Speech recognition模型:RNN Transducer(RNN-T)
一,RNA(recurrent Neural Aligner)
RNA的模型结构介于 CTC 和 RNN-T 之间,在介绍RNN-T之前,将首先介绍RNA。
- RNA模型结构:
RNA相较于CTC,有2大改进:
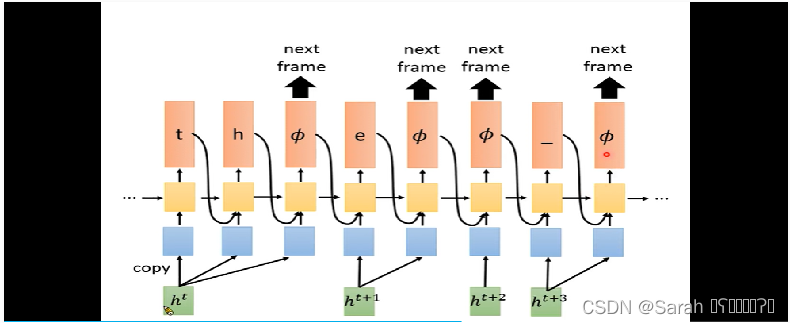
1,RNA中,将CTC的classifier改为了一个LSTM,使得模型在分类时,不单考虑了当下time step的h,同时也考虑了前一个time step的token。
2,RNA中,输入一个acoustic feature,可以输出多个output(即输出多个token),直到输出 null为止,该time step的output结束。
其模型结构如下图所示:
- RNA存在问题:
同CTC一样,RNA的训练也存在2方面的问题:
1,原始的训练数据为(语音,文本)对,但是,实际的模型训练时,需要的训练数据为paired train data,即(acoustic feature,token),所以,需要对训练数据进行alignment。
2,由于输入一个acoustic feature,其会一直输出token,直到输出null为止。因此,工程师在制作训练数据时,需要自行考虑将null插入文本中的何处。
二,RNN-T
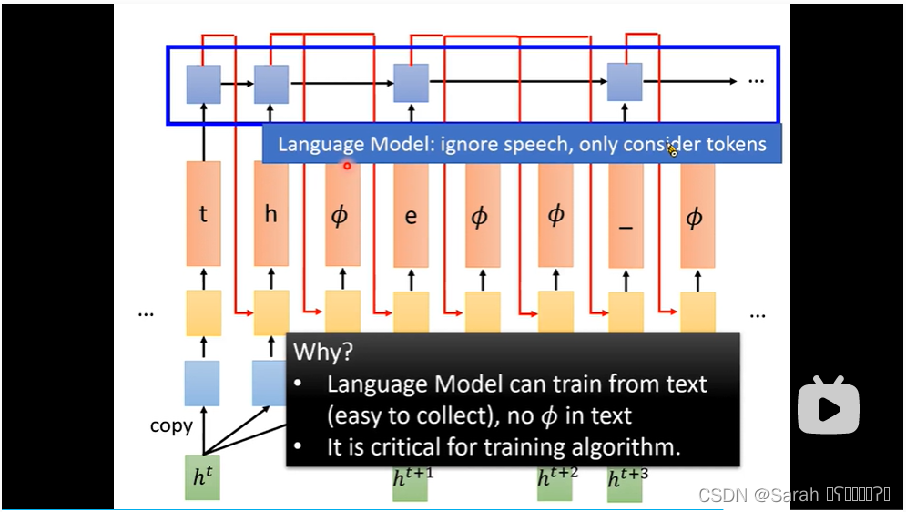
- RNN-T在RNA的基础上做了2处修改:
1,将RNA的LSTM classifier打断;
2,在output(token)上方,加了一个RNN,其input为token,当token为null时,则自动将其忽略。RNN在该time step的输出将会灌入下一个time step的classifier中作为输入,同acoustic feature一起 ,参与output token的预测。
这里,RNN起到了language model的作用,只不过是更小粒度的language。个人理解,这里的RNN是与模型的其他部分一起进行训练的。
其结构如下图所示:
- RNN-T存在的缺陷与RNA一样,在此不再赘述。
三,LAS,CTC,RNA,RNN-T 都是输入一个acoustic feature 然后给出输出的模型,在下一节中,将讲述另外一种类型的模型,即:给定一把输入,then,进行output。