python数据分析及可视化(八)pandas数据规整(层级索引、数据重塑、数据合并、数据连接)
层级索引
分层索引是pandas的一个重要特性,允许在一个轴上拥有多个索引层级,层级索引一般用于数据重塑和分组操作。
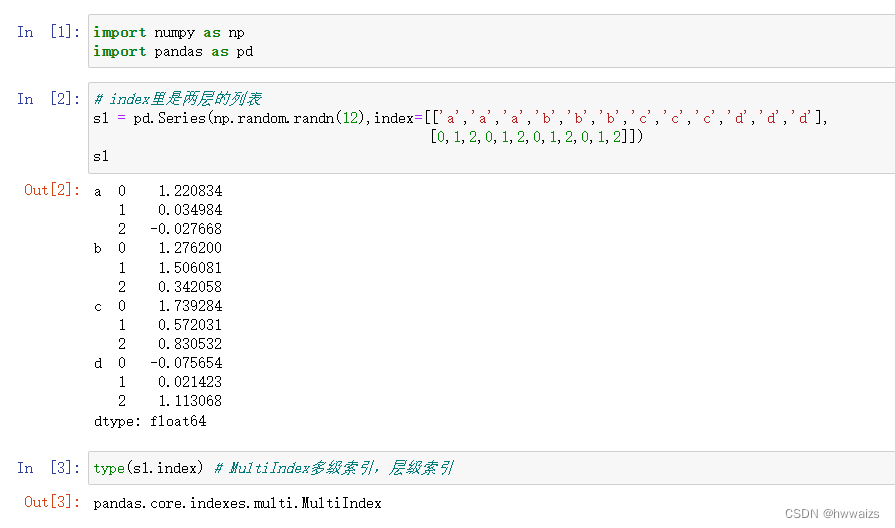
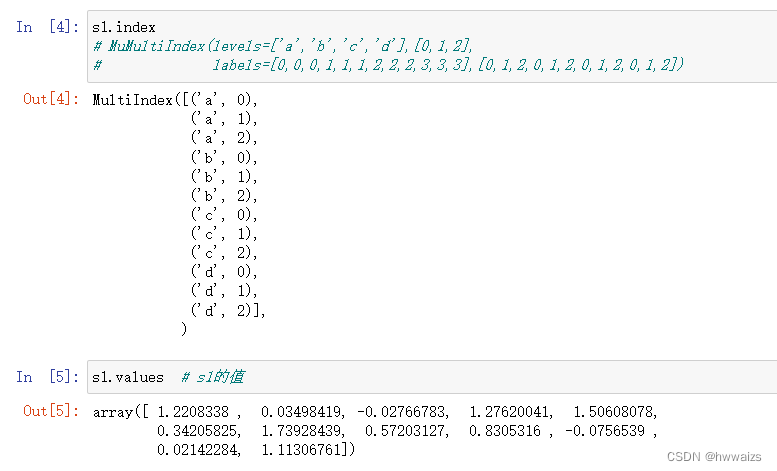
index里是一个两层的列表,得到的Series对象为两层索引,这种就是层级索引,通常见到的Series只有键和值两列。multiIndex表示多级索引,用index去查询,可以看到levels表示两个层级中分别有那些标签(两层索引,外层是a,b,c,内层是0,1,2);labels是每个位置分别是什么标签(外层是a的索引0,0,0,内层是对应的0,1,2),在levlels里外层的三个0相当于外层a的索引,内层的0,1,2是a的三个值。就好比a,b,c,d相当于四个班级,0,1,2代表班级的前三名,每个班都会有前三名。
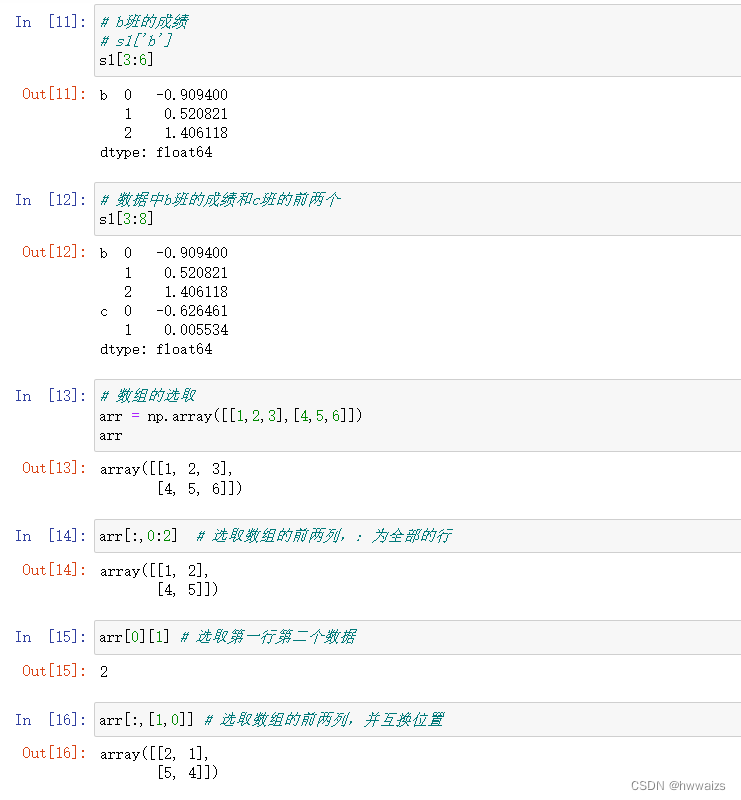
拥有层级索引的Series对象,正常的数据选取的操作示例,通过与数组操作的对比,选取了单个班级的单个成绩和多个成绩,以及多个班级的单个成绩和多个成绩。

交换内外层索引
拥有层级索引的Series对象具备的方法
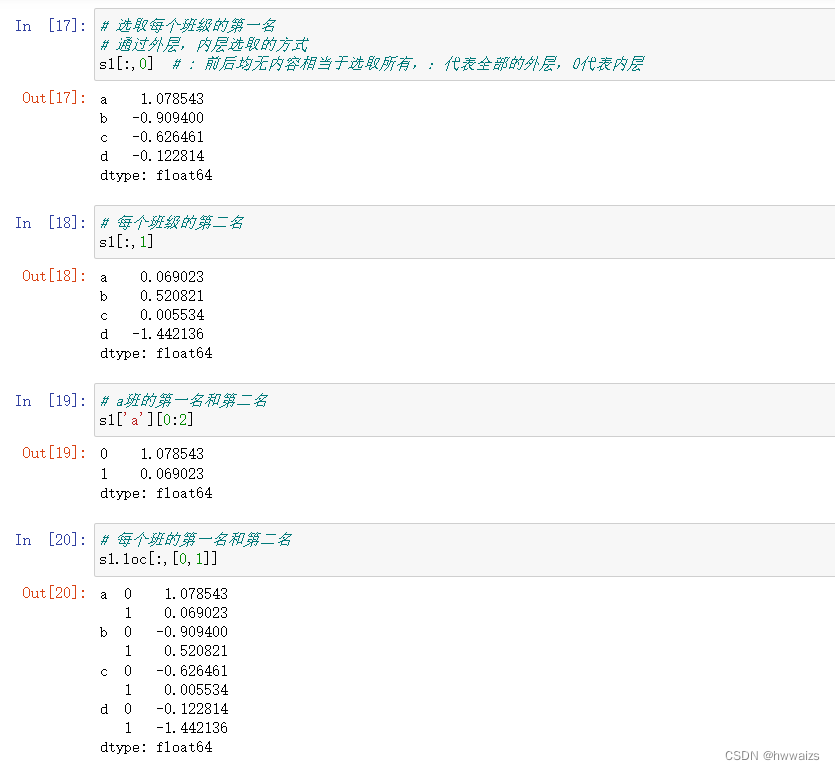
1.交换层级索引的内外层。a,b,c,d为外层索引,0、1、2为内层索引,对它们进行交换。

数据重塑
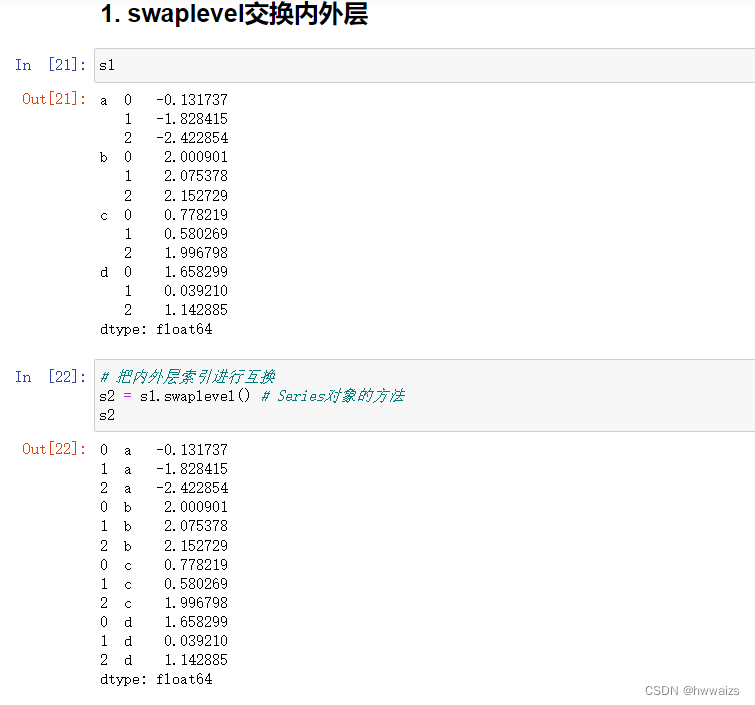
unstack(),将拥有层级索引的Series转换为Dataframe,外层索引作为行索引,内层索引作为列索引
stack(),将Dataframe转换为拥有层级索引的Series
两种方法可以交替使用,可以实现把每个班的第一名、第二名、第三名分别进行排列。

sortlevel()排序
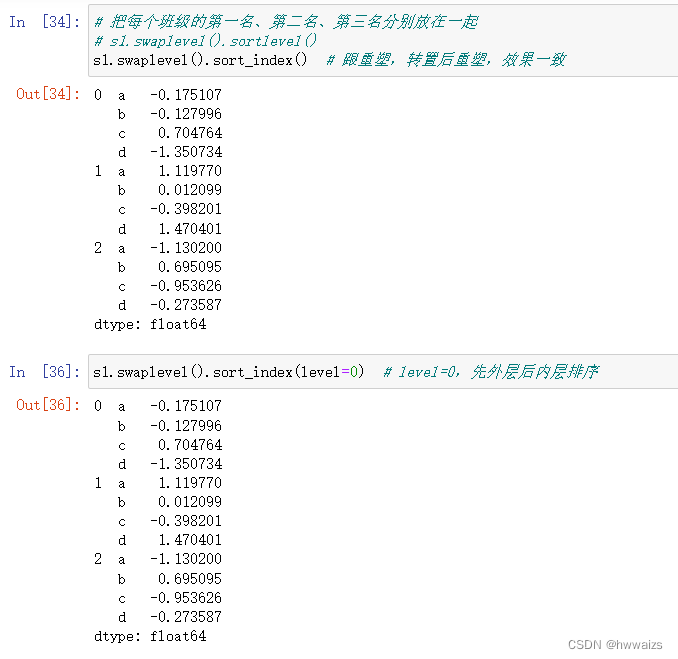
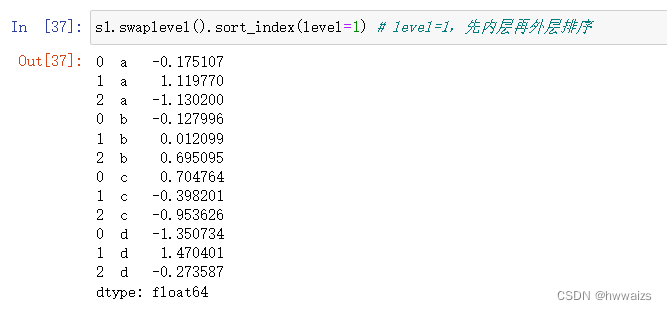
s1.swaplevel().sort_index(level=),level=0先排外层,然后排内层;level=1先排内层再排外层。
数据合并
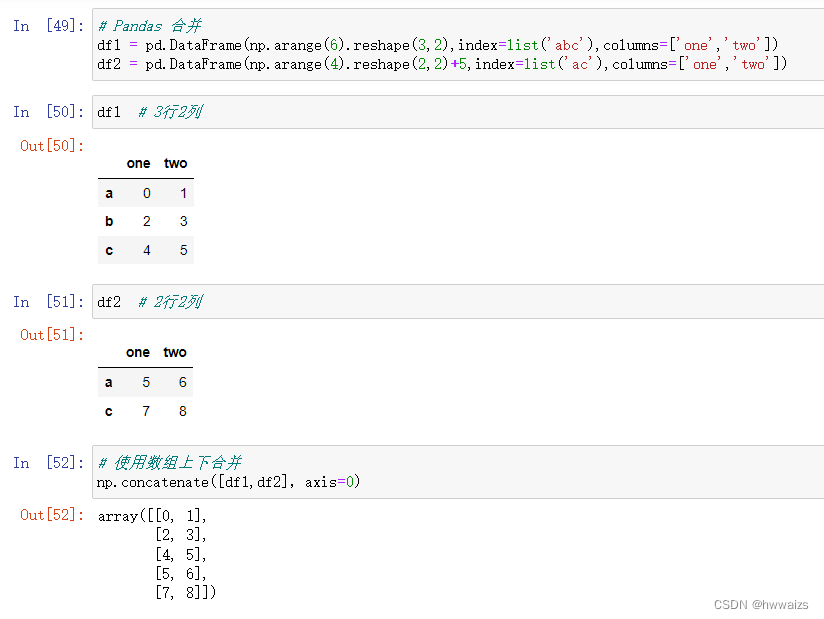
数组合并时,左右合并必须保证行数相同;列数和列名称相同可以进行上下合并。

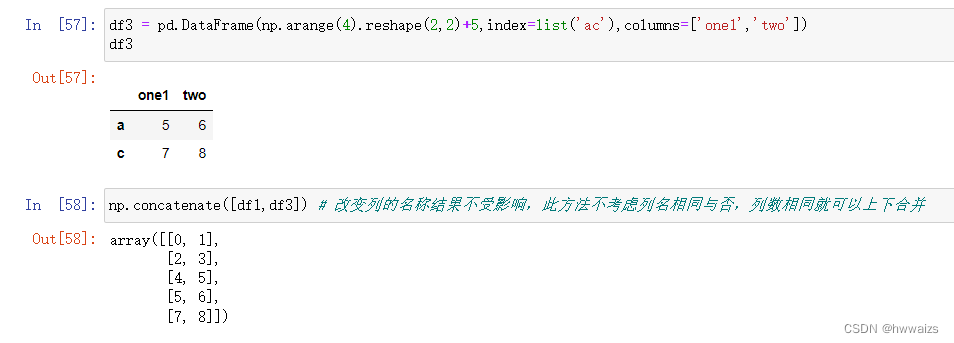
np.concatenate() , 改变列的名称结果不受影响,此方法不考虑列名相同与否,列数相同就可以上下合并,只关心值的部分。
合并数据的方法
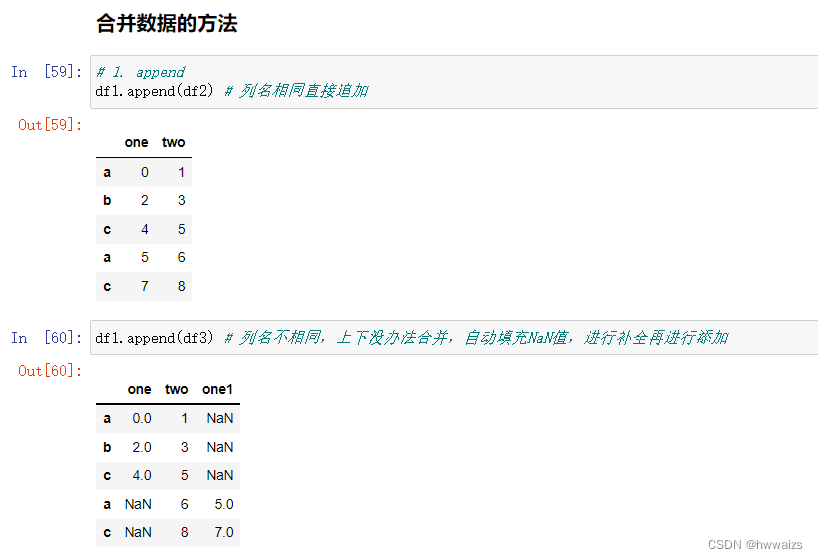
1.append
列名相同,直接进行合并;列名称不相同,没办法进行上下合并,自动填充NaN值进行补全。
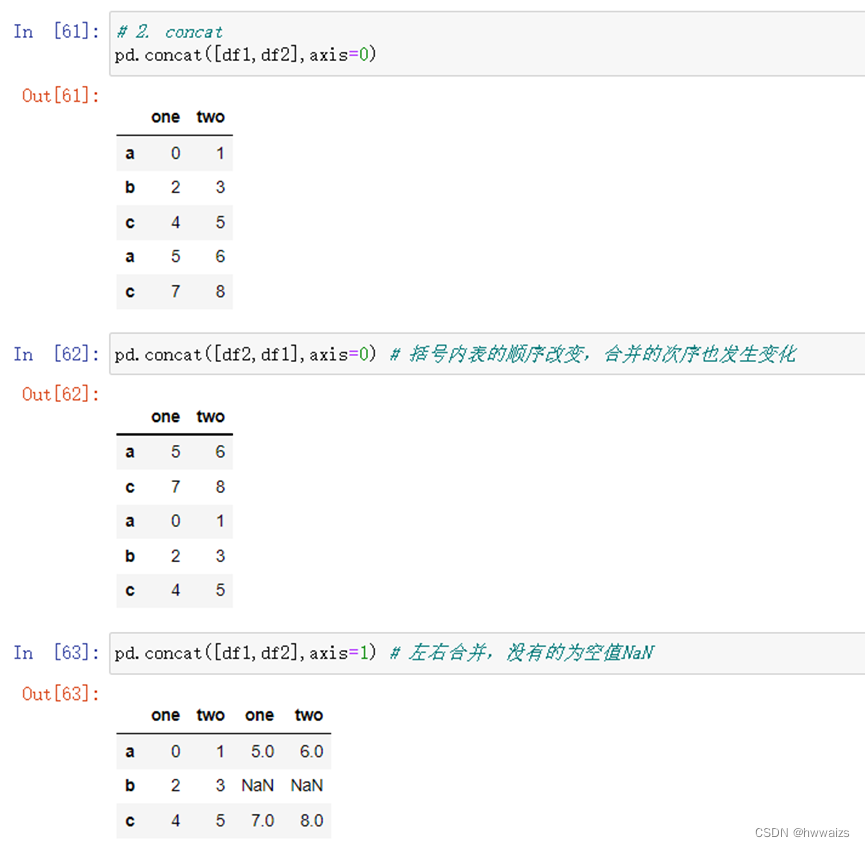
2.concat
括号内的表的顺序不同,合并的次序就不同。
数据连接
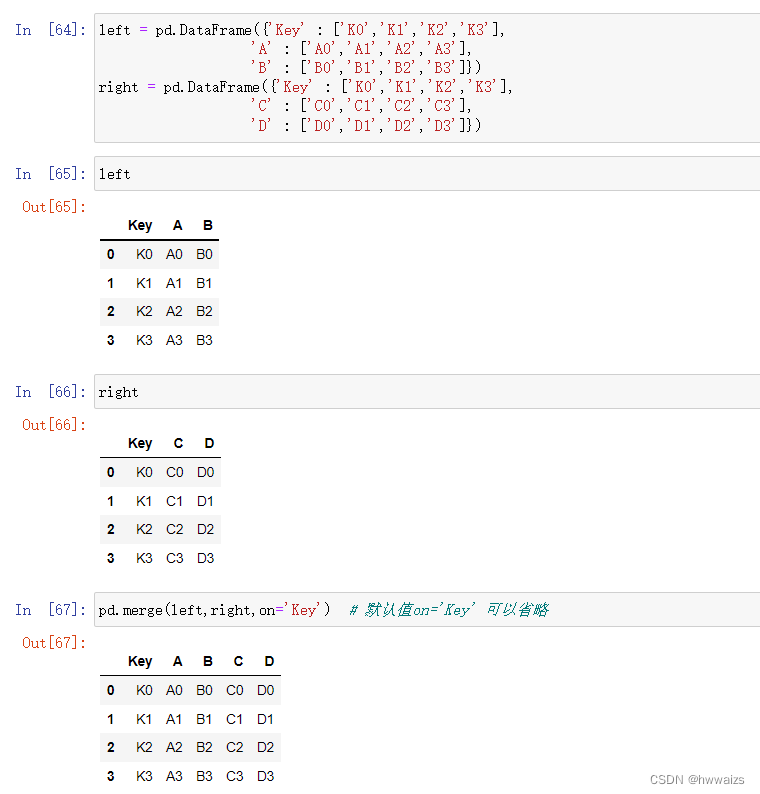
pd.merge
需要一个连接键,数据连接的桥梁,也即是相同的key值,按照连接键进行合并。通常会找两张表中列名称相同的列作为连接键。
内连接
当有两列数据相同,进行合并的时候,默认是求两个表的交集.
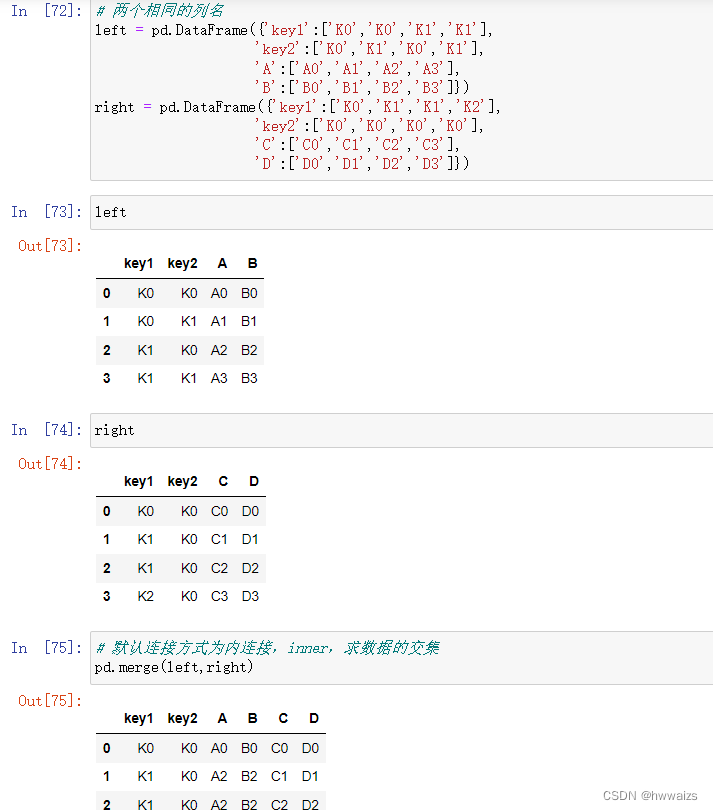
默认情况下,两个表进行连接的时候,相当于内连接,求两个表数据的交集。在上述表中,有key1,key2两列的列名称相同,在进行连接的时候,key1,key2作为一个整体,在left表中,key1和key2的第一行K0,K0与right表key1,key2第一行的K0,K0相同,进行连接,得到 K0,K0,A0,B0,C0,D0;然后再找right表key1,key2中有没有K0,K0,有的话继续连接,没有的话就进行left表第二行的判断;left表key1,key2的第二行K0,K1,在right表key1,key2中从上到下没有相同的数据,所以没有连接的数据;left表key1,key2第三行K1,K0,在right表key1,key2的第二行、第三行均由与K1,K0相同的数据,分别进行连接;left表key1,key2的第四行K1,K1与right表没有相同的key1,key2值匹配,所以就不能进行连接。
外连接
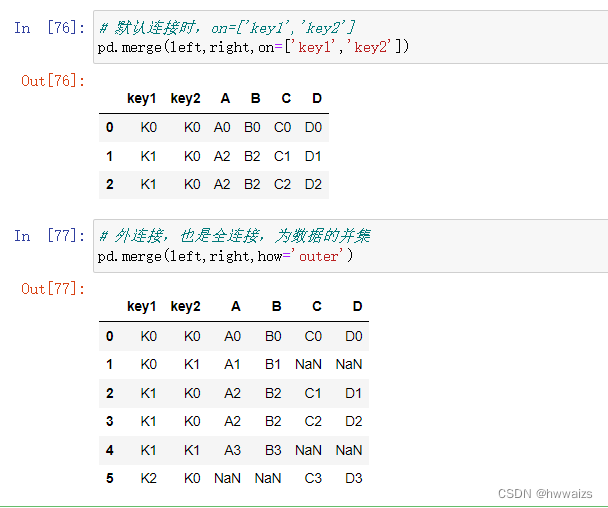
也可以指定参数,把两个表进行外连接,求两个表的交集。在上述连接中,指定连接方式为“how=‘outer’”,两个表进行连接时,key1,key2作为整体,left表的key1和key2的第一行K0,K0与right表key1,key2第一行的K0,K0相同,进行连接,得到 K0,K0,A0,B0,C0,D0,right表中key1,key2里中没有K0,K0,left表的第一行就不再与ringht表进行连接;left表key1,key2列第二行key的值为K0,K1,在right表中没有与之相同的key值,用NaN进行填充,则第二行的连接结果就为:K0,K1,A1,B1,NaN,NaN;left表的第三行连接方法同内连接一样;left表的第四行连接方法同第二行一样;left表连接完成后,right表key1,key2的第四行还没有参与连接,key1,key2的值在left表中没有找到相同的值,所以最后一行的连接为,K2,K0,NaN,NaN,C3,D3。
左连接
左连接,指的是以左边的表为主,进行连接的方式。
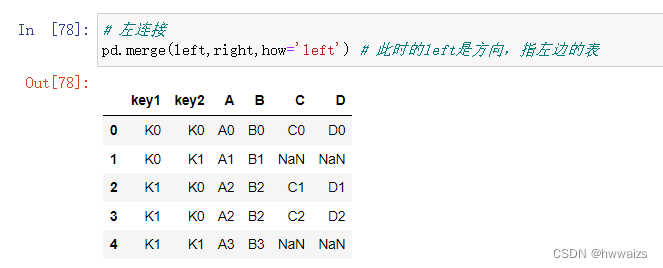
连接时以左边的表为主,可以看到,在左边表出现过的key,在结果中都会出现。第一行两个表key值相同,进行正常的连接;左边的left表第二行的key在right表中没有相同的值,用NaN进行填充;第三行同之前的连接方式一样,与right表的两行进行连接,第四行的key值在right表中没有相同的值,用NaN进行填充。
右连接

连接的原则同左连接类似,只要是在右边表中出现的key值,在结果中都可以得到。
指定连接值
左边的表以key1作为连接键,右边的表以key2作为连接键。

指定左边表的key1和右边表的key2作为连接键,在左边的left表中key1的值为K0,K0,K1,K1,在右边的right表的key2的值为K0,K0,K0,K0,左边表中的K1在右边表中没有出现,不能进行连接,两张表的连接方式为:left表第一行的key1值为K0,right表的key2值均为K0,则left表的第一行与right表的每一行进行连接;left表的第二行同样的连接方法;left表的第三、四行为K1,在right表中没有,则不进行连接。
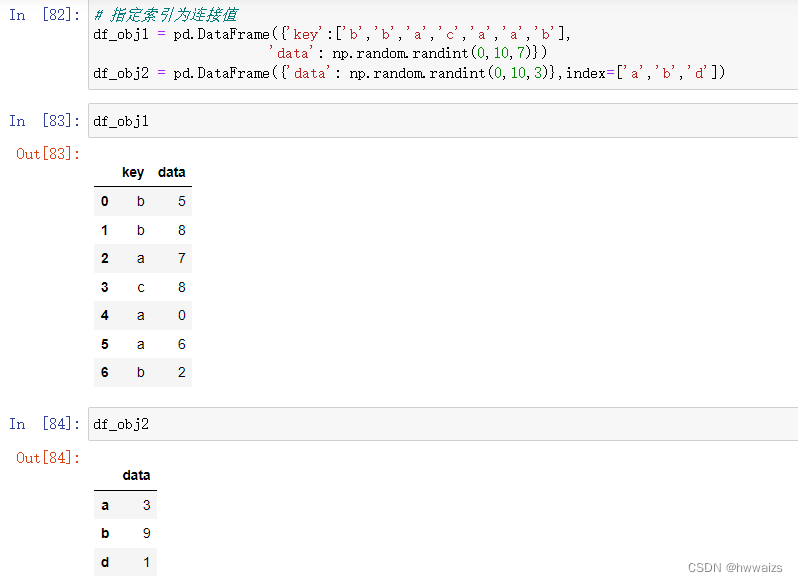
指定索引值为连接值
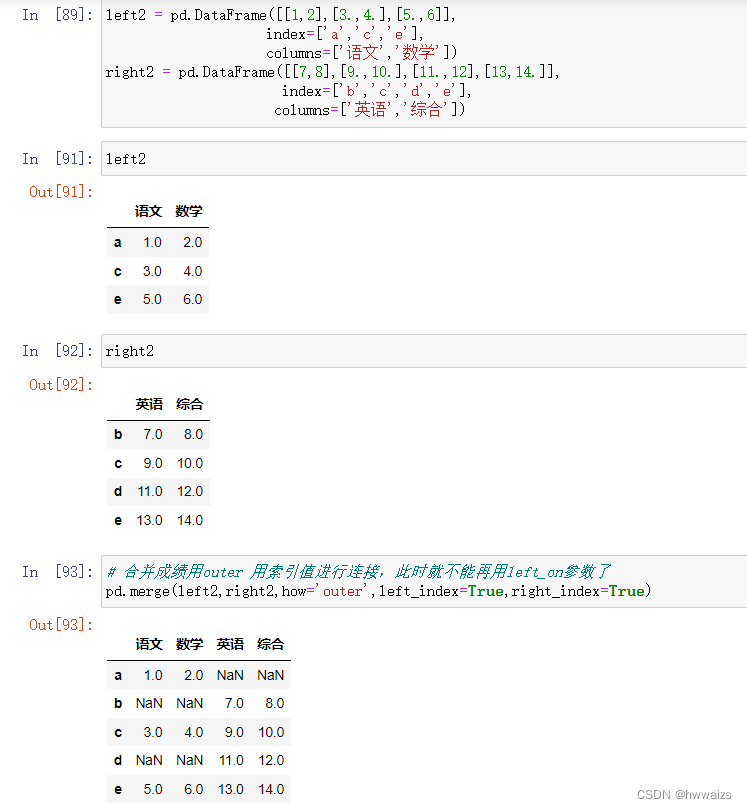
两张表的行数和列数均不相同,指定左边表的key和右边表的索引作为连接。
right_index=True,用右侧表的索引作为连接值
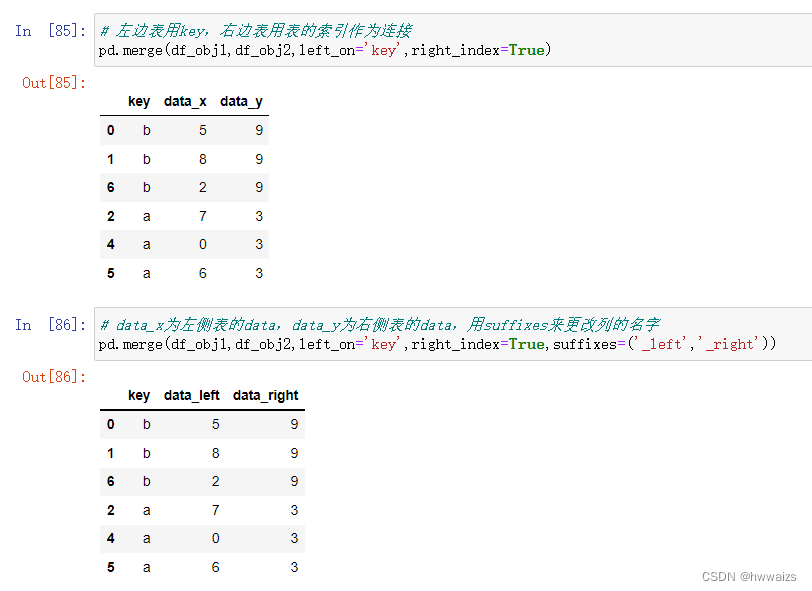
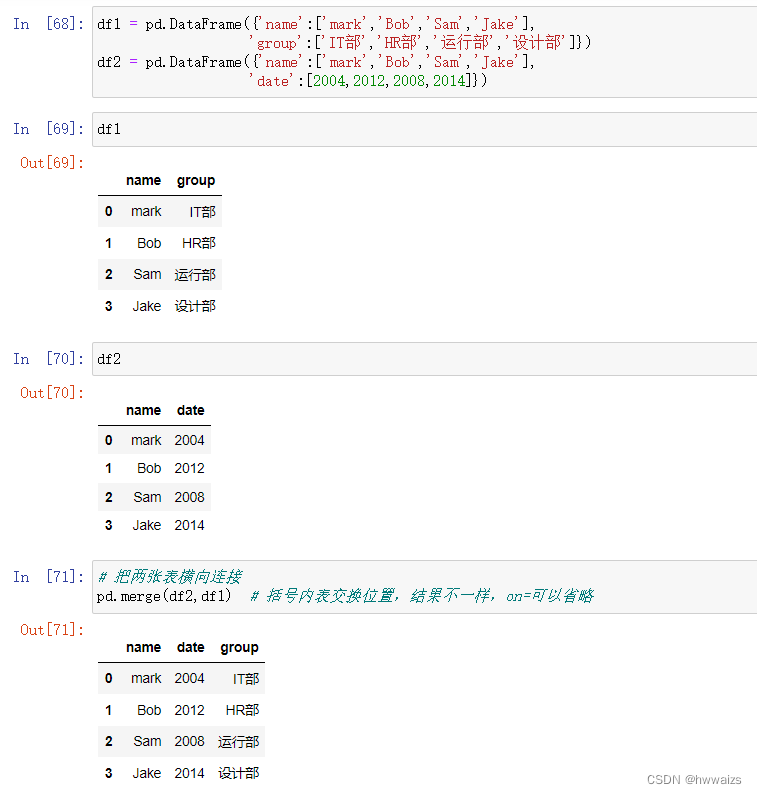
数据连接方式跟之前的一致。data_x指的是左侧表的data,data_y指的是右侧表的data,也可以用suffixes更改显示的列名称。
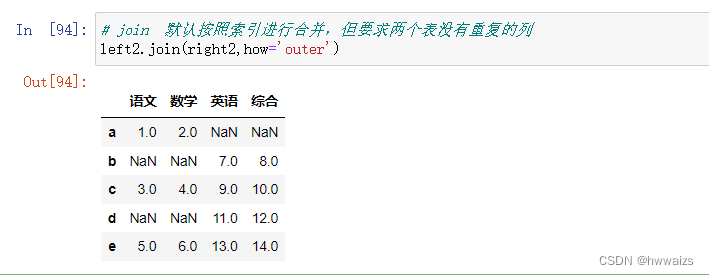
第一张表是语文数学的成绩表,第二张表是英语和综合的成绩表,abcd代表的是学生姓名,两张表合并的时候应该指定方式为‘outer’,连接值用索引值,此时left_on参数就不再使用了。
join
join,默认按照索引进行合并,但要求两个表没有重复的列,否则就会报错。