Merge-On-Write 的处理流程
简单来讲,Merge-On-Write 的处理流程是:
-
对于每一条 Key,查找它在 Base 数据中的位置(rowsetid + segmentid + 行号)
-
如果 Key 存在,则将该行数据标记删除。标记删除的信息记录在 Delete Bitmap 中,其中每个 Segment 都有一个对应的 Delete Bitmap
-
将更新的数据写入新的 Rowset 中,完成事务,让新数据可见(能够被查询到)
-
查询时,读取 Delete Bitmap,将被标记删除的行过滤掉,只返回有效的数据
关键问题
设计适合 Doris 的 Merge-On-Write 方案,需要重点解决以下几个问题:
-
导入时如何高效定位到是否存在需要被标记删除的旧数据?
-
标记删除的信息如何进行高效的存储?
-
查询阶段如何高效的使用标记删除的信息来过滤数据?
-
能否实现多版本支持?
-
如何避免并发导入的事务冲突,导入与 Compaction 的写冲突?
-
方案引入的额外内存消耗是否合理?
-
写入代价导致的写入性能下降是否在可接受范围内?
根据以上关键问题,我们进行了一系列优化措施,使得以上问题得到较好的解决。 下 文中我们将进行详细介绍:
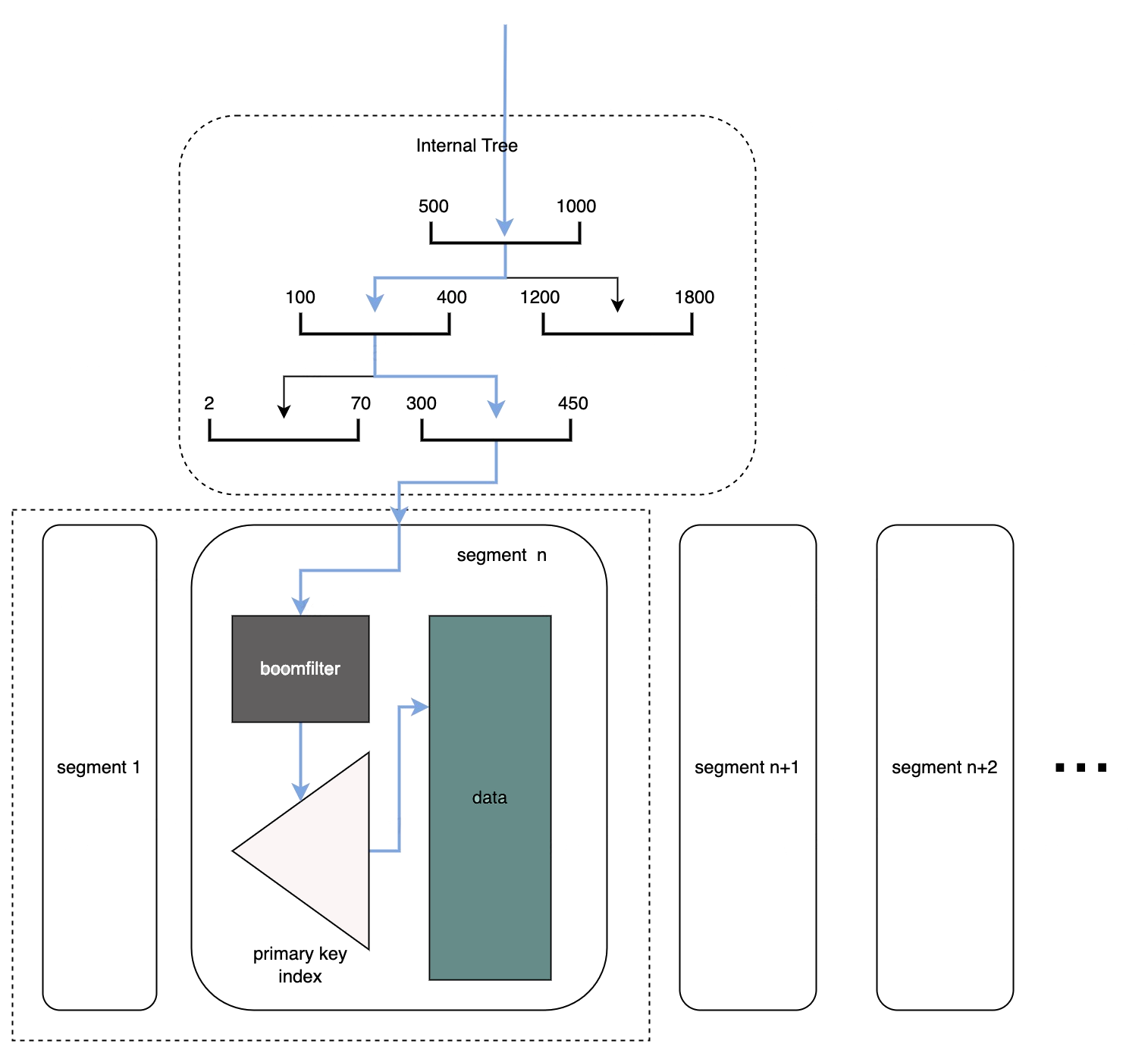
主键索引
由于 Doris 是面向大规模分析设计的列存系统,并没有主键索引的能力,因此为了能够快速定位到有没有要覆盖的主键,以及要覆盖的主键的行号,就需要给 Doris 增加一个主键索引。
我们采取了如下的优化措施:
-
为每个 Segment 维护一个主键索引。主键索引的实现采用了似于 RocksDB Partitioned Index 的方案。该方案能够实现非常高的查询 QPS,同时基于文件的索引方案也能够节省内存占用。
-
为每个 Segment 维护一个主键索引对应的 Bloom Filter。当 Bloom Filter 命中时才会查询主键索引。
-
为每个 Segment 记录一个主键的区间范围 [min-key, max-key]
-
维护一个纯内存的区间树,使用所有 Segment 的主键区间构造。在查询一个主键时,无需遍历所有的 Segment,可以通过区间树定位到可能包含该主键的 Segment,大幅减少需要查询的索引量 。
-
对于命中的所有 Segment,按照版本从高到低进行查询。在 Doris 中高版本意味着更新的数据,因此如果一个主键在高版本的 Segment 索引中命中,就无需继续查询更低版本的 Segment 。
查询单个主键的流程如下图所示:
Delete Bitmap
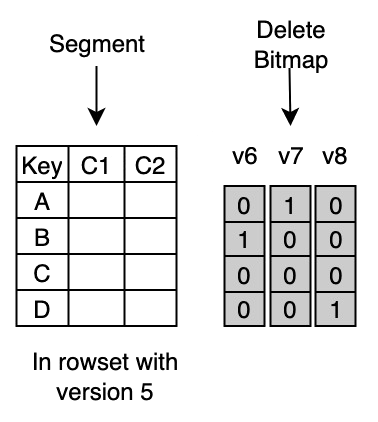
Delete Bitmap 采取多版本的方式进行记录,具体如下图所示:
-
图中的 Segment 文件是由版本 5 的导入产生的,包含了该 Tablet 中版本 5 的导入数据
-
版本 6 的导入中包含了对主键 B 的更新,因此会在 Bitmap 中将第二行标记删除,并在 DeleteBitmap 中记录版本 6 的导入对该 Segment 的修改
-
版本 7 的导入包含了对主键 A 的更新,也会产生一个对应版本的 Bitmap;同理版本 8 的导入也会产生一个对应的 Bitmap
所有的 Delete Bitmap 存储在一个大的 Map 中,每次导入都会将最新的 Delete Bitmap 序列化到 RocksDB 中。其中关键定义如下:
using SegmentId = uint32_t;
using Version = uint64_t;
using BitmapKey = std::tuple<RowsetId, SegmentId, Version>;
std::map<BitmapKey, roaring::Roaring> delete_bitmap;
每个 Rowset 中的每个 Segment,都会记录多个版本的 Bitmap。Version 为 x 的 Bitmap 意味着版本为 x 的导入对当前 Segment 的修改。
多版本 Delete Bitmap 的优点:
-
能很好的支持多版本的查询,例如版本 7 的导入完成后,一个该表的查询开始执行,会使用 Version 7 来执行,即使这个查询执行时间较长,在查询执行期间版本 8 的导入已经完成,也无需担心读到版本 8 的数据(或者漏掉被版本 8 删除的数据)
-
能够很好的支持复杂的 Schema Change。在 Doris 中,复杂的 Schema Change(例如类型转换)需要先进行双写,同时将某个版本之前的历史数据进行转换后再删除掉旧版的数据。多版本的 Delete Bitmap 可以很好的支持当前的 Schema Change 实现
-
可以支持数据拷贝和副本修复时的多版本需求