当陪玩真能月入过万?Python获取陪玩数据
前言
一 、数据来源分析:
- 确定需求, 采集那个网站上面什么数据
- 抓包分析, 通过开发者工具进行抓包分析
二、代码实现步骤过程:
- 发送请求, 对于刚刚分析得到url地址发送请求
- 获取数据, 获取服务器返回响应数据
- 解析数据, 提取我们想要数据内容, 音频试音, 陪玩照片, 基本陪玩数据
- 保存数据, 保存本地文件夹
开发环境
- python 3.8
- pycharm
模块使用
- import os: 文件操作
- import re: 正则
- import requests: 数据请求
- import json: json数据转换
- import csv: 保存csv数据
代码实现
请求数据
对于分析得到url地址发送请求
headers是否添加, 看网站, 网站没什么反爬的话, 可以不用加
url = 'https://www.peiwantv.com/api'
# 请求参数
data = {
'act': 'userList',
'page': page,
'type': '1',
'sex': '2',
'voice': '1',
'order': '1',
}
# 发送请求
response = requests.post(url=url, data=data)
解析数据
提取我们想要数据内容, 音频试音, 陪玩照片, 基本陪玩数据
键值对取值:返回数据字典数据类型, 字典取值 根据冒号左边的内容[键], 提取冒号右边的内容[值]
for index in response.json()['data']['rows']:
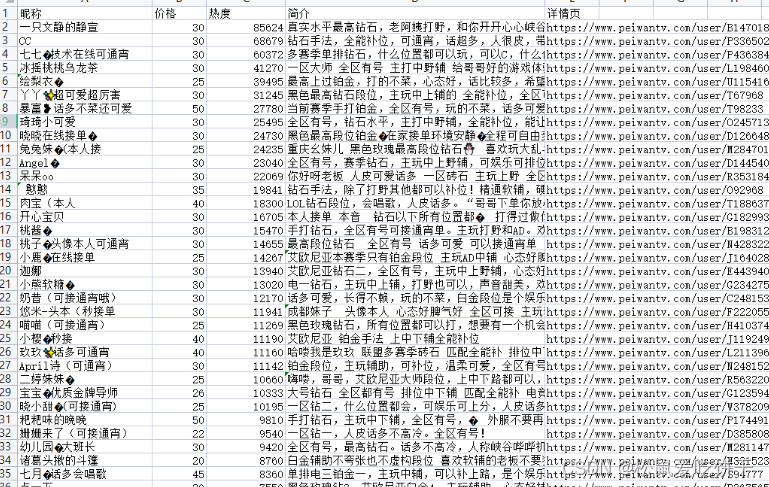
# 基本数据获取 --> 保存表格里面
dit = {
'昵称': index['nickname'],
'价格': index['price'],
'热度': index['exp'],
# replace() 字符串替换的方法 replace('替换之前的内容', '替换之后的内容')
'简介': index['summary'].replace('\n', ''),
# f'{}' 字符串格式化方法 format
'详情页': f'https://www.peiwantv.com/user/{index["uid"]}',
}
audio_url = 'https://static.peiwan.tv/' + json.loads(index['voice'])['url']
img_url = f'https://www.peiwantv.com/user/avatar/{index["uid"]}?image…ew2/1/interlace/1/ignore-error/1/w/100/format/jpg'
保存数据
陪玩详情数据
import os.path
c = open('data.csv', mode='a', encoding='utf-8-sig', newline='')
# c 文件对象 fieldnames 字段名
csv_writer = csv.DictWriter(c, fieldnames=[
'昵称',
'价格',
'热度',
'简介',
'详情页',
])
# 写入表头
csv_writer.writeheader()
# 保存表格数据
csv_writer.writerow(dit)
print(dit)
保存试音音频、图片数据
img_content = requests.get(url=img_url).content # 图片二进制数据
audio_content = requests.get(url=audio_url).content # 音频二进制数据
title = index["nickname"]
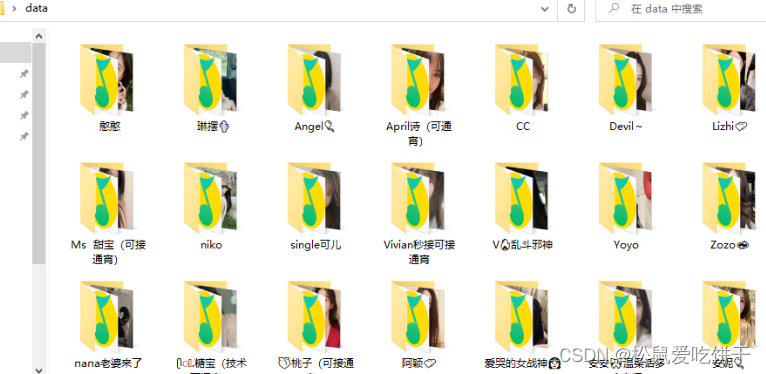
# 自动创建文件夹 data\\憨憨\\
file = f'data\\{title}\\'
# 判断如果没有文件夹
if not os.path.exists(file):
# 自动创建文件夹
os.makedirs(file)
with open(file + title + '.jpg', mode='wb') as img:
img.write(img_content)
with open(file + title + '.mp3', mode='wb') as audio:
audio.write(audio_content)