【数据结构】------ 堆
目录
堆的概念及结构
堆的实现
堆向上调整算法
堆向下调整算法
堆的创建
堆的初始化和销毁
堆的插入
堆的删除
获取堆顶的数据
获取堆的数据个数
堆的判空
TopK问题(在N个数找出最大(小)的前K个)
堆排序
堆的概念及结构
如果有一个关键码的集合K = {k0,k1, k2,…,kn-1},把它的所有元素按完全二叉树的顺序存储方式存储 在一个一维数组中,并满足:Ki = K2i+1 且 Ki >= K2i+2) i = 0,1,2…,则称为 小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
(所有数组都可以表示为完全二叉树,但不一定可以表示为堆)
假设parent是父亲节点在数组中的下标,leftchild=parent*2+1,rightchild=parent*2+2。
假设孩子在数组中的下标是child,不管是左孩子还是右孩子,parent=(child-1)/2。)
堆的性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树。
大堆:树中一个树及子树中,父亲都大于等于孩子。
小堆:树中一个树及子树中,父亲都小于等于孩子。
堆的实现
堆向上调整算法
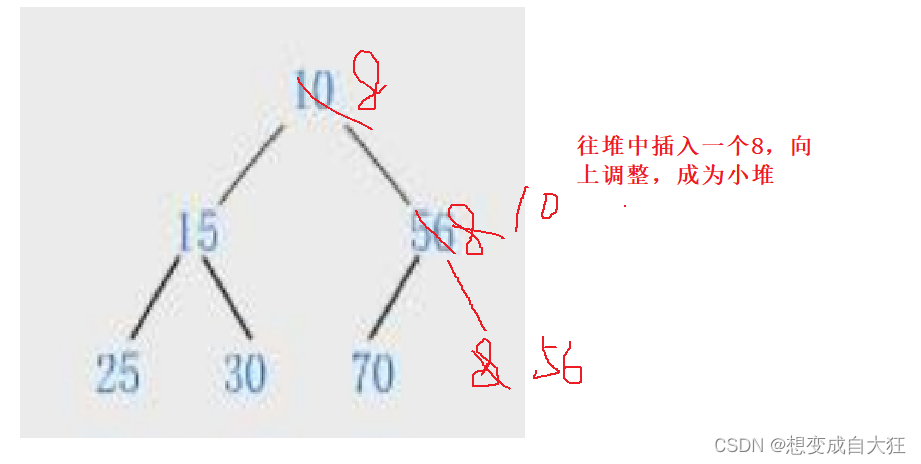
当我们在一个堆的末尾插入一个数据后,需要对堆进行调整,使其仍然是一个堆,这时需要用到堆的向上调整算法。
向上调整算法的基本思想(以建小堆为例):
1.将目标结点与其父结点比较。
2.若目标结点的值比其父结点的值小,则交换目标结点与其父结点的位置,并将原目标结点的父 结点当作新的目标结点继续进行向上调整。若目标结点的值比其父结点的值大,或者已经调整 到了根节点,则停止调整,此时该树已经是小堆了。
void Swap(HPDataType* px, HPDataType* py)
{
HPDataType tmp = *px;
*px = *py;
*py = tmp;
}
void AdjustUp(int* a,int child)
{
int parent = (child - 1) / 2;
//while (parent > 0)
//parent =0 ---恒成立,循环是通过beak跳出去的,不符合要求,但是能达到想要的效果
while (child > 0)
{
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;//负数除2 parent=0
}
else
{
break;
}
}
}堆向下调整算法
现在我们给出一个数组,逻辑上看做一颗完全二叉树。我们通过从根节点开始的向下调整算法可以把它调整成一个小堆。向下调整算法有一个前提:左右子树必须是一个堆,才能调整。
向下调整为小堆,那么根结点的左右子树必须都为小堆。
向下调整为大堆,那么根结点的左右子树必须都为大堆。
向下调整为小堆示意图:
int a[] = {27,15,19,18,28,34,65,49,25,37};

void Swap(HPDataType* px, HPDataType* py)
{
HPDataType tmp = *px;
*px = *py;
*py = tmp;
}
void AdjustDown(HPDataType* a, int n, int parent)
{
int child = 2 * parent + 1;
//调整结束条件:
//父亲 <= 小的孩子,停止
//调整到叶子节点(叶子节点没有孩子,左孩子下标超出数组范围,则是调整到叶子节点)
while (child < n)
{
//选出左右孩子小的那一个(小堆)
if (child + 1 < n && a[child + 1] < a[child])//右孩子可能不存在
{
++child;
}
//如果小的孩子小于父亲,则交换,并继续向下调整(小堆)
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}使用堆的向下调整算法,最坏的情况下(即一直需要交换结点),需要循环的次数为:h - 1次(h为树的高度)。而h = log2(N+1)(N为树的总结点数)。所以堆的向下调整算法的时间复杂度为:O(logN) 。
堆的创建
下面我们给出一个数组,这个数组逻辑上可以看做一颗完全二叉树,但是还不是一个堆,现在我们通过算法,把它构建成一个堆。根节点左右子树不是堆,我们怎么调整呢?
int a[] = {1,5,3,8,7,6};
这里我们从倒数的第一个非叶子节点的子树开始调整,一直调整到根节点的树,就可以调整成堆。
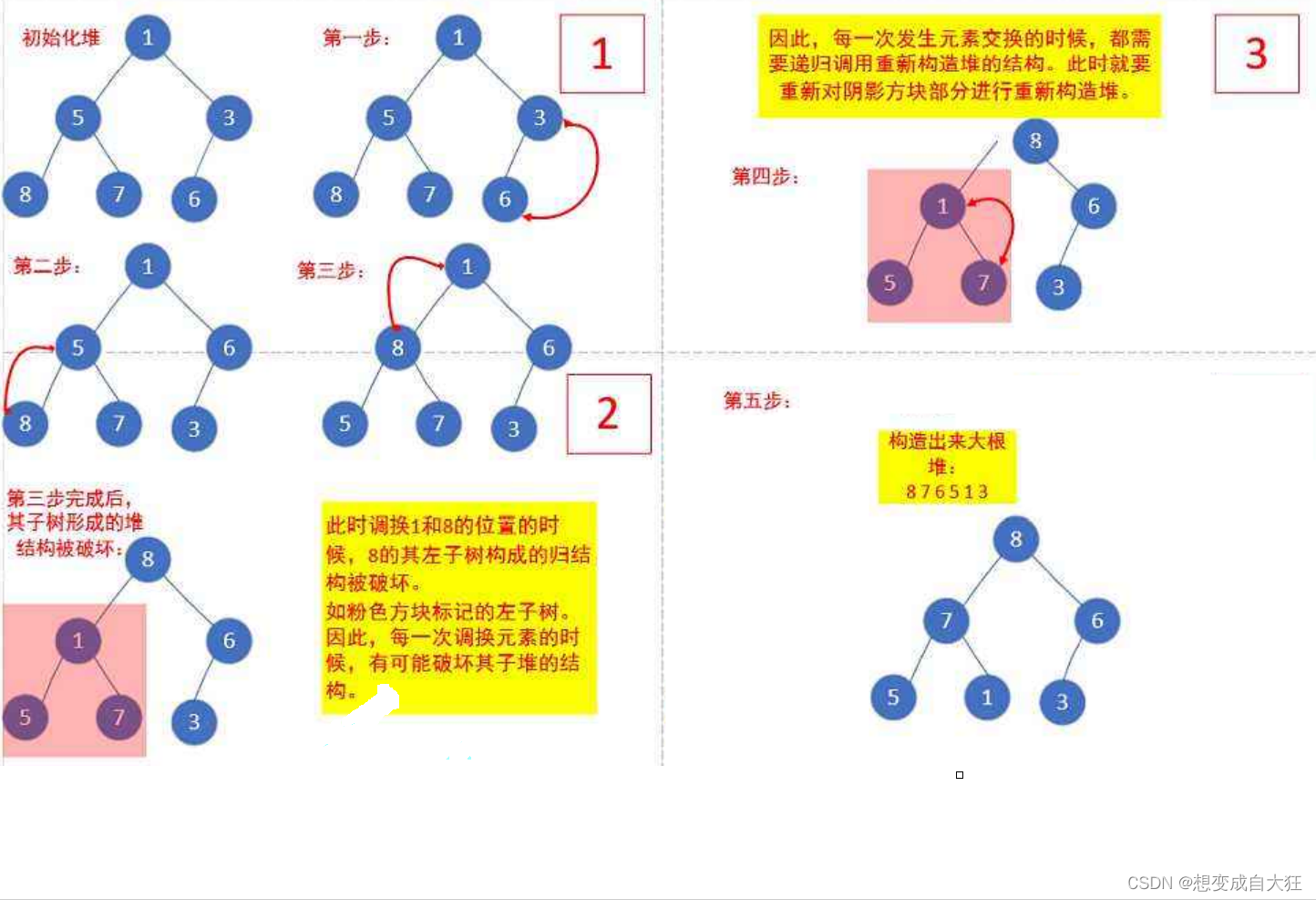
倒数的第一个是最后一个节点的父亲
child=parent*2+1
parent=(child-1)/2
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}建堆的时间复杂度:O(N)
堆的初始化和销毁
堆的结构:
typedef int HPDataType;//堆的数据类型
typedef struct Heap
{
HPDataType* a;//数组--存储堆
int size; //堆中数据的个数
int capacity;//数组的容量
}HP;构建一个堆首先对结构进行初始化,使用完堆后要进行销毁(为了避免内存泄漏,使用完动态开辟的内存空间后都要及时释放该空间)
void HeapInit(HP* hp)
{
assert(hp);
hp->a = NULL;
hp->size = hp->capacity = 0;
}
void HeapDestory(HP* hp)
{
assert(hp);
free(hp->a);
hp->size = hp->capacity = 0;
}
//打印堆中的数据
void HeapPrint(HP* hp)
{
assert(hp);
for (int i = 0; i < hp->size; i++)
{
printf("%d ",hp->a[i]);
}
printf("\n");
}堆的插入
在堆的末尾插入数据,向上调整成为小堆(大堆)
void HeapPush(HP* hp, HPDataType x)
{
assert(hp);
if (hp->size == hp->capacity)
{
size_t newcapacity = hp->capacity == 0 ? 4 : hp->capacity * 2;
HPDataType* tmp = (HPDataType*)realloc(hp->a, sizeof(HPDataType)*newcapacity);
if (tmp == NULL)
{
printf("realloc fail\n");
exit(-1);
}
hp->a = tmp;
hp->capacity = newcapacity;
}
hp->a[hp->size] = x;
hp->size++;
//向上调整
AdjustUp(hp->a, hp->size - 1);
}堆的删除
删除堆是删除堆顶的数据,将堆顶的数据和最后一个数据一换,然后删除数组最后一个数据,再进行向下调整算法。
//删除堆顶的数据
void HeapPop(HP* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
Swap(&hp->a[0], &hp->a[hp->size - 1]);
hp->size--;
AdjustDown(hp->a, hp->size, 0);
}获取堆顶的数据
HPDataType HeapTop(HP* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
return hp->a[0];
}获取堆的数据个数
int HeapSize(HP* hp)
{
assert(hp);
return hp->size;
}堆的判空
bool HeapEmpty(HP* hp)
{
assert(hp);
return hp->size == 0;
}
TopK问题(在N个数找出最大(小)的前K个)
例:
1000个数找出最大的前10个
方式一:先排降序,前十个就是最大的。时间复杂度:O(N+logN*K),排序方法可用快排,归并等。
方式二:N个数依次插入大堆(时间复杂度:N),Pop K次,每次取堆顶的数据,就是前K个。时间复杂度:O(N+logN*K)
方式三:假设N非常大,N是十亿,内存中存不下这些数,他们存在文件中,K是100。这时方式一和方式二都不能用了。
1.用前K个数建立一个K个数的小堆。
2.剩下的N-K个数,依次跟堆顶的数据进行比较,如果比堆顶数据大,就替换堆顶的数据,再向下调整。
3.最后堆里面K个数就是最大的K个数。时间复杂度:K+(N-K)logK ----> O(N*logK)
方式三代码:
//Topk问题
void PrintTopK(int* a, int n, int k)
{
HP hp;
HeapInit(&hp);
//前K个数建立小堆
for (int i = 0; i < k; i++)
{
HeapPush(&hp, a[i]);
}
//N-K 个数依次和堆顶的数据比较
for (int i = k; i < n; i++)
{
if (a[i] > HeapTop(&hp))
{
HeapPop(&hp);
HeapPush(&hp, a[i]);
//hp.a[0] = a[i];
//AdjustDown(hp.a,hp.size,0);
}
}
HeapPrint(&hp);
HeapDestory(&hp);
}堆排序
排升序构建大堆。
排降序构建小堆
堆排序(升序)
1.构建大堆,选出最大的数
2.将第一个数与最后一个数交换
3.将调整后的最后一个数不看成堆里面的数据,向上调整,找出次小的数,将次小的数和最后一个数交换(此时最后一个数实际上是第n-1个数)
4.以此类推,最后堆里面的数据就是升序的了。
void HeapSort(int* a,int n)
{
//构建大堆(向上调整,从第二个节点开始)
/*for (int i = 1; i < n; i++)
{
AdjustUp(a, i);
}*/
//构建大堆(向下调整,从最后一个非叶子节点,最后一个非叶子节点是最后一个节点的父亲)
for (int i = (n - 1 -1)/2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
//依次选数,调堆
for (int end = n - 1; end > 0; end--)
{
Swap(&a[end], &a[0]);
//再调堆,选出次小的数
AdjustDown(a, end, 0);
}
}