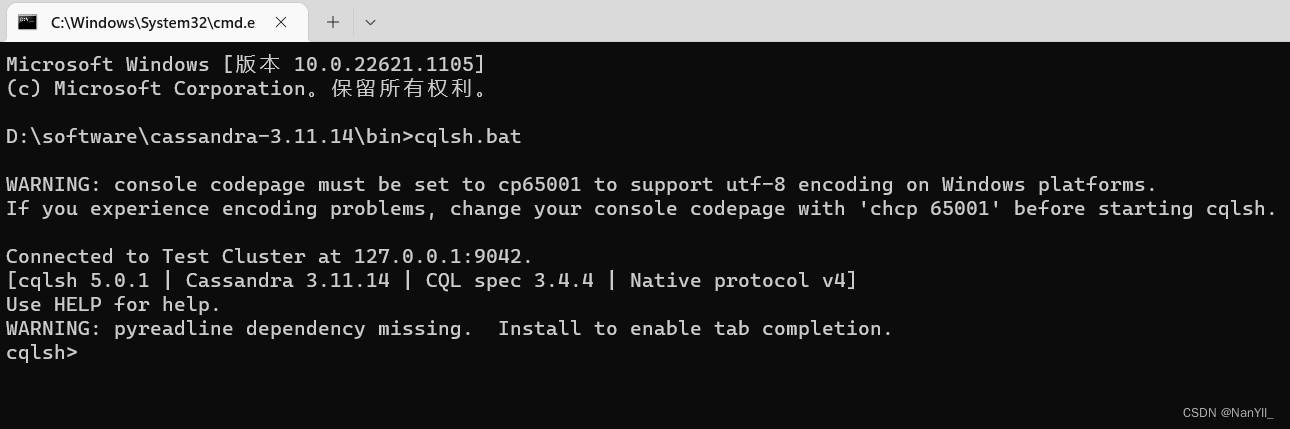
4.3.2 cqlsh的基本命令
命令列表
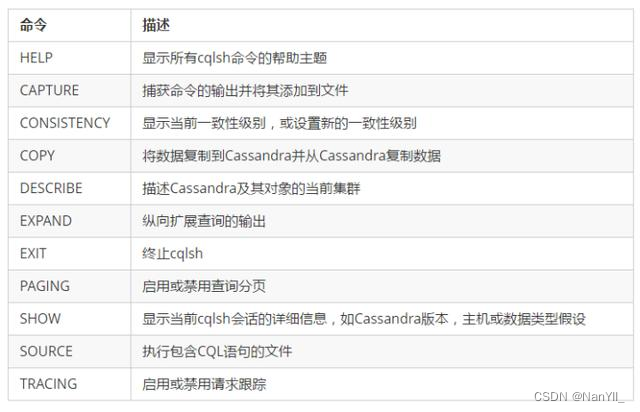
-
help 帮助
输入命令,可以查看cqlsh 支持的命令cqlsh> help
-
DESCRIBE
此命令配合 一些内容可以输入信息Describe cluster 提供有关集群的信息
输入命令:
cqlsh> describe cluster;

describe keyspaces; 列出集群中的所有Keyspaces(键空间)
输入命令:
cqlsh> describe keyspaces;

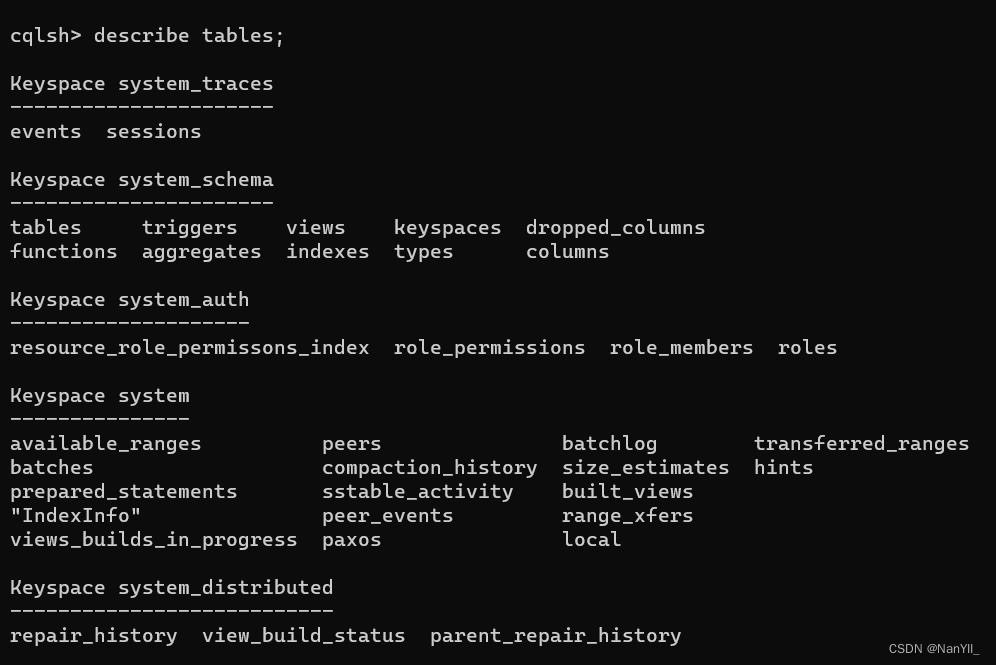
describe tables; 列出键空间的所有表
输入命令:
cqlsh> describe tables;
当前没有创建任何的键空间,这里显示的默认内置的表
describe sessions; 列出键空间内指定表的信息
先指定键空间 ,这里使用 system_traces
输入命令:cqlsh> use system_traces;
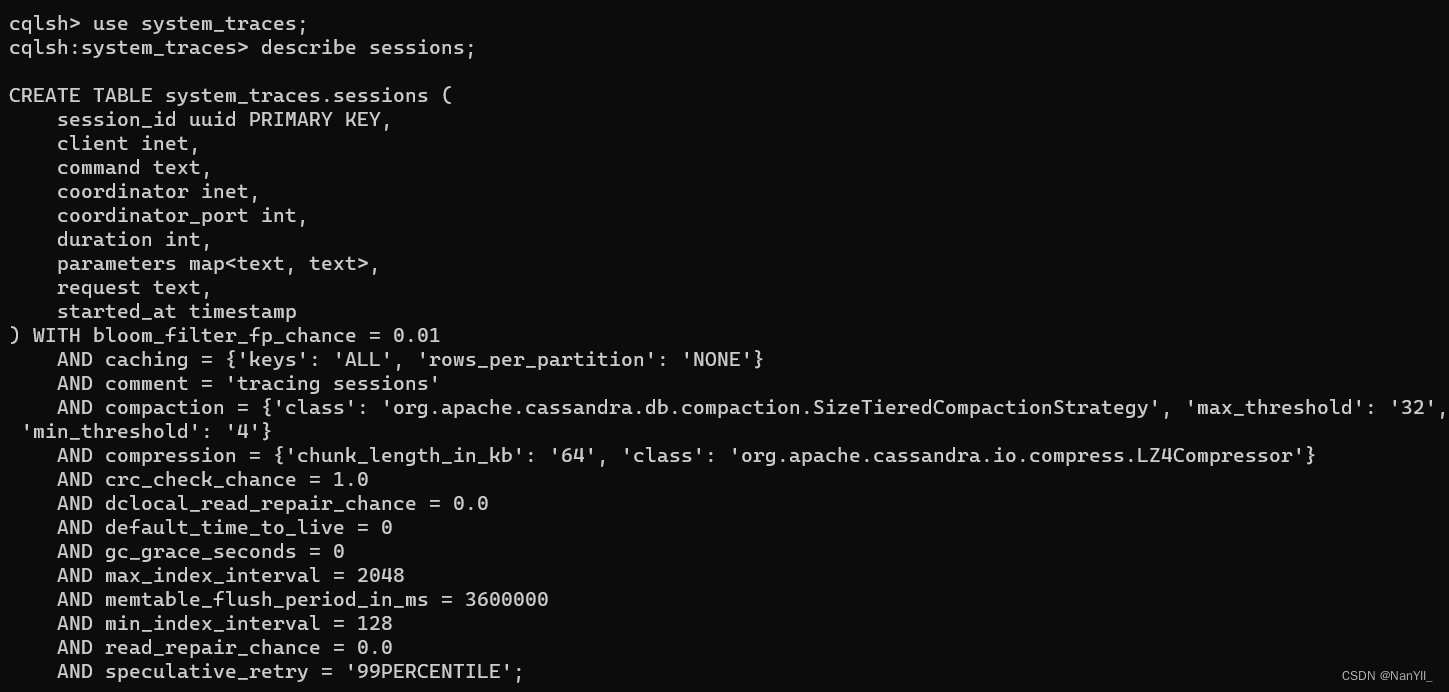
列出system_traces 下的 sessions信息:
输入命令:describe sessions; 列出键空间内指定表的信息
Capture 捕获命令输出到文件
此命令捕获命令的输出并将其添加到文件。输入命令,将输出内容捕获到名为outputfile的文件
cqlsh> capture ‘outputfile’;

执行一个查询,控制台可以看到输出。
然后去看outputfile文件,会发现把刚才查询的结果写到outputfile文件中show 显示当前cqlsh会话的详细信息
show命令后可以跟3个内容 ,分别是 HOST 、SESSION 、VERSION 输入SHOW ,点击2次TAB 按键,可以看到3个内容提示
命令:
cqlsh> show;
输入SHOW HOST,显示当前cqlsh 连接的Cassandra服务的ip和端口
cqlsh> show host;
输入 SHOW VERSION 显示当前的版本
cqlsh> show version;
出入SHOW SESSION 显示会话信息,需要参数uuid
cqlsh> show session < uuid >
Exit 用于终止cql shell
4.4 CQL-Cassandra查询语言
CQL:Cassandra Query Language 和关系型数据库的 SQL 很类似(一些关键词相似),可以使用CQL和 Cassandra 进行交互,实现 定义数据结构,插入数据,执行查询。
注意:CQL 和 SQL 是相互独立,没有任何关系的。CQL 缺少 SQL 的一些关键功能,比如 JOIN 等。
4.4.1 数据定义命令
4.4.2 数据操作指令

4.4.3 查询指令

五、Cassandra的基本操作
本章来学习在CQL Shell中使用CQL操作、查询Cassandra数据
5.1 操作键空间
5.1.1 创建Keyspace
语法
- 创建键空间
CREATE KEYSPACE <identifier> WITH <properties>;
实例:
Create keyspace KeyspaceName with replicaton={'class':strategy name,
'replication_factor': No of replications on different nodes};
要填写的内容:
KeyspaceName 代表键空间的名字
strategy name 代表副本放置策略,内容包括:简单策略、网络拓扑策略,选择其中的一个
No of replications on different nodes 代表 复制因子,放置在不同节点上的数据的副本数
编写完成的创建语句 创建一个键空间名字为:school,副本策略选择:简单策略 SimpleStrategy,副本因子:3
CREATE KEYSPACE school WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};

- 输入 DESCRIBE keyspaces查看所有的键空间,命令:

-
输入 DESCRIBE school 查看键空间的创建语句,命令:
DESCRIBE school;

5.1.2连接Keyspace
语法:USE <identifier>;
编写完整的连接Keyspace语句,连接school 键空间
use school;

5.1.3修改键空间
ALTER KEYSPACE <identifier> WITH <properties>
编写完整的修改键空间语句,修改school键空间,把副本引子 从3 改为1
ALTER KEYSPACE school WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 1};

5.1.4 删除键空间
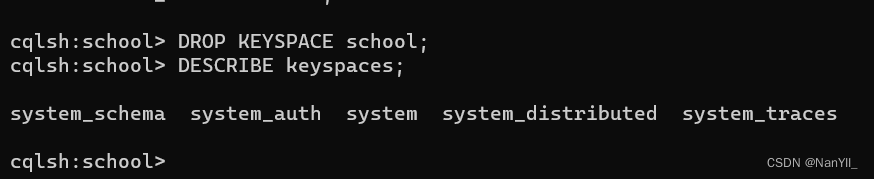
DROP KEYSPACE <identifier>
完整删除键空间语句,删除school键空间:
DROP KEYSPACE school;
5.2 操作表、索引
注意:操作前,先把键空间school键空间创建,并使用school 键空间,代码
5.2.1 查看键空间下所有表
DESCRIBE TABLES;

5.2.2 创建表
CREATE (TABLE | COLUMNFAMILY) <tablename> ('<column-definition>' , '<column-definition>')
(WITH <option> AND <option>)
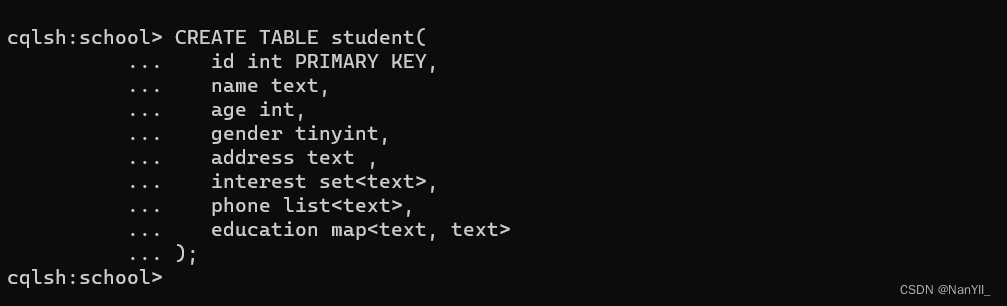
完整创建表语句,创建student 表,student包含属性如下: 学生编号(id), 姓名(name),年龄(age),性别(gender),家庭地址(address),interest(兴趣),phone(电话号码),education(教育经历) id 为主键,并且为每个Column选择对应的数据类型。 注意:interest 的数据类型是set ,phone的数据类型是list,education 的数据类型是map.
CREATE TABLE student(
id int PRIMARY KEY,
name text,
age int,
gender tinyint,
address text ,
interest set<text>,
phone list<text>,
education map<text, text>
);
使用 DESCRIBE TABLE student; 查看创建的表:
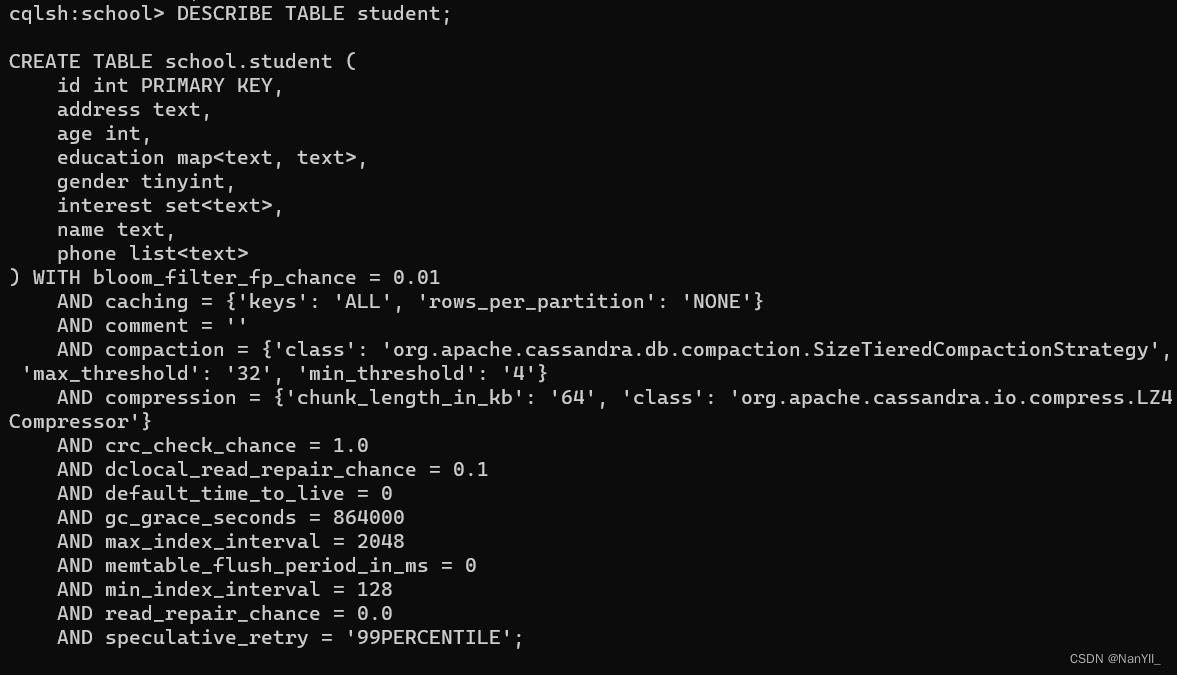
5.2.3 cassandra的索引(KEY)
上面创建student的时候,把student_id 设置为primary key 在Cassandra中的primary key是比较宏观概念,用于从表中取出数据。primary key可以由1个或多个column组合而成。 不要在以下情况使用索引:
- 这列的值很多的情况下,因为你相当于查询了一个很多条记录,得到一个很小的结果
- 表中有couter类型的列
- 频繁更新和删除的列
- 在一个很大的分区中去查询一条记录的时候(也就是不指定分区主键的查询)
Cassandra的5种Key:
-
Primary Key 主键
是用来获取某一行的数据, 可以是单一列(Single column Primary Key)或者多列(Composite Primary Key)。在 Single column Primary Key 决定这一条记录放在哪个节点。
例如:create table testTab (
id int PRIMARY KEY,
name text
); -
Partition Key 分区Key
在组合主键的情况下(上面的例子),第一部分称作Partition Key(key_one就是partition key),第二部分是CLUSTERING KEY(key_two)
Cassandra会对Partition key 做一个hash计算,并自己决定将这一条记录放在哪个节点。
如果 Partition key 由多个字段组成,称之为 Composite Partition key
例如:create table testTab (
key_part_one int,
key_part_two int,
key_clust_one int,
key_clust_two int,
key_clust_three uuid,
name text,
PRIMARY KEY((key_part_one,key_part_two), key_clust_one, key_clust_two, key_clust_three)
); -
Composite Primary Key 复合Key
如果 Primary Key 由多列组成,那么这种情况称为 Compound Primary Key 或 Composite Primary Key。
例如:create table testTab (
key_one int,
key_two int,
name text,
PRIMARY KEY(key_one, key_two)
);
执行创建表后,查询testTab,会发现key_one和key_two 的颜色与其他列不一样,效果: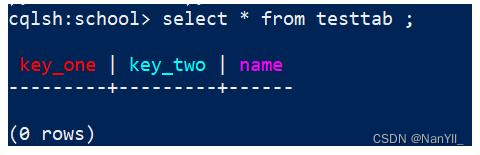
-
Clustering Key 集群
决定同一个分区内相同 Partition Key 数据的排序,默认为升序,可以在建表语句里面手动设置排序的方式
5.2.4 修改表结构
-
添加列,语法
ALTER TABLE table name ADD new column datatype;
例如:给student添加一个列email代码:
cqlsh:school> ALTER TABLE student ADD email text;

-
删除列,语法
ALTER table name DROP columnname;
例如:给student添加一个列email代码:
cqlsh:school> ALTER table student DROP column email;

5.2.5 删除表
DROP TABLE
删除student,命令如下:
DROP TABLE student;

5.2.6 清空表
表的所有行都将永久删除
TRUNCATE <tablename>;
实例:
TRUNCATE testtab;
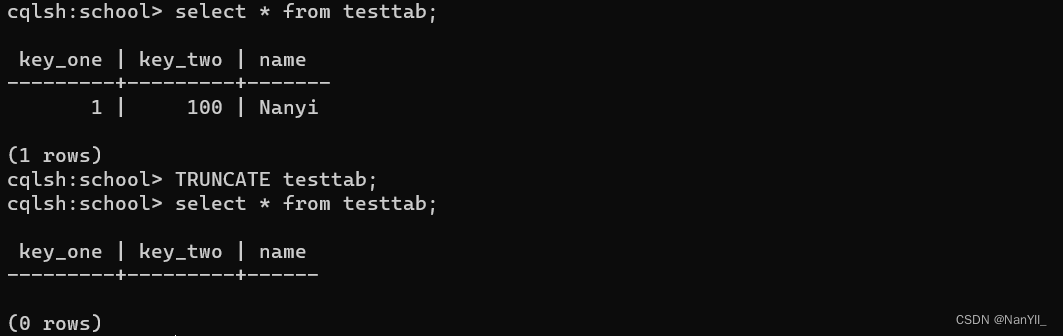
5.2.7 创建索引
- 普通列创建索引
CREATE INDEX ON
为student的 name 添加索引,索引的名字为:sname, 命令:
CREATE INDEX sname ON student (name);
为student 的age添加索引,不设置索引名字,命令:
CREATE INDEX ON student (age);
使用 DESCRIBE student 查看表:
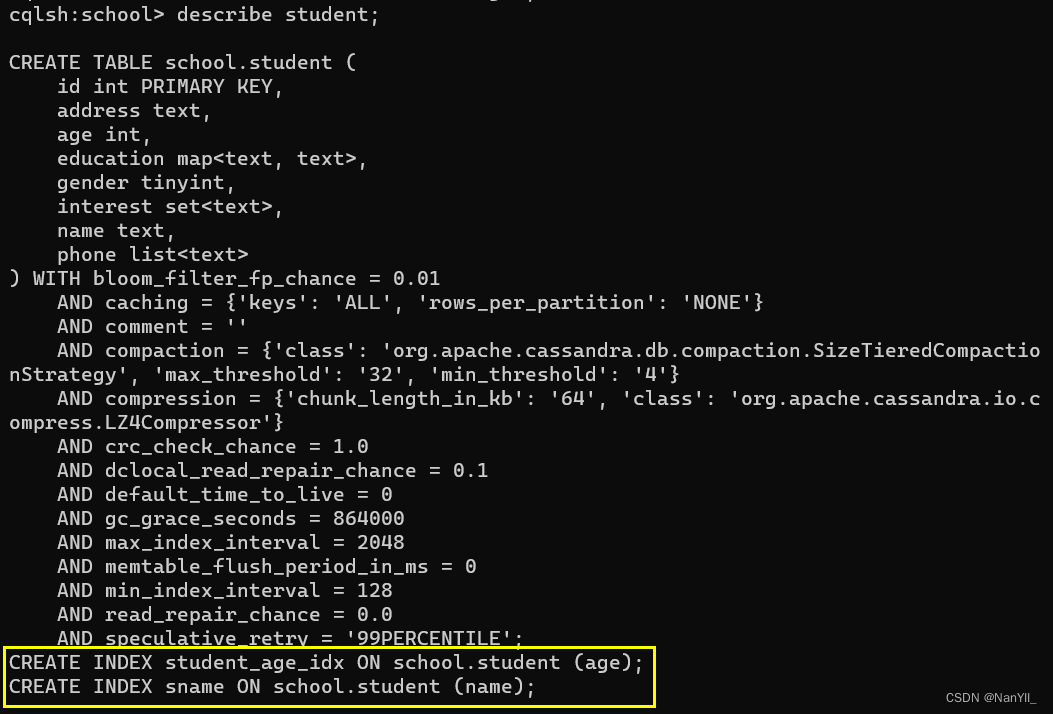
可以发现 对age创建索引,没有指定索引名字,会提供一个默认的索引名:student_age_idx。
索引原理:
Cassandra之中的索引的实现相对MySQL的索引来说就要简单粗暴很多了。Cassandra自动新创建了一张表格,同时将原始表格之中的索引字段作为新索引表的Primary Key!并且存储的值为原始数据的Primary Key
- 集合列创建索引
给集合列设置索引:
CREATE INDEX ON student(interest); -- set集合添加索引
CREATE INDEX mymap ON student(KEYS(education)); -- map结合添加索引
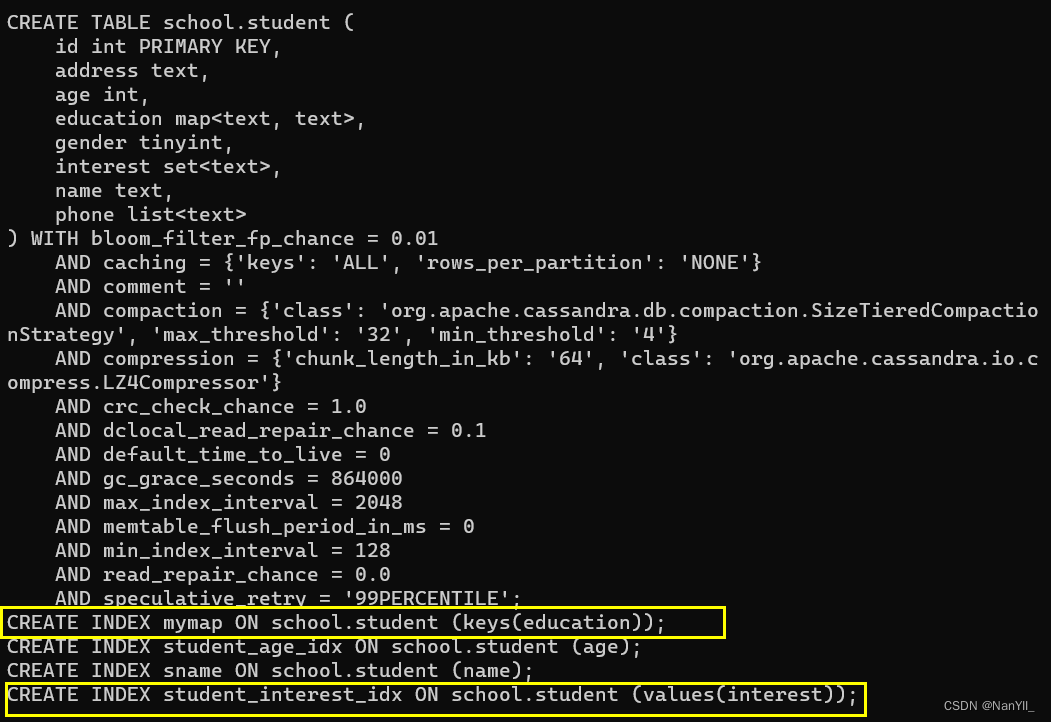
5.2.8 删除索引
DROP INDEX
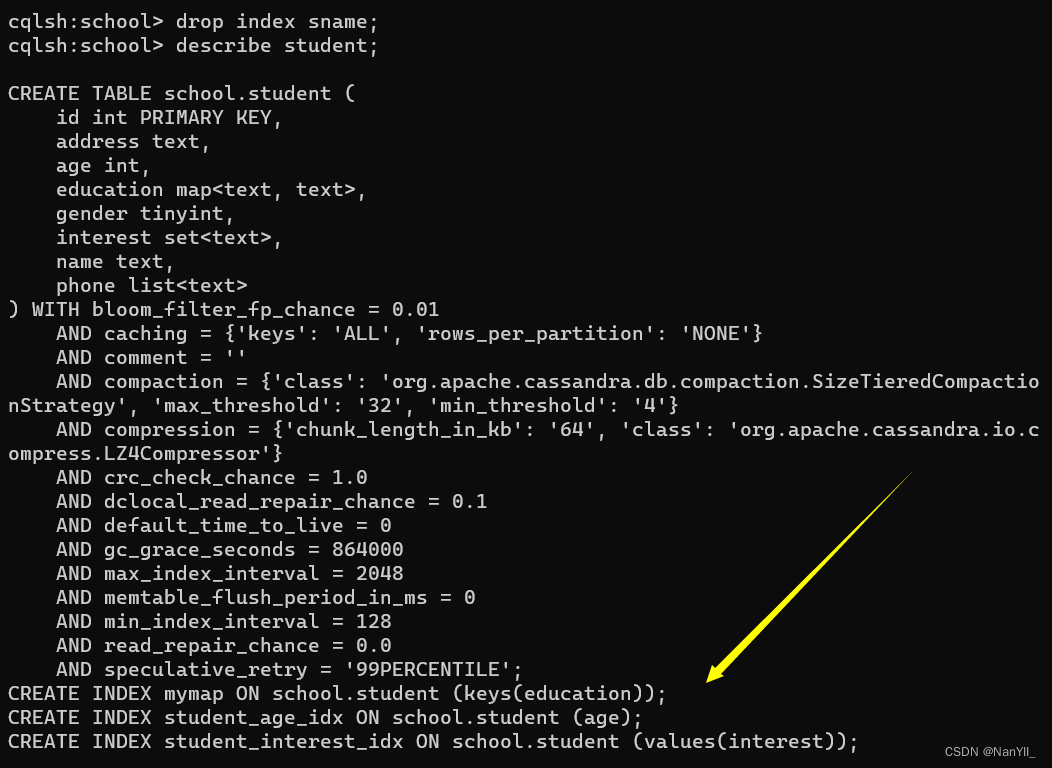
删除student的sname 索引,命令:
drop index sname;
执行上面代码,然后使用DESCRIBE student 查看表,发现sname索引已经不存在:
5.3 查询数据
5.3.1 查询数据
使用 SELECT 、WHERE、LIKE、GROUP BY 、ORDER BY等关键词
SELECT FROM <tablename>
SELECT FROM <table name> WHERE <condition>;
- 查询所有数据
cqlsh:school> select * from student;
- 根据主键查询
cqlsh:school> select * from student where id=1012;
5.3.2 查询时使用索引
Cassandra对查询时使用索引有一定的要求,具体如下:
- Primary Key 只能用 = 号查询
- 第二主键 支持= > < >= <=
- 索引列 只支持 = 号
- 非索引非主键字段过滤可以使用ALLOW FILTERING
当前的表testTab,表中包含一些数据:
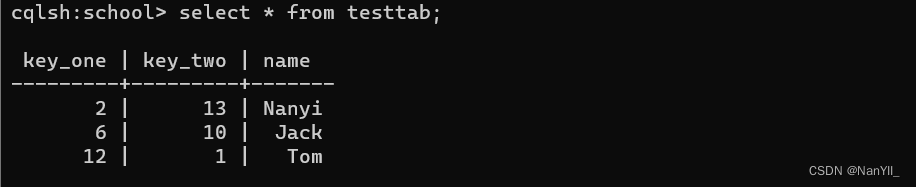
- 第一主键 只能用=号查询
key_one列是第一主键 对key_one进行 = 号查询,可以查出结果:
select * from testtab where key_one=6;

对key_one 进行范围查询使用 > 号,无法查出结果:

- 第二主键 支持 = 、>、 <、 >= 、 <=
key_two是第二主键,不要单独对key_two 进行 查询:

意思是如果想要完成这个查询,可以使用 ALLOW FILTERING
select * from testtab where key_two = 1 ALLOW FILTERING;

注意:加上ALLOW FILTERING 后确实可以查询出数据,但是不建议这么做
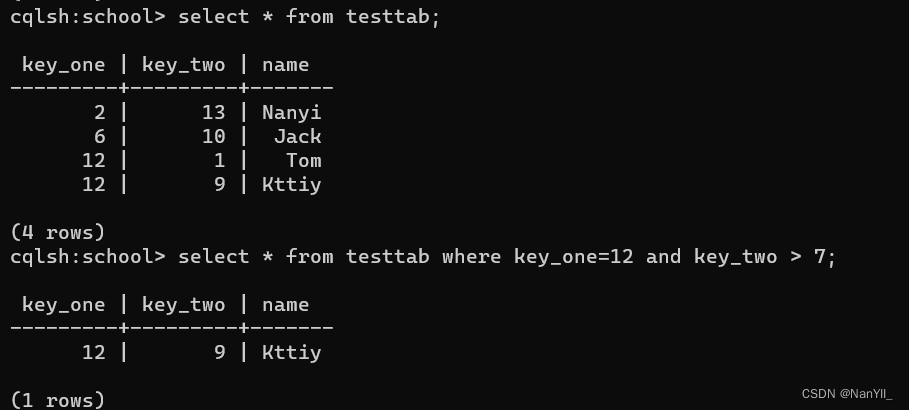
正确的做法是 ,在查询第二主键时,前面先写上第一主键:
select * from testtab where key_one=12 and key_two = 1;

select * from testtab where key_one=12 and key_two > 7;
- 索引列 只支持=号
select * from testtab where 索引列名称 = 19; -- 正确
select * from testtab where 索引列名称 > 20 ; --会报错
select * from testtab where 索引列名称 >20 allow filtering; --可以查询出结果,但是不建议这么做
- 普通列,非索引非主键字段
name是普通列,在查询时需要使用ALLOW FILTERING
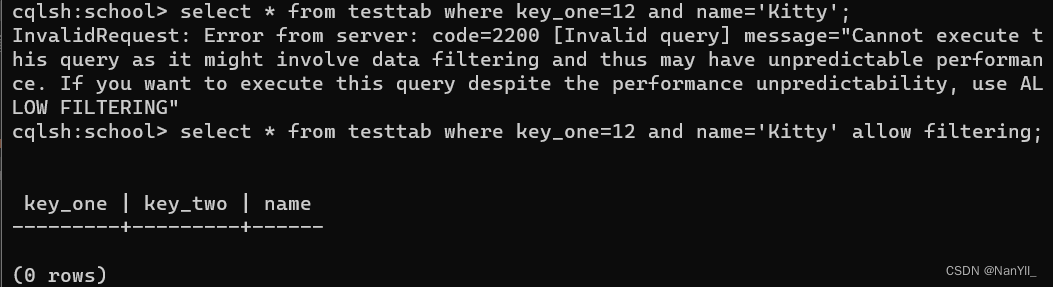
select * from testtab where key_one=12 and name='Kitty'; --报错
select * from testtab where key_one=12 and name='Kitty' allow filtering; --可以查询
- 集合列
使用student表来测试集合列上的索引使用。
假设已经给集合添加了索引,就可以使用where子句的CONTAINS条件按照给定的值进行过滤;
select * from student where interest CONTAINS '电影'; -- 查询set集合
select * from student where education CONTAINS key '小学'; --查询map集合的key值
select * from student where education CONTAINS '中心第9小学' allow filtering; --查询map的value值
-
ALLOW FILTERING
ALLOW FILTERING是一种非常消耗计算机资源的查询方式。 如果表包含例如100万行,并且其中95%具有满足查询条件的值,则查询仍然相对有效,这时应该使用ALLOW FILTERING。
如果表包含100万行,并且只有2行包含满足查询条件值,则查询效率极低。Cassandra将无需加载999,998行。如果经常使用查询,则最好在列上添加索引。
ALLOW FILTERING在表数据量小的时候没有什么问题,但是数据量过大就会使查询变得缓慢。
5.3.3 查询时排序
cassandra也是支持排序的,order by。 排序也是有条件的。
-
必须有第一主键的=号查询
cassandra的第一主键是决定记录分布在哪台机器上,cassandra只支持单台机器上的记录排序。
-
只能根据第二、三、四…主键进行有序的,相同的排序。
-
不能有索引查询
cassandra的任何查询,最后的结果都是有序的,内部就是这样存储的。现在使用 testTab表,来测试排序。
select * from testtab where key_one = 12 order by key_two; --正确
select * from testtab where key_one = 12 and age =19 order key_two; --错误,不能有索引查询
索引列 支持 like
主键支持 group by
5.4 分页查询
INSERT INTO <tablename>(<column1 name>, <column2 name>....) VALUES (<value1>, <value2>....) USING <option>
给student添加2行数据,包含对set,list ,map类型数据,命令:
INSERT INTO student (id,address,age,gender,name,interest, phone,education) VALUES (1011,'中山路21号',16,1,'Tom',{'游泳', '跑步'},['010-88888888','13888888888'],{'小学' : '城市第一小学', '中学' : '城市第一中学'}) ;
INSERT INTO student (id,address,age,gender,name,interest, phone,education) VALUES (1012,'朝阳路19号',17,2,'Jerry',{'看书', '电影'},['020-66666666','13666666666'],{'小学' :'城市第五小学','中学':'城市第五中学'});
添加TTL,设定的computed_ttl数值秒后,数据会自动删除:
INSERT INTO student (id,address,age,gender,name,interest, phone,education) VALUES (1030,'朝阳路30号',20,1,'Cary',{'运动', '游戏'},['020-7777888','139876667556'],{'小学' :'第30小学','中学':'第30中学'}) USING TTL 60;
5.5 更新列数据
更新表中的数据,可用关键字:
- Where - 选择要更新的行
- Set - 设置要更新的值
- Must - 包括组成主键的所有列
在更新行时,如果给定行不可用,则UPDATE创建一个新行:
UPDATE <tablename>
SET <column name> = <new value>
<column name> = <value>....
WHERE <condition>
5.5.1 更新简单数据
把student_id = 1012 的数据的gender列 的值改为1,命令:
UPDATE student set gender = 1 where student_id= 1012;
5.5.2 更新set类型数据
在student中interest列是set类型
- 添加一个元素
使用UPDATE命令 和 ‘+’ 操作符
UPDATE student SET interest = interest + {'游戏'} WHERE student_id = 1012;
- 删除一个元素
使用UPDATE命令 和 ‘-’ 操作符
UPDATE student SET interest = interest - {'电影'} WHERE student_id = 1012;
- 删除所有元素
可以使用UPDATA或DELETE命令,效果一样
UPDATE student SET interest = {} WHERE student_id = 1012;
或
DELETE interest FROM student WHERE student_id = 1012;
注意:一般来说,Set,list和Map要求最少有一个元素,否则Cassandra无法把其同一个空值区分
5.5.3 更新list类型数据
- 使用UPDATA命令向list插入值
UPDATE student SET phone = ['020-66666666', '13666666666'] WHERE student_id = 1012;
- 在list前面插入值
UPDATE student SET phone = [ '030-55555555' ] + phone WHERE student_id = 1012;
- 在list后面插入值
UPDATE student SET phone = phone + [ '040-33333333' ] WHERE student_id = 1012;
- 使用列表索引设置值,覆盖已经存在的值
这种操作会读入整个list,效率比上面2种方式差
现在把phone中下标为2的数据,也就是 “13666666666”替换,命令:
UPDATE student SET phone[2] = '050-22222222' WHERE student_id = 1012;
- 【不推荐】使用DELETE命令和索引删除某个特定位置的值
非线程安全的,如果在操作时其它线程在前面添加了一个元素,会导致移除错误的元素
DELETE phone[2] FROM student WHERE student_id = 1012;
- 【推荐】使用UPDATE命令和‘-’移除list中所有的特定值
UPDATE student SET phone = phone - ['020-66666666'] WHERE student_id = 1012;
5.5.4 更新map类型数据
map输出顺序取决于map类型。
- 使用Insert或Update命令
UPDATE student SET education=
{'中学': '城市第五中学', '小学': '城市第五小学'} WHERE student_id = 1012;
- 使用UPDATE命令设置指定元素的value
UPDATE student SET education['中学'] = '爱民中学' WHERE student_id = 1012;
- 可以使用如下语法增加map元素。如果key已存在,value会被覆盖,不存在则插入
覆盖“中学”为“科技路中学”,添加“幼儿园”数据,命令:
UPDATE student SET education = education + { '幼儿园' : '大海幼儿园', '中学': '科技路中学'} WHERE student_id = 1012;
- 删除元素
可以用DELETE 和 UPDATE 删除Map类型中的数据
使用DELETE删除数据:
DELETE education['幼儿园'] FROM student WHERE student_id = 1012;
使用UPDATE删除数据:
UPDATE student SET education=education - {'中学','小学'} WHERE student_id = 1012;
5.6 删除行
DELETE FROM <identifier> WHERE <condition>;
删除student中student_id=1012 的数据,命令:
DELETE FROM student WHERE student_id=1012;
5.7 批量操作
把多次更新操作合并为一次请求,减少客户端和服务端的网络交互。 batch中同一个partition key的操作具有隔离性。
使用BATCH,您可以同时执行多个修改语句(插入,更新,删除)
BEGIN BATCH
<insert-stmt>/ <update-stmt>/ <delete-stmt>
APPLY BATCH
1、先把数据清空,然后使用添加数据的代码,在student中添加2条记录,student_id 为1011 、 1012
2、在批量操作中实现 3个操作:
新增一行数据,student_id =1015
更新student_id =1012的数据,把年龄改为11,
删除已经存在的student_id=1011的数据,命令:
BEGIN BATCH
INSERT INTO student (id,address,age,gender,name) VALUES (1015,'上海路',20,1,'Jack') ;
UPDATE student set age = 11 where id= 1012;
DELETE FROM student WHERE id=1011;
APPLY BATCH;