WebMagic
1.介绍
WebMagic是一款简单灵活的爬虫框架。基于它你可以很容易的编写一个爬虫。
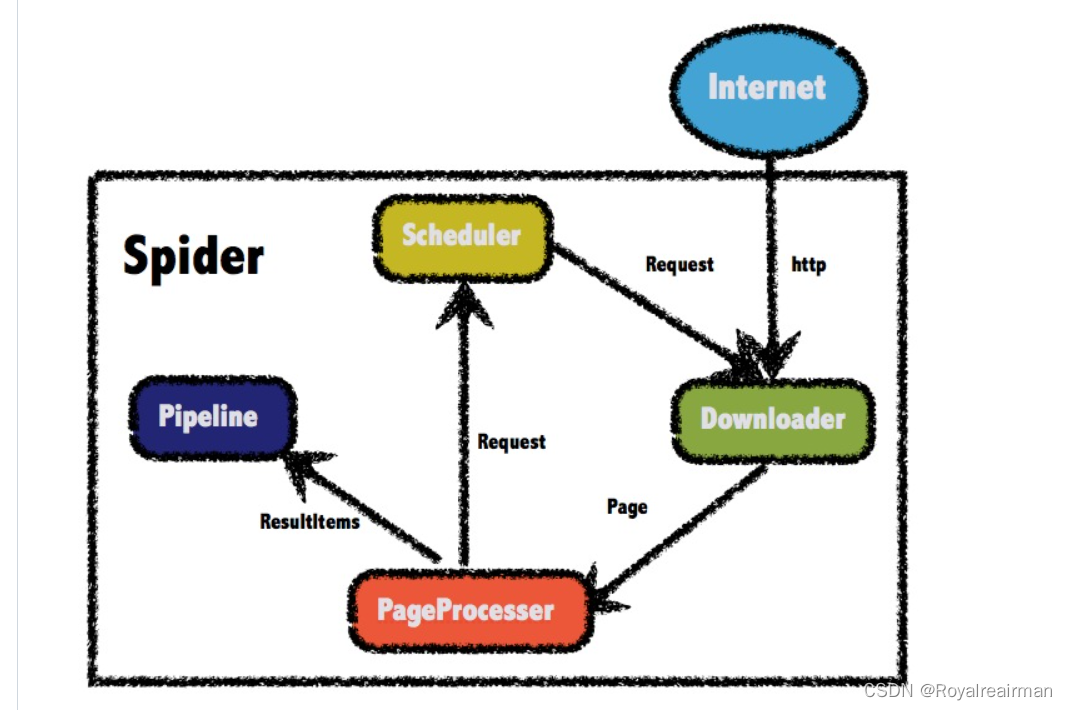
WebMagic由四个组件(Downloader、PageProcessor、Scheduler、Pipeline)构成,核心代码非常简单,主要是将这些组件结合并完成多线程的任务。这意味着,在WebMagic中,你基本上可以对爬虫的功能做任何定制。
Introduction · WebMagic Documents
2.依赖
注意:0.74以前的版本存在ssl并不完全的问题, 新版没得这个问题
github上面有方法https://github.com/code4craft/webmagic/issues/1022
<!--WebMagic-->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.4</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.4</version>
</dependency>3.基础案列
在学习WebMagic,你要jsoup或者其他爬虫框架有一定的了解,不明白我css写的什么意思,可以去看一下我jsoup的选择器
//页面处理类
public class JobProcessor implements PageProcessor {
//解析页面
@Override
public void process(Page page) {
//解析放回的数据放到page 并且把解析的结果放到 resultems中
page.putField("div",page.getHtml().css("div.search-m a").all());
}
private Site site =Site.me();
@Override
public Site getSite() {
return site;
}
//主函数执行爬虫
public static void main(String[] args) {
Spider.create(new JobProcessor()).addUrl("https://**.jd.com/").run();
}
}
4.抽取技术
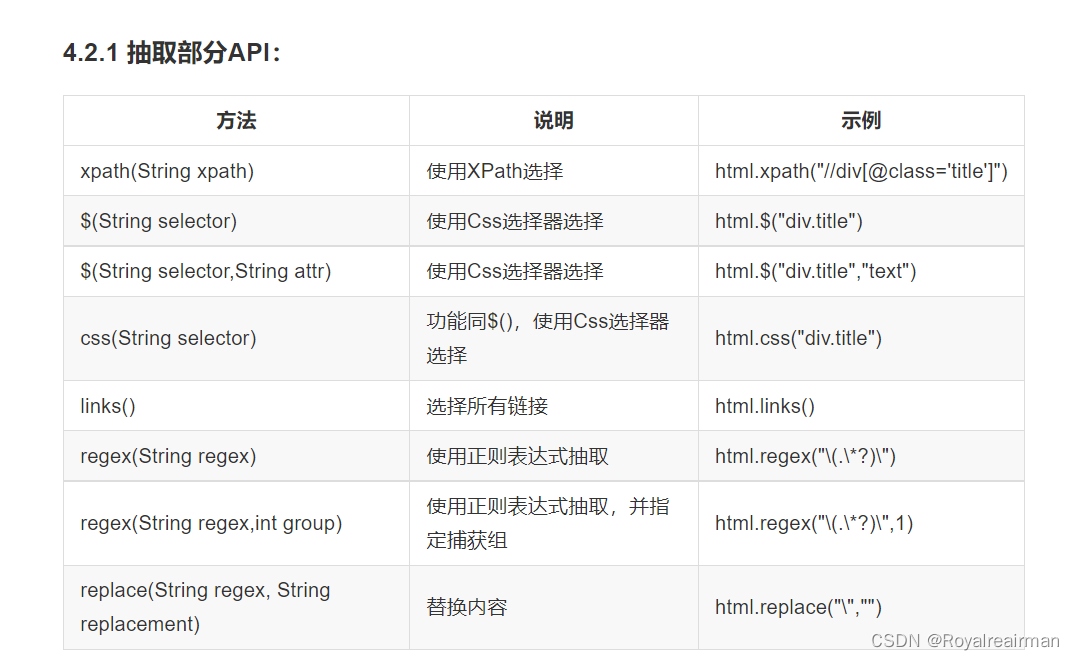
webMagic一共有三种 css选择器 、Xpath 和正则表达式,css这里不叙说
Xpath
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
因此,对 XPath 的理解是很多高级 XML 应用的基础。
XPath 教程
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
//页面处理类
public class JobProcessor implements PageProcessor {
//解析页面
@Override
public void process(Page page) {
//解析放回的数据放到page 并且把解析的结果放到 resultems中 css解析
page.putField("div",page.getHtml().css("div.search-m a").all());
//xpath 解析
page.putField("div2", page.getHtml().xpath("//div[@class=search-m]"));
}
private Site site = Site.me();
@Override
public Site getSite() {
return site;
}
//主函数执行爬虫
public static void main(String[] args) {
Spider.create(new JobProcessor()).addUrl("https://**.jd.com/").run();
}
}
正则表达式
Java 正则表达式 | 菜鸟教程
//页面处理类
public class JobProcessor implements PageProcessor {
//解析页面
@Override
public void process(Page page) {
//解析放回的数据放到page 并且把解析的结果放到 resultems中 css解析
page.putField("div",page.getHtml().css("div.search-m a").all());
//xpath 解析
page.putField("div2", page.getHtml().xpath("//div[@class=search-m]").all());
//正则表达式
page.putField("div3",page.getHtml().regex(".*电脑.*").all());
}
获取连接
我们在浏览一个网站,往往需要看的是点击后的信息,这里就需要引入获取连接的方法
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
//页面处理类
public class JobProcessor implements PageProcessor {
//解析页面
@Override
public void process(Page page) {
page.addTargetRequests(page.getHtml().css("div#logo").links().all());
page.putField("url",page.getHtml().all());
}
private Site site = Site.me();
@Override
public Site getSite() {
return site;
}
//主函数执行爬虫
public static void main(String[] args) {
Spider.create(new JobProcessor()).addUrl("https://**.jd.com/").run();
}
}
文件输出
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.FilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
//页面处理类
public class JobProcessor implements PageProcessor {
//解析页面
@Override
public void process(Page page) {
page.addTargetRequests(page.getHtml().css("div#logo").links().all());
page.putField("url",page.getHtml().all());
}
private Site site = Site.me();
@Override
public Site getSite() {
return site;
}
//主函数执行爬虫
public static void main(String[] args) {
Spider.create(new JobProcessor()).addUrl("https://**.jd.com/")
.addPipeline(new FilePipeline("E:\\java\\jsoup"))
.run();
}
}
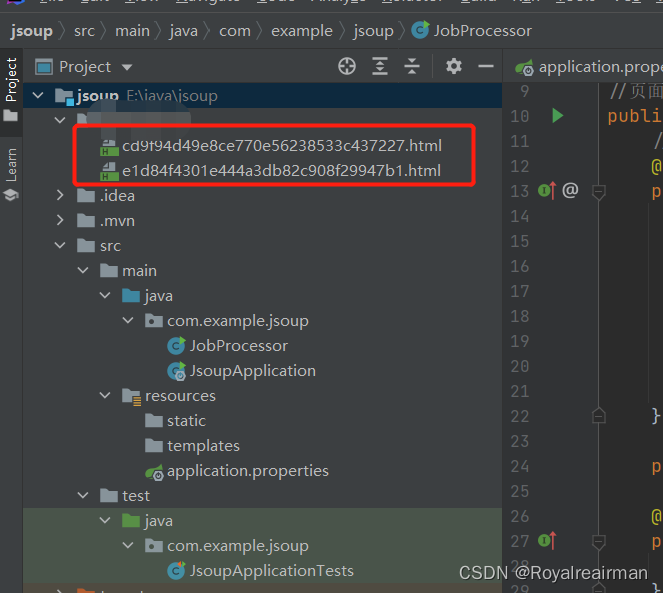
改目录下已经有文件了
爬虫的其他设置
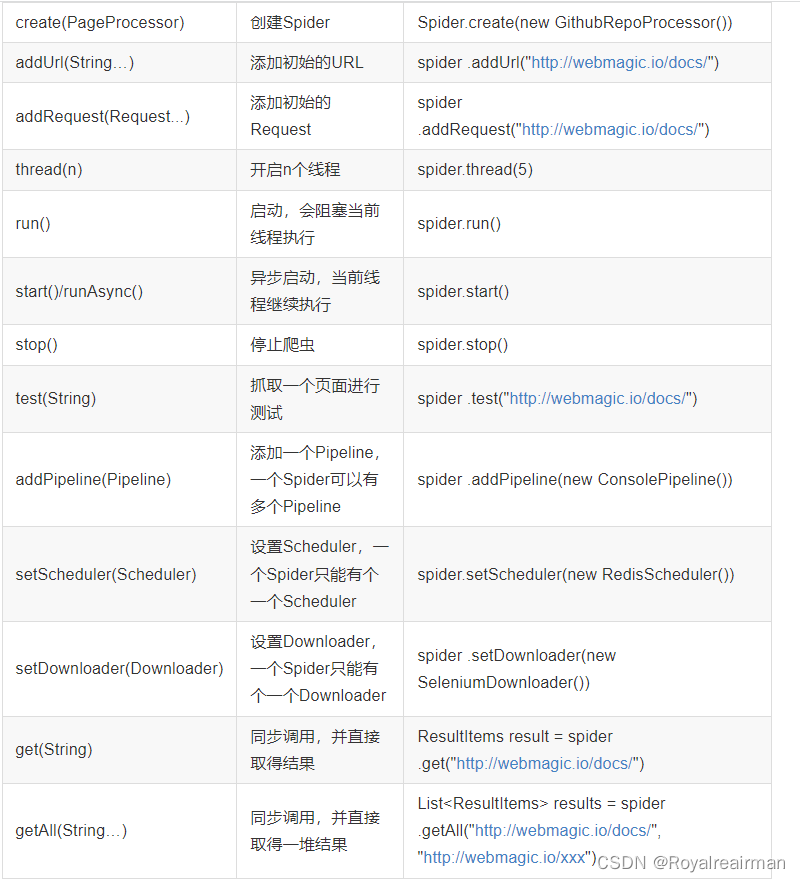
Spider是爬虫启动的入口。在启动爬虫之前,我们需要使用一个PageProcessor创建一个Spider对象,然后使用run()进行启动。同时Spider的其他组件(Downloader、Scheduler、Pipeline)都可以通过set方法来进行设置。
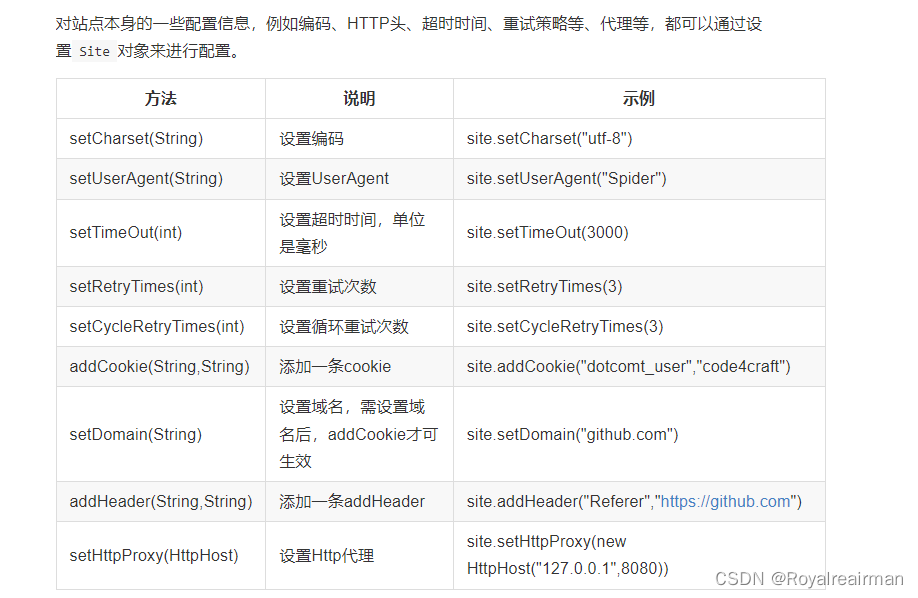
Site
对站点本身的一些配置信息,例如编码、HTTP头、超时时间、重试策略等、代理等,都可以通过设置Site对象来进行配置
5.基于注解的开发
WebMagic支持使用独有的注解风格编写一个爬虫,引入webmagic-extension包即可使用此功能。
在注解模式下,使用一个简单对象加上注解,可以用极少的代码量就完成一个爬虫的编写。对于简单的爬虫,这样写既简单又容易理解,并且管理起来也很方便。这也是WebMagic的一大特色,我戏称它为OEM(Object/Extraction Mapping)。
注解模式的开发方式是这样的:
- 首先定义你需要抽取的数据,并编写类。
- 在类上写明
@TargetUrl注解,定义对哪些URL进行下载和抽取。 - 在类的字段上加上
@ExtractBy注解,定义这个字段使用什么方式进行抽取。 - 定义结果的存储方式。
@TargetUrl("https://github.com/\\w+/\\w+") //初始的url
@HelpUrl("https://github.com/\\w+") //第二次的网址
public class GithubRepo {
@ExtractBy(value = "//h1[@class='entry-title public']/strong/a/text()", notNull = true)
private String name;
@ExtractByUrl("https://github\\.com/(\\w+)/.*")
private String author;
@ExtractBy("//div[@id='readme']/tidyText()")
private String readme;
public static void main(String[] args) {
OOSpider.create(Site.me().setSleepTime(1000)
, new ConsolePageModelPipeline(), GithubRepo.class)
.addUrl("https://github.com/code4craft").thread(5).run();
}
}我这里只是简单的说了一下,想要详细的操作可以看一下官方文档,写的真的很详细