深度学习——物体检测算法:R-CNN,SSD,YOLO(笔记)
一,R-CNN
1.区域卷积神经网络R-CNN

首先从输入图像中提取若干个锚框,并标注好它们的类别和偏移量。然后用卷积神经网络对每一个锚框进行前向传播抽取特征。最后用每个提议区域的特征来预测类别和边界框。
①使用启发式搜索算法来选择锚框
②使用预训练好的模型来对每个锚框进行特征提取
③训练一个SVM对类别分类
④训练一个线性回归模型来预测边缘框的偏移
缺点:有多少个边缘框就需要多少次特征提取,计算量非常大。
2.兴趣区域(Rol)池化层:将大小不一的锚框变成统一的形状
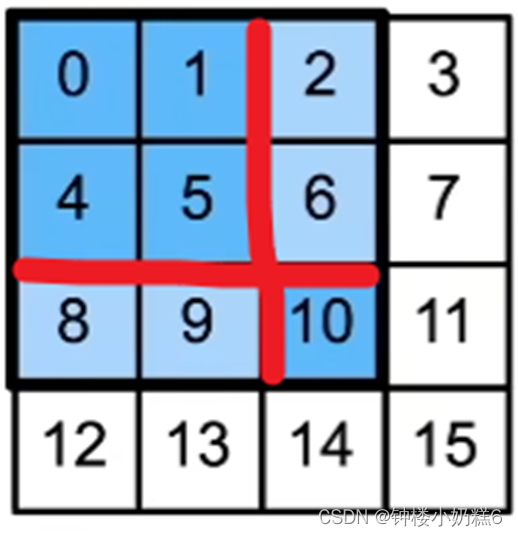
①给定一个锚框,分割成n*m块(n*m就是Rol的大小,不一定是均分),输出每块的最大值
②不管锚框多大,总是输出n*m个值
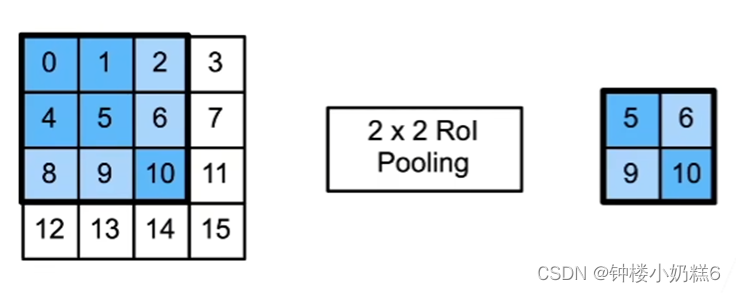
“因为Rol是2*2的,所以分割4块,输出每块的最大值”
3.Fast RCNN
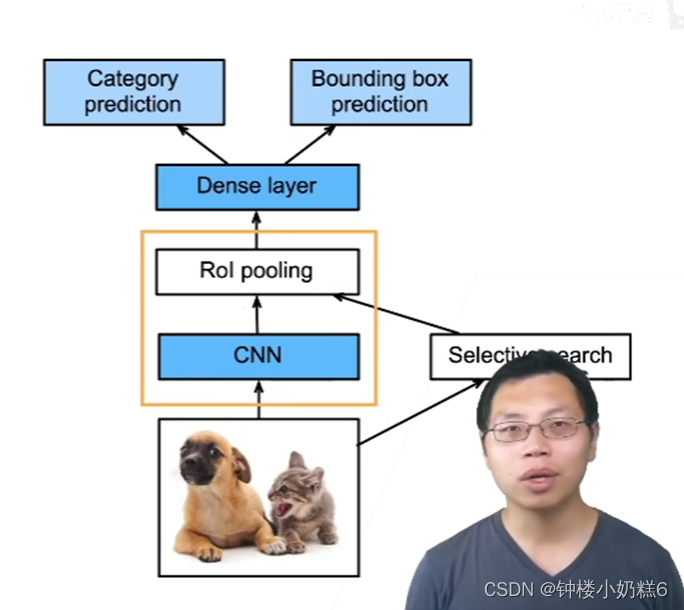
①使用CNN对图片抽取特征
②使用Rol池化层对每个锚框生成固定长度的特征
改进:
①使用CNN对整张图片提取特征,最终得到一个7*7或14*14的feature map
②抽取完特征后,对图片进行锚框的选择。搜索到原始图片上的锚框将其映射到CNN输出上
③映射完锚框后,使用Rol池化层对CNN上的feature map进行特征提取,生成固定长度的特征。最后通过全连接层对每个锚框预测:类别和偏移
Fast R-CNN 相对于 R-CNN 更快的原因是:Fast R-CNN 中的 CNN 不再对每个锚框抽取特征,而是对整个图片进行特征的提取(这样做的好处是:不同的锚框之间可能会有重叠的部分,如果对每个锚框都进行特征提取的话,可能会重复特征提取),然后再在整张图片的feature中找出原图中锚框对应的特征,最后一起做预测。
4.Faster R-CNN
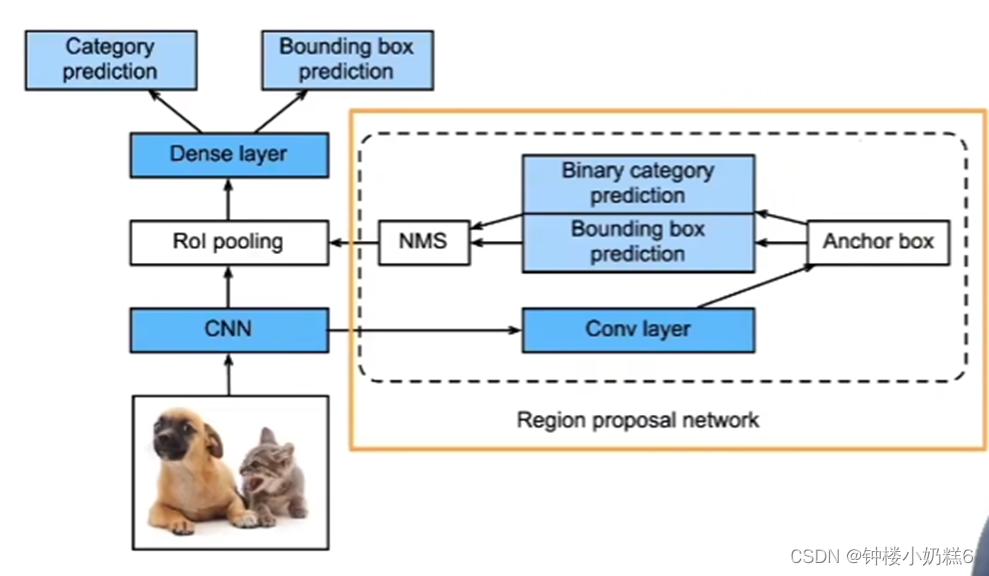
①使用一个区域提议网络来代替启发式搜索来获得更好的锚框
②Rol的输入是CNN输出的feature map和生成的锚框
③RPN的输入是CNN输出的feature map,输出是高质量的锚框
CNN的输出进入到RPN之后再做一次卷积,然后生成一些锚框。再训练一个二分类问题:预测锚框是否框住了真实物体以及锚框的偏移,最后使用NMS进行锚框去重,使得锚框数量变少
④准确率比较高,但是速度慢
5.Mask R-CNN
如果在训练集中标注了每个目标图像上像素级的位置。Mask R-CNN有效利用这些标注信息提升目标检测的精度。
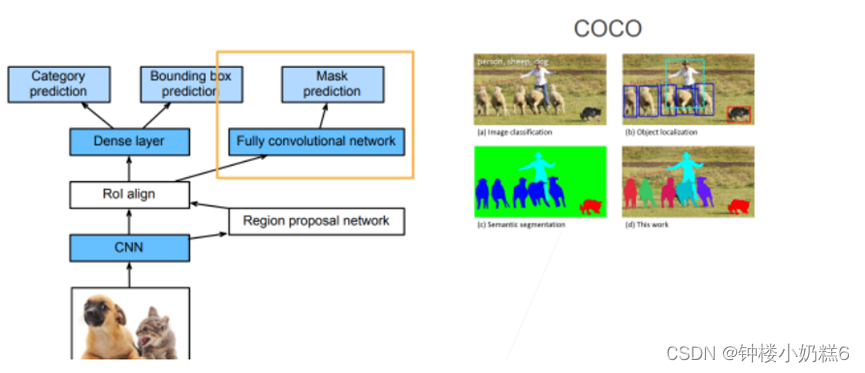
①假设有每个像素的标号,对每个像素做预测(FCN)
②将兴趣区域汇聚层替换了兴趣区域对齐层(Rol pooling->Rol align),使用双线性插值保留特征图上的空间信息,适合像素级预测。Rol pooling对像素级有极大的误差。Rol align不能整除时,会直接将像素切开,切开后的每一部分是原像素的加权(它的值是原像素的一部分)
③兴趣区域对齐层的输出包含了所有兴趣区域形状相同的特征图,它们不仅被用于预测每个兴趣区域的类别和边界框,还通过额外的全卷积网络预测目标的像素级位置。
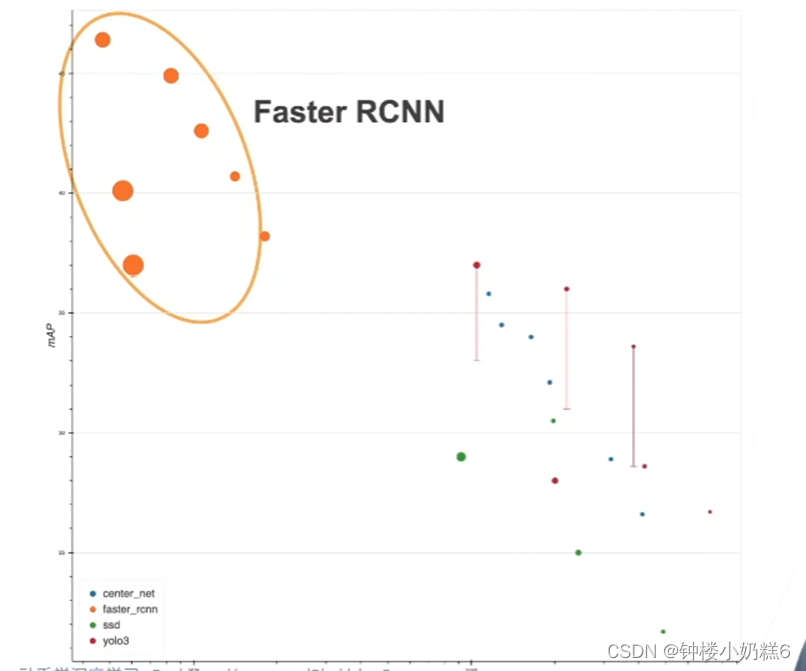
X轴表示模型运行速度,y轴表示精度,Faster RCNN 相对来说精度比较高,速度慢。
【总结】
①R-CNN是最早,也是最有名的一类基于锚框和CNN的目标检测算法
②Fast/Faster R-CNN持续提升性能
③Faster R-CNN 和 Mask R-CNN高精度算法
二。单发多框检测(SSD)
对每个像素生成多个以它为中心的多个锚框

SSD模型:
①一个基础网络来抽取特征,然后多个卷积层来减半高宽
②在每段都生成锚框,底部来拟合小物体,顶部来拟合大物体
③对每个锚框预测类别和真实边缘框
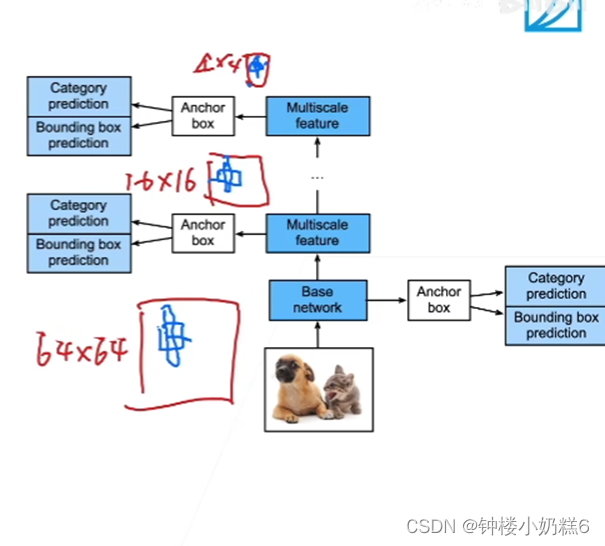
①输入图像后,首先进入一个基础网格抽取特征,抽取完特质之后对每个像素生成大量的锚框(每个锚框就是一个样本,然后预测锚框的类别和偏移)
②SSD给定锚框之后直接对锚框将进行预测,不需要两阶段。SSD 通过做不同分辨率下的预测来提升最终的效果,越到底层的 feature map,就越大,越往上,feature map 越少,因此底层更加有利于小物体的检测,而上层图像小 更有利于大物体的检测
③SSD不再使用RPN网络,而是直接生成大量样本(锚框)上做预测。看是否包含目标物体。如果包含目标物体,再预测该样本到真实边缘框的偏移。

上图中绿色的点表示 SSD
从图中可以看出,SSD 相对于Faster RCNN 来讲速度快很多,但是精度不是太好
SSD 的实现相对来讲比较简单,R-CNN 系列代码的实现非常困难
【总结】
①SSD通过单神经网络来检测模型
②以每个像素为中心产生多个锚框
③在多个段的输出上进行多尺度的检测
三。YOLO

①SSD中大量锚框重叠,浪费了很多计算
②YOLO将图片均分分成S*S个锚框
③每个锚框预测B个边缘框
补充:
①yolo 也是一个 single-stage 的算法,只有一个单神经网络来做预测
②yolo 也需要锚框,这点和 SSD 相同,但是 SSD 是对每个像素点生成多个锚框,所以在绝大部分情况下两个相邻像素的所生成的锚框的重叠率是相当高的,这样就会导致很大的重复计算量
③yolo 的想法是尽量让锚框不重叠:首先将图片均匀地分成 S * S 块,每一块就是一个锚框,每一个锚框预测 B 个边缘框(考虑到一个锚框中可能包含多个物体),所以最终就会产生 S ^ 2 * B 个样本,因此速度会远远快于 SSD
④yolo 在后续的版本(V2,V3,V4...)中有持续的改进,但是核心思想没有变,真实的边缘框不会随机的出现,真实的边缘框的比例、大小在每个数据集上的出现是有一定的规律的,在知道有一定的规律的时候就可以使用聚类算法将这个规律找出来(给定一个数据集,先分析数据集中的统计信息,然后找出边缘框出现的规律,这样之后在生成锚框的时候就会有先验知识,从而进一步做出优化)
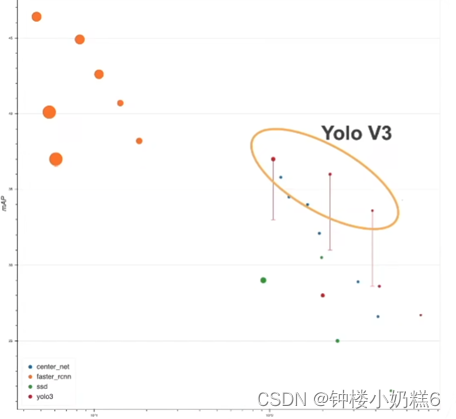
上图中表示 yolo v3 的直线底端表示论文中的原始精度,顶端表示通过改进之后所能达到的最大精度