Hadoop学习----MapReduceYARN
Map Reduce
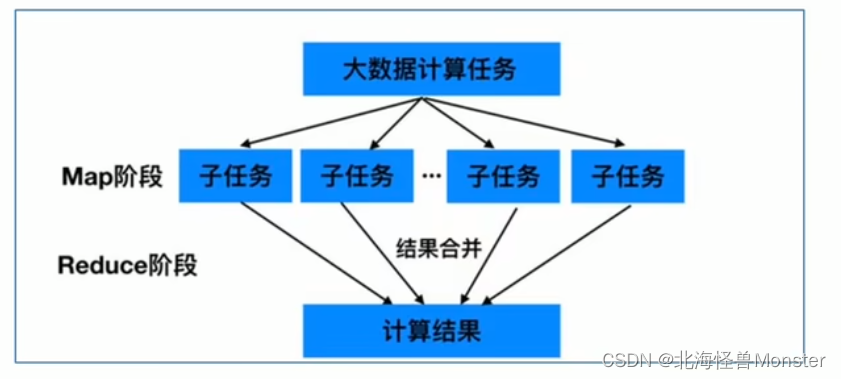
1、Map Reduce的思想核心是"先分再合,分而治之"
所谓"分而治之"就是把一个复杂的问题,按照一定的"分解"方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,最后把各部分的结果组成问题的最终结果
Map表示第一阶段,负责"拆分":即把复杂任务分解为若干个简单的子任务来并行处理,可以进行拆分的前提是这些小任务可以并行计算,彼此之间没有依赖关系。
Reduce表示第二阶段,负责"合并":即对map阶段的结果进行全局汇总
这两个阶段合起来就是MapReduce思想的体现。
2、MapReduce设计构思
构建抽象编程模型
MapReduce借鉴了函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型
Map:对一组数据元素进行某种重复式的处理
reduce:对map的中间结果进行某种进一步的结果整理

分布式计算概念
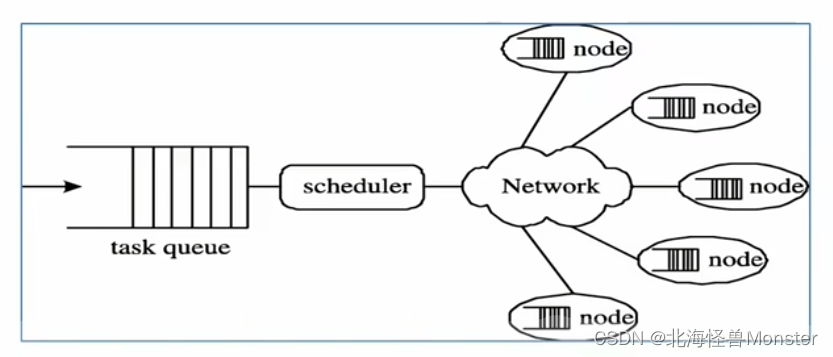
分布式计算是一种计算方法,和集中式计算式相对的
随着计算技术的发展,有些应用需要非常巨大的计算能力才能完成,如果采用集中式计算,需要耗费很多时间。
分布式计算将该应用拆分成许多小的部分,分配给多台计算机进行处理,这样可以节约整体计算时间,大大提高计算效率
Map Reduce介绍
是一个分布式计算框架,用于轻松编写分布式应用程序,这些应用程序以可靠,容错的方式并行处理大型硬件集群上的大量数据
MapReduce 是一种面向海量数据处理的一种指导思想,也是用于对大规模数据进行分布式计算的编程模型。
- 易于编程
MapReduce框架提供了用于二次开发的接口,简单的实现一些接口,就可以完成一个分布式程序,任务计算交给计算框架取处理,将分布式程序部署到hadoop集群上运行,集群节点可以扩展到成百上千个 - 良好扩展性
当计算机资源不能得到满足的时候,可以通过增加机器来扩展它的计算额能力。基于MapReduce的分布式计算的特点可以随节点数保持近似于线性的增长。 - 高容错性
Hadoop集群式分布式搭建和部署,任何单一机器节点宕机,它可以把上面的计算任务转移到另一个节点上运行,不影响整个作业的完成,过程完全是由hadoop内部完成 - 适合海量数据的离线处理
- 可以处理GB、TB和PB级别的数据量
相比其他Spark Flink,这些非常快,但是它们在内存中计算不够稳定,相比较MapReduce更加稳定。
局限性:
实时计算性能差
MapReduce主要用于离线作业,无法做到秒级或者亚秒级的数据响应
不能进行流式计算
流式计算的特点是数据是源源不断的计算,并且数据是动态的;而MapReduce作为离线计算框架,主要针对静态数据,数据是不能动态变化的。所以实时领域MapReduce几乎没有容身之地,着重在离线计算领域。
MapReduce实例进程
一个完整的MapReduce程序在分布式运行时有三类
- MRAppMaster:负责整个MR程序的过程调度及状态协调
- MapTask:负责map阶段的整个数据处理流程
- ReduceTask:负责reduce阶段的整个数据处理流程
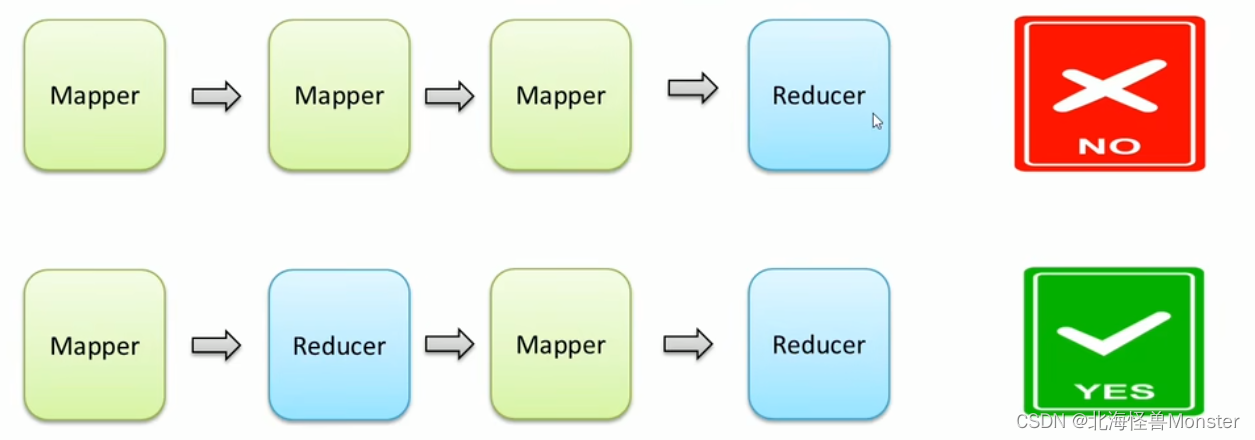
阶段组成:一个MapReduce编程模型中只能包含一个Map阶段和一个Reduce阶段,或者只有Map阶段
不能由多个map阶段,多个Reduce阶段的情况出现
如果用户的业务非常复杂,那就只能多个MapReduce程序串行运行
注意:整个MapReduce程序中,数据都是以kv键值对的形式流转的
官方示例
示例一:计算圆周率
示例程序路径: 安装包路径/hadoop/share/hadoop/mapreduce
示例程序:hadoop-mapreduce-examples-3.3.0.jar
MapReduce程序提交命令 :[hadoop jar|yarn jar] hadoop-mapreduce-examples-3.3.0.jar args…
提交到Yarn集群上分布式执行。
案例:评估圆周率的值
这里计算圆周率的方法是蒙特卡洛算法

10就是进行10次,每次撒点50,最后求平均,数越大得出结果越精准。这里是感受如何提交计算任务
# 第一个参数:pi表示MapReduce程序执行圆周率计算任务
# 第二个参数:用于指定map阶段运行的任务task次数,并发度,这里是10
# 第三个参数:用于指定每个map任务取样的个数,这里是50
hadoop jar hadoop-mapreduce-examples-3.3.4.jar pi 10 50
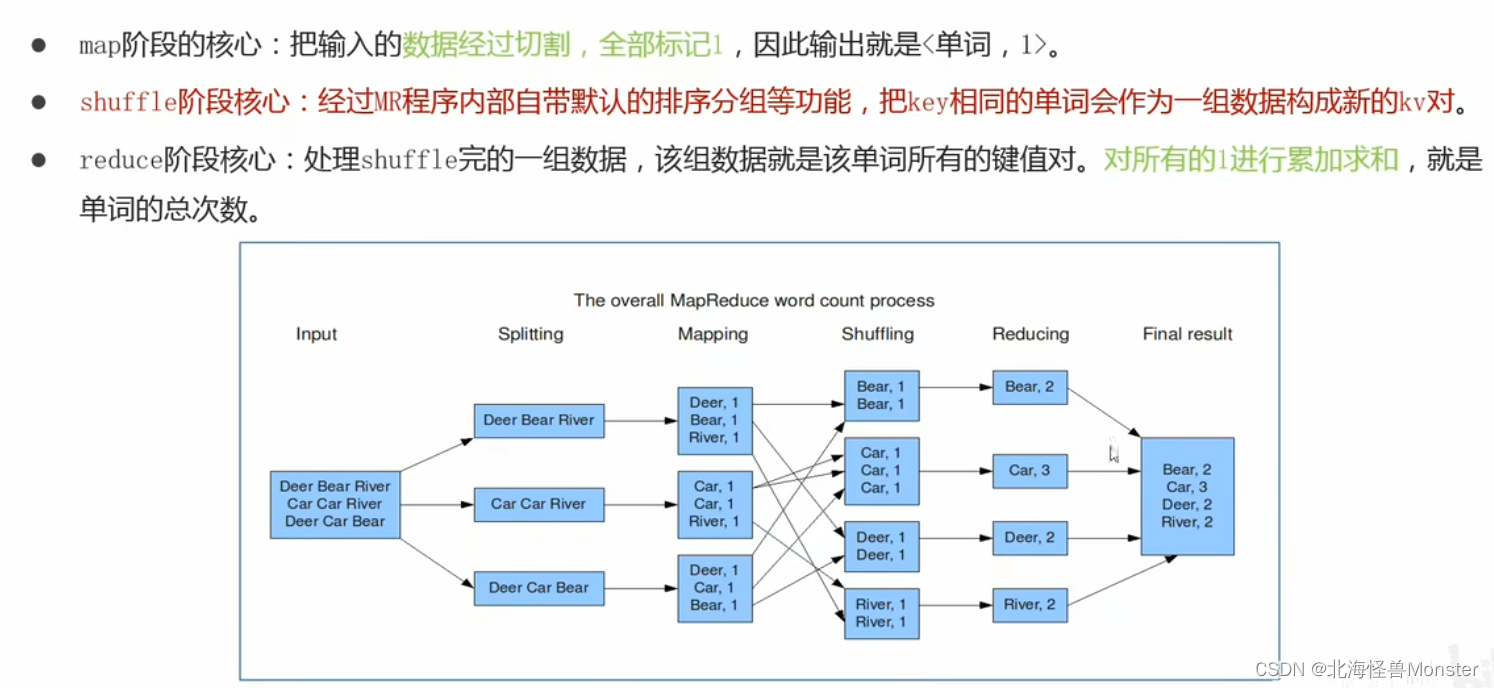
示例二:wordCount 单词统计次数
WordCount算是大数据计算领域经典,相当于hello world
虽然WordCount业务及其简单,但是通过案例感受背后MapReduce的执行流程和默认的行为机制,这才是关键
# 参数一:wordcount 代表要执行的动作
# 参数二:输入路径
# 参数三:输出路径,输出路径不能已经存在
hadoop jar hadoop-mapreduce-examples-3.3.4.jar wordcount /input /output
第一个文件大小为0,这是一个成功失败的标识文件
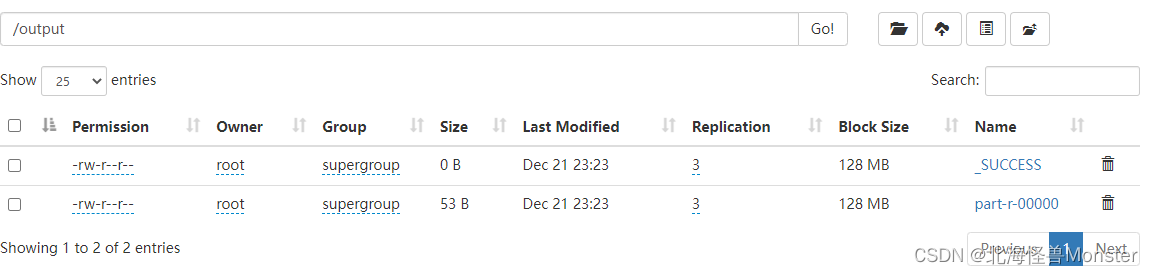
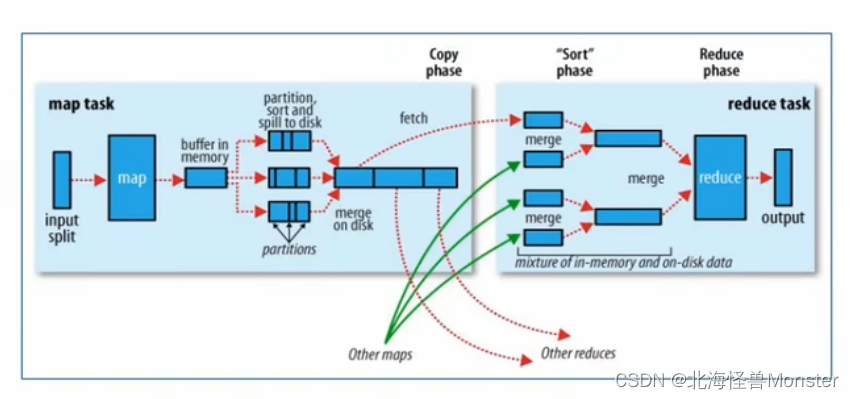
Map阶段执行过程:
第一阶段:把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划,默认Split size = Block size(128M),每一个切片由一个MapTask处理
第二阶段:对切片中的数据按照一定的规则读取解析返回 <key,value>对,默认是按行读取。key是每一行的起始位置偏移量,value是本行文本内容
第三阶段:调用Mapper类中的map方法处理数据,每读取解析出来一个<key,value>调用一次map方法
第四阶段:按照一定的规则对Map输出的键值对进行分区,默认不分区,因为只有一个reducetask,分区的数量就是reducemask运行的数量
第五阶段:Map输出数据写入内存缓冲区,达到比例溢出到磁盘上,溢出spill的时候根据key进行排序sort,默认根据key字典序排序
第六阶段:对所有溢出文件进行最终的merge合并,成为一个文件
Reduce阶段执行过程:
第一阶段:ReduceTask会主动从MapTask复制拉取属于需要自己处理的数据
第二阶段:把拉取来的数据全部进行合并merge,即把分散的数据合并成一个大的数据。再对合并后的数据排序
第三阶段:是对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,最后把这些输出的键值对写入到HDFS文件中
shuffle概念:
在MapReduce中,shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则"打乱"成具有一定规则的数据,以便reduce端接收处理
一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程成为shuffle
这也是MapReduce处理过程慢的问题所在,就拿wordcount来说,map产出文件在内存,溢出之后到磁盘,通过网络传输到reduce内存,由合并到磁盘,就涉及了多次IO
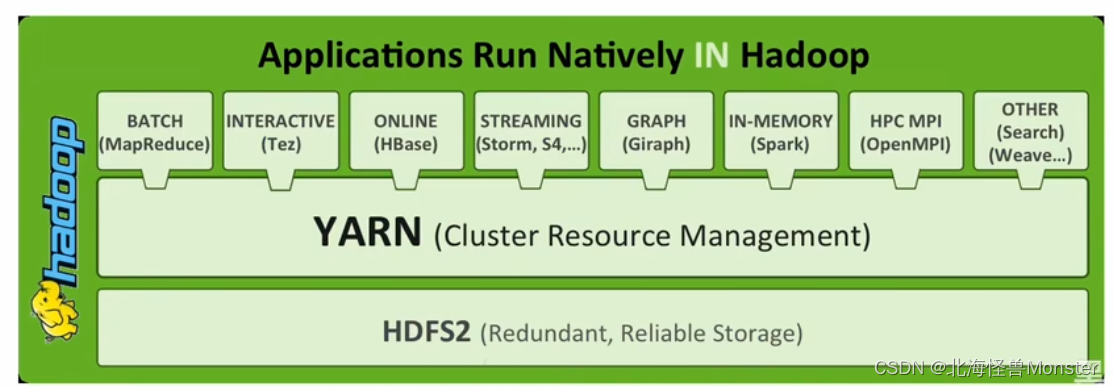
YARN
Apache Hadoop YARN(Yet Another Resource Negotiator,另一种资源协调者),是一种新的Hadoop资源管理器。
YARN是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度
它的引入为集群在利用率、资源统一管理和数据共享方面带来了巨大好处。
资源管理系统:集群的硬件资源,和程序运行相关,比如:内存、CPU等
调度平台:多个程序同时申请计算资源时如何分配,调度的规则(算法)
通用:不仅仅支持MapReduce程序,理论上支持各种计算程序。YARN不关心你干什么,只关心你要资源,在有的情况下给你,用完之后还我。
可以把Hadoop Yarn理解为相当于一个分布式的操作系统平台,而MapReduce等计算程序则相当于运行于操作系统之上的应用程序,YARN为这些程序提供运算所需的资源
Hadoop能有今天这个地位,YARN是功不可没,因为有了YARN,更多计算框架可以接入到HDFS中,而不单单是MapReduce,正是因为YARN的包容,使得其他计算框架能够专注于计算性能的提升。
HDFS可能不是最优秀的大数据存储系统,但却是应用最广泛的大数据存储系统,YARN功不可没
YARN中有一个关键组件—Resource Scheduler
它是 ResouceManager的内部组件之一,Scheduler 完全专用于调度作业,它无法跟踪应用程序的状态。
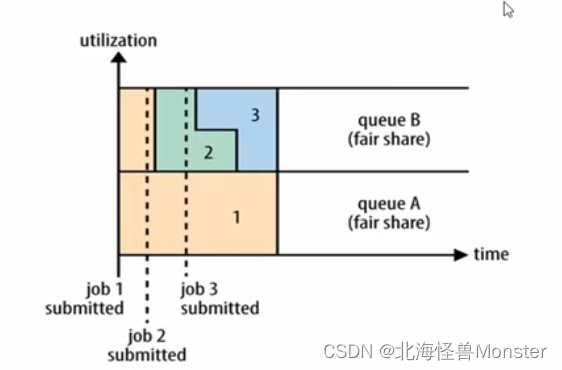
Hadoop提供了三种调度策略: FIFO Scheduler(先进先出调度器) Capacity Scheduler(容量调度器) Fair Scheduler(公平调度器)
默认使用的 Capacity Scheduler
如果需要使用其他调度器,可以在yarn-site.xml中的yarn.resourcemanager.shceduler.class进行配置
没有最好的,只有最符合业务的。
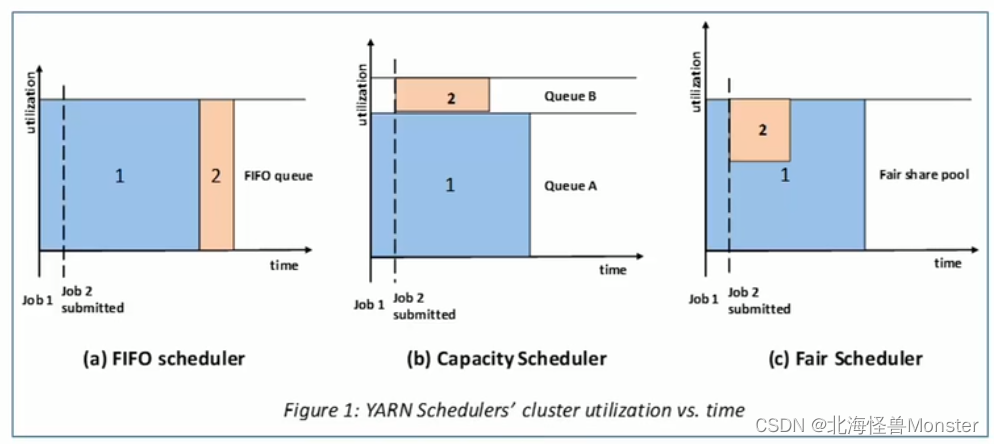
FIFO Scheduler(先进先出调度器): 先来的先执行,后来的后执行。优先级无法调整。
Capacity Scheduler(容量调度器):默认方式,该策略允许多个组织共享整个集群资源。
Fair Scheduler(公平调度器):如图,有两个用于作业,A用于先来,1占据了所有资源,B用户来了之后,根据用户平分资源。B有两个作业,2和3平分B用户资源