机械转码日记【20】vector及vector的模拟实现
目录
前言
1.vector的使用
1.1构造函数
1.2vector的遍历
1.3reserve和resize
1.4insert和erase
1.5 find
1.6 sort
2.vector的OJ题
2.1只出现一次的数字
2.2杨辉三角
2.3电话号码的字母组合
3.vector和string的区别
4.vector的模拟实现
4.1构造函数、析构函数、拷贝构造、赋值重载=
4.2reserve()和push_back()
4.3begin()、end()、capacity()、size()
4.4popback()
4.5[ ]
4.6reserve()和resize()
4.7erase()和insert()
5.迭代器失效
5.1insert的迭代器失效
5.2erase的迭代器失效
6.深层次的深浅拷贝问题
前言
vector是stl里面一个可以动态增长的顺序容器,这篇博客我们就来学习它的使用和模拟实现。vector的使用方法和模拟实现逻辑很多都是和前一篇博客提到的string相像的,我们可以参考前一篇博客去理解我们这篇博客。
1.vector的使用
vector的使用还是比较轻松的,因为我们前一篇博客学习了string类,里面的很多接口函数都是同名的,这就是C++的STL方便的地方。因此这篇博客对于介绍vector的使用还是比较少的,因为大部分用法都和string一样。
1.1构造函数
vector的构造函数有多种形式,我们主要用到的是无参构造和拷贝构造,剩下的查手册就行。
| (vector的构造函数)构造函数声明 | 接口说明 |
| vector()(重点) | 无参构造 |
| vector(size_type n, const value_type& val = value_type()) | 构造并初始化n个val |
| vector (const vector& x); (重点) | 拷贝构造 |
| vector (InputIterator first, InputIterator last); | 使用迭代器进行初始化构造 |
void test_vector_1()
{
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
vector<double> v2;
v2.push_back(1.1);
v2.push_back(2.2);
v2.push_back(3.3);
vector<string> v3;
v3.push_back("李白");
v3.push_back("苏轼");
v3.push_back("白居易");
v3.push_back("杜甫");
vector<int> v4(10, 5);//构造的时候用10个5去初始化
vector<string> v5(++v3.begin(), --v3.end());//用迭代器区间初始化
string s = "hello world";
vector<char> v6(s.begin(), s.end());//可以用任意类型的迭代器初始化
}1.2vector的遍历
vector的遍历和之前string差不多,都是三种:
- 下标+[]
- 迭代器
- 范围for
void test_vector_2()
{
//vector的遍历
vector <int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
//1、下标+[]
for (size_t i = 0; i < v.size(); i++)
{
v[i] += 1;
cout << v[i] << " ";
}
cout << endl;
//2、迭代器
vector<int>::iterator it = v.begin();
while (it != v.end())
{
*it -= 1;
cout << *it << " ";
it++;
}
cout << endl;
//3、范围for
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}
1.3reserve和resize
reserve和resize的区别其实和string的一样,reserve是单纯的开辟一段空间供vector对象使用,而resize是开空间+初始化,如下面这段程序:
void test_vector_5()
{
size_t sz;
std::vector<int> foo;
foo.reserve(100);//用这个没有增容
foo.resize(100);//开空间+初始化,用这个增容了,因为已经初始化全为0了,尾插是在0的后面继续插入,所以还是会增容,因此应该用reserve
sz = foo.capacity();
std::cout << "making foo grow:\n";
for (int i = 0; i < 100; ++i)
{
foo.push_back(i);
if (sz != foo.capacity())
{
sz = foo.capacity();
std::cout << "capacity changed: " << sz << '\n';
}
}
}运行结果如下:

可以看到用reserve(100)是提前开辟了100个空间(并没有初始化),使用resize(100)也是提前开辟了100个空间但是全部初始化为0了,后续再插入数据是尾插再这100个数据之后,所以发生了增容。
1.4insert和erase
vector的insert和string的区别是它不支持下标了,只支持通过迭代器插入;erase也是只能通过传迭代器去使用


void test_vector_6()
{
vector <int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
//头插
v.insert(v.begin(), -1);
v.insert(v.begin(), -2);
v.insert(v.begin(), -3);
//越界也会报错
//v.insert(v.begin() + 8, 300);
//头删
v.erase(v.begin());
//insert效率较低,慎用
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}1.5 find
vector和string不一样,它的库里面没有find这个函数,如果要找到vector对象的某个元素,要使用algorithm.h里面的find函数,find如果找到了就会返回迭代器,找不到返回last(也就是vector的最后一个位置的迭代器)。
void test_vector_7()
{
vector <int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
//头插
v.insert(v.begin(), -1);
v.insert(v.begin(), -2);
v.insert(v.begin(), -3);
//find:
//vector<int>::iterator pos = find(v.begin(), v.end(), 3);
//嫌烦可以用auto自动推导
auto pos = find(v.begin(), v.end(), 3);
if (pos != v.end())
{
cout << "找到了!" << endl;
v.erase(pos);
}
else
{
cout << "没找到!" << endl;
}
}
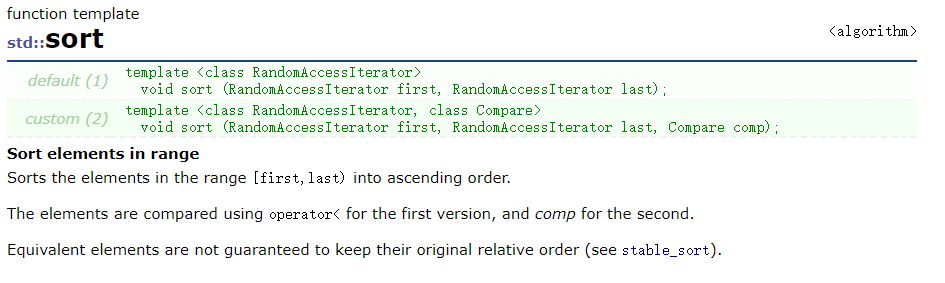
1.6 sort
sort函数也是algorithm.h的函数,顾名思义,他是实现排序的功能,它默认是排升序,如果要排降序,需要用到仿函数grearter,同时我们也可以选择显式的传一个排升序的仿函数less,(是不是很奇怪,传的仿函数都是反的,但是事实就是如此,我也无力吐槽)使用方法如下图所示:
void test_vector_9()
{
vector <int> v;
v.push_back(0);
v.push_back(9);
v.push_back(3);
v.push_back(1);
v.push_back(3);
v.push_back(8);
//默认是升序
cout << "排序前:" << endl;
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
sort(v.begin(), v.end(), greater<int>());
cout << "排降序“sort(v.begin(), v.end(), greater<int>())”:" << endl;
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
cout << "排升序“sort(v.begin(), v.end(), less<int>())”:" << endl;
sort(v.begin(), v.end(), less<int>());
for (auto e : v)
{
cout << e << " ";
}
}
2.vector的OJ题
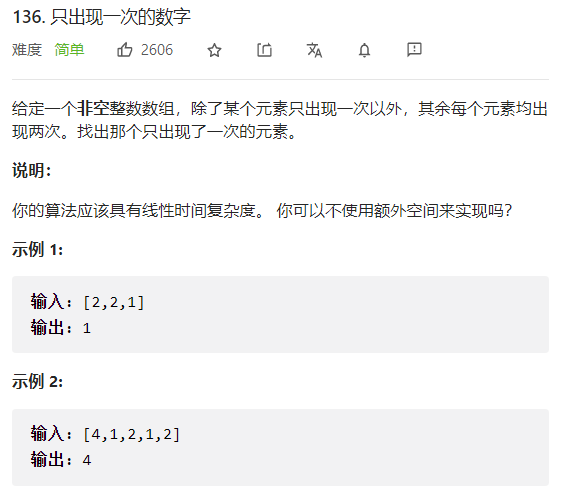
2.1只出现一次的数字
只出现一次的数字
这道题可以取巧来做,只出现一次的数字用异或操作就可以完美解决,我们只需要记住异或的以下三条定律就行:
- a^b = b^a
- a^a=0
- a^0=a
class Solution {
// 异或满足两条定律:
// 1、a^b = b^a
// 2、a^a=0
// 3、a^0=a;
public:
int singleNumber(vector<int>& nums)
{
int ans=0;
for(int n : nums)
ans ^= n; //异或
return ans;
}
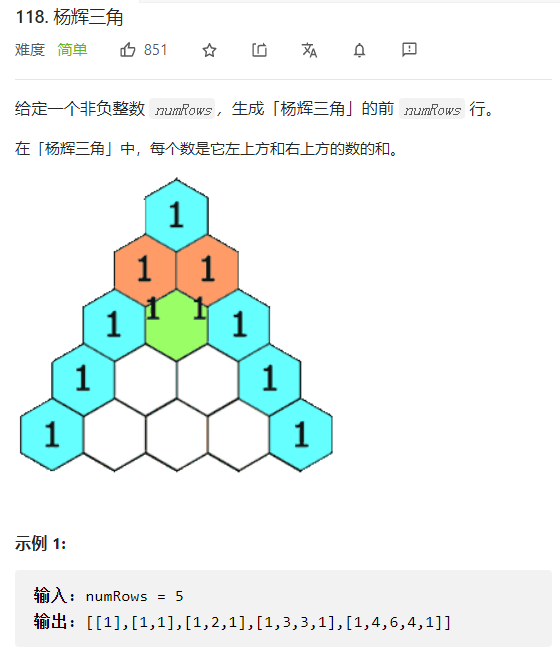
};2.2杨辉三角
杨辉三角
这道题是生成杨辉三角,如果用C语言来做的话会非常麻烦,将会用到二维数组,但用C++来做是很方便的,我们可以使用vector<vector<int>> 来模仿一个int类型的二维数组,并且能用到vector的库函数,这将会很方便,生成杨辉三角的逻辑也是很简单的,先将作用两列都初始化为1,接着将不是1的数值都变成上一行的左右两列相加就行。

class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>> vv;
vv.resize(numRows);
for(size_t i = 0;i <vv.size();i++)
{
vv[i].resize(i+1,0);//每一行全部初始化为0,
vv[i][0]=1;//最左列初始化为1;
vv[i][i]=1;//最右列初始化为1
}
//遍历vv
for(size_t i = 0;i <vv.size();i++)
{
for(size_t j = 0;j<vv[i].size();++j)
{
//如果为0,说明不是最左列和最右列
if(vv[i][j]==0)
{
//那么他的值就是上一行的第j-1个和第j个
vv[i][j]=vv[i-1][j-1]+vv[i-1][j];
}
}
}
return vv;
}
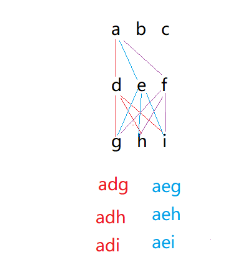
};2.3电话号码的字母组合
电话号码的字母组合

这道题就上难度了,这是关于排列组合的一道题,提到排列组合就要用到递归解题,递归可能对我们来说有点挑战,但其实也没那么麻烦,我们可以一层一层的画递归展开图去解题,每当排完一层就跳出这一层循环。
class Solution {
string _numToStr[10] = {"","","abc","def","ghi","jkl","mno","pqrs","tuv","wxyz"};
public:
void _letterCombine(string digits,size_t di,string combineStr,vector<string>& retV)
{
if(di==digits.size())
{
retV.push_back(combineStr);
return;
}
//取到数字字符转换成数字,再取到映射的字符串
int num = digits[di]-'0';
string str = _numToStr[num];
for(auto ch:str)
{
_letterCombine(digits,di+1,combineStr+ch,retV);
}
}
vector<string> letterCombinations(string digits) {
vector<string> retV;
if(digits.empty())
{
return retV;
}
size_t i = 0;
string str;
_letterCombine(digits,i,str,retV);
return retV;
}
};3.vector<char>和string的区别
string的底层其实是一个char的数组,那么你肯定会疑问,能不能用vector<char>去替换string呢?因为vector<char>其实也是一个char类型的数组啊。可以是可以的,它们相差不大,但是则两个数组还是有区别的:
1.vector<char>不支持+=和append

2.vector<char>不支持c语言类型的字符串,也就是说它的字符串最后面要有'\0',但是vector<char>没有。
3.string支持流插入的输出,但是vector<char>不支持
string细究起来还是和vector<char>有一些区别的,但是string是一个更加专用化的容器,在实际使用中,string要比vector<char>的使用实际意义更大一些。
4.vector的模拟实现
我们先从sgi版本的stl_vector.h里看看vector的源代码:

可以看到它的成员变量和string是不一样的,它由三个迭代器组成,分别为start,finish和end of storage;我们可以猜想一下,start可以看作是string的成员变量的_str指针,finish代表string的_size下标的位置,end of storage代表capacity的位置。实际上也确实是这样,我们看看capacity()、begin()、end()函数的实现就可以看出我们刚刚的猜想是正确的。
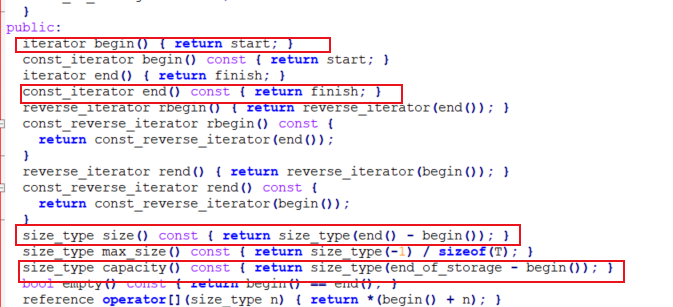
了解了vector的基本构造,我们就开始来模拟实现吧,这样能使熟悉加深对这个容器的理解。
根据我们刚刚的猜想,先把它的基本架构搭起来
namespace bit
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
private:
iterator _start;
iterator _finish;
iterator _endofstorage;
}
}vector的start,finish和endofstorage 所在的位置如下图:

4.1构造函数、析构函数、拷贝构造、赋值重载=
先来一个无参的构造函数:
vector()
:_start(nullptr)
,_finish(nullptr)
,_endofstorage(nullptr)
{}析构函数也很简单:
~vector()
{
if (_start)
{
delete[]_start;
_start = _finish = _endofstorage = nullptr;
}
}拷贝构造,我们用上一篇博客的现代写法来写拷贝构造,首先我们需要里用到一个带参的构造函数来帮助我们构造临时对象tmp;然后用swap函数交换tmp和拷贝构造的新对象的内容。
template<class InputIterator>
vector(InputIterator first, InputIterator last)
: _start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
while (first != last)
{
push_back(*first);
++first;
}
}
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_endofstorage, v._endofstorage);
}
//拷贝构造
vector(const vector<T>& v)
: _start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
vector<T> tmp(v.begin(), v.end());
this->swap(tmp);
}赋值运算符重载也可以写成现代写法,它要保证能实现深拷贝:
vector<T> operator=(vector<T> v)
{
this->swap(v);
return *this;
}这里能是实现深拷贝,因为vector<T> v是会调用拷贝构造的,也是实现了深拷贝。
4.2reserve()和push_back()
这里是用引用传参,因为引用传参可以不发生拷贝,如果是普通的传值传参,就会发生拷贝的动作,降低程序运行的效率,同时由于我们插入的参数是不会修改的,于是用上了const修饰。
void reserve(size_t n)
{
size_t sz = size();//拷贝原来vector的size
if (n>capacity())
{
T* tmp = new T[n];
if (_start)//旧空间有数据,才能使用memcpy,不然_start是空指针
{
memcpy(tmp, _start, size() * sizeof(T));
delete[]_start;
}
_start = tmp;
}
//更新_finish和_endofstorage
_finish = _start + sz;
_endofstorage = _start + n;
}
void push_back(const T& x)
{
size_t newCapacity;
if (_finish == _endofstorage)//判断是否需要扩容
{
if (capacity() == 0)
{
newCapacity = 4;
}
else
{
newCapacity = capacity() * 2;
}
reserve(newCapacity);
}
*_finish = x;
++_finish;
}4.3begin()、end()、capacity()、size()
这几个函数没什么讲的,只需要根据我们上面的那副图的定义,返回相应的值就可以。
iterator begin()
{
return _start;
}
const_iterator begin()const
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator end()const
{
return _finish;
}
size_t size() const
{
return _finish - _start;
}
size_t capacity() const
{
return _endofstorage - _start;
}4.4popback()
popback只需要将size的大小减一就实现尾删了(当然前提是要存在数据才可以将size的大小减一)
void pop_back()
{
if (_finish > _start)//判断是否存在数据,finish小于等于start是不存在数据的
{
--_finish;
}
}4.5[ ]
实现vector的遍历需要用到operator[],也就是对于[]的重载,那么我们对[]进行重载:
T& operator[](size_t pos)
{
assert(pos < size());
return _start[pos];
}
const T& operator[](size_t pos)const
{
assert(pos < size());
return _start[pos];
}4.6reserve()和resize()
reserve的模拟需要注意的是不能用memcpy将原来的数据拷贝过来,因为memecpy是浅拷贝(这点会在第六点讲),我们可以通过自己前面实现的赋值重载函数来实现深拷贝的操作;resize也是和string一样考虑一下初始化内存大小和_finish的关系就行。
void reserve(size_t n)
{
size_t sz = size();
if (n>capacity())
{
T* tmp = new T[n];
if (_start)
{
//memcpy(tmp, _start, size() * sizeof(T));
for (size_t i = 0; i < size(); ++i)
{
tmp[i] = _start[i];
}
delete[]_start;
}
_start = tmp;
}
_finish = _start + sz;
_endofstorage = _start + n;
}
void resize(size_t n, T val = T())
{
if (n > capacity())
{
reserve(n);
}
//要初始化的数据大于原始数据长度
if (n > size())
{
while (_finish < _start + n)
{
*_finish = val;
++_finish;
}
}
//要初始化的数据小于等于原始数据(_finish)长度,缩容
else
{
_finish = _start + n;
}
}4.7erase()和insert()
insert和erase的逻辑和string的相同,但是insert要注意扩容后要更新一下pos的位置,不然pos会变成一个野指针,同时erase和insert都要返回迭代器,insert是返回插入的那个元素的位置,erase是返回被删除元素的下一个位置,至于为什么要返回,我们看第五届的迭代器失效问题
iterator insert(iterator pos, const T& x)
{
assert(pos >= _start && pos <= _finish);
//空间不够就扩容
//扩容以后pos就失效了,需要更新一下
size_t newCapacity;
if (_finish == _endofstorage)
{
size_t n = pos - _start;
if (capacity() == 0)
{
newCapacity = 4;
}
else
{
newCapacity = capacity() * 2;
}
reserve(newCapacity);
pos = _start + n;
}
//挪动数据
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
//放数据
*pos = x;
++_finish;
return pos;
}
iterator erase(iterator pos)
{
assert(pos >= _start && pos < _finish);
iterator it = pos + 1;
//挪动数据
while (it !=_finish)
{
*(it - 1) = *it;
++it;
}
--_finish;
return pos;//返回被删除的元素的下一个位置
}5.迭代器失效
迭代器的主要作用就是让算法能够不用关心底层数据结构,其底层实际就是一个指针,或者是对指针进行了封装,比如:vector的迭代器就是原生态指针T* 。因此迭代器失效,实际就是迭代器底层对应指针所指向的 空间被销毁了,而使用一块已经被释放的空间,造成的后果是程序崩溃(即如果继续使用已经失效的迭代器, 程序可能会崩溃)。 对于vector可能会导致其迭代器失效的操作有两种:
- 会引起其底层空间改变的操作,都有可能是迭代器失效,比如:resize、reserve、insert、assign、 push_back等。
- 指定位置元素的删除操作--erase
5.1insert的迭代器失效
insert的失效有两种情况:
- 野指针的失效
- 指针的意义变了引起的失效
第一种情况,我们可以看看我们实现下面的insert函数会发生什么状况(你会不会觉得这个insert没有很大的逻辑错误,扩容,挪动数据的逻辑都看起来是对的):
void insert(iterator pos, const T& x)
{
assert(pos >= _start && pos <= _finish);
//空间不够就扩容
size_t newCapacity;
if (_finish == _endofstorage)
{
newCapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newCapacity);
}
//挪动数据
iterator end = _finish - 1;
while(end >= pos)
{
*(end + 1) = *end;
--end;
}
//放数据
*pos = x;
++_finish;
}
void test_vector14()
{
bit::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.insert(v.begin(), 0);
for (auto e : v)
{
cout << e << endl;
}
}运行结果是程序崩溃了:
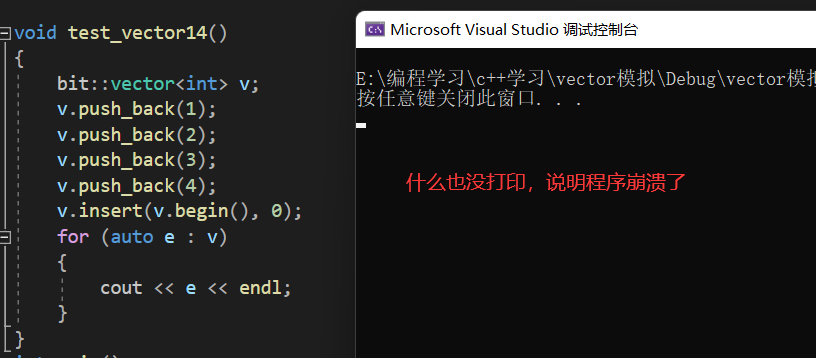
那么错误原因在哪呢?通过调试我们可以看出程序死循环了,因为我们扩容之后,旧空间被释放,pos所指向的空间也被释放了,pos变成了野指针,导致程序在挪动数据的时候发生了死循环,所以在扩容之后,我们要更新pos的值。
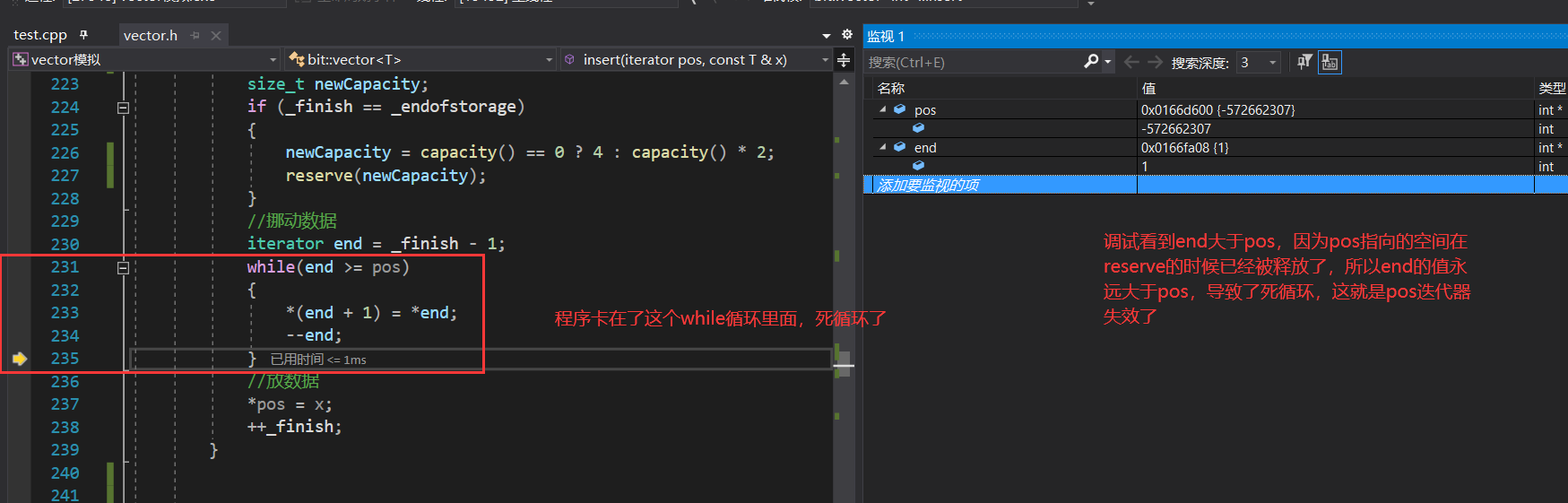
void insert(iterator pos, const T& x)
{
assert(pos >= _start && pos <= _finish);
//空间不够就扩容
size_t newCapacity;
if (_finish == _endofstorage)
{
size_t n = pos - _start;
if (capacity() == 0)
{
newCapacity = 4;
}
else
{
newCapacity = capacity() * 2;
}
reserve(newCapacity);
pos = _start + n;
}
//挪动数据
iterator end = _finish - 1;
while(end >= pos)
{
*(end + 1) = *end;
--end;
}
//放数据
*pos = x;
++_finish;
}运行结果正确,我们成功打印出插入0之后的值
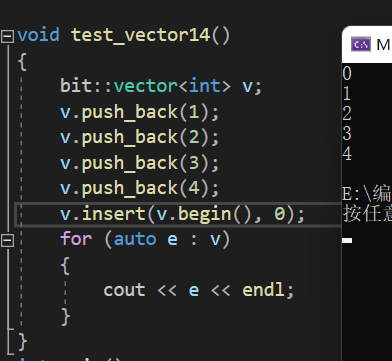
但上面的程序正确吗?其实并不正确,它还存在指针的意义变了引起的失效的问题,我们看下面这段代码:
void test_vector14()
{
//在偶数的后面插入20
bit::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
v.push_back(6);
bit::vector<int>::iterator it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
{
v.insert(it, 20);
}
}
}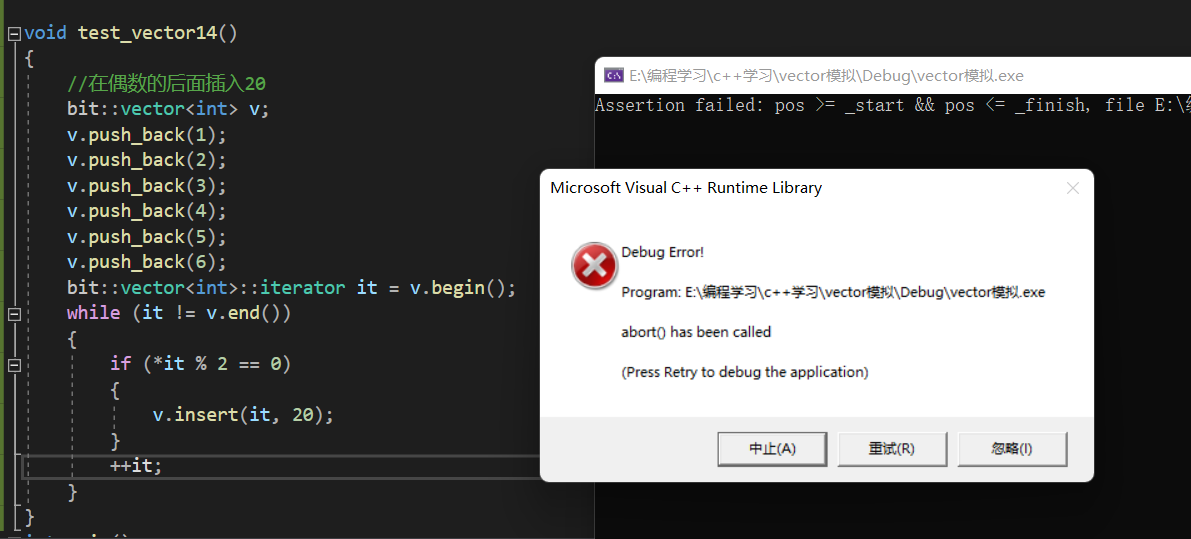
运行以后怎么报错了?报了个断言错误,好奇怪啊,我们通过调试,发现了在插入20之后,pos的位置并不是我们想要的位置了,这就是第二种迭代器失效的情况,那么如何避免呢?这就需要在执行完插入程序之后,更新一下迭代器的位置。
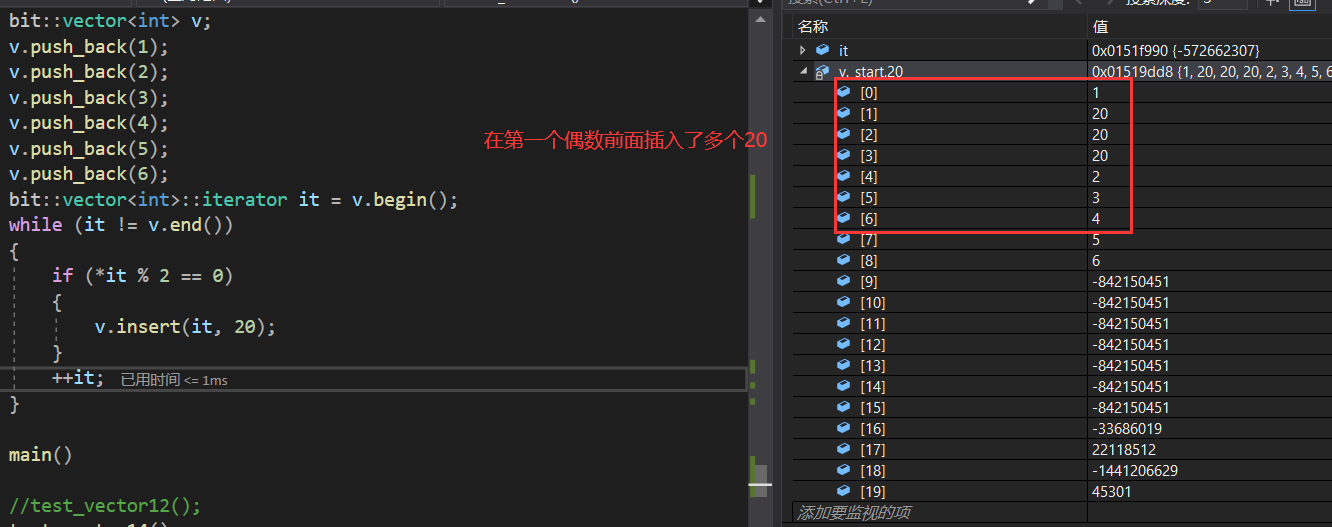
代码如下:
iterator insert(iterator pos, const T& x)
{
assert(pos >= _start && pos <= _finish);
//空间不够就扩容
//扩容以后pos就失效了,需要更新一下
size_t newCapacity;
if (_finish == _endofstorage)
{
size_t n = pos - _start;
if (capacity() == 0)
{
newCapacity = 4;
}
else
{
newCapacity = capacity() * 2;
}
reserve(newCapacity);
pos = _start + n;
}
//挪动数据
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
//放数据
*pos = x;
++_finish;
return pos;
}
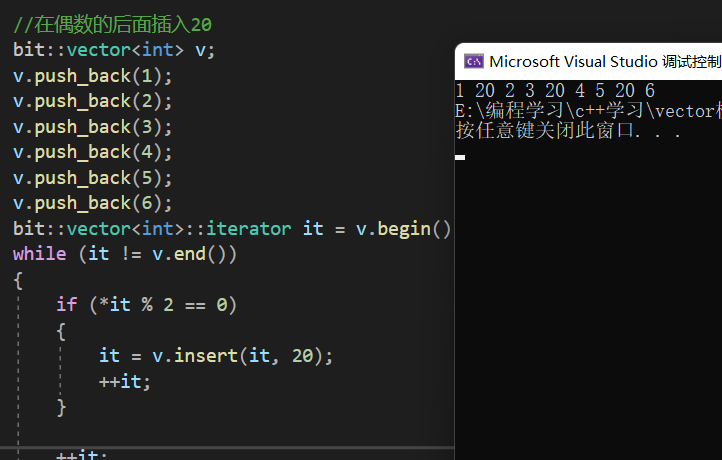
void test_vector14()
{
//在偶数的后面插入20
bit::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
v.push_back(6);
bit::vector<int>::iterator it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
{
it = v.insert(it, 20);
++it;
}
++it;
}
for (auto e : v)
{
cout << e << " ";
}
}
5.2erase的迭代器失效
erase的失效基本上不发生野指针的情况,除非缩容;不缩容,pos就不会失效,缩容了,pos就有失效的风险(缩容可能导致原来vector的底层空间被改变,即可能会有野指针的风险)。erase的失效都是意义变了,或者不在有效访问数据有效范围。一般不会使用缩容的方案,那么erase的失效,一般也不存在野指针的失效。
iterator erase(iterator pos)
{
assert(pos >= _start && pos < _finish);
iterator it = pos + 1;
//挪动数据
while (it !=_finish)
{
*(it - 1) = *it;
++it;
}
--_finish;
return pos;//返回被删除的元素的下一个位置
}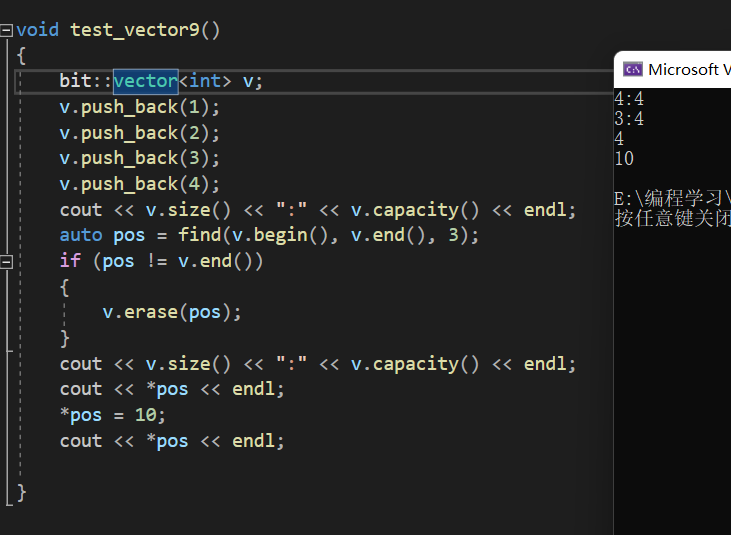
自己写的,没有缩容,所以没有报错。但是用库里面的,即vs环境下的vector,程序崩溃了:
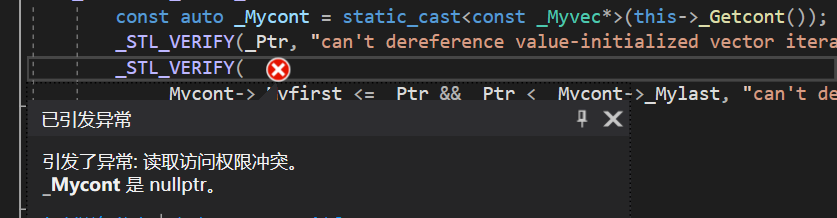
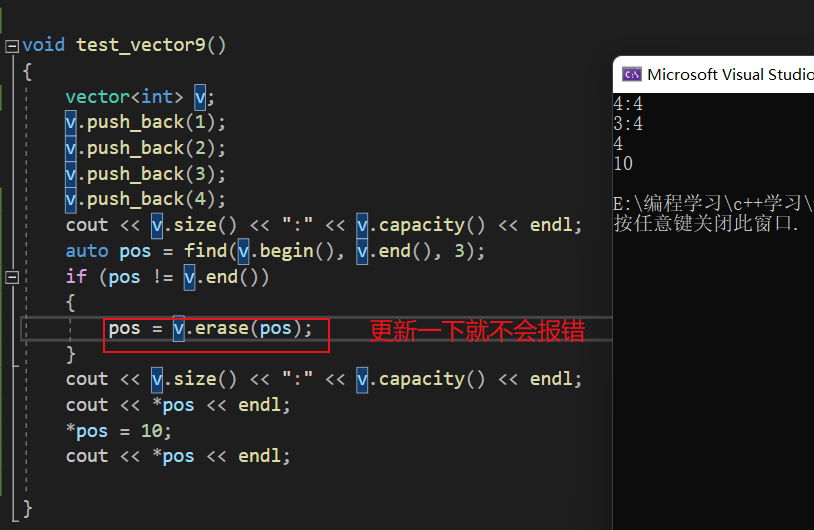
这个地方并没有发生像insert一样的野指针失效,从代码的角度来说它并没有失效,但是vs它也报错了,这是因为vs做了一个强制检查,pos被erase删除后,不可以再进行读写,那么如何让程序不报错呢?只有让pos被删除后再更新一下,才不会报错。
6.深层次的深浅拷贝问题
假设模拟实现的vector中的reserve接口中,使用memcpy进行的拷贝,以下代码会发生什么问题?
//使用memcpy的reserve函数:
void reserve(size_t n)
{
size_t sz = size();
if (n>capacity())
{
T* tmp = new T[n];
if (_start)
{
memcpy(tmp, _start, size() * sizeof(T));
delete[]_start;
}
_start = tmp;
}
_finish = _start + sz;
_endofstorage = _start + n;
}
//以下代码会出现什么问题:
int main()
{
bit::vector<string> v;
v.push_back("1111");
v.push_back("2222");
v.push_back("3333");
v.push_back("4444");
v.push_back("5555");
for (auto e : v)
{
cout << e << endl;
}
return 0;
}程序发生了崩溃 ,原因是什么呢?
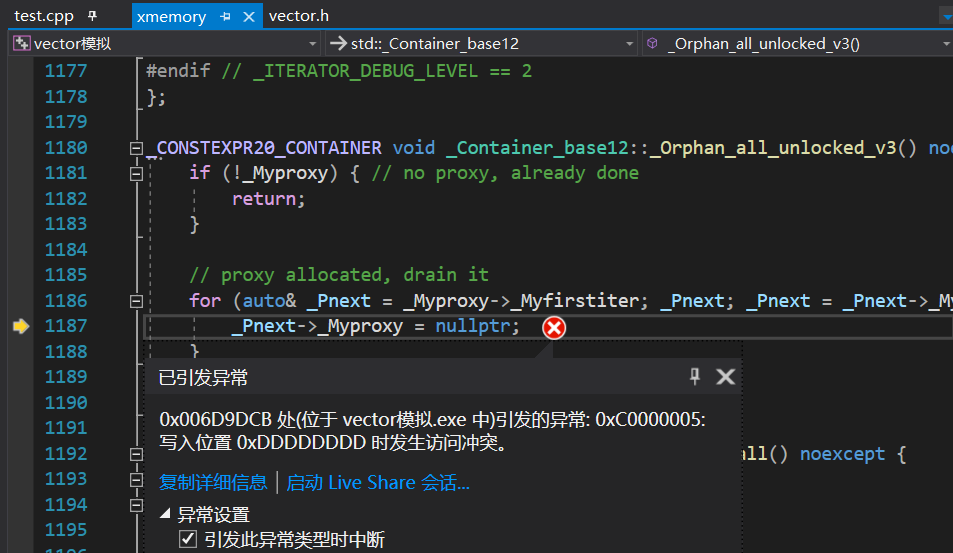
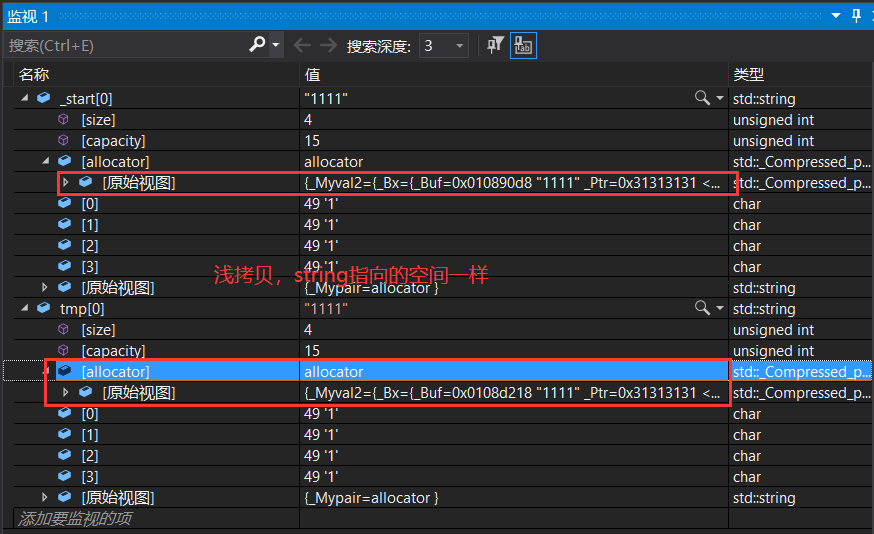
我们通过调试可以看到我们通过memcpy,使得tmp和_start指向了同一片空间,那么在我们创建新空间,释放了旧空间的同时,就把_start所指向的那片空间也释放了,这样使得tmp成为了一个野指针,当程序结束,调用析构函数释放新空间时,相当于访问了野指针,这使得程序崩溃。
所以通过上述现象的分析,我们可以得出结论:
如果拷贝的是内置类型的元素,memcpy既高效又不会出错,但如果拷贝的是自定义类型元素,并且自定义类型元素中涉及到资源管理时,就会出错,因为memcpy的拷贝实际是浅拷贝。所以如果对象中涉及到资源管理时,千万不能使用memcpy进行对象之间的拷贝,因为memcpy是浅拷贝,否则可能会引起内存泄漏甚至程序崩溃。