R语言应用xgboost进行机器学习(1)
XGBoost 机器学习模型是一种高效且可扩的展的机器学习分类器,由 Chen 和 Guestrin 在 2016 年推广。XGBoost原理是是在决策树的基础上产生迭代,它以 boosting 的方式结合了多个决策树。通常创建每棵新树是为了通过梯度提升来减少先前模型的误差,误差指的是实际值和预测值之间的差异。把误差作为协变量参与下一个模型的预测,反复执行这个过程,降低出错率,直到决策树指定阈值,模型已经被训练成功。XGBoost 具有与梯度提升相同的原理,它使用提升次数、学习率、二次采样率和最大树深度来控制过度拟合并增强更好的性能.


今天我们通过R语言来演示一下xgboost进行机器学习,使用的是我们的体检数据,
我们先导入数据
library(xgboost)
bc<-read.csv("E:/r/test/demo.csv",sep=',',header=TRUE)

数据变量很多,我解释几个我等下要用的,HBP:是否发生高血压,结局指标,AGE:年龄,是我们的协变量,SEX:性别等。公众号回复:体检数据,可以获得数据。
我们用不到这么多变量取一部分变量来建模
bc<-bc[,c("HBP","SEX","AGE","FEV1","OCCU","COUGH","EDU")]
bc <- na.omit(bc)
先把分类变量转成因子
bc$HBP<-as.factor(bc$HBP)
bc$SEX<-as.factor(bc$SEX)
bc$OCCU<-as.factor(bc$OCCU)
bc$EDU<-as.factor(bc$EDU)
建模前要构建全是数字矩阵,分类变量要转成哑变量矩阵,可以使用XGBoost自带的xgb.DMatrix 函数来构建,
x = model.matrix(HBP~.,bc)[,-1]
data_train <- xgb.DMatrix(x , label =as.numeric(bc$HBP))
构建好矩阵后就可以建模了,param <- list(objective = “reg:squarederror”)为默认的
param <- list(objective = "reg:squarederror")
HR_xgb_model <- xgb.train(param, data_train, nrounds = 50)
HR_xgb_model

上图显示的是模型的一些基本参数,niter 为迭代次数, nfeatures为训练数据中的特征数量,nrounds提升迭代的最大次数,模型建立好后,我们可以使用DALEX包的explain函数进行解析
因为我们做的是逻辑回归,所以要建立两个解析式
library("DALEX")
predict_logit <- function(model, x) {
raw_x <- predict(model, x)
exp(raw_x)/(1 + exp(raw_x))
}
logit <- function(x) {
exp(x)/(1+exp(x))
}
进行解析
explainer_xgb <- explain(HR_xgb_model,
data = x,
y = as.numeric(bc$HBP),
predict_function = predict_logit,
link = logit,
label = "xgboost")
explainer_xgb

使用model_profile函数进行变量分析
sv_xgb_satisfaction_level <-DALEX::model_profile(explainer_xgb,
type = "partial")
head(sv_xgb_satisfaction_level)
plot(sv_xgb_satisfaction_level)

可以看到age和fev1这两个变量和结局是相关的
我们导入breakDown包进一步分析
library("breakDown")
library(ggplot2)
nobs <- model_martix_train[1L, , drop = FALSE]
explain_2 <- broken(HR_xgb_model, new_observation = nobs,
data = model_martix_train)
explain_2
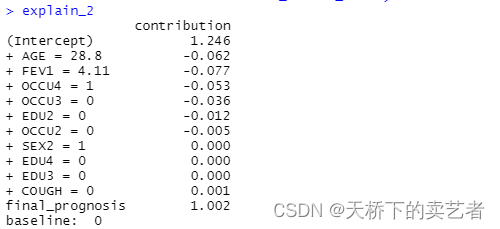
explain_2表示了每个变量对结局影响的权重,下图则以图示说明每个变量是怎么样对模型进行影响的

我们还可以进行进行模型指标重要行绘图
vd_xgb <- variable_importance(explainer_xgb, type = "raw")
plot(vd_xgb)
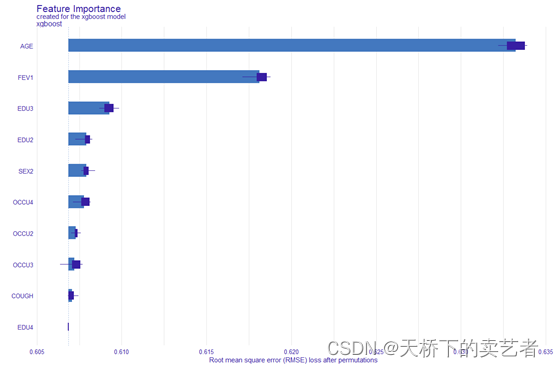
上图显示了哪个指标对结局变量的影响最大,我们可以看到对结局影响最大是是年龄、FEV1,EDU3.
OK,本期先介绍到这里,未完待续。