损失函数
L
(
y
i
,
y
^
i
)
L(y_i,\hat{y}_i)
L(yi,y^i)用来描述神经网络的输出
y
^
i
\hat{y}_i
y^i和基本事实(Ground Truth,GT)
y
i
y_i
yi的差异
对于回归问题,常用均方误差(Mean Square Error,MSE)损失函数
L
(
y
i
,
y
^
i
)
=
∥
y
i
−
y
^
i
∥
2
2
L(y_i,\hat{y}_i)=\left \| y_i-\hat{y}_i \right \|_2^2
L(yi,y^i)=∥yi−y^i∥22
神经网络的训练过程就是寻找一组参数
θ
\theta
θ,使得神经网络在一个batch的训练上,损失函数的和最小
θ
=
arg
min
θ
∑
i
=
1
N
L
(
y
i
,
y
^
i
)
\theta=\arg\min_{\theta}\sum_{i=1}^{N}L(y_i,\hat{y}_i)
θ=argθmini=1∑NL(yi,y^i)
得到概率分布后,使用交叉熵(Cross Entropy,CE)损失函数,计算预测的概率分布,与真实的概率分布之间的差距,假设概率分布的向量维度为K
H
(
p
,
q
)
=
−
∑
i
=
1
K
p
i
⋅
ln
q
i
H(p,q)=-\sum_{i=1}^{K}p_i\cdot\ln q_i
H(p,q)=−i=1∑Kpi⋅lnqi 其中,
p
p
p是真实的概率分布,采用独热向量(One-hot Vector),即只有真实说话人对应的值为1,其他的值都为0
q
q
q是预测的概率分布,经过Softmax激活函数之后,最大值接近1,所有值求和等于1
由于
p
p
p为独热向量,所以损失函数简化为
H
(
p
,
q
)
=
−
ln
q
j
H(p,q)=-\ln q_j
H(p,q)=−lnqj,
q
j
q_j
qj指预测的概率分布中,真实说话人对应的概率
H
(
p
,
q
)
H(p,q)
H(p,q)的值越小,代表两个分布越接近
训练时:在训练数据上,最小化
H
(
p
,
q
)
H(p,q)
H(p,q)来优化参数
运行时:直接使用嵌入码,用于说话人识别(可用余弦相似度、欧氏距离等)
这种方法的缺点
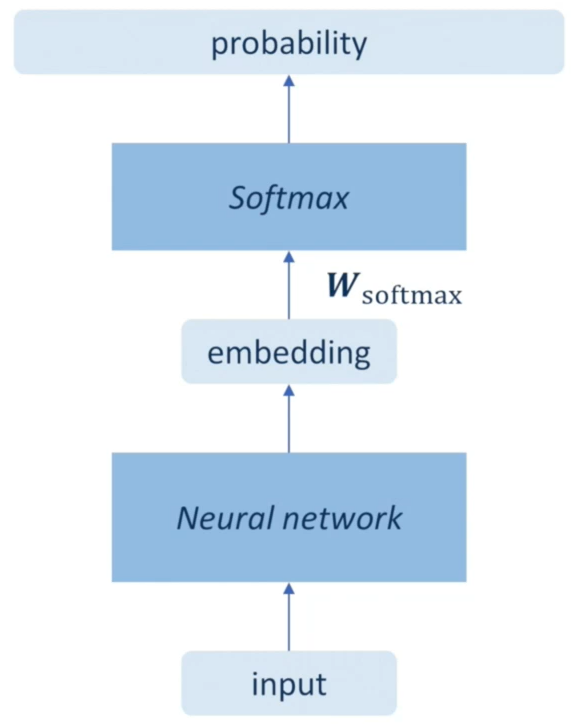
用于计算概率分布的MLP,其参数会随着训练数据说话人数量线性增加
例如嵌入码的维度是1280,训练数据有1000人,那么MLP的参数矩阵
W
S
o
f
t
m
a
x
∈
R
1000
×
1280
W_{Softmax} \in R^{1000 \times 1280}
WSoftmax∈R1000×1280,光是MLP的参数量就达到了128万
训练集中,部分说话人的数据量较少,这意味着
W
S
o
f
t
m
a
x
W_{Softmax}
WSoftmax中,有部分参数极少发挥作用,但是前向传播时每次都需要计算整个矩阵,这导致训练过程中,花费了大量的资源用于优化几乎没有用的参数
W
S
o
f
t
m
a
x
W_{Softmax}
WSoftmax只在训练时发挥作用,与运行时的相似度计算不完全一致,这会导致网络难以泛化到训练集中未出现过的说话人
将
W
S
o
f
t
m
a
x
W_{Softmax}
WSoftmax中的每个行向量
w
r
w_r
wr都限制为单位长度的向量,设嵌入码为
e
e
e,那么
w
r
⋅
e
=
∣
∣
e
∣
∣
cos
θ
i
w_r \cdot e=||e|| \cos \theta_i
wr⋅e=∣∣e∣∣cosθi
W
S
o
f
t
m
a
x
⋅
e
W_{Softmax} \cdot e
WSoftmax⋅e的运算结果,就是
e
e
e的范数,乘以一个余弦值,此时的优化过程,会与运行时的相似度计算更加一致
注意,关于Softmax的计算,如果幂的值很大,取指数会导致溢出(即便是Python也要考虑这个问题),此时需要令输入向量中的每一个值,都减去向量中的最大值,然后再进行标准的Softmax运算,这不影响运算结果,但是保证了数值计算的稳定,原因如下
y
i
=
e
x
p
(
x
i
−
x
m
a
x
)
∑
j
=
i
K
e
x
p
(
x
j
−
x
m
a
x
)
=
e
x
p
(
x
i
)
/
e
x
p
(
x
m
a
x
)
∑
j
=
i
K
[
e
x
p
(
x
j
)
/
e
x
p
(
x
m
a
x
)
]
=
e
x
p
(
x
i
)
∑
j
=
i
K
e
x
p
(
x
j
)
\begin{aligned} y_i&=\frac{exp(x_i-x_{max})}{\sum_{j=i}^{K}exp(x_j-x_{max})} \\ &=\frac{exp(x_i)/exp(x_{max})}{\sum_{j=i}^{K}[exp(x_j)/exp(x_{max})]} \\ &=\frac{exp(x_i)}{\sum_{j=i}^{K}exp(x_j)} \\ \end{aligned}
yi=∑j=iKexp(xj−xmax)exp(xi−xmax)=∑j=iK[exp(xj)/exp(xmax)]exp(xi)/exp(xmax)=∑j=iKexp(xj)exp(xi)
二值决策
针对多说话人分类方法,训练和运行时,目标不匹配的问题,研究人员提出二值决策方法
给定两个话语,网络对这两个话语进行二值决策:
0,表示两个话语来自不同的说话人
1,表示两个话语来自同一个说话人
损失函数必须基于,由至少两个话语组成的样本,来定义
Pairwise Loss
假设有两个输入
x
i
x_i
xi和
x
j
x_j
xj,它们都进入同一个网络,得到两个嵌入码,两个嵌入码的余弦相似度是
s
i
j
s_{ij}
sij,假设GT表示为:
y
i
j
=
{
0
,
若
x
i
和
x
j
来自不同的说话人
1
,
若
x
i
和
x
j
来自同一个说话人
y_{ij}= \left\{\begin{matrix} 0,若x_i和x_j来自不同的说话人\\ 1,若x_i和x_j来自同一个说话人 \end{matrix}\right.
yij={0,若xi和xj来自不同的说话人1,若xi和xj来自同一个说话人
对应的损失函数为
L
(
s
i
j
,
y
i
j
)
L(s_{ij},y_{ij})
L(sij,yij)
可以将这个问题视为二分类问题,使用二元交叉熵(Binary Cross Entropy,BCE)损失函数
L
B
C
E
(
s
,
y
)
=
−
y
ln
s
−
(
1
−
y
)
ln
(
1
−
s
)
L_{BCE}(s,y)=-y\ln s- (1-y)\ln (1-s)
LBCE(s,y)=−ylns−(1−y)ln(1−s)
由于要对余弦相似度取对数,而余弦相似度可能为负数,所需需要将
s
s
s变换为正数,常见做法:
s
′
=
σ
(
w
s
+
b
)
=
1
1
+
e
x
p
(
−
(
w
s
+
b
)
)
s'=\sigma (ws+b)=\frac{1}{1+exp(-(ws+b))}
s′=σ(ws+b)=1+exp(−(ws+b))1 其中,
w
w
w和
b
b
b都是可学习参数,
w
>
0
w>0
w>0,
σ
(
⋅
)
\sigma(\cdot)
σ(⋅)是Sigmoid函数。从而,损失函数变为
L
B
C
E
(
s
′
,
y
)
L_{BCE}(s',y)
LBCE(s′,y),这就是基于样本对的损失函数Pairwise Loss
缺点:由于网络参数随训练过程变化,所以难以平衡正样本和负样本在训练过程中的数量平衡
Triplet Loss
针对Pairwise Loss的缺点,研究人员提出了基于三元组的损失函数Triplet Loss
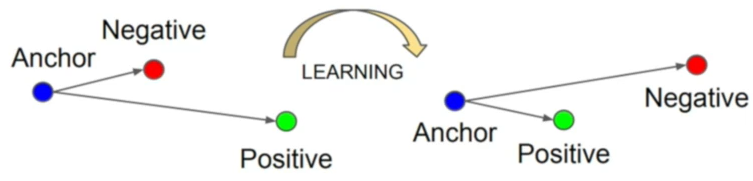
先思考:在设计损失函数时,我们希望给网络的监督信息的效果是什么?
对于同一个说话人的嵌入码,我们希望这两个嵌入码在嵌入码空间中越接近越好
对于不同的说话人的嵌入码,我们希望这两个嵌入码在嵌入码空间中越远离越好
针对上述思考,Triplet Loss需要挑选三个话语:
锚样本(Anchor)
x
a
x^a
xa
正样本(Positive)
x
p
x^p
xp,和锚样本来自同一个说话人
负样本(Negative)
x
n
x^n
xn,和锚样本来自不同的说话人
那么,这三个话语的嵌入码,经过参数更新后效果如下图所示:
数学形式
L
=
[
∥
f
(
x
a
)
−
f
(
x
p
)
∥
2
2
−
∥
f
(
x
a
)
−
f
(
x
n
)
∥
2
2
+
α
]
+
L=[\left \| f(x^a)-f(x^p) \right \|_2^2-\left \| f(x^a)-f(x^n) \right \|_2^2 +\alpha]_+
L=[∥f(xa)−f(xp)∥22−∥f(xa)−f(xn)∥22+α]+ 其中,
[
x
]
+
[x]_+
[x]+表示函数
m
a
x
(
x
,
0
)
max(x,0)
max(x,0)
∥
∥
2
2
\left \| \right \|_2^2
∥∥22表示欧氏距离的平方
上述形式的Triplet Loss常用于人脸识别,对于说话人识别,会将欧氏距离改为余弦相似度:
L
=
[
cos
(
f
(
x
a
)
,
f
(
x
n
)
)
−
cos
(
f
(
x
a
)
,
f
(
x
p
)
)
+
α
]
+
L=[\cos (f(x^a),f(x^n)) - \cos (f(x^a),f(x^p)) +\alpha]_+
L=[cos(f(xa),f(xn))−cos(f(xa),f(xp))+α]+
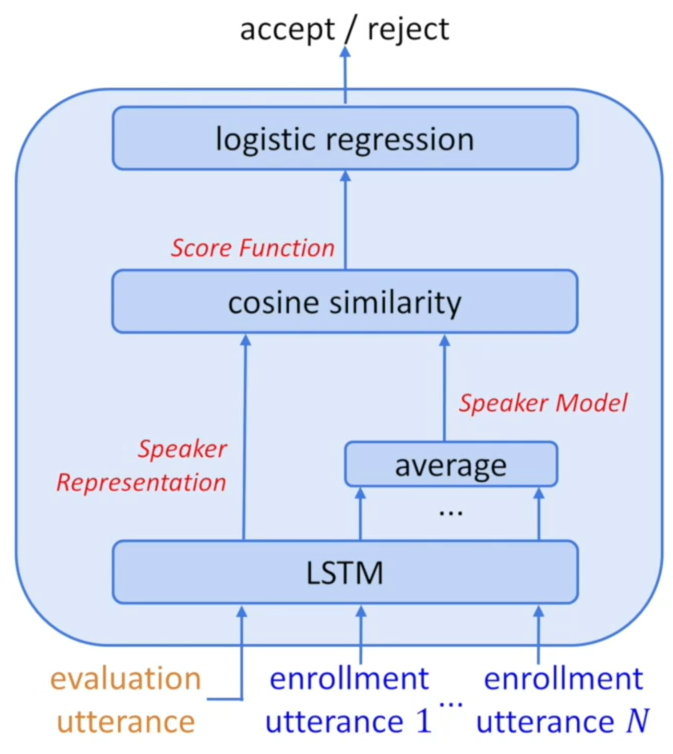
这
N
+
1
N+1
N+1个话语,经过同一个神经网络,其中来自真实说话人的
N
N
N个话语的嵌入码,被聚合(通常是取平均),成为说话人模型
另外一个嵌入码,与说话人模型计算余弦相似度
余弦相似度经过变换成为正数,然后计算二元交叉熵损失
s
′
=
σ
(
w
s
+
b
)
=
1
1
+
e
x
p
(
−
(
w
s
+
b
)
)
L
B
C
E
(
s
′
,
y
)
=
−
y
ln
s
′
−
(
1
−
y
)
ln
(
1
−
s
′
)
\begin{aligned} s'&=\sigma (ws+b)=\frac{1}{1+exp(-(ws+b))} \\ L_{BCE}(s',y)&=-y\ln s'- (1-y)\ln (1-s') \end{aligned}
s′LBCE(s′,y)=σ(ws+b)=1+exp(−(ws+b))1=−ylns′−(1−y)ln(1−s′)
最后的损失函数计算过程,非常类似Pairwise Loss,只不过端到端系统的输入是
N
+
1
N+1
N+1个话语,而不是两个话语
x-vector系统采用的是类似上述的端到端损失函数,不过将余弦相似度,替换成了另一种相似性度量:
L
(
e
1
,
e
2
)
=
e
1
T
e
2
−
e
1
T
S
e
1
−
e
2
T
S
e
2
+
b
L(e_1,e_2)=e_1^Te_2-e_1^TSe_1-e_2^TSe_2+b
L(e1,e2)=e1Te2−e1TSe1−e2TSe2+b 其中,
矩阵
S
S
S和标量
b
b
b都是可学习参数
这是基于PLDA所衍生出来的一种相似性度量
关键点
关于
N
N
N的选定,可以按照运行时的情况来决定,如果不确定运行时会有几个注册话语,则取平均值或者中间值
如何平衡正负样本比例?这是常见的问题,通常负样本数远远多于正样本数,常见的做法是:在负样本的损失函数上,乘以一个常数
K
,
0
<
K
<
1
K,0<K<1
K,0<K<1
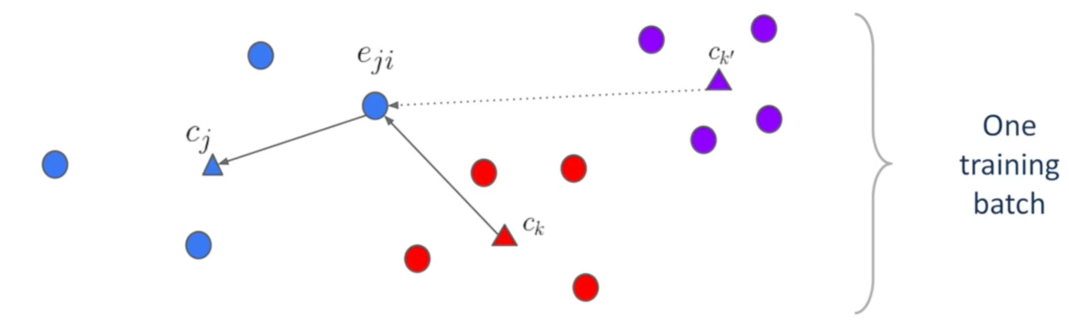
将嵌入码记为
e
j
i
e_{ji}
eji,
j
j
j表示说话人,
i
i
i表示属于第
j
j
j个说话人的第
i
i
i个话语;某个说话人的嵌入码中心记为
c
j
c_j
cj
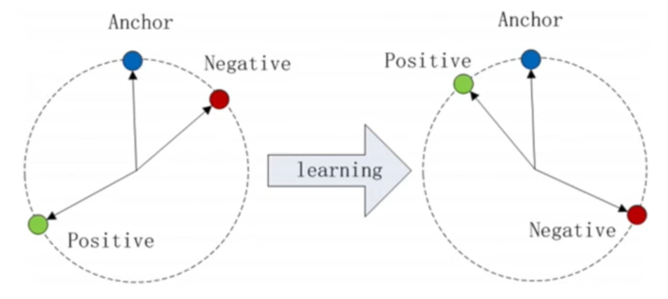
基本思想,具体而言:
对于每一个
e
j
i
e_{ji}
eji而言,我们希望它与
c
j
c_j
cj靠近,与其他的
c
k
、
c
k
′
c_k、c_{k'}
ck、ck′远离
在一个batch内,对于一个
e
j
i
e_{ji}
eji而言,会出现多个其他说话人的中心点,如
c
k
、
c
k
′
c_k、c_{k'}
ck、ck′
根据最大间隔原理,只关注距离该
e
j
i
e_{ji}
eji最接近的其他说话人的中心,从图中来看,则是只关注
c
k
c_k
ck,不关注
c
k
′
c_{k'}
ck′
对神经网络而言,
c
k
c_k
ck是区分
e
j
i
e_{ji}
eji属于
c
j
c_j
cj,最困难的一个其他说话人。也就是说,对于
e
j
i
e_{ji}
eji而言,
c
k
c_k
ck是支持说话人(Support Speaker)
计算损失函数前的准备工作
假设,一个batch的维度为
N
×
M
N \times M
N×M,
N
N
N表示该batch包含的说话人个数,
M
M
M表示该batch中每个说话人的话语数
该batch的数据,经过神经网络后,每个话语都向量化,得到嵌入码
e
j
i
e_{ji}
eji,从而:
c
j
=
1
M
∑
i
=
1
M
e
j
i
c_j=\frac{1}{M}\sum_{i=1}^{M}e_{ji}
cj=M1i=1∑Meji
对整个batch,计算相似度矩阵,维度为
N
M
×
N
NM \times N
NM×N:
S
j
i
,
k
=
w
⋅
cos
(
e
j
i
,
c
k
)
+
b
S_{ji,k}=w\cdot \cos (e_{ji},c_k)+b
Sji,k=w⋅cos(eji,ck)+b 其中,
w
>
0
,
w
、
b
w>0,w、b
w>0,w、b都是可学习参数
相似度矩阵,表示batch中的每一个嵌入码
e
j
i
e_{ji}
eji,与batch内所有说话人的中心点
c
k
c_k
ck,计算相似度,然后进行线性变换,因此维度是
N
M
×
N
NM \times N
NM×N
损失函数的定义:有两种方法实现最大间隔原理
基于对比的方法:对于每一个
e
j
i
e_{ji}
eji而言,损失函数为
L
(
e
j
i
)
=
1
−
σ
(
S
j
i
,
j
)
+
max
1
≤
k
≤
N
,
k
≠
j
σ
(
S
j
i
,
k
)
L(e_{ji})=1-\sigma(S_{ji,j})+\max_{1\le k \le N,k \ne j} \sigma(S_{ji,k})
L(eji)=1−σ(Sji,j)+1≤k≤N,k=jmaxσ(Sji,k) 其中,
1
−
σ
(
S
j
i
,
j
)
1-\sigma(S_{ji,j})
1−σ(Sji,j)表示正样本对的余弦相似度越接近1越好
max
1
≤
k
≤
N
,
k
≠
j
σ
(
S
j
i
,
k
)
\max_{1\le k \le N,k \ne j} \sigma(S_{ji,k})
max1≤k≤N,k=jσ(Sji,k)表示最困难负样本对的余弦相似度越小越好
这种同时考虑正样本对和负样本对的思想,与Triplet Loss类似,不同之处在于:
使用中心点,模拟运行时的说话人嵌入码
负样本对的优化,只针对支持说话人
缺点:使用了
max
(
⋅
)
\max(\cdot)
max(⋅),这是不可导的函数
基于Softmax的方法,针对方法1的缺点,采用
max
(
⋅
)
\max(\cdot)
max(⋅)的可微分版本——Softmax来改进
L
(
e
j
i
)
=
−
S
j
i
,
j
+
ln
∑
k
=
1
N
exp
(
S
j
i
,
k
)
=
−
ln
(
exp
(
S
j
i
,
j
)
)
+
ln
∑
k
=
1
N
exp
(
S
j
i
,
k
)
=
ln
∑
k
=
1
N
exp
(
S
j
i
,
k
)
exp
(
S
j
i
,
j
)
=
−
ln
exp
(
S
j
i
,
j
)
∑
k
=
1
N
exp
(
S
j
i
,
k
)
\begin{aligned} L(e_{ji})&=-S_{ji,j}+\ln \sum_{k=1}^{N} \exp(S_{ji,k}) \\ &=-\ln(\exp(S_{ji,j}))+\ln \sum_{k=1}^{N} \exp(S_{ji,k}) \\ &=\ln \frac{\sum_{k=1}^{N} \exp(S_{ji,k})}{\exp(S_{ji,j})} \\ &=- \ln \frac{\exp(S_{ji,j})}{\sum_{k=1}^{N} \exp(S_{ji,k})} \end{aligned}
L(eji)=−Sji,j+lnk=1∑Nexp(Sji,k)=−ln(exp(Sji,j))+lnk=1∑Nexp(Sji,k)=lnexp(Sji,j)∑k=1Nexp(Sji,k)=−ln∑k=1Nexp(Sji,k)exp(Sji,j) 这个损失函数,将每个嵌入码推到其对应说话人中心点附近,并将其拉离所有其他说话人中心点
为了避免平凡解,一个重要的技巧是:在计算
e
j
i
e_{ji}
eji的损失函数时,对于
c
j
c_j
cj的计算,不要将
e
j
i
e_{ji}
eji本身加进去,新的
c
j
c_j
cj表达式如下,式中的
(
−
i
)
(-i)
(−i)表示排除
i
i
i
c
j
(
−
i
)
=
1
M
−
1
∑
m
=
1
,
m
≠
i
M
e
j
m
c_j^{(-i)}=\frac{1}{M-1}\sum_{m=1,m \ne i}^{M}e_{jm}
cj(−i)=M−11m=1,m=i∑Mejm