HEVC学习之CTU划分
一,CTU相关概念
H.265将图像划分为“树编码单元(coding tree units, CTU)”,而不是像H.264那样的16×16的宏块。根据不同的编码设置,树编码块的尺寸可以被设置为64×64或有限的32×32或16×16。
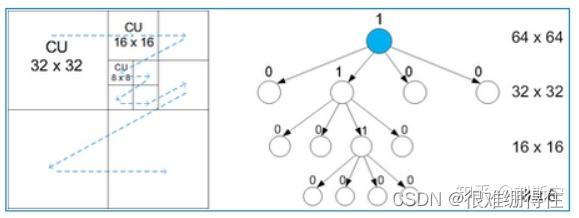
上图就是一个64×64树编码块的分区示例,每个树编码块可以被递归分割,利用四叉树结构,分割为32×32、16×16、8×8的子区域。
右侧四叉树中每个节点有4个子节点,依次对应CU块中左上、右上、左下、右下子块,若子块需要继续划分,则该四叉树该子节点下方还由4个子节点。此外还能看到随着二叉树深度加深,对应的CU尺寸也是逐渐减少。
如下图所示,一个CTU由1个亮度CTB和两个色度CTB,一个语法元素组成,其中B(Block)是真正存储数据的地方。若采用YUV420格式,其中的色度CTB的长宽都是亮度CTB的1/2
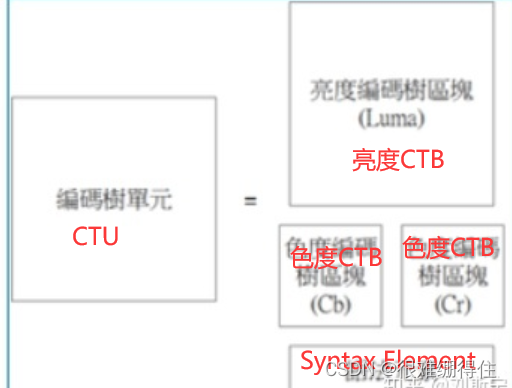
。编码树单元可向下分成编码单元(Coding Unit,CU)、预测单元(Prediction Unit,PU)及转换单元(Transform Unit,TU)。
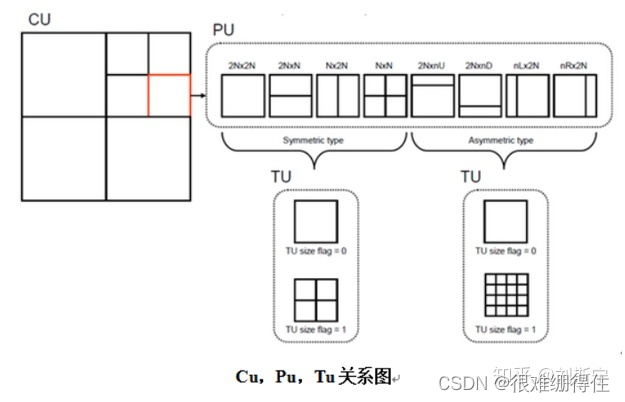
PU:在转换和量化之前,首先是预测阶段(包括帧内预测和帧间预测)。一个编码单元CU可以使用以下八种预测模式中的一种进行预测。编码单元与预测单元的不同之处在于预测单元只能被切割一次。预测单元PU规定了编码单元的所有预测模式,一切与预测有关的信息都定义在预测单元部分。比如,帧内预测的方向、帧间预测的分割方式、运动矢量预测,以及帧间预测参考图像索引号都属于预测单元的范畴。
TU:转换单元是呈现残量(Residual)或是转换系数(Transform Coefficients)的区块,这个区块主要是做整数转换(Integer Transform)或是量化(Quantization)。变换单元是独立完成变换和量化的基本单元,其尺寸也是灵活变化的。根据预测残差的局部变化特性,TU可以自适应地选择最优的模式。大块的TU模式能够将能量更好地集中,小块的TU模式能够保存更多的图像细节。 这种灵活的分割结构,可以使变换后的残差能量得到充分压缩,以进一步提高编码增益。
参考:http://t.zoukankan.com/sddai-p-14365572.html
二、HM中CTU划分的代码
HM代码框架:
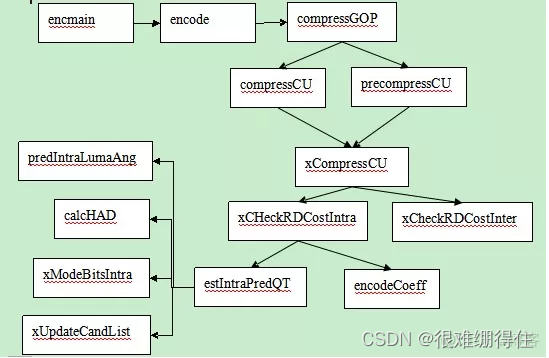
01.encmain函数:中主要做了编码器对象的创建、分析配置文件,初始化配置参数,和编码器最重要的功能"encode"。
02.encode函数:主要实现了读取YUV文件的数据、初始化工具对象例如:GOPEncoder、SliceEncoder、CUEncder……。在此函数里,还包括一个encode函数,调用CompressGOP函数来具体执行编码任务。
03.CompressGOP函数:InitGOP将文件的码流分成若干GOP以便后续程序能够顺利执行,InitEncSlice创建编码的Slice。
03.preCompressSlice和CompressSlice两个函数:前者的作用是选择不同的lamuda进行编码(编码是调用了CompressCU函数,后续介绍),后者是在最好的lamuda下进行编码。
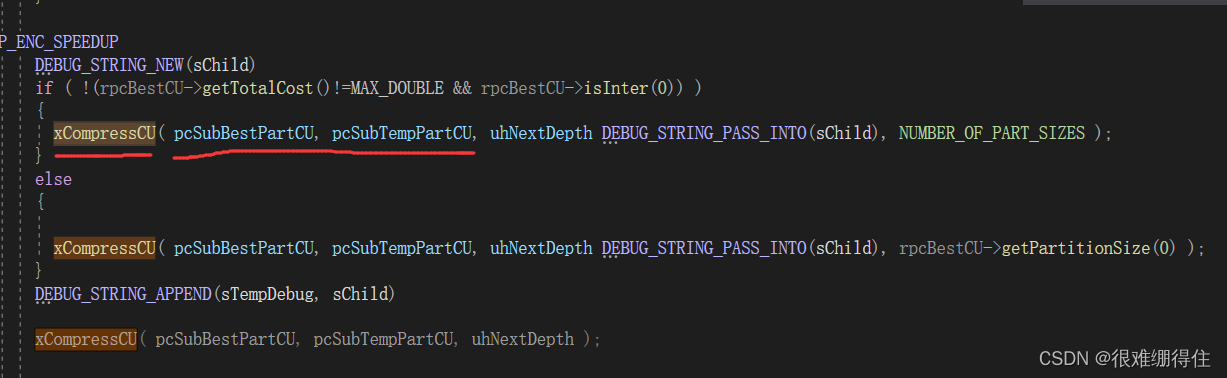
04.xCompressCU函数:CompressCU函数的主体也是调用xComprssCU函数),先进行帧间预测xCheckRDCostMerge2Nx2N,xCheckRDCostInter等。在做完帧间预测后进行阵内预测,这是调用的函数是xCheckRDCostIntra,在xCompressCU函数的后续部分,还递归调用自身以实现对每个CU的编码。变换编码在encodeCoeff中实现,量化在xCheckIntraPCM完成。
5.xCheckRDCostIntra函数,主要完成帧内预测的任务,对亮度的预测使用estIntraPredQT,对色度使用estIntraPredChromaQT。predIntraLumaAng函数实现了方向的预测;calcHAD函数计算了SATD;xModeBitsIntra函数计算编码的码率;xUpdateCandList更新了最好的RDCost所使用的模式。
参考:https://blog.51cto.com/u_15785281/5663436
于是我们查看CompressCU(这里看的是compressCTU)函数,该函数主要任务是调用XCompressCU,Xcompresscu 主要完成块划分(包括CU,PU,TU划分),pu预测模式选择,期间继续调用函数完成帧间预测帧内预测,PCM模式测试,因此在Xcompress函数完成块划分后用TComDataCU* DepthCU来存放划分信息
Void TEncCu::compressCtu( TComDataCU* pCtu )
{
// initialize CU data
m_ppcBestCU[0]->initCtu( pCtu->getPic(), pCtu->getCtuRsAddr() );
m_ppcTempCU[0]->initCtu( pCtu->getPic(), pCtu->getCtuRsAddr() );
// analysis of CU
DEBUG_STRING_NEW(sDebug)
xCompressCU( m_ppcBestCU[0], m_ppcTempCU[0], 0 DEBUG_STRING_PASS_INTO(sDebug) );
ofstream DepthInfo;
TComDataCU* DepthCU = m_ppcBestCU[0];
DepthInfo.open("BestDepth.txt", ios::app);
for (UInt iPartitionNum = 0; iPartitionNum < DepthCU->getTotalNumPart(); iPartitionNum++)
{
DepthInfo << DepthCU->getDepth()[iPartitionNum];
}
DepthInfo.close();
DEBUG_STRING_OUTPUT(std::cout, sDebug)
#if ADAPTIVE_QP_SELECTION
if( m_pcEncCfg->getUseAdaptQpSelect() )
{
if(pCtu->getSlice()->getSliceType()!=I_SLICE) //IIII
{
xCtuCollectARLStats( pCtu );
}
}
#endif
}
xCompressCU( m_ppcBestCU[0], m_ppcTempCU[0], 0 DEBUG_STRING_PASS_INTO(sDebug) );
第一个参数为最佳CU划分信息,第二个参数为当前评估的CU信息,第三个参数是 CU的分割深度。64x64的深度为0
在其中可以看到递归对字块划分的代码:
三,CTU划分直观展示
将CU划分方法文件通过matlab直观展示在压缩后的YUV序列中:

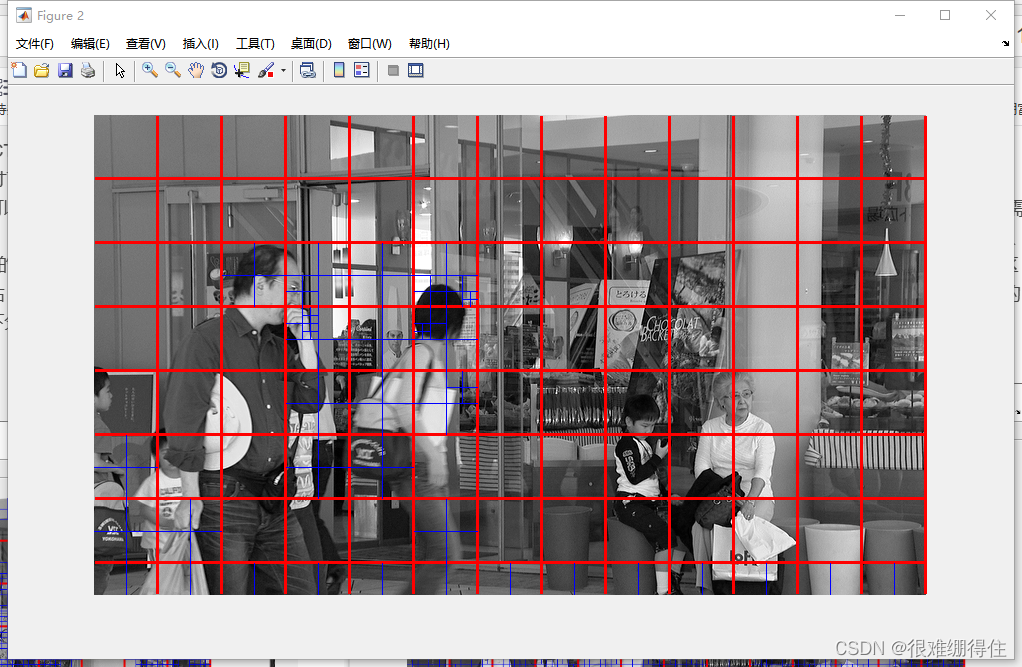
可以看到,figure1的块划分远比figure2的细致,再打开HEVC分析软件查看:
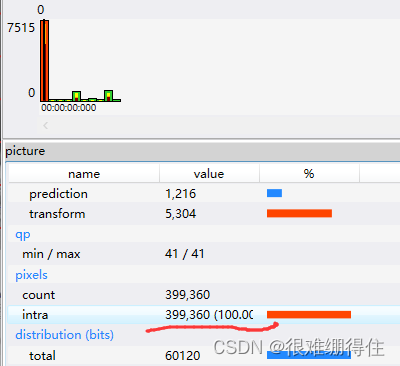
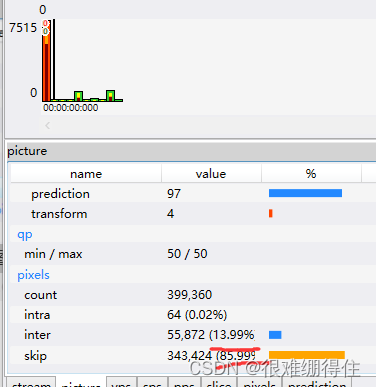
可以看到figure1位为I帧,采用的全是帧内编码,figure2为P帧,其中0.02%的帧内编码,13.99%的帧间编码,85.99%的skip模式(跳过型CU只能采用帧间预测模式,而且产生的运动向量和图像的残差信息不需要传送给解码器)。
再查看这两帧与压缩前帧之差:
figure1:

figure2:

可以看到figure2的残差中不会因为采取了skip策略残差就变少,因此只提取CU信息去辅助压缩视频多帧增强任务是不准确的