TensorRT学习笔记 1 - 概述
TensorRT系列笔记是作者半年来学习和使用TensorRT(后称trt)积累笔记 整理和心得。包含trt的基本概念,相关资料,实践笔记,踩坑记录等等。
本篇博客希望可以初步说清楚
- trt是什么;
- 模型部署为什么使用trt,以及使用trt的基本步骤
目录
1. trt是什么
1.1 从模型部署说起。
1.2 如何提升速度又减低内存
1.3 什么是TensorRT
1.4 使用注意
2. trt的基本用法
2.1 为什么trt可以为深度学习模型加速
2.2 trt使用的基本步骤
2.3 构建期的基本方法及其比较
2.4 相关概念的介绍
3. 小结
1. trt是什么
1.1 从模型部署说起。
算法工程师们训练了一个优秀的模型,并保存为一批参数的集合,tensorflow一般保存的是ckpt文件,torch一般保存的是pt文件。算法工程师在使用自己训练的模型的时候,使用的步骤一般是,编写推理代码,加载模型,输入测试数据,获取结果。此时算法工程师们一般更关注的是结果的准确率、语音的自然度和表现力,不关心速度、实时率、吞吐率、首包延迟等等工程性指标。ckpt和pt文件中保存了许多与前向推理无关的参数,占用内存,拖慢推理速度。并且想ckpt这样的模型,在恢复模型之前需要重新定义一遍网络结构(拜静态图所赐),速度就更慢了。
当然,爱折腾的算法工程师们,愿意花费一点点精力,把原始的模型转换成pb文件,pb文件可以只存储参数;也可以把参数和网络结构一并存储,这样就不需要重新再代码中定义网络结构,文件大小也被压缩,看起来友好了很多。
谷歌推荐的保存模型的方式是保存模型为 PB 文件,它具有语言独立性,可独立运行,封闭的序列化格式,任何语言都可以解析它,它允许其他语言和深度学习框架读取、继续训练和迁移 TensorFlow 的模型。
它的主要使用场景是实现创建模型与使用模型的解耦, 使得前向推导 inference的代码统一。另外的好处是保存为 PB 文件时候,模型的变量都会变成固定的,导致模型的大小会大大减小,适合在手机端运行。
但是,这里的前向推理仍然是按照网络结构的定义,一个节点一个节点的计算。速度还是不尽人意。而速度和内存占用恰恰是算法工程化的工程师极度关注的东西,因为这些指标直接关系到模型上线之后的成本问题和用户体验问题。毕竟老板不希望因为推理速度慢,内存占用大,导致一个模型占用巨大的硬件成本,用户也不希望发送一个请求,在等待了漫长的一秒钟之后才收到了第一批返回数据。
因此,模型的部署绝不是简单的把训练好的模型直接放到机器上运行就完事儿了,从训练完毕到服务用户之间,必然需要有许多的工作要做,比如如何把模型变小,如何让模型变快,如何让模型实现并发,这就是模型部署部分的工作。
1.2 如何提升速度又减低内存
作为一个程序员,作为一个有一张显卡执行并行计算的程序员,作为一个有高数和线性代数等作为武器的程序员,当然是希望用尽各种方法把计算的速度提上来。
一个很直接的想法,模型内部的前向推理,本质上就是一个有一个的矩阵运算,还记得线性代数你看了一遍又一遍的矩阵运算规则吗,现在他们从一个个枯燥的公式,变成了你的有力武器。有的矩阵运算原本是先做乘法在做加法,现在可以把它们变成先做拼接在做乘法,原来的若干次运算变成了一次运算,速度是不是提升了。
如果把前向推理的所有计算都做了合并和优化,是不是计算就更快了(计算次数少了,有显卡的并行计算加持,不用太担心大矩阵运算的开销),那么多的节点优化成了一个节点,是不是内存也会变少了?那么我们的目标是不是就达成了。
当然,这些工作已经有人帮我们做了。比如百度和阿里推出了模型优化部署方案,比如英伟达推出的TensoRT。
1.3 什么是TensorRT
- 用于高效实现已经训练好的深度学习模型的推理过程的SDK
- 内含推理优化器和运行时环境
- 目的是使得深度学习模型可以更高吞吐量和更低的延迟运行
- c++和python API可以等价混用
总结起来,tensorrt是一种与模型优化和部署相关的一整套工具,这套工具含有推理优化器和运行时环境,可以训练好的模型的推理过程做运算合并和优化生成一种新的计算流程并保存为trt引擎,并高效的完成推理过程。最终目的是提高深度学习模型的吞吐和延迟,使其更符合线上服务的需求。
1.4 使用注意
- trt与硬件相关,A10上生成的引擎,一般无法在V100上使用
- trt可以与cuda编程结合,提升速度和编程灵活性。
2. trt的基本用法
2.1 为什么trt可以为深度学习模型加速
- 主要从以下两个阶段完成模型的优化和推理加速。
- 构建期(推理优化器)
- 模型解析/建立 : 加载onnx等其他格式的模型, 或者使用原生API搭建模型
- 计算图优化 : 使用横向层融合和纵向层融合
- 节点消除 : 去除无用层、无用的节点变化, 比如pad, slice, concat, shuffle
- 多精度支持 : fp32, fp16, int8, tf32(这个过程可能插入reformat节点,用于数据类型变换)
- 优选kernel/format : 硬件有关优化。trt是硬件相关的,每个节点有多种实现,哪一种更好需要trt选择
- 导入plugin : 用于实现自定义的操作
- 显存优化 : 显存池复用,显存池由trt维护
- 运行期(运行时环境)
- 运行时环境 : 管理对象生命期、内存、显存, 处理异常
- 序列化与反序列化 : 推理引擎保存至磁盘,或者加载至显存
2.2 trt使用的基本步骤
trt的使用也是遵循两个阶段。首先在构建期,使用工具把深度学习模型转换成指定精度的序列化表示(trt引擎),这是模型部署的前期准备工作;然后再运行期加载这个引擎,并编写对应的输入输出数据的处理代码,完成模型的推理。
如果你选择框架自带的parser解析深度学习模型并转化为trt引擎。
- 构建期有几种不同的路径,这里介绍两种:
- pt -> onnx -> trt
- pb -> (pb2onnx模块) -> onnx -> trt
- 可以使用int8量化,需要自己实现calibrator类。
- onnx -> trt 这个步骤一般直接使用tensorrt提供的trtexec工具转换。
-
不支持节点有一下几种方法
- 修改parser: 修改trt源代码,重新编译trt
- tensorrt实现plugin
- 修改onnx计算图(onnx-surgeon)
- 修改源模型
- 运行期
- 建立engine, context
- 准备buffer, 用于host和device之间的数据拷贝
- 执行推理,即执行execute(_v2)函数
如果你选择使用trt API自行搭建前向推理计算的所有流程
- 构建阶段
- 建立Logger, 这是日志记录器
- 建立Builder(网络元数据)和BuilderConfig(网络元数据的选项、配置, 比如是否开启精度等)
- 创建Network, 也就是自行搭建计算图的内容
- 生成序列化文件
- 运行阶段
- 建立engine
- 建立context, 类比cpu进程,负责管理,是执行trt的主体。
- 准备host buffer, device buffer
- buffer拷贝 : h -> d
- 执行推理
- buffer拷贝 : d -> h
- 善后工作
- 上述概念介绍见2.4
- 综上,一个完整的trt开发和推理流程应该是这样的
- 准备原始网络代码,基于tensorflow或者torch或者基于其他框架的代码。必要时需要对代码做修改。
- 准备训练好的原始模型,比如ckpt模型等等。
- 从ckpt模型获取模型中的所有张量以及对应的张量名称
- 确定模型的所有输入,以及输入的形状,如果有动态形状,使用 -1 指代,并指定动态形状的范围。可以借助netron工具查看计算图。
- 按照原始网络代码,使用trt API(python / c++)自行搭建网络,并将获取的张量值按照张量名称放进自行搭建的网络中
- 搭建完毕之后指定网络的输出,并执行编译代码,生成engine
- 根据模型的输入输出完成engine 的 inffer代码。见上述运行阶段步骤。
2.3 构建期的基本方法及其比较
构建期是把深度学习模型转换成trt引擎的步骤,有三种不同的方法。方法不同,但是目的不同,区别在于难度和灵活度等。但是一般情况下,使用API搭建的方式,性能可以达到最优。

- 第一种: 使用框架自带的trt接口, 比如tf-trt, troch-tensorrt
- 这种方式简单灵活,部署仍然使用的原始框架。
- 对于不支持的算子,不需要书写plugin,而是会自动会滚到原始框架中进行计算。
- 第二种:最推荐 使用parser, 比如tf/torch/.. -> onnx. -> tensorrt
- 流程成熟, onnx通用性比较好,方便网络调整,兼顾效率性能
- 对于不支持的算子,可以通过修改网络,修改parser, 书写plugin等方法实现。
- 第三种: 使用API自行搭建网络
- 性能最优,精细控制网络,兼容性最好
2.4 相关概念的介绍
- Logger, 日志记录器, 多个builder可以共享一个logger
- 可选参数: verbose, info, warning, error, internal_error, 用于产生不同等级的日志,有详细到简略
- Builder, 引擎构建器,是构建推理引擎的核心对象
- builder = trt.BUilder(logger)
- 仅仅作为构建引擎的入口
- Dynamic shape模式必须使用 builderConfig以及相关的API
- Builderconfig, 网络属性设置选项
- config = builder.create_builder_config()
- 设置是否开启疯跑6, int8量化等
- 设置其他高级选项,比如 set_static_sources/set_timing_cache/algorithm_selector
- Network, 网络具体构建
- network = builder.creat_network()
- explicit batch模式和 implicit batch模式
- implicit模式中,所有张量的batch维度不会显式指定,而是在运行期再指定
- explitcit模式(推荐)表示,所有张量的batch维度,需要显式的指定。
- onnx倒入的模型默认使用explicit batch 模式
- dynamic shape模式
- 使用这种模式的原因:
- 在实际场景中,需要使用同一个模型处理不同尺寸的数据,如图像分辨率,语音文本的长度等都是随时变化的
- 实际场景中,数据的batch大小也是随时变化的,
- 因此,允许模型张量的部分维度延迟到运行在做具体指定或者确认。
- 构建阶段需要使用builder.create_optimization_profile指定该张量所有可变维度的变化范围
- 运行阶段,需要使用context.set_binding_shape(axis, [reshape])指定张量的实际维度
- binding
- engine/context给所有的输入输出张量都安排了位置
- 总共有engine.num_bindings个binding, 输入张量在前,输出张量在后(只有一个profile时)
- 运行阶段绑定张量形状,要按照指定的位置绑定,这样trt才能初始化整个网络,当指定输入形状之后,trt会自动计算输出张量的形状,便于用户获取输出张量的形状,提前为输出张量开辟空间,拷贝输出数据。
- 要注意,在指定多个profile是,binding的规则会比较复杂。
- buffer
- cuda的异构计算
- 同时准备cpu内存和gpu显存
- 开始计算之前,把数据从内存拷贝到显存
- 计算时的输入输出数据都在gpu上进行读写
- 计算完成之后,把结果从gpu拷贝到cpu
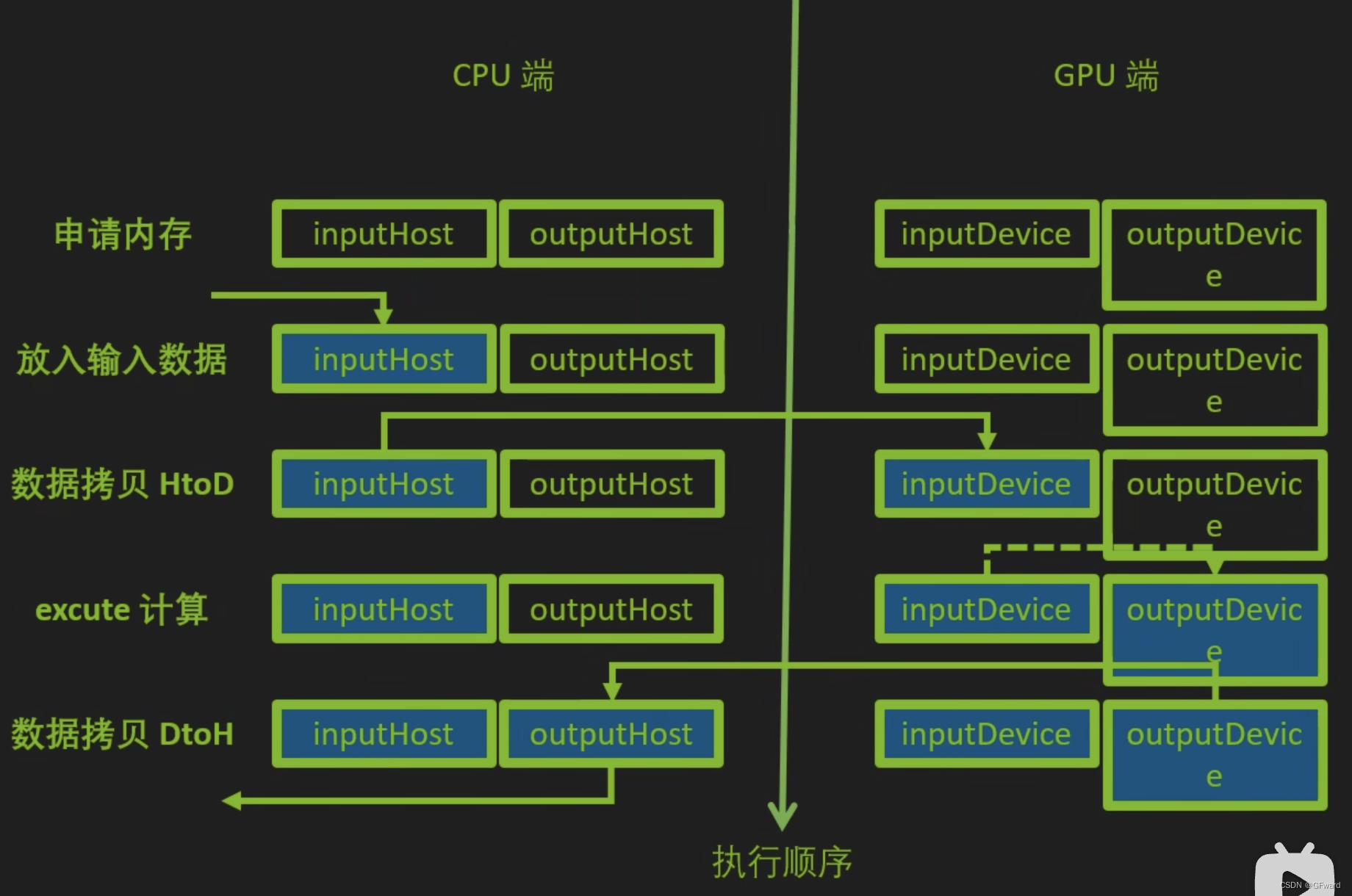
- cuda的异构计算
- 序列化与反序列化
- 二者环境必须完全统一,版本统一,应将统一
- 同一个平台同一个环境生成的engine也可能不同。原因是在不同的构造过程中,由于轻微的扰动,同一个算子的优化使用了不同的实现。
- 一种解决方式是,使用algorithmSelector或者timemingCache多次生成一模一样的engine。
3. 小结
至此,我们了解了什么是tensorrt, trt是用来干什么的,trt是如何实现这些功能的,trt基本的使用方法,trt使用中涉及的基本概念。
后面几篇笔记,我们将会了解trt如何下载和在python环境中使用,并给出onnx转trt的一个示例(不一定可运行),给出API搭建引擎过程中的一些细节。还会给出一些相关的参考资料。
更进一步的,还会介绍一个引擎搭建完毕可运行的时候,我们如何测试他们的指标等等。