六、Buffer缓冲区和Stream流

Buffer —— 缓冲区
JavaScript 提供了大量对字符串的便捷操作,但没有读取或操作二进制数据流机制,而在Node.js中可以直接用Buffer类提供的构造函数创建Buffer实例,一个Buffer实例代表一个缓冲区,Buffer的缓冲区专门用于存放二进制数据,进行二进制字节流的读写、网络传输;数据在计算机中以二进制形式表示,那么需要用字符编码转换,比如非常熟悉的字符编码UTF-8,字符集和字符编码一般都是成对的,比如:GB2312,GBK,ASXII,IOS-8859-1 ... ,那么对Buffer有基本的了解之后,来使用一下Buffer:
创建Buffer

Buffer.from()
Buffer.from(value,...)方法申请一个被字符串值初始化的Buffer实例;
// from.js 返回一个被string初始化的新Buffer实例
const buff = Buffer.from('Hello');
console.log(buff);
Buffer的访问可以像数组一样;
console.log(buff[0]); // H - 72
buff.length —— 获取到 Buffer 长度;

使用 for 遍历 buffer;
const buff = Buffer.from('Hello');
for(const item of buff){
console.log(item); // 72 101 108 108 111
}通过数组的方式修改Buffer
const buff = Buffer.from('Hello');
// H[72] e[101] l[108] l[108] o[111];
buff[1] = 111;
console.log(buff.toString()); // Hollo write ——更改Buffer
const buff = Buffer.from('Hey');
buff.write('www');
console.log(buff.toString()); // wwwBuffer.alloc()
Buffer.alloc(size[,fill [,encoding]]) 返回一个指定size字节空间大小的Buffer实例;size 指字节大小,fill 指设置新建Buffer初始值,省略则默为undefined,encoding默认为utf-8;
// alloc.js
const buff1 = Buffer.alloc(6); // size
const buff2 = Buffer.alloc(6,3); // size , fill
const buff3 = Buffer.alloc(6,'点赞','utf-8'); // size , fill , encoding
console.log( ... )
fill 为undefined时,Buffer则用0填充;一个汉字3个字节,size超过12字节的内容会被截断;
// alloc.js
const buff1 = Buffer.alloc(12,'灵魂学者','utf-8');
const buff2 = Buffer.alloc(12,'灵魂学者感谢各位','utf-8');
console.log(buff1);
console.log(buff2);
通过以上的两端Buffer可以看到第二段的Buffer与第一段Buffer一样,那么为了更加直观,将Buffer进行转为字符串的形式来看:
toString() —— 转字符串
console.log(buff1.toString());
console.log(buff2.toString());
write
const buff = Buffer.alloc(4);
buff.write('lhxz');
console.log(buff.toString()); // lhxzcopy
const buff1 = Buffer.alloc(4,'lhxz');
const buff2 = Buffer.alloc(4);
buff1.copy(buff2);
console.log(buff1.toString(),buff2.toString());![]()
Buffer.allocUnsafe()
Buffer.allocUnsafe(size) 返回一个size字节大小的新的非0填充的Buffer,生产Buffer实例不被初始化,size是一个数字表示分配字节大小,size不是数字则会抛出TypeError错误。
// allocUnsafe.js文件
const buff1 = Buffer.allocUnsafe(12);
const buff2 = Buffer.allocUnsafe(12);
console.log(buff1);
console.log(buff2);
每通过Buffer.allocUnsafe()执行的结果都不相同,因为该方法分配的空间是未重置的,会保留先前的垃圾信息;allocUnsafe的使用是很不安全的,但读取速率比alloc更快;一般使用Buffer.allocUnsafe() 创建Buffer之后要使用Buffer.fill(0) 将这个Buffer初始化为0;
const buff = Buffer.allocUnsafe(12);
buff.fill(0);Buffer转为不同字符编码的字符串
const buff = Buffer.from('感谢有你');
console.log(buff);
console.log(buff.toString());
console.log(buff.toString('ascii'));
console.log(buff.toString('base64'));
console.log(buff.toString('utf-8'));
切片Buffer
const buff = Buffer.from('lhxz');
buff.slice(0).toString(); // lhxz
const slice1 = buff.slice(0,2); // lh
const slice2 = buff.slice(2,4); // xz
console.log(slice1.toString(),slice2.toString());
合并Buffer
Buffer.concat(list[,totalLength]),返回一个合并了list中所有Buffer实例的新Buffer;
const buff1 = Buffer.concat([slice1,slice2]);
console.log(buff1);
console.log(buff1.toString());
toJSON() —— 返回JSON对象
const buff = Buffer.from('mp.csdn.net');
console.log(buff.toJSON());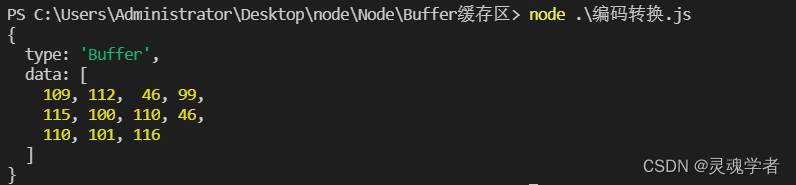
Stream流
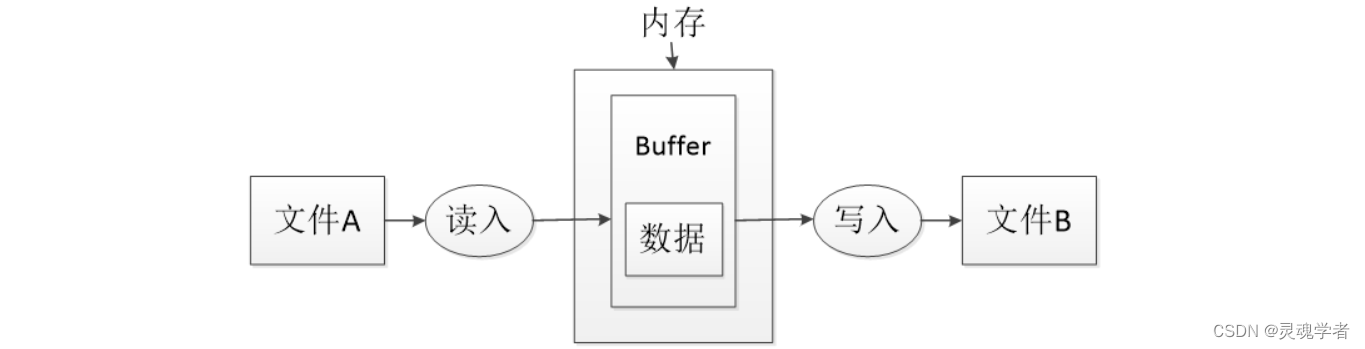 通过之前的fs文件系统模块,如果对一个很大的数据文件进行网络读写传输的话,需要通过fs.readFile()读取文件 - fs.writeFile()写入文件,这个读写过程对整个文件的全部内容进行一次性完整读写,由于Buffer缓冲区的限制在1GB,超过就无法直接完成读写,所以Node.js对于大数据的读写就出现问题,随之出现的就是Stream流来解决!
通过之前的fs文件系统模块,如果对一个很大的数据文件进行网络读写传输的话,需要通过fs.readFile()读取文件 - fs.writeFile()写入文件,这个读写过程对整个文件的全部内容进行一次性完整读写,由于Buffer缓冲区的限制在1GB,超过就无法直接完成读写,所以Node.js对于大数据的读写就出现问题,随之出现的就是Stream流来解决!
fs流是Node.js的抽象接口,fs流的最大作用就是读取大文件的过程,不会一次性的全读而是每次只读数据源的一个数据块,数据处理完后会进入垃圾回收机制!
在Node.js中,文件流的类型有四种:1.Readable可读 2.Writeable可写 3.Duplex可读可写 4.Transform操作被写入,然后读出结果;
| data 事件 | 当有数据可读时触发 |
| end事件 | 没有更多的数据可读时触发 |
| error事件 | 在接收和写入过程中发生错误异常时触发 |
| finish事件 | 所有数据已被写入底层系统时触发 |
fs.createReadStream() —— 创建可读流
fs.createReadStream(path[,options])可以来创建fs可读流,用于从流中读取数据;
// createReadStream.js文件
const fs = require('fs');
const path = require('path');
var data = '';
const readStream = fs.createReadStream(path.join(__dirname + '/read.txt'))
readStream.setEncoding('utf-8');
readStream.on('data',function(chunk){ // 有数据时触发
data += chunk;
})
readStream.on('end',function(){ // 没有数据时触发
console.log('该文件内容中无内容!')
})
readStream.on('error',function(err){
console.log('出现异常:',err.stack); // 打开文件出现异常时触发
})
console.log('程序执行完成!')
/read.txt 能够正常读取,改为/reads.txt(无该文件),使其读取异常报错;

fs.createWriteStream() —— 创建可写流
fs.createWriteStream(path[,options])可以来创建可写流,也称写入流;
// createWriteStream.js文件
const fs = require('fs');
const path = require('path');
var data = 'syan123将会写入到read.txt文件中';
const writeStream = fs.createWriteStream(path.join(__dirname + '/read.txt'));
writeStream.write(data,'utf-8');
writeStream.end();
// 数据处理 ——> finish,error
writeStream.on('finish',function(){
console.log("写入完成!");
})
writeStream.on('error',function(err){
console.log("出现异常:",err.stack);
})
![]()

管道流 —— pipe()
readable.pipe(destination[,options]),管道流是可读流的一种方法,通过用于从一个流中获取数据并将数据传递到另外一个流中,将可读流的信息通过管道方式写入可写流的一种数据写入方式;
// pipe.js文件
const fs = require('fs');
const path = require('path');
const readStream = fs.createReadStream(__dirname + '/input.txt');
const writeStream = fs.createWriteStream(__dirname + '/output.txt');
readStream.pipe(writeStream);
console.log('—— <complete> ——');![]()


链式流
将输出流与另外一个流连接起来并创建多个流操作链的机制,这种流通常会用在管道流上能够对单个可读流上绑定多个可写流操作链;
1)可读流读取input.txt文件 —— pipe() 进行压缩 —— pipe() 进行写入流写入output.txt 文件
const fs = require('fs');
const path = require('path');
const zlib = require('zlib'); // zlib压缩文件模块
const inp = fs.createReadStream(path.join(__dirname+'/input.txt'));
const out = fs.createWriteStream(path.join(__dirname+'/input.txt.rar'));
inp.pipe(zlib.createGzip()).pipe(out);
console.log('File压缩完成!')![]()

2)可读流读取压缩文件input.txt.rar —— pipe() 进行解压 —— pipe() 进行写入流写入out.txt 文件
const inp = fs.createReadStream(path.join(__dirname + '/input.txt.rar'));
const out = fs.createWriteStream(path.join(__dirname + '/out.txt'));
inp.pipe(zlib.createGunzip()).pipe(out);
console.log("File解压完成!")![]()

