【Java基础知识复盘】HashMap篇——持续更新中
本人知识复盘系列的博客并非全部原创,大部分摘自网络,只是为了记录在自己的博客方便查阅,往后也会陆续在本篇博客更新本人查阅到的新的知识点,望悉知!
HashMap
概述
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射
HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步
HashMap 是无序的,即不会记录插入的顺序
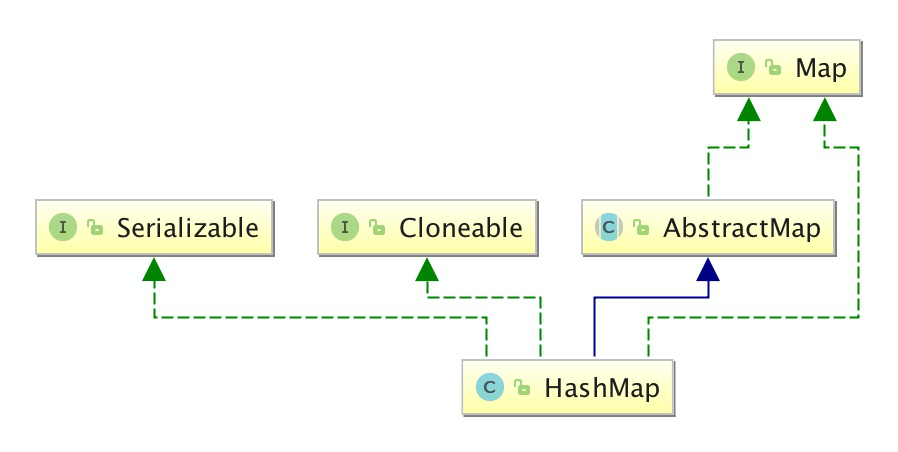
HashMap 继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口
HashMap 的 key 与 value 类型可以相同也可以不同,可以是字符串(String)类型的 key 和 value,也可以是整型(Integer)的 key 和字符串(String)类型的 value
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mdeGp5L0-1671692978989)(null)]
HashMap 中的元素实际上是对象,一些常见的基本类型可以使用它的包装类
| 基本类型 | 引用类型 |
|---|---|
| boolean | Boolean |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
创建实例:
import java.util.HashMap; // 引入 HashMap 类
HashMap<Integer, String> Sites = new HashMap<Integer, String>();
常用方法
添加:put(key,value)
访问:get(key)
删除:remove(key)
计算大小:size()
迭代HashMap:
如果只想获取 key,可以使用 keySet() 方法,然后可以通过 get(key) 获取对应的 value,如果你只想获取 value,可以使用 values() 方法
// 创建 HashMap 对象 Sites HashMap<Integer, String> Sites = new HashMap<Integer, String>(); // 添加键值对 Sites.put(1, "Google"); Sites.put(2, "Runoob"); Sites.put(3, "Taobao"); Sites.put(4, "Zhihu"); // 输出 key 和 value for (Integer i : Sites.keySet()) { System.out.println("key: " + i + " value: " + Sites.get(i)); } // 返回所有 value 值 for(String value: Sites.values()) { // 输出每一个value System.out.print(value + ", "); }
更多方法
| 方法 | 描述 |
|---|---|
| clear() | 删除 hashMap 中的所有键/值对 |
| clone() | 复制一份 hashMap |
| isEmpty() | 判断 hashMap 是否为空 |
| size() | 计算 hashMap 中键/值对的数量 |
| put() | 将键/值对添加到 hashMap 中 |
| putAll() | 将所有键/值对添加到 hashMap 中 |
| putIfAbsent() | 如果 hashMap 中不存在指定的键,则将指定的键/值对插入到 hashMap 中。 |
| remove() | 删除 hashMap 中指定键 key 的映射关系 |
| containsKey() | 检查 hashMap 中是否存在指定的 key 对应的映射关系。 |
| containsValue() | 检查 hashMap 中是否存在指定的 value 对应的映射关系。 |
| replace() | 替换 hashMap 中是指定的 key 对应的 value。 |
| replaceAll() | 将 hashMap 中的所有映射关系替换成给定的函数所执行的结果。 |
| get() | 获取指定 key 对应对 value |
| getOrDefault() | 获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值 |
| forEach() | 对 hashMap 中的每个映射执行指定的操作。 |
| entrySet() | 返回 hashMap 中所有映射项的集合集合视图。 |
| keySet() | 返回 hashMap 中所有 key 组成的集合视图。 |
| values() | 返回 hashMap 中存在的所有 value 值。 |
| merge() | 添加键值对到 hashMap 中 |
| compute() | 对 hashMap 中指定 key 的值进行重新计算 |
| computeIfAbsent() | 对 hashMap 中指定 key 的值进行重新计算,如果不存在这个 key,则添加到 hasMap 中 |
| computeIfPresent() | 对 hashMap 中指定 key 的值进行重新计算,前提是该 key 存在于 hashMap 中。 |
常见面试题
HashMap的底层数据结构
HashMap底层实现数据结构为数组+链表的形式,JDK8及其以后的版本中使用了数组+链表+红黑树实现,解决了链表太长导致的查询速度变慢的问题
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。HashMap通过key的HashCode经过扰动函数处理过后得到Hash值,然后通过位运算判断当前元素存放的位置,如果当前位置存在元素的话,就判断该元素与要存入的元素的hash值以及key是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。当Map中的元素总数超过Entry数组的0.75时,触发扩容操作,为了减少链表长度,元素分配更均匀
HashMap如何有效地减少碰撞
- 扰动函数:促使元素位置分布均匀,减少碰撞几率
- 使用final对象,并采用合适的equals()和hashCode()方法
HashMap可以实现同步吗
HashMap可以通过下面的语句进行同步:
Map m = Collections.synchronizeMap(hashMap);
HashMap什么时候进行扩容?怎么扩容?
HashMap进行扩容取决于以下两个元素:
Capacity:HashMap当前长度。
LoadFactor:负载因子,默认值0.75f。
当Map中的元素个数(包括数组,链表和红黑树中)超过了16*0.75=12之后开始扩容。
具体怎么进行扩容呢?将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing ,因为它将会调用hash方法找到新的bucket位置。
HashMap原理
HashMap在jdk1.8以后是基于数组+链表+红黑树来实现的,特点是,key不能重复,可以为null,线程不安全
HashMap的扩容机制:
①HashMap的默认容量为16,默认的负载因子为0.75,当HashMap中元素个数超过容量乘以负载因子的个数时,就创建一个大小为前一次两倍的新数组,再将原来数组中的数据复制到新数组中。当数组长度到达64且链表长度大于8时,链表转为红黑树
红黑树是一种自平衡的二叉查找树,是一种高效的查找树。
红黑树具有良好的效率,它可在 O(logN) 时间内完成查找、增加、删除等操作。
它是具备了某些特性的二叉搜索树,能解决非平衡树问题,红黑树是一种接近平衡的二叉树(说它是接近平衡因为它并没有像AVL树的平衡因子的概念,它只是靠着满足红黑节点的5条性质来维持一种接近平衡的结构,进而提升整体的性能,并没有严格的卡定某个平衡因子来维持绝对平衡)
HashMap存取原理:
①计算key的hash值,然后进行二次hash,根据二次hash结果找到对应的索引位置
②如果这个位置有值,先进行equals比较,若结果为true则取代该元素,若结果为false,就使用高低位平移法将节点插入链表
什么是Java集合中的快速失败(fast-fail)机制?
快速失败是Java集合的一种错误检测机制,当多个线程对集合进行结构上的改变的操作时,有可能会产生fail-fast。
举个例子:假设存在两个线程(线程1、线程2),线程1通过Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就可能会抛出 ConcurrentModificationException异常,从而产生fast-fail快速失败。
参考文章:
史上最全Hashmap面试总结,51道附带答案,持续更新中…
菜鸟教程