Hive的表操作3
Hive系列
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下Hive的表操作
#博学谷IT学习技术支持
文章目录
- Hive系列
- 前言
- 一、Hive表数据的插入方式
- 二、Hive表数据导出
- 三、Hive表的查询-基本查询
- 1、普通查询
- 2、join查询
- 3、排序查询
- 总结
前言

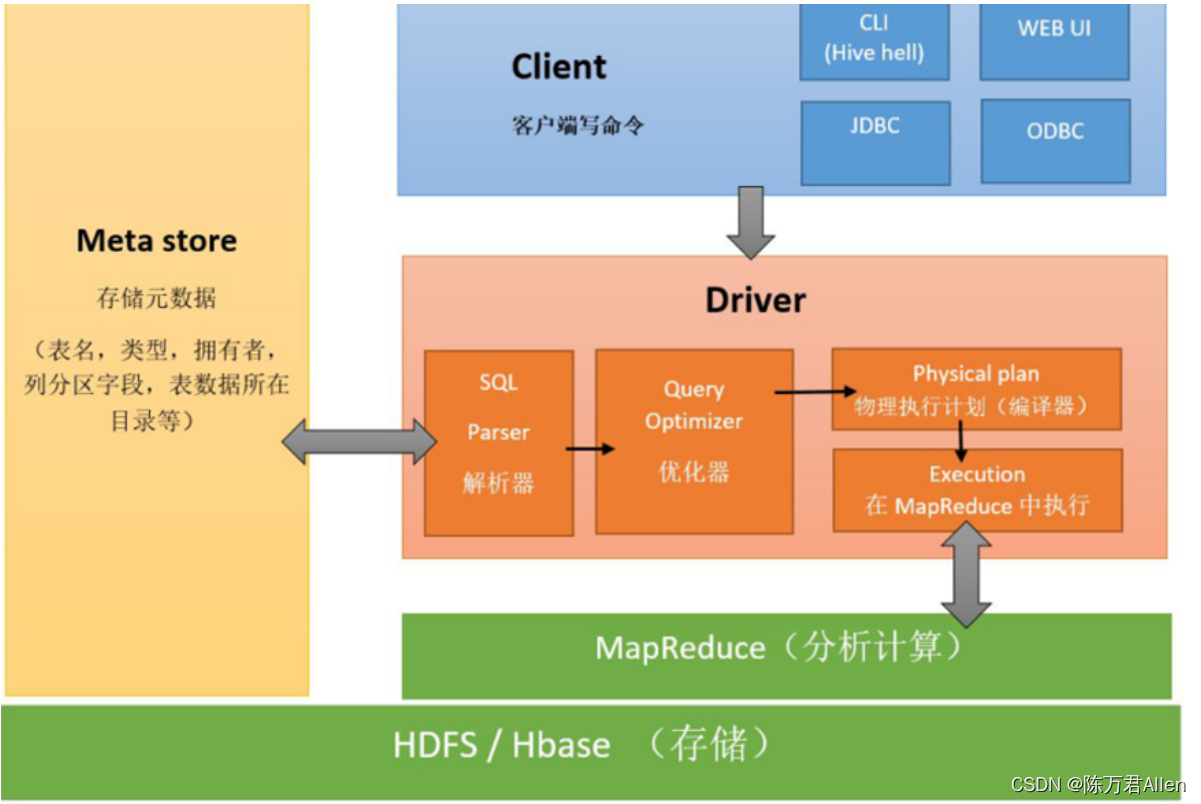
1、Hive是数仓管理工具,用来管理数仓
2、Hive可以将数仓存在HDFS上的文件变成一张张的表
3、Hive提供一种HiveSQL可以表进行分析处理
4、HiveSQL底层默认是MapReduce,以后可以换成其他的引擎(Spark),我们写HiveSQL会去匹配底层的MR模板,匹配上则执行,否则不能执行
一、Hive表数据的插入方式
1、方式1:
insert into table score3 partition(dt ='2022-10-01') values ('001','002',100);
2、方式2 -(重要)
insert overwrite table score4 partition(dt ='2022-10-01')
select sid,cid,sscore from score;
3、方式3 -(重要)
load data local inpath '/export/data/hivedatas/score.txt' overwrite into table score5 partition(dt ='2022-10-01');
4、方式4
create table score5 as select * from score;
5、方式5 -(重要)
create external table score6 (sid string,cid string,sscore int) row format delimited fields terminated by '\t' location '/myscore6';
6、方式6
hadoop fs -put stu.txt /user/hive/warehouse/myhive.db/stu
7、方式7 -(重要)
sqoop框架将数据直接导入hive
二、Hive表数据导出
-- 将sql查询的结果导出到本地磁盘
insert overwrite local directory '/export/data/exporthive'
row format delimited fields terminated by '\t'
select * from score where sscore > 85;
-- 将sql查询的结果导出到HDFS —(重要)
insert overwrite directory '/export/data/exporthive'
row format delimited fields terminated by '\t'
select * from score where sscore > 85;
-- 将Hive -e 命令的执行结果导出本地目录文件
hive -e "select * from myhive.score;" > /export/data/exporthive/score.txt
-- 将一张表的数据全部导出到HDFS
export table score to '/export/exporthive/score';
三、Hive表的查询-基本查询
和其他SQL语句差不多
1、普通查询
1、聚合函数对null的态度
create table test11(
id int,
score int
);
insert into test11 values (1,50);
insert into test11 values (2,50);
insert into test11 values (3,null);
insert into test11 values (4,50);
select * from test11;
select sum(score) from test11; // 150
select avg(score) from test11; // 150 / 3
select avg(if(score is null, 0, score)) from test11; // 150 / 4
select avg(coalesce(score,0)) from test11; // 150 / 4
2、limit关键字
select * from student limit 3;
select * from student limit 2,3; --从索引为2(从0开始)显示,显示3行
3、where条件查询
select * from score where sscore not in(80,90); -- 成绩不是80或者90
select * from score where not sscore in(80,90);-- 成绩不是80或者90
4、like关键字
select * from student where sname like '赵%'; -- 姓赵的
select * from student where sname like '%雷'; -- 名字最后一个字是 雷
select * from student where sname like '%雷%'; -- 名字中包含 雷
select * from student where sname like '_雷%'; -- 名字第二个字是 雷\
5、分组-group by
-- 分组之后每一组只剩下一条数据,所以select后边只能跟分组字段和聚合函数
select sid, sum(sscore) from score group by sid;
-- 分组之后的条件筛选是having,不是where
select sid, sum(sscore) as total_score from score group by sid having total_score > 450
2、join查询
-- 1、内连接:求交集
select * from teacher;
insert into teacher values ('04','赵六');
select * from teacher inner join course c on teacher.tid = c.tid;
select * from teacher join course c on teacher.tid = c.tid;
select * from teacher , course where teacher.tid = course.tid;
-- 2、左外连接
-- 左外是以左表为主,把左表的数据全部输出,右表有对应的数据就输出,没有对应的数据就输出NULL
select * from teacher left join course c on teacher.tid = c.tid;
-- 3、右外连接
select * from course;
insert into course values ('04','政治','05');
-- 右外是以右表为主,把右表的数据全部输出,左表有对应的数据就输出,没有对应的数据就输出NULL
select * from teacher right join course c on teacher.tid = c.tid;
-- 4、满外连接
-- 查询左外连接和右外连接的并集
select * from teacher full join course c on teacher.tid = c.tid;
3、排序查询
-- 1.order by
1、order by 用于全局排序,要求只能有一个Reduce
2、如果有多个Reduce,则不能使用order by
3、order by 的使用方法和MySQL是一样的
select * from score order by sscore ; -- 升序排序
select * from score order by sscore desc; -- 降序排序
-- 2.sort by
1、 sort by 会做两件事情:
1)会将表文件拆分成多个文件(默认的分区)
2)保证每一个输出的文件内容都有序
1)设置reduce个数
set mapreduce.job.reduces=3;
2)查询成绩按照成绩降序排列
select * from score sort by sscore;
3)将查询结果导入到文件中(按照成绩降序排列)
insert overwrite local directory '/export/data/exporthive/sort' select * from score sort by sscore;
-- 3.distributed by + sort by
1、distributed by 会按照某个字段进行分区,sort by 会给每个分区的数据进行排序
1)设置reduce的个数,将我们对应的sid划分到对应的reduce当中去
set mapreduce.job.reduces=7;
2)通过distribute by进行数据的分区
insert overwrite local directory '/export/data/exporthive/distribute' select * from score distribute by sid sort by sscore;
-- 4.cluster by
1、当distributed by 和 sort by字段相同时:cluster by 等价于 distributed by + sort by
cluster by id => distributed by id sort by id
2、当reduce个数 < id的个数时,排序有意义
id有100个 rduce 100个
set mapreduce.job.reduces=2;
insert overwrite local directory '/export/data/exporthive/cluster_by'
select * from score cluster by sid;
总结
今天继续和大家分享一下Hive的表操作3。