作一回白嫖怪:写一个脚本自动获取ST官网积分,用积分领取奖品
环境:Python、selenium、ubuntu22.04
网址:STMCU中文官网
chrome: 版本 108.0.5359.124(正式版本) (64 位)
chromeDriver: CNPM Binaries Mirror
这两个文件我打包起来了,0积分方便大家白嫖:https://download.csdn.net/download/c_1969/87335607
怎么安装的可以看这一篇文章:
Linux(Ubuntu)配置Chromedriver_时至二五的博客-CSDN博客_chromedriver linux
简单说,就是如下:
mv webdriver /usr/local/bin
chmod +777 webdriver
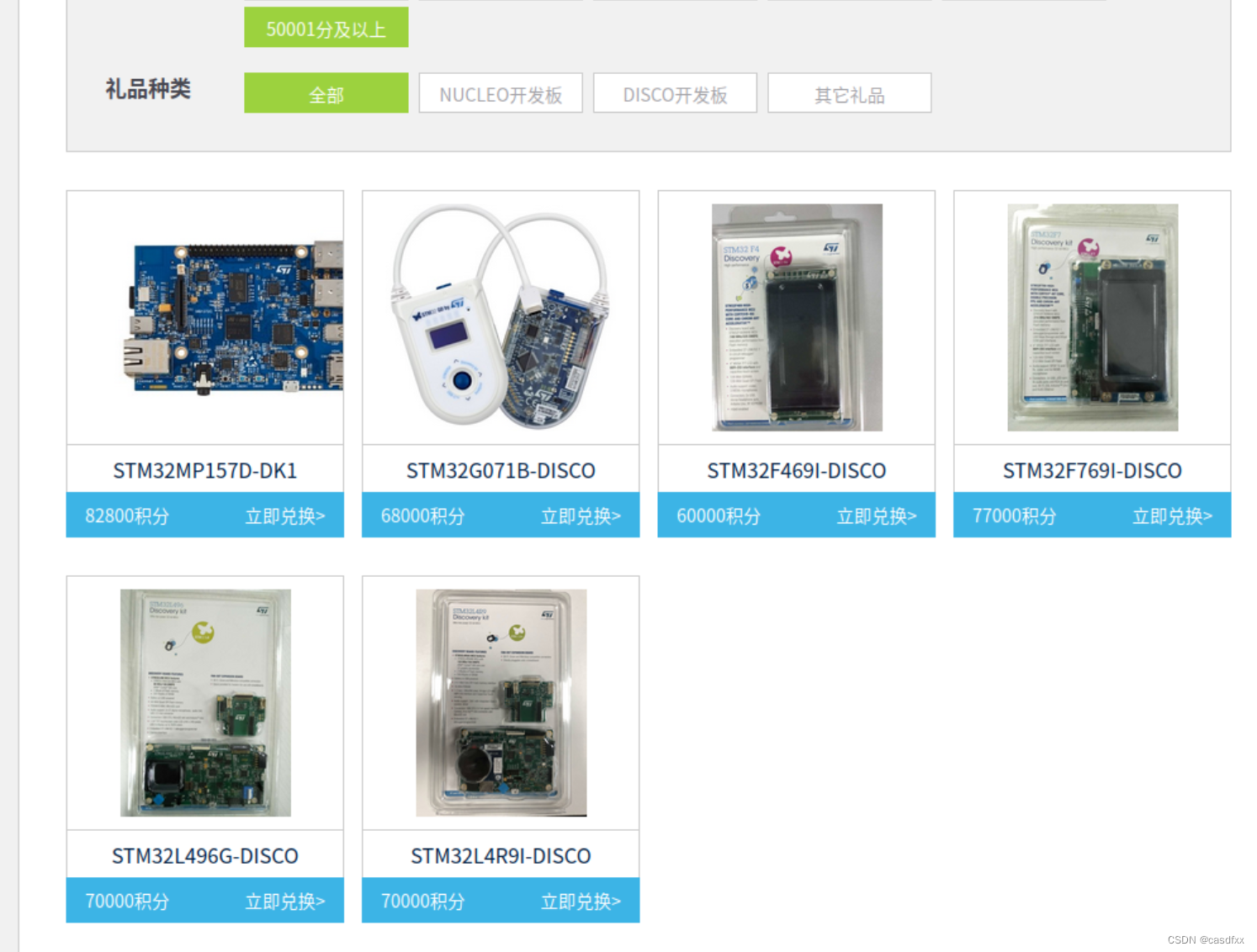
一、先给大家看看“奖品”:
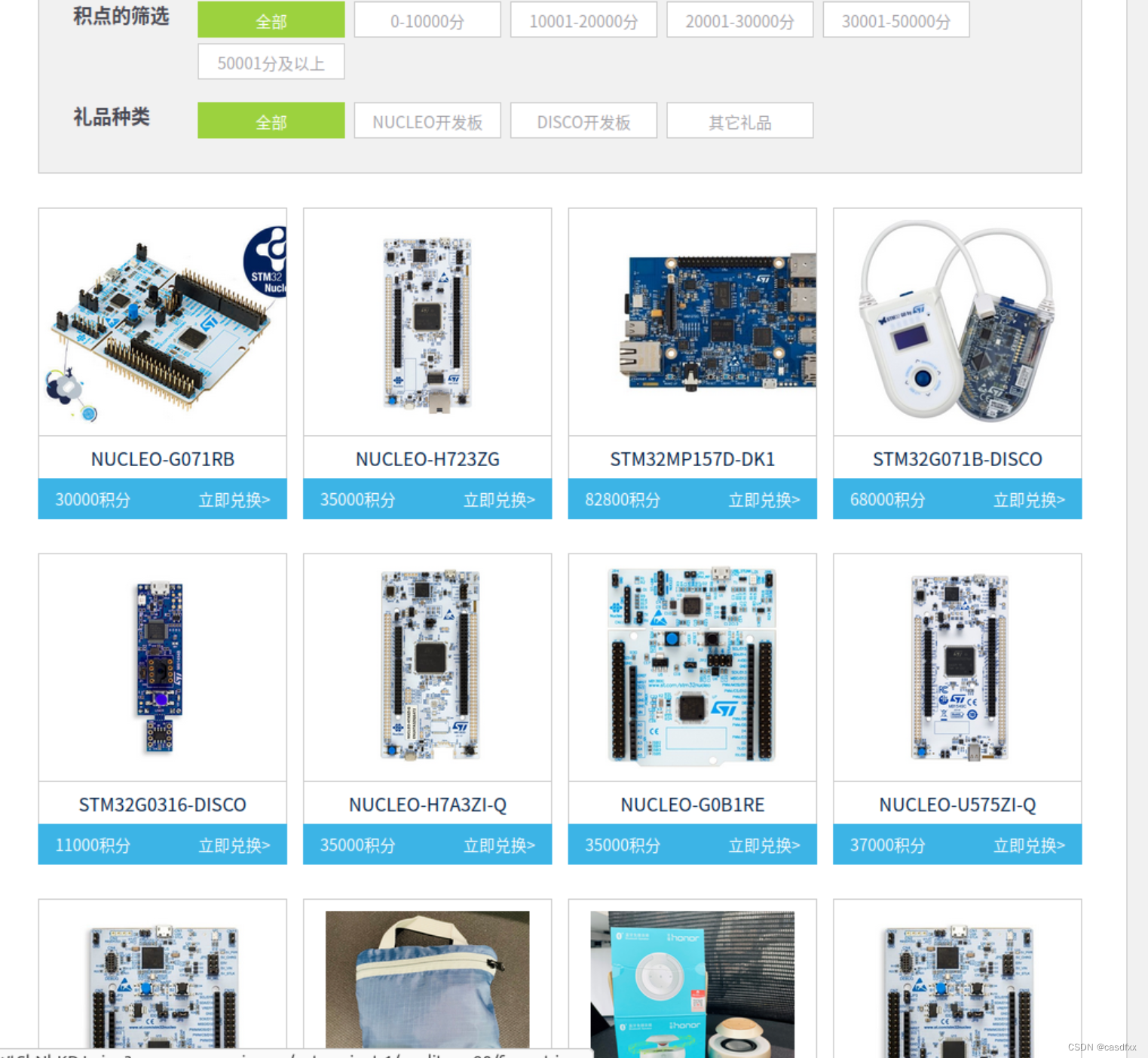
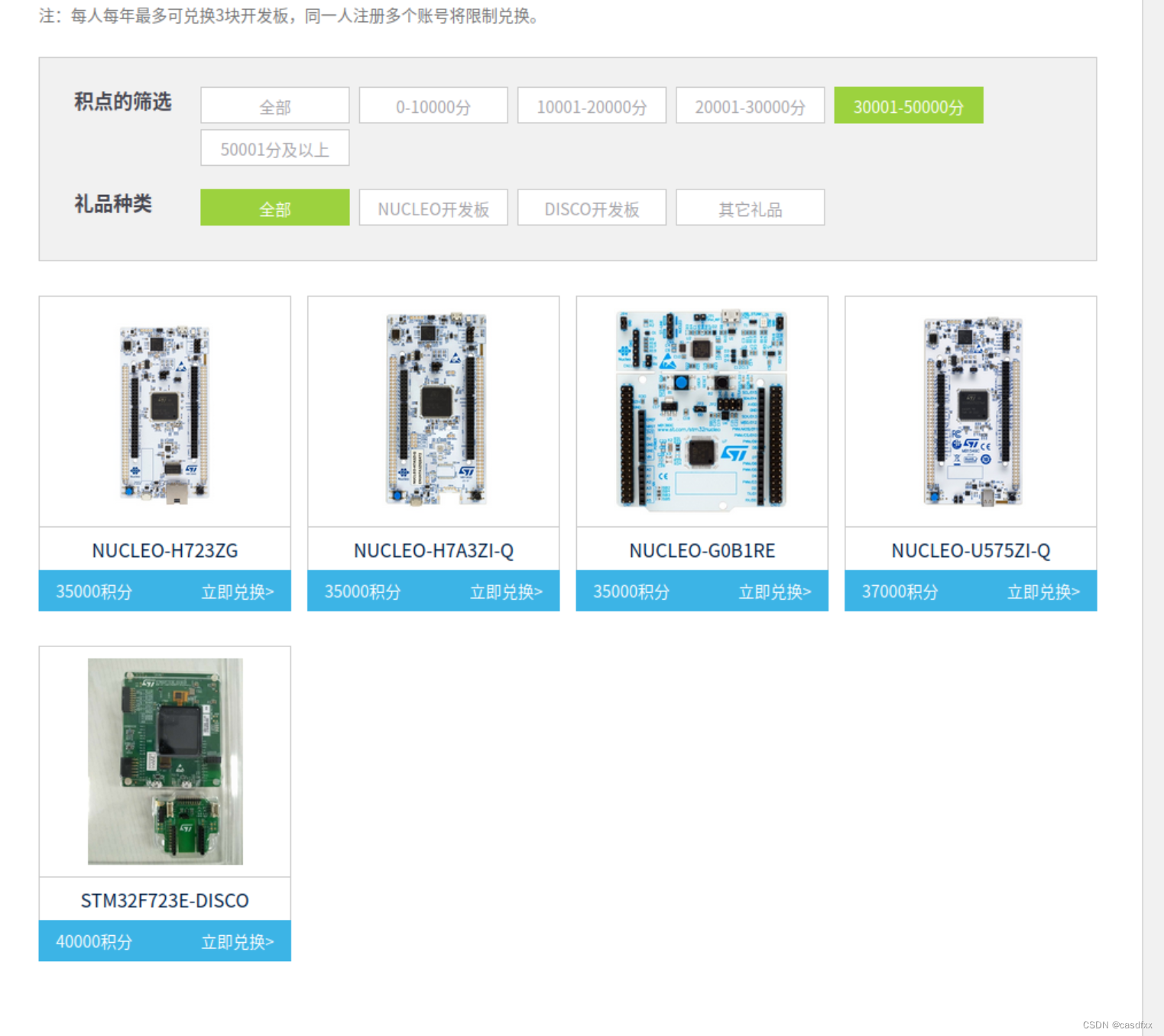
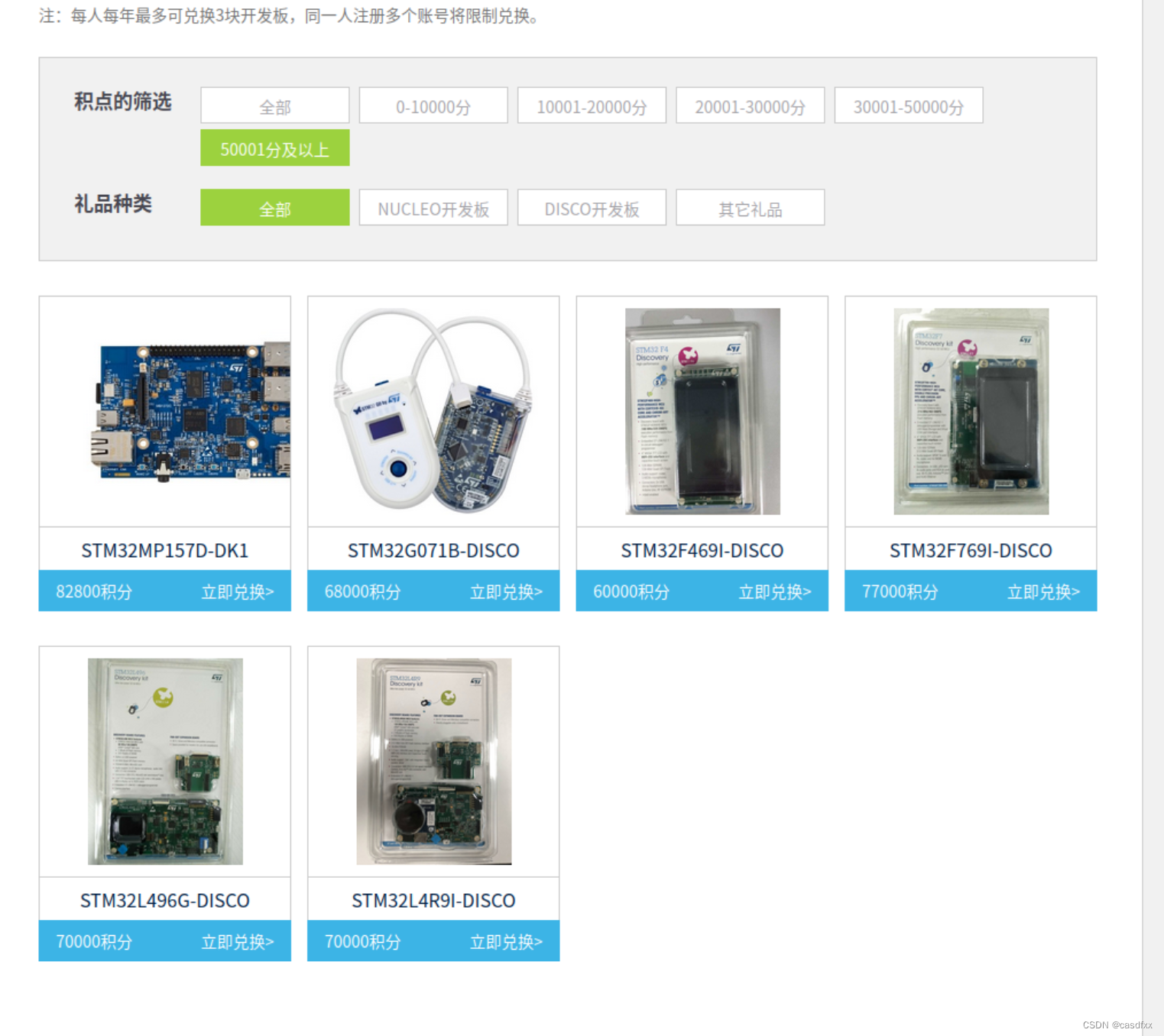
只要积攒够了分数就可以申请领取, 博主已经知道有人领到过了。
要注意的是这样来的:

播主试过每天手动领取(通过下载文档的方式),由于网页打开速度满的原因,每天赞够分数需要花费半个小时。非常耽误时间,为了节省时间精力才有了下文的自动化代码。
二、代码展示:
脚本分为两个文件,
文件1:stmcu.py
class Stmcu:
def saveparam(self,arg):
f = open("stmcu.txt",'w')
f.write(arg)
f.close()
def getparam(self):
f2 = open("stmcu.txt",'r')
content = f2.read()
f2.close()
return content文件2:stmcuAutoDownload.py
username.send_keys('你的账户')
password.send_keys('你的密码')
#from ctypes import WinDLL
import ctypes
from xml.dom.minidom import Element
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import re
import os
FIRSTTIME = 1666200000
DAYLYMAXDOWNLOAD = 29
wd = webdriver.Chrome()
#wd.set_window_position(0,0)
#wd.set_window_size(200,200)
wd.maximize_window()
#step1 登录
wd.get('https://sso.stmicroelectronics.cn/User/LoginByPassword')
username = wd.find_element(By.ID, 'username')
password = wd.find_element(By.ID, 'password')
loginbtn = wd.find_element(By.XPATH, '//input[@type="submit"]')
username.send_keys('你的账户')
password.send_keys('你的密码')
loginbtn.click()
#"""
wd.get('https://www.stmcu.com.cn/Product/pro_detail/PRODUCTSTM32/design_resource')
es = wd.find_elements(By.CLASS_NAME, 'cd_lan')
i = 0
maxup = 10
#print(e.get_attribute('href'))
#print(e.text);
"""
for e in es:
i = i + 1
if 'ES0005_STM32F205或207xx和STM32F215或217xx...' == e.text:
print('ok')
print(i)
#print(es.index(i).text)
break
"""
j = 0
ls = list()
#step02 获取开始位置
"""
curday = int((time.time() - FIRSTTIME)/86400)
curindex = 774+curday*10
print('day:'+str(curday))
"""
from stmcu import Stmcu
stmcu = Stmcu()
curindex = int(stmcu.getparam())
#step03 获取链接
for e in es:
j = j + 1
if j < curindex:
continue
print(e.text)
if None!=re.match('https://www.stmcu.com.cn/Designresource/detail/document/[\s\S]+',e.get_attribute('href')):
ls.append(e.get_attribute('href'))
else:
curindex = curindex + 1
#wd.execute_script('window.open("'+e.get_attribute('href')+'")')
if j >= curindex + DAYLYMAXDOWNLOAD:
break
stmcu.saveparam(str(curindex+DAYLYMAXDOWNLOAD))
#step04 打开链接并下载
for k in ls:
try:
print(k)
wd.execute_script('window.open("'+k+'")')
handles = wd.window_handles
wd.switch_to.window(handles[-1])
item = wd.find_element(By.XPATH, '//*[@id="down_load_btn"]')
item.click()
wd.switch_to.window(handles[1])
time.sleep(5)
except:
wd.get_screenshot_as_png()
continue
#break
文件3:运行后生成
代码运行后,会生成 stmcu.txt 这一文件,用于保存下载文件的位置。毕竟要达到几万的积分,需要下载几千个文件,如果将文件随意下载,很有可能会造成重复下载的问题,而重复下载是不能获取积分的。
三、效果展示:

已经为我获得了一万多的积分。
当前已经下载了3000+文档,一共6000+文档,等脚本运行完成,我就要领取一个高端开发板了(大概值,没仔细数)。