【数据驱动测试】从方法探研到最佳实践
导读
在自动化测试实践中,测试数据是制造测试场景的必要条件,本文主要讲述了在沟通自动化框架如何分层,数据如何存储,以及基于单元测试pytest下如何执行。并通过实践案例分享,提供数据驱动测试的具体落地方案。
基本概念
数据驱动测试(DDT)是一种方法,其中在数据源的帮助下重复执行相同顺序的测试步骤,以便在验证步骤进行时驱动那些步骤的输入值和/或期望值。在数据驱动测试的情况下,环境设置和控制不是硬编码的。换句话说,数据驱动的测试是在框架中构建要与所有相关数据集一起执行的测试脚本,该脚本利用了可重用的测试逻辑。数据驱动的测试提供了可重复性,将测试逻辑与测试数据分离以及减少测试用例数量等优势。
设计思路
1.测试数据
在测试过程中往往需要更加充分地测试场景,而创建数据测试。测试数据包括输入输出,对输出的自动化验证等。创建测试数据,可以通过手动拼装,生产环境拷贝,或通过自动化工具生成。
2.数据存储
数据驱动测试中使用的数据源可以是Excel文件,CSV文件,Yaml文件,数据池,ADO对象或ODBC源。
3.数据驱动优势
-
如果应用程序开发还在进行当中,测试者仍然可以进行脚本的编写工作。
-
减少了冗余和不必要的测试脚本。
-
用较少的代码生成测试脚本。
-
所有信息,如输入、输出和预期结果,都以适当的文本记录形式进行存储。
-
为应用程序的维护提供利了灵活性条件。
-
如果功能发生了变化,只需要调整特定的函数脚本。
实践分享
基于Laputa框架现有测试脚本,抽离测试数据与测试逻辑,实现数据驱动测试。
Laputa框架简介:Laputa框架基于 Pytest 集成了对API接口自动化, 以及对 Web应用, 移动端应用和 Windows 桌面应用 UI 等自动化的能力。具有可视化的Web界面工具, 便于配置执行规则,关联执行脚本, 触发用例执行,查看执行结果。提供CI集成服务,调用Jenkins API跟踪持续集成结果,开放接口,实现流水线自动化测试。
1.环境依赖
(1)参数化配置方式
pytest参数化有两种方式:
@pytest.fixture(params=[])
@pytest.mark.parametrize()
两者都会多次执行使用它的测试函数,但@pytest.mark.parametrize()使用方法更丰富一些,laputa更建议使用后者。
(2)用 parametrize 实现参数化
parametrize( ) 方法源码:
【python】
def parametrize(self,argnames, argvalues, indirect=False, ids=None, scope=None):
- 主要参数说明
(1)argsnames :参数名,是个字符串,如中间用逗号分隔则表示为多个参数名。
(2)argsvalues :参数值,参数组成的列表,列表中有几个元素,就会生成几条用例。
- 使用方法
(1)使用 @pytest.mark.paramtrize() 装饰测试方法;
(2)parametrize('data', param) 中的 “data” 是自定义的参数名,param 是引入的参数列表;
(3)将自定义的参数名 data 作为参数传给测试用例 test_func;
(4)在测试用例内部使用 data 的参数。
创建测试用例,传入三组参数,每组两个元素,判断每组参数里面表达式和值是否相等,代码如下:
【python】
@pytest.mark.parametrize("test_input,expected",[("3+5",8),("2+5",7),("7*5",30)])
def test_eval(test_input,expected):
# eval 将字符串str当成有效的表达式来求值,并返回结果
assert eval(test_input) == expected
运行结果:
【python】
test_mark_paramize.py::test_eval[3+5-8]test_mark_paramize.py::test_eval[2+5-7]
test_mark_paramize.py::test_eval[7*5-35]
============================== 3 passed in 0.02s ===============================
整个执行过程中,pytest 将参数列表 ("3+5",8),("2+5",7),("7*5",30) 中的三组数据取出来,每组数据生成一条测试用例,并且将每组数据中的两个元素分别赋值到方法中,作为测试方法的参数由测试用例使用。
(3)多次使用 parametrize
同一个测试用例还可以同时添加多个 @pytest.mark.parametrize 装饰器, 多个 parametrize 的所有元素互相组合(类似笛卡儿乘积),生成大量测试用例。
场景:比如登录场景,用户名输入情况有 n 种,密码的输入情况有 m 种,希望验证用户名和密码,就会涉及到 n*m 种组合的测试用例,如果把这些数据一一的列出来,工作量也是非常大的。pytest 提供了一种参数化的方式,将多组测试数据自动组合,生成大量的测试用例。示例代码如下:
【python】
@pytest.mark.parametrize("x",[1,2])@pytest.mark.parametrize("y",[8,10,11])
def test_foo(x,y):print(f"测试数据组合x: {x} , y:{y}")
运行结果:
【python】
test_mark_paramize.py::test_foo[8-1]
test_mark_paramize.py::test_foo[8-2]
test_mark_paramize.py::test_foo[10-1]
test_mark_paramize.py::test_foo[10-2]
test_mark_paramize.py::test_foo[11-1]
test_mark_paramize.py::test_foo[11-2]
分析如上运行结果,测试方法 test_foo( ) 添加了两个 @pytest.mark.parametrize() 装饰器,两个装饰器分别提供两个参数值的列表,2 * 3 = 6 种结合,pytest 便会生成 6 条测试用例。在测试中通常使用这种方法是所有变量、所有取值的完全组合,可以实现全面的测试。
(4) @pytest.fixture 与 @pytest.mark.parametrize 结合
下面讲讲结合 @pytest.fixture 与 @pytest.mark.parametrize 实现参数化。
如果测试数据需要在 fixture 方法中使用,同时也需要在测试用例中使用,可以在使用 parametrize 的时候添加一个参数 indirect=True,pytest 可以实现将参数传入到 fixture 方法中,也可以在当前的测试用例中使用。
parametrize 源码:
【python】
def parametrize(self,argnames, argvalues, indirect=False, ids=None, scope=None):
indirect 参数设置为 True,pytest 会把 argnames 当作函数去执行,将 argvalues 作为参数传入到 argnames 这个函数里。创建“test_param.py”文件,代码如下:
【python】
# 方法名作为参数
test_user_data = ['Tome', 'Jerry']
@pytest.fixture(scope="module")
def login_r(request):
# 通过request.param获取参数
user = request.param
print(f"\n 登录用户:{user}")return user
@pytest.mark.parametrize("login_r", test_user_data,indirect=True)
def test_login(login_r):
a = login_r
print(f"测试用例中login的返回值; {a}")
assert a != "
运行结果:
【plain】
登录用户:Tome PASSED [50%]测试用例中login的返回值; Tome
登录用户:Jerry PASSED [100%]测试用例中login的返回值; Jerry
上面的结果可以看出,当 indirect=True 时,会将 login_r 作为参数,test_user_data 被当作参数传入到 login_r 方法中,生成多条测试用例。通过 return 将结果返回,当调用 login_r 可以获取到 login_r 这个方法返回数据。
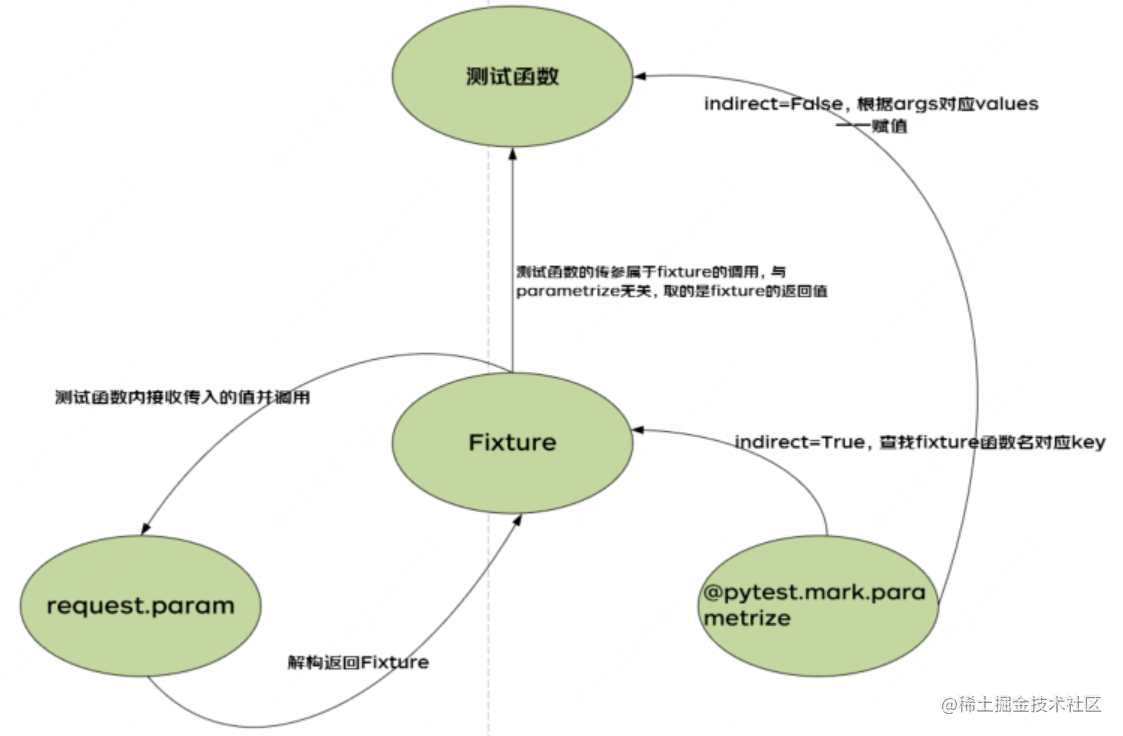
图1 @pytest.fixture 与 @pytest.mark.parametrize 结合读取数据图例
(5)conftest作用域
其作用范围是当前目录包括子目录里的测试模块。
(1)如果在测试框架的根目录创建conftest.py文件,文件中的Fixture的作用范围是所有测试模块。
(2)如果在某个单独的测试文件夹里创建conftest.py文件,文件中Fixture的作用范围,就仅局限于该测试文件夹里的测试模块。
(3)该测试文件夹外的测试模块,或者该测试文件夹外的测试文件夹,是无法调用到该conftest.py文件中的Fixture。
(4)如果测试框架的根目录和子包中都有conftest.py文件,并且这两个conftest.py文件中都有一个同名的Fixture,实际生效的是测试框架中子包目录下的conftest.py文件中配置的Fixture。
3.代码Demo
测试数据存储yaml文件:
【YAML】
测试流程:[
{"name":"B2B普货运输三方司机流程","senior":{"createTransJobResource":"B2B","createType":"三方","platformType":2}},
{"name":"B2B普货运输三方司机逆向流程","senior":{"isback":"True","createTransJobResource":"B2B","createType":"三方","platformType":2}},
]
测试数据准备,定义统一读取测试数据方法:
【python】
def dataBuilder(key):dires = path.join(dires, "test_data.yaml")
parameters = laputa_util.read_yaml(dires)[key]
name = []
senior = []
for item in parameters:
name.append(item['name'] if 'name' in item else '')
senior.append(item['senior'] if 'senior' in item else '')
return name, senior
测试用例标识,通过@pytest.mark.parametrize方法驱动用例:
【python】
class TestRegression:
case, param = dataBuilder('测试流程')
@pytest.mark.parametrize("param", param, ids=case)
def test_regression_case(self, param):
# 调度
res = create_trans_bill(params)
trans_job_code = res['data']['jobcode']
carrier_type = params['createType'] if params['createType'] in ('自营', '三方') else '个体'
# 执行
work_info = select_trans_work_info_new(trans_job_code)
trans_work_code = work_info['trans_work_code']
if 'isback' in params and params['isback']:
execute_param.update(isBack=params['isback'])
execute_bill_core(**execute_param)
# 结算
if carrier_type != '自营':
trans_fee_code = CreateTransFeeBillBase.checkTF(trans_job_code)
receive_trans_bill_core(**bill_param)
总结
日常测试过程中,无论是通过手动执行或者脚本执行,都需要利用数据驱动设计思路,这有助于提高测试场景覆盖率,测试用例的健壮性和复用性,及需求测试效率。通过数据驱动测试不仅可以得到更好的投资回报率,还可以达到质效合一的测试流程。
B站2023年最详细的python自动化测试框架全栈测试开发技术入门到精通教程_哔哩哔哩_bilibili