谷粒学院复习
一、Mybatis Plus复习
- 分布式系统唯一ID主键策略(面试)
面试的时候就说知道有以下四种策略,分别介绍一下每一种,然后说一下项目中用的是雪花算法
分类
自动增长 AUTO INCREMENT
就是自动增长,每次都会自动加一。
缺点:如果在分库分表的场景中,每次到一个id数量要加新的表了,要得到上一张表的最后一个id,才能生成新的表。
UUID
每次都会生成一个随机的唯一的值
缺点:排序不方便
Redis生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试redis来生成,只要依赖于redis是单线程,所以可以用生成全局唯一的id,可以用redis原子操作来实现
可以使用Redis集群来获取更高的吞吐。假如一个集群中有5台Redis可以初始化每台Redis的值分别是1,2,3,,5,然后步长都是5各个Redis生成的ID为:
A: 1,6,11,16,21
B: 2,7,12,17,22
C: 3,8,13,18,23
D: 4,9,14,19,24
E: 5,10,15,20,25
这个,随便负载到哪个机确定好,未来很做修改。但是3-5台服务器基本能够满足器上,都可以获得不同的1D。但是步长和初值-定需要事先需要了·使用Redis集群也可以防止单点故障的问题。
另外,比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key;使用INCR进行累加
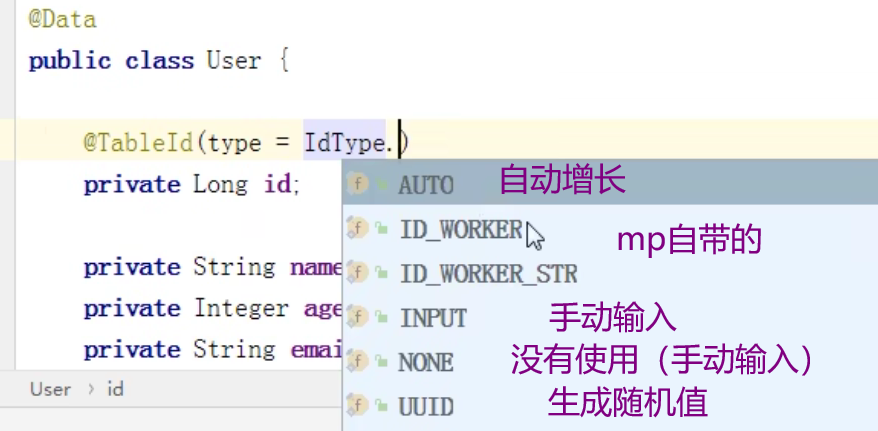
mp自带雪花算法
使用mybatisPlus自带的雪花算法,保证唯一的值
使用
在实体类的主键上面加上@TableId注解就行
ID_WORKER 是mp自带的,会生成一个19位的值,如果属性是数字类型就使用
ID_WORKER_STR也是mp自带的,生成一个19位的值,字符串类型用这种策略
- 自动填充
@Data@AllArgsConstructor@NoArgsConstructorpublicclassUser {
@TableId(type = IdType.AUTO)private Long id;
private String name;
private Integer age;
private String email;
//创建时间,插入数据时操作
@TableField(fill = FieldFill.INSERT)
private Date createTime;
//更新时间,插入和更新是操作
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updateTime;
}数据库加字段,在实体类属性中增加注解@TableField(fill = FieldFill.INSERT_UPDATE)
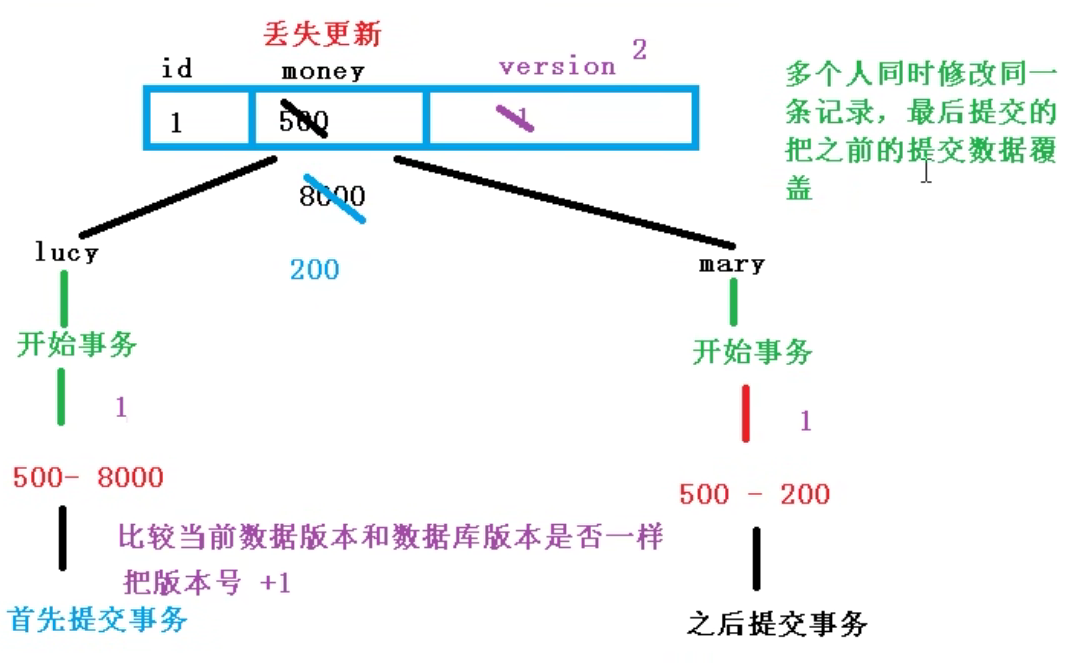
- 乐观锁(面试)
在并发情况下,写的时候会存在丢失更新问题(多个人同时修改同一条记录,最后提交会把之前的提交都覆盖)默认版本是1
通过一个字段version版本号来对比数据,修改的话谁先提交版本就会发生变化,别的人就不能修改了。
@Version//乐观锁Version注解
private Integer version;- 查询操作
根据id查询
userMapper.selectById(1231233312);
查询多个id查询
userMapper.selectBatchIds(Arrays.asList(1,2,3));
分页查询
先配置分页插件
@EnableTransactionManagement@Configuration@MapperScan("com.ly.mapper")publicclassMybatisPlusConfig {
@Beanpublic PaginationInterceptor paginationInterceptor() {
PaginationInterceptorpaginationInterceptor=newPaginationInterceptor();
// 设置请求的页面大于最大页后操作, true调回到首页,false 继续请求 默认false// paginationInterceptor.setOverflow(false);// 设置最大单页限制数量,默认 500 条,-1 不受限制// paginationInterceptor.setLimit(500);// 开启 count 的 join 优化,只针对部分 left join
paginationInterceptor.setCountSqlParser(newJsqlParserCountOptimize(true));
return paginationInterceptor;
}
}然后就能直接用了,selectPage第一次参数传设置的page对象,第二个传条件wrapper
//测试分页查询@TestpublicvoidtestPage(){
// 参数一:当前页// 参数二:页面大小// 使用了分页插件之后,所有的分页操作也变得简单了
Page<User> page =newPage<>(2,5);
userMapper.selectPage(page,null);
page.getRecords().forEach(System.out::println);
//获取总数
page.getTotal();
}
- 删除操作
物理删除

逻辑删除
在表中加delete字段
实体类中增加属性,并添加@TableLogic注解
@TableLogic
//3.1.1开始可以不用这一步,但如果实体类上有 @TableLogic 则以实体上的为准,忽略全局
private Integer deleted;然后在mp配置类配置逻辑删除插件

- 条件查询(重点)
1.查询name不为null的用户,并且邮箱不为null的永不,年龄大于等于35的用户
@TestpublicvoidfindByAgeLessThan(){
// 查询name不为null的用户,并且邮箱不为null的永不,年龄大于等于35的用户
QueryWrapper<User> wrapper =newQueryWrapper<>();
wrapper.isNotNull("name");
wrapper.isNotNull("email");
wrapper.ge("age",35);
userMapper.selectList(wrapper).forEach(System.out::println);
}2.查询name为LY的用户
@TestpublicvoidfindByName(){
// 查询name为LZY的用户
QueryWrapper<User> wrapper =newQueryWrapper<>();
wrapper.eq("name","LY");
User user=userMapper.selectOne(wrapper);
System.out.println(user);
}3.查询年龄在10~30岁之间的用户
@TestpublicvoidfindByAgeBetween(){
// 查询年龄在10~30岁之间的用户
QueryWrapper<User> wrapper =newQueryWrapper<>();
wrapper.between("age",10,30);
Integer count=userMapper.selectCount(wrapper);//查询结果数
System.out.println(count);
}4.测试模糊查询
//模糊查询@TestpublicvoidfindByLink(){
QueryWrapper<User> wrapper =newQueryWrapper<>();
wrapper.notLike("name","Z");//相当于NOT LIKE '%Z%'
wrapper.likeLeft("email","@qq.com");//相当于LIKE '%@qq.com'
List<Map<String,Object>> maps =userMapper.selectMaps(wrapper);//查询结果数
maps.forEach(System.out::println);
}5.测试子查询
@TestpublicvoidfindById() {
QueryWrapper<User> wrapper = newQueryWrapper<>();
//子查询
wrapper.inSql("id", "select id from user where id<5");
List<Object> objects = userMapper.selectObjs(wrapper);
objects.forEach(System.out::println);
}6.通过id进行排序
@TestpublicvoidfindByIdOrderByIdAsc(){
QueryWrapper<User> wrapper =newQueryWrapper<>();
//通过id进行排序
wrapper.orderByAsc("id");
List<User> users =userMapper.selectList(wrapper);
users.forEach(System.out::println);
}二、通用模块开发
- 整合Swagger
创建一个公共通用的模块common,里面再创建个service_base来整合Swagger
然后写个swagger的配置类内容直接复制加@Configuration和@EnableSwagger2
然后再这个要用这个组件的模块的启动类加上@ComponmentScan(basePackage={"com.pzh"},这样就能都能扫描到
最后就能在类上加各种文档注解@Api实现接口文档
- 统一返回结果
统一返回的json字符串格式:

在公共通用模块common创建模块common_util
写个interface来定义返回的状态码 code

定义一个类用来做通用的返回类型R
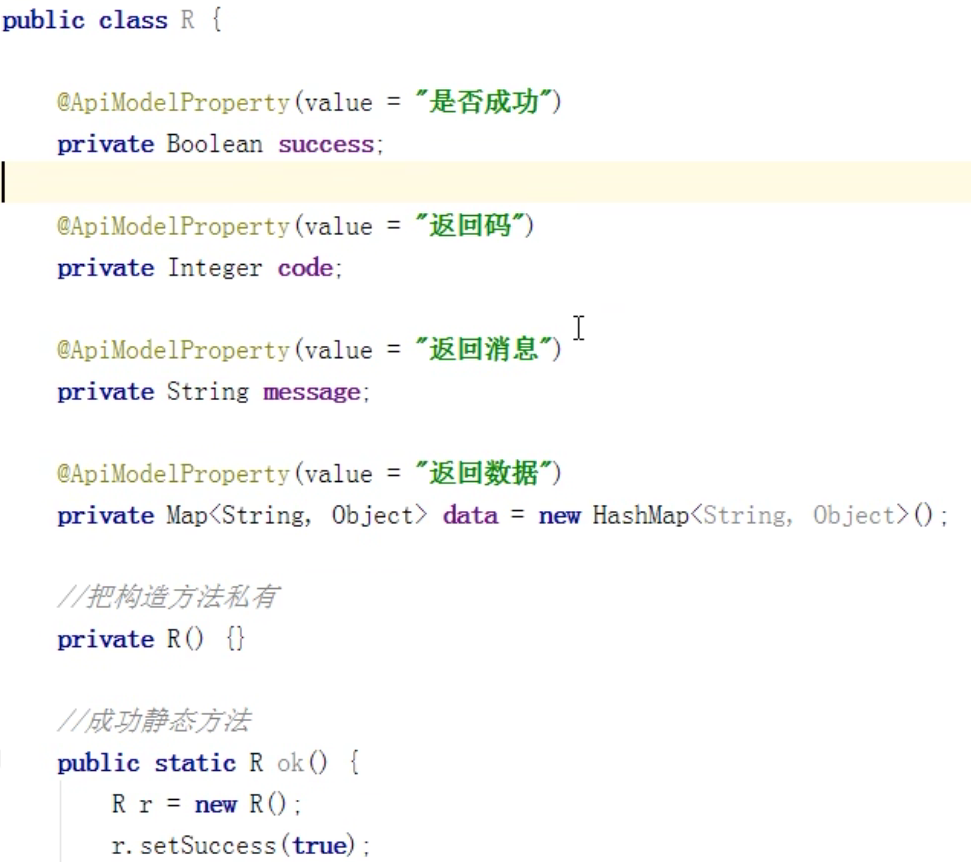
(因为这个R类data的很多构造方法返回的都是this,类的方法又是静态方法,所以可以用链式编程)
最后所有的后端接口的返回类型都为R
- 统一异常处理类
在common模块的service_base模块中添加统一异常类
类上要加@ControllerAdvice注解
然后把common_util的依赖引入到这个模块里面来,就能调用R类型返回异常信息

注意:我们service-edu中引入了service-base依赖,service-base引入common-util依赖,那么我们service-edu就不用引入util了,会传递的
自定义异常
1、创建自定义异常类继承RuntimeException写异常属性

2、然后再统一异常类里面添加自定义异常类

3、要捕获的时候自己手动new

- 统一日志处理
日志级别
ERROR、WARN、INFO、DEBUG(越往后打印越多日志 )
默认情况下spring boot从控制台打印出来的只有info以上级别,可以配置日志级别
使用步骤
删除application.properties中的日志配置
resources中创建logback-spring.xml文件,然后这个文件中可以配置很多,比如改为把日志输出到文件中,文件的位置(D盘哪个位置),会分开放,有error,info,warn三个文件
输出异常信息输出文件夹件中
在全局统一的异常类上加上@Slf4j注解
然后异常类的方法上加上log.error(e.getMessage());
最后就会发现这些异常信息都输出到了error文件中
三、EasyExcel解析Excel
java解析生成excel有名的框架,早期有poi和jxi框架。他们都非常耗内存,EasyExcel对poi进行了封装,效率更高了,主要原因是在解析Excel的时候没有将文件数据一次性全部加载到内存中,而是从磁盘上一行行读取数据,逐个解析。
使用easyExcel进行写操作
引入依赖
创建实体类要和excel表格列对上,实体类属性注释加上表头,excel表格的第一行,属性对应每一列的第一行

定义变量设置写入文件地址,然后调用easyexcel的write方法传入地址和实体类,然后连式编程调用sheet可以给分类命名,doWrite方法传入list里面是写入的数据

使用easyExcel进行读操作
创建实体类,标注实体类对应列的属性

然后创建一个类来读取,这个类实现一个接口泛型是上面的实体类
然后实现两个方法,一个方法读取内容一行行读取,一个是读取表头
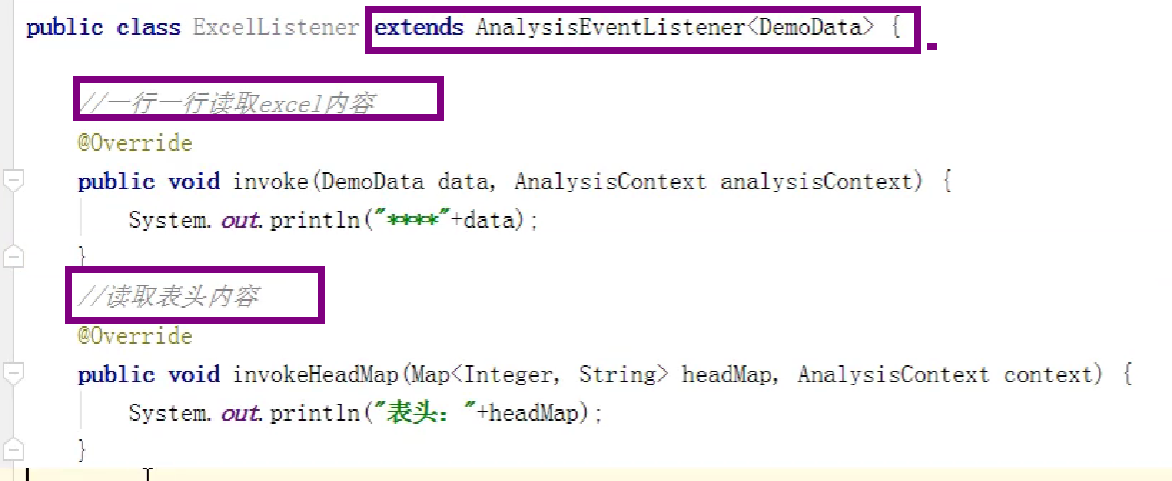
调用读方法

项目中
项目中用来读取课程分类
controller写接收前端的文件然后调用service读取
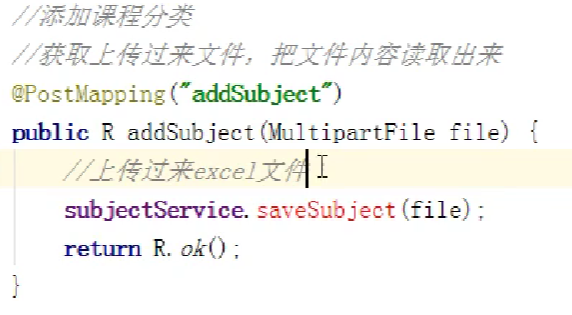
编写实体类属性一级分类和二级分类

然后写一个类(监听器),实现easyExcel的接口,然后这里保存到数据库
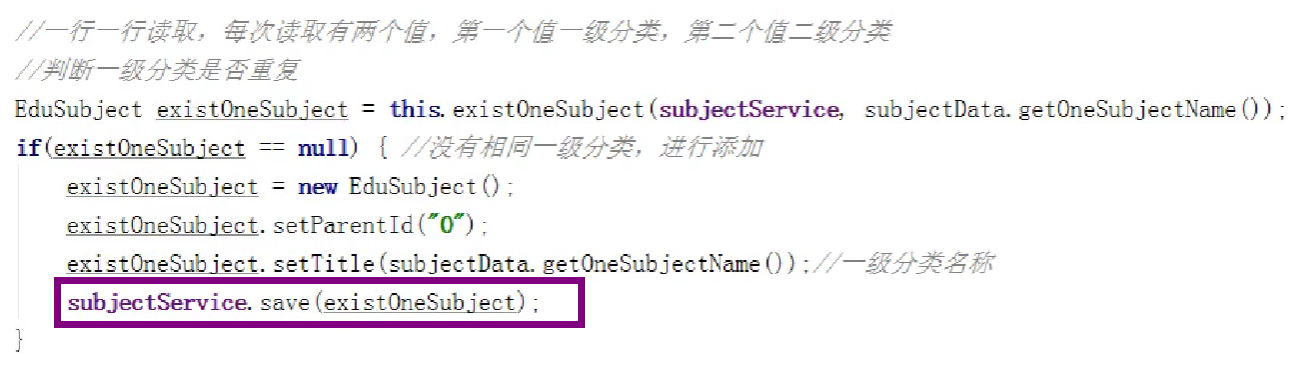
在savesubjectservice类里调用easyexcel的read方法传入文件输入流和实体类还有实现easyExcel的监听器
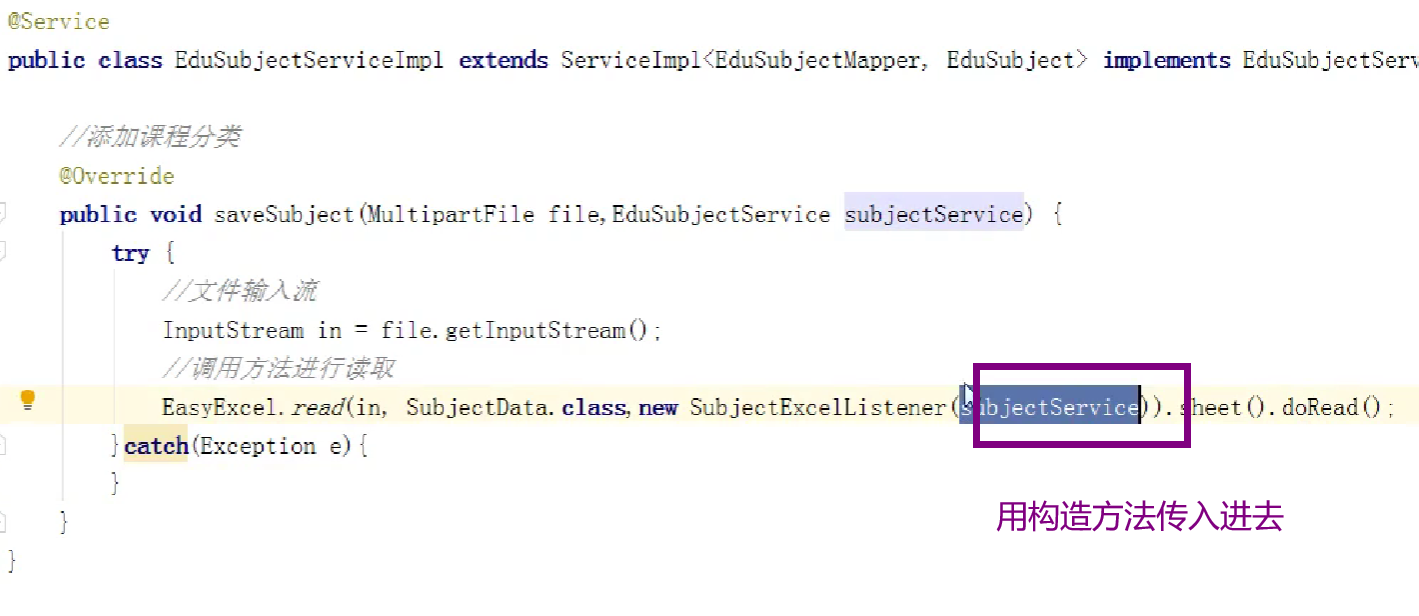
四、阿里云的技术
阿里云OSS上传文件
准备工作:创建操作阿里云oss许可证(阿里云颁发id和秘钥)
在servcie模块简历service_oss子模块并引入阿里云oss依赖
然后写个类上传文件接口,service写下面方法用MultipartFile类接收文件
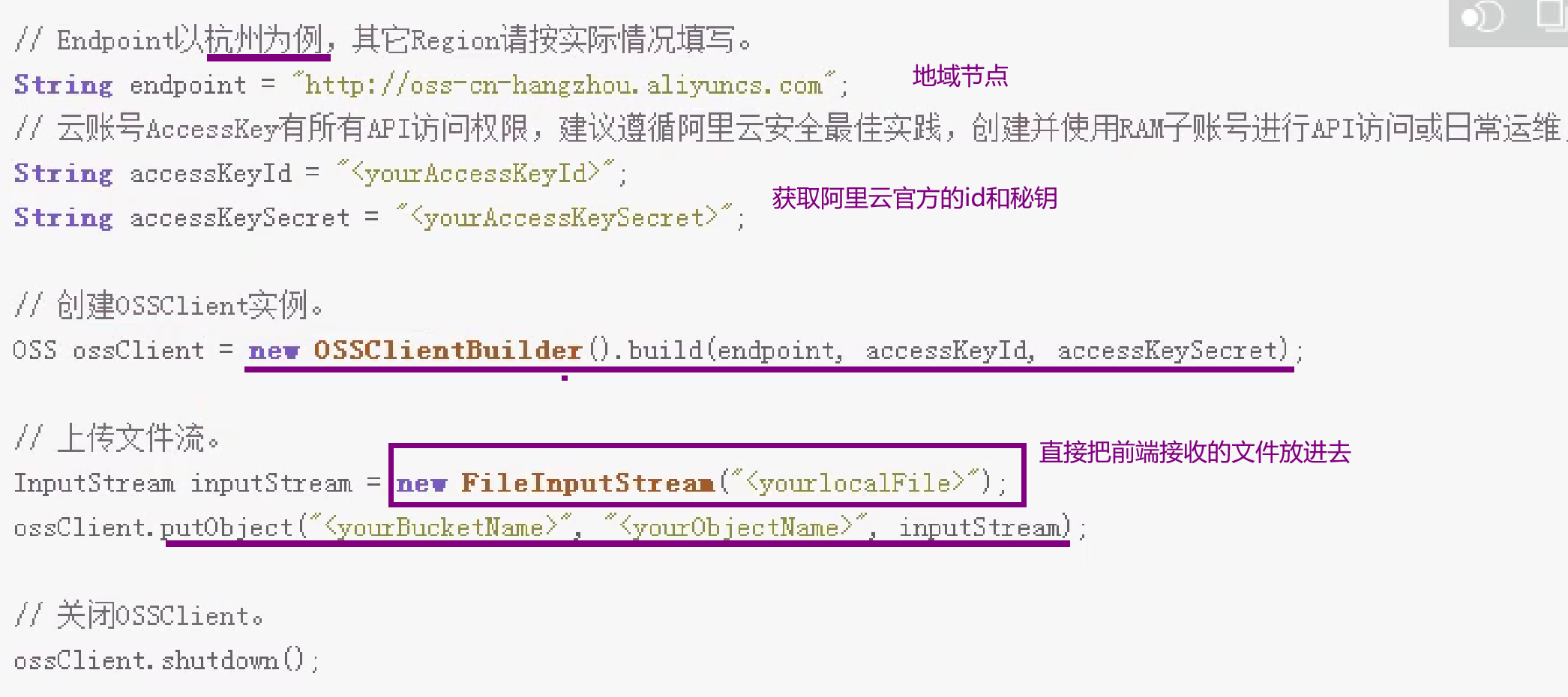
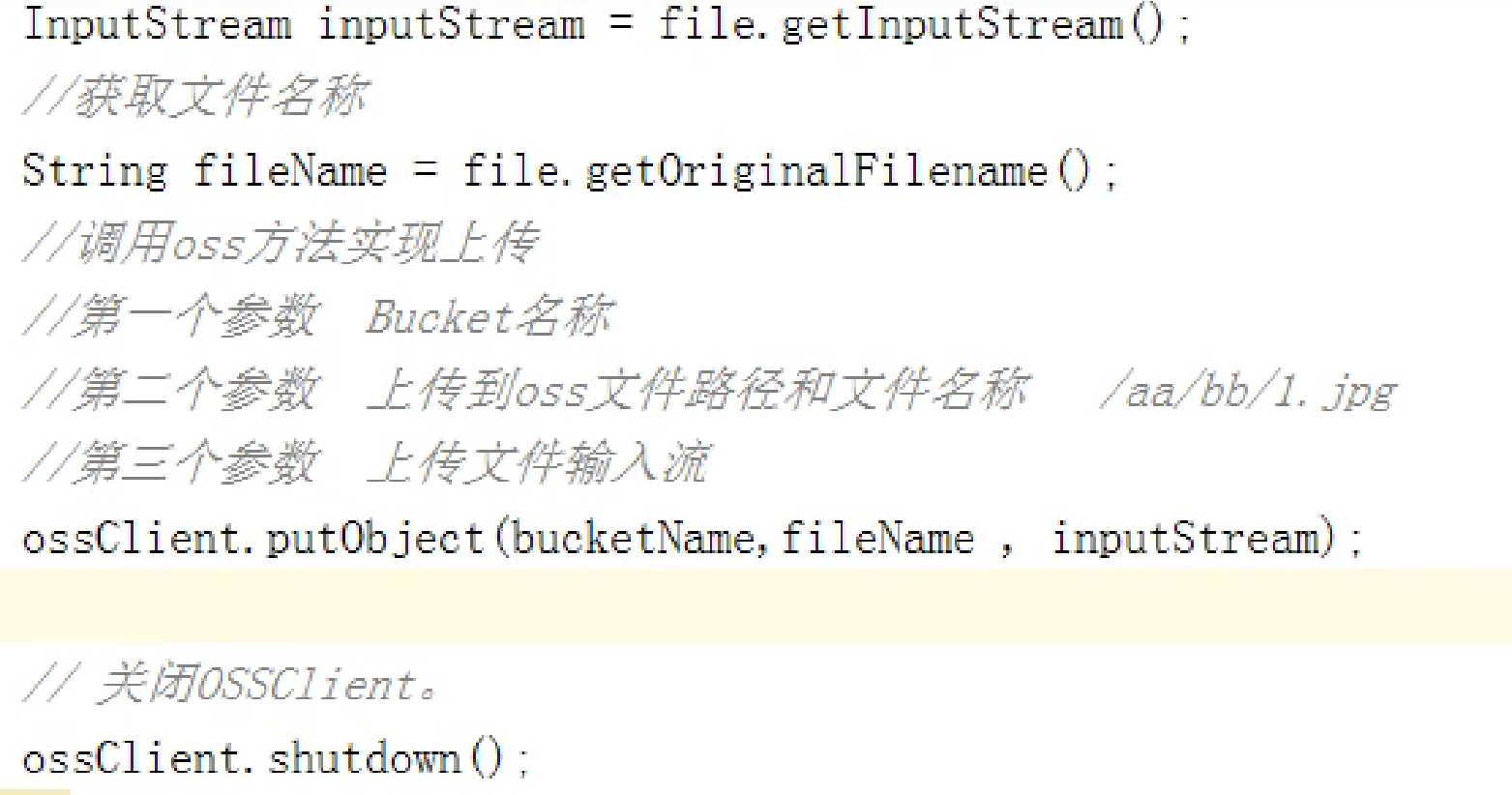
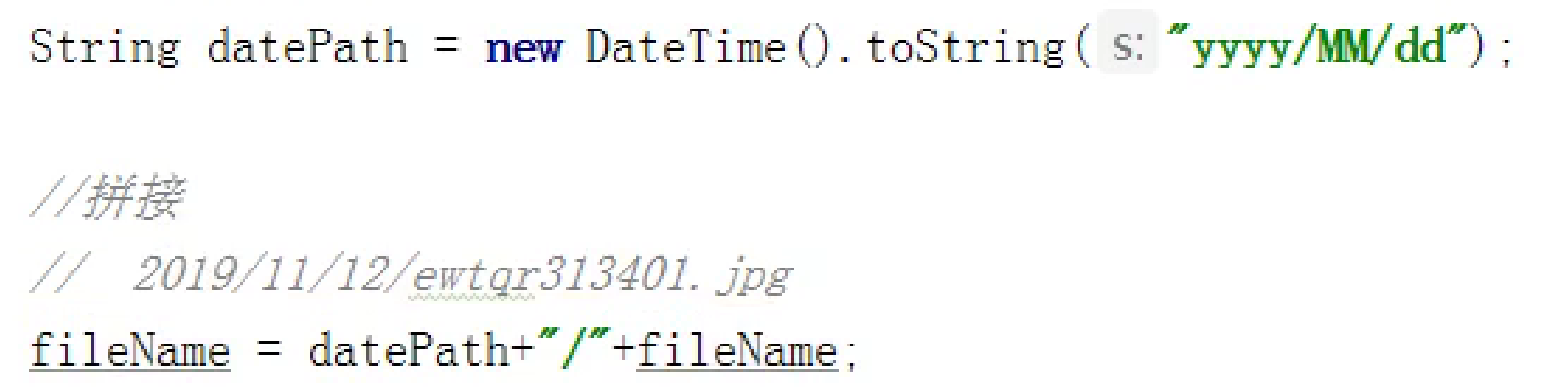
优化1:在文件每次里面添加随机唯一的值,UUID防止上传重复名字文件,会把之前的覆盖

优化2:根据日期分类文件
使用joda-time工具类,引入依赖
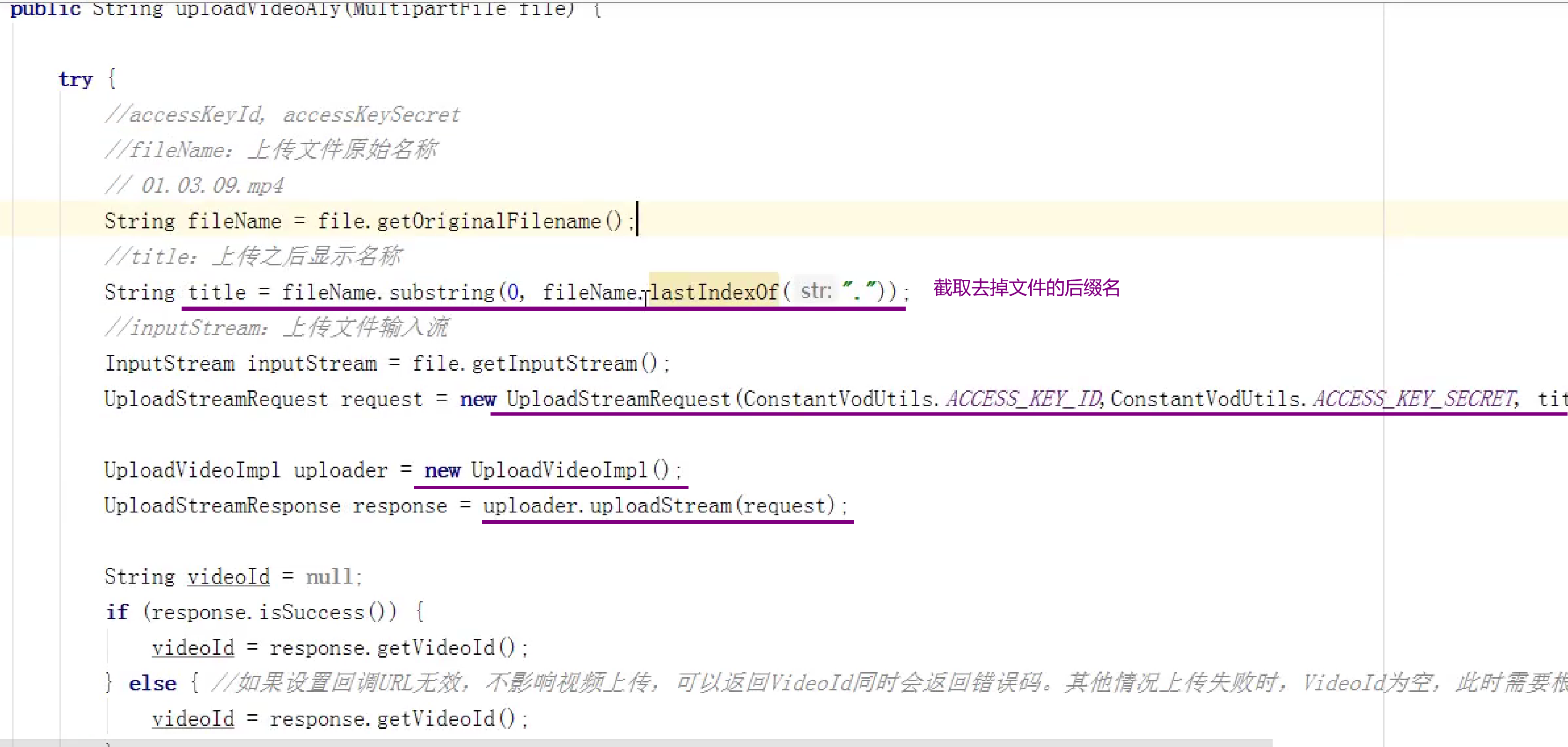
阿里云视频点播
可以在阿里云网页端设置视频转码,上传视频后就会转成你设置转码后的分辨率清晰度等,默认不转码
获取视频播放地址
获取视频id获取播放凭证
上传视频到阿里云视频点播服务
项目课程管理上传视频
写个controller前端传视频文件,我们后盾调用上传方法放回视频id给前端
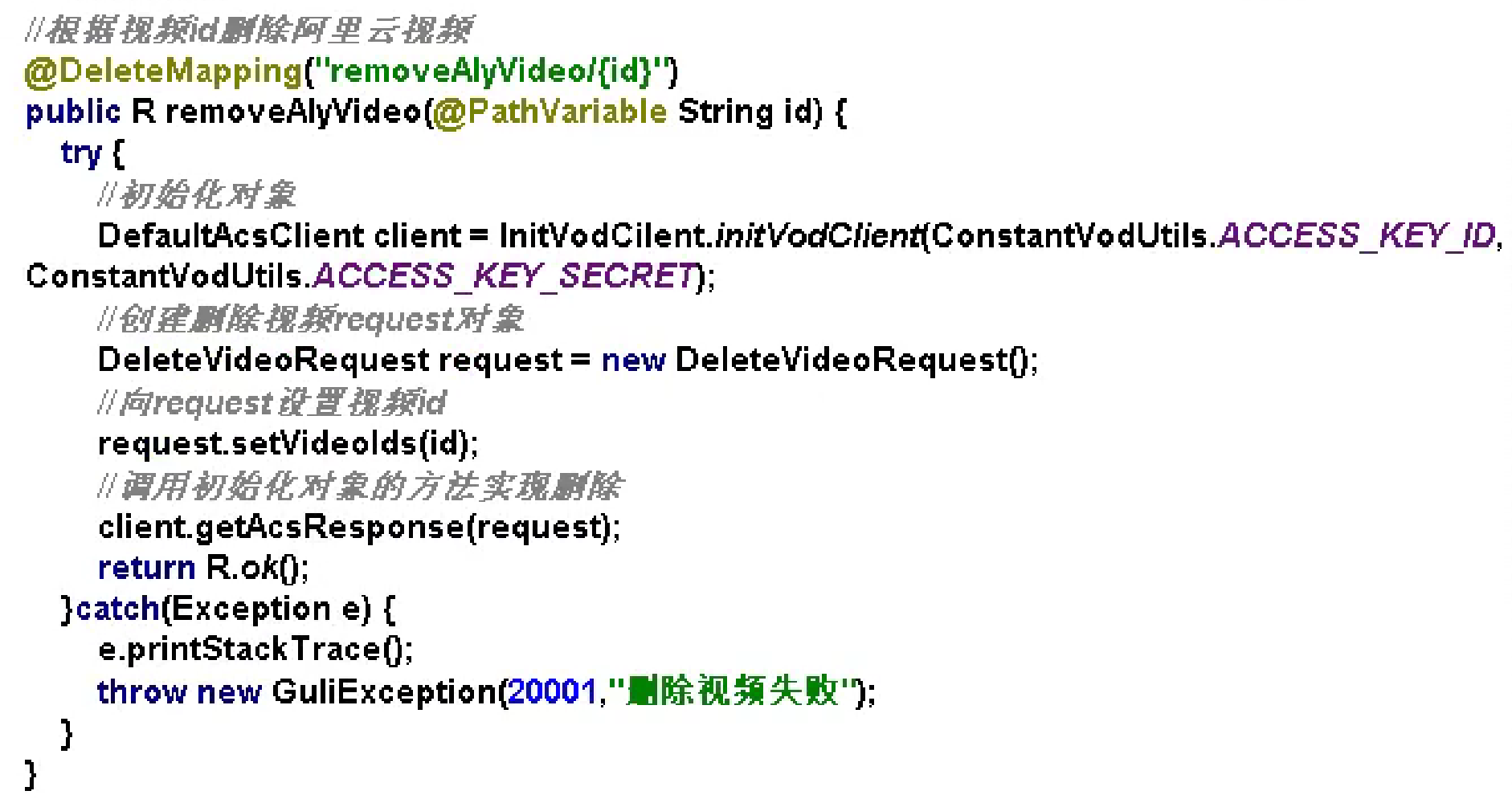
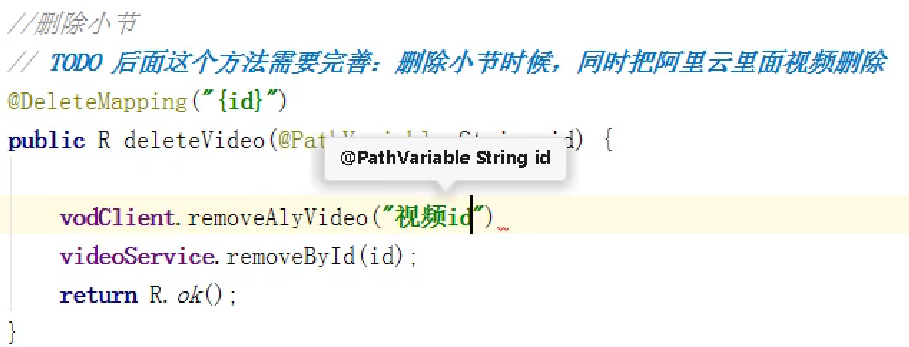
删除视频接口
阿里云短信服务
阿里云短信服务这是发送短信的,随机值验证码还是要自己用工具类生成,然后调用api发送
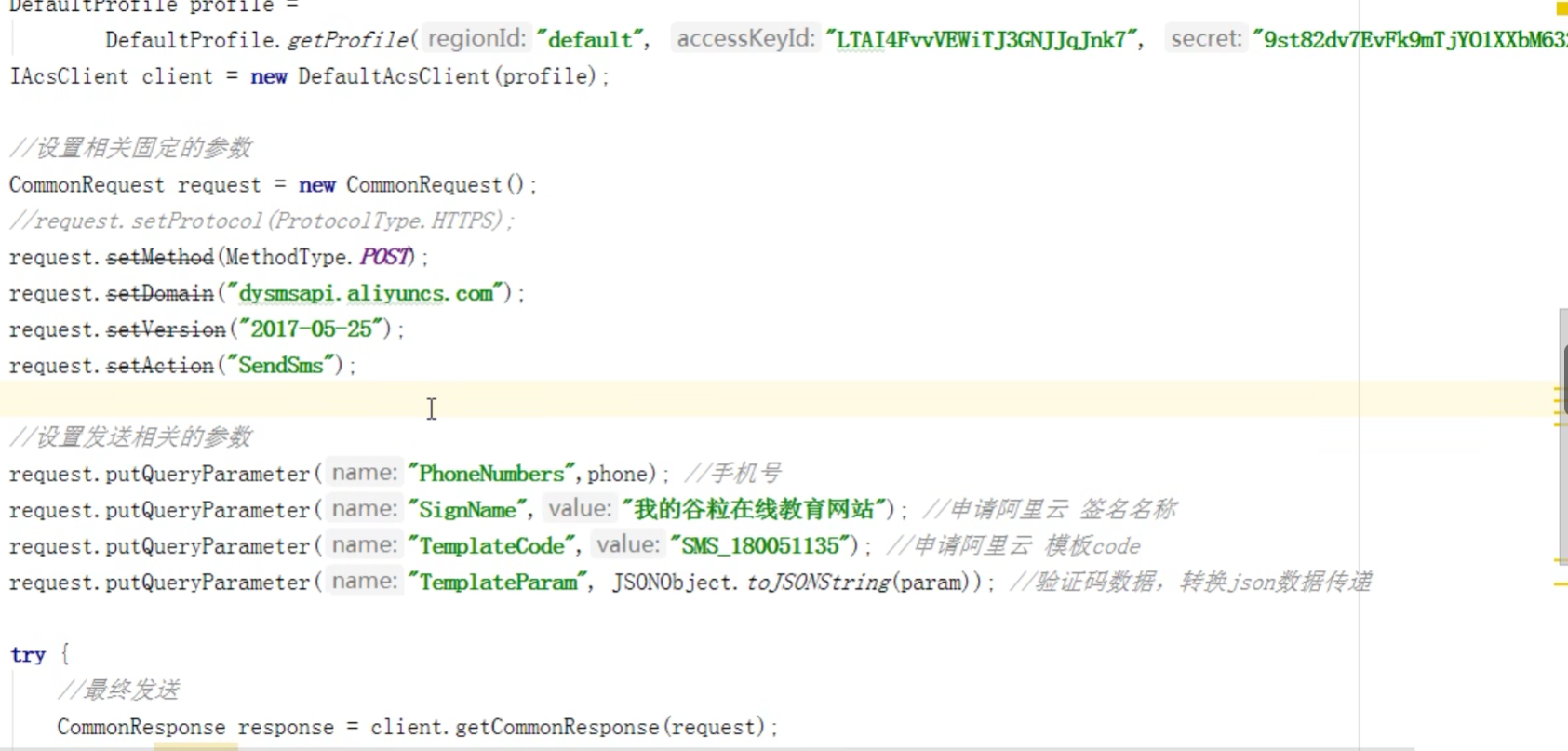
发送成功之后,把生成的验证码放到redis里面,并设置时间。手机号为key,验证码为value
五、微服务组件
Nacos
NAC早期Springcloud用的是Eureka可以当注册中心,但是遇到性能瓶颈,停止维护,现在用Nacos。
Nacos很强大可以替代springcloud很多原生组件,比如Eureka服务发现和config配置中心和Bus信息总线。一个nacos可以实现3个
注册中心
先在要注册的模块引入依赖
然后在模块的配置文件配置nacos的id端口号
然后启动类加上注解@EnableDiscoveryClient
最后就在nacos后台管理系统看到
配置中心
我们之前是每个模块都有个核心配偶文件,这样坏处是万一改数据库了,我们很多模块都要发生改变,这时候就需要配置中心做全局统一配置,实现配置的动态变更
在nacos后台配置列表新建配置文件,配置服务名称,dev,文件的扩展名yaml或properties或xml这些,然后完成创建
配置文件加载顺序(先加载bootstrap文件,然后加载application配置文件,如果application里面有spring.profiles.active=dev的话,还会加载application-dev的配)
所以要在项目中创建bootstrap文件,然后配配置nacos地址和配置中心的dataId
然后把我们原本application注解掉也可以了 他会去nacos里面读取配置
如果有环境dev这些还要去nacos新增命名空间,然后bootstrap添加命名空间
Feign
Feign是Netflix开发的组件,用他做服务调用,前提条件这些服务必须先注册
项目中,删除课程的时候调用视频模块删除视频
先引入依赖
在调用端的启动类添加@EnableFeignClients
在调用端创建interface使用注解指定调用服务名称,定义调用的方法路径

实现代码
Hystrix
Hystrix是提供延迟和容错功能,保证复杂系统面临失败时仍有弹性。
请求路线:先nacos注册,然后feign调用服务后会经过熔断器,然后ribbon负载均衡到要的服务
项目中整合熔断器
添加hystrix和ribbon的依赖
在调用端的配置文件中开启熔断器,在上配置,设置超时时间,默认1000毫秒
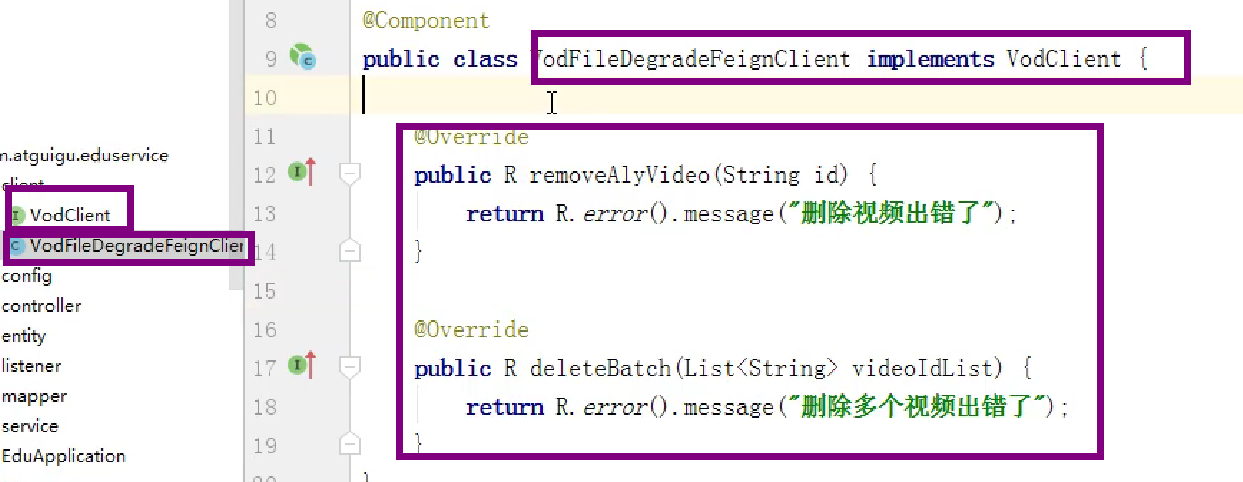
在创建Feign的interface之后,还需要创建interface刚刚那个接口的对应的实现类,实现方法说明出错的时候执行的方法(出错后执行)
最后在interface上面添加注解和属性
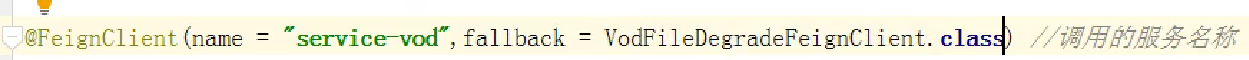
Gateway
Gateway网关也要去nacos注册,有路由,断言和过滤器。
配置好就行,这个项目网关就是哪来做路由转发的
项目中网关的配置
引入gateway依赖
创建启动类也要注册nacos的步骤注册进nacos,创建配置文件,在配置文件配置网关规则
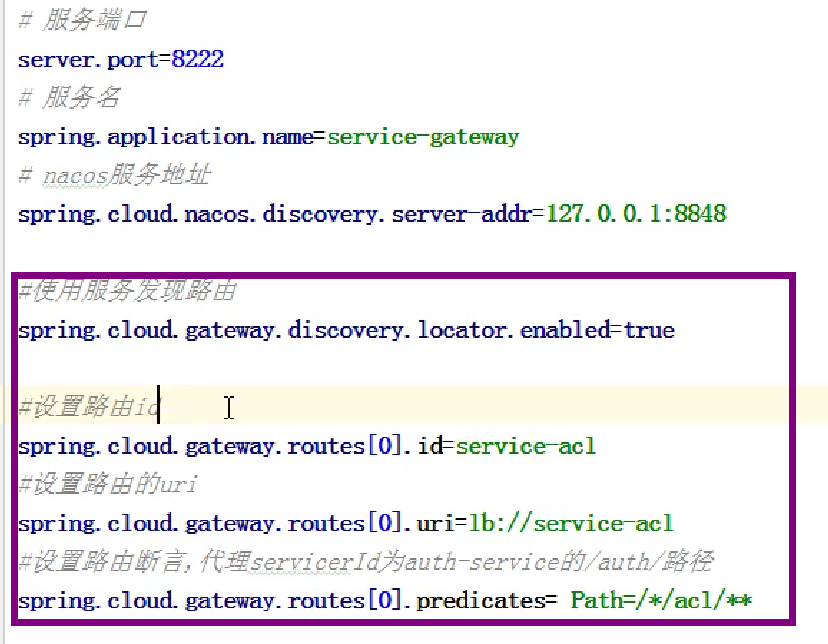

routes[]这个数字可以很多 ,0代表第一个服务
id是名字随便写
uri是固定写法,写的是nacos注册的服务名称
prediates断言表示匹配规则,path后面写的是路由的匹配值跟nginx那个一样检测到什么路径转发到上面的对应uri
这样配置好之后,我们只要访问8222端口这个网关的端口就行了,路径就写要调用的
用网关解决跨域问题

新增加一个config来解决跨域问题,加一个配置类,里面加一个插件处理让所有请求都没有跨域
网关统一过滤器
网关模块配置filter里面配置,可以做到全局的过滤器
六、单点登录

JWT
token是按照一定规则生成的字符串,包含用户信息,什么规则呢,jwt就是一种通用规则
JWT生成的字符串包含3部分:jwt头信息、有效载荷(主体部分,用户信息)、签名哈希(防伪标志)
引入jwt依赖和jwt的工具类
jwt工具类可以设置token的过期时间、秘钥。方法有:
通过用户id和名字生成token字符串的方法
判断token是否有效的方法(参数有为request,从request的请求头获取token再来判断是否有效)
通过token字符串获取用户信息
jwt的流程
登录输入密码账号比对正确就jwt生成token发前端
前端拿这个token存请求头,找后端要用户信息
后端根据这个token解析出id,然后查询数据库里面用户信息返回前端
以后的每个请求都会带着token发给后端
后端会用jwt工具对token进行检查,对token的“第一部分的头部”和“第二部分的载体”再进行一次加密,然后和“第三部分的秘钥”进行对比,有效没过期才能执行后面操作
存储位置
jwt token不需要存服务器,只需要存在客户端。服务器拿到token后,对token的“第一部分的头部”和“第二部分的载体”再进行一次加密,然后和“第三部分的秘钥”进行对比
总结:普通token需要和数据库比对,jwt token需要再次加密验证。
注意事项:
jwt token 第二部分的载体一般是放信息的部分,这是可逆的,所以不能放敏感的信息如密码等
引发思考:
为什么有些时候我们用jwt还要存redis,为了保证安全,不然用户拿到我们的秘钥也能破解,那既然用了jwt加redis还不如直接用原本的自定义token呢为什么要jwt呢?
就单点登录里的token而言,单点登录是为了实现一次登录其他相互信任的系统不用登陆就可访问的效果,既然如此就不止一个系统,每个系统的数据存在不同的数据库中,A系统不可以访问B系统的数据库,若将token存在于A系统数据库中,B系统登录时就访问不到token,但是所有系统都可以访问redis缓存数据库,而且token具有时效性,而redis天然支持设置过期时长【set(key,value,毫秒值)】,而且redis响应速度很快。
有这样一个场景,用户密码丢失后,修改密码后,如果token存储在redis中,可以避免旧密码生成的token到期之前依然可以通过接口访问用户信息
登录接口
登录的时候先接收前端的用户密码,然后根据用户账号和密码跟数据库比对看是否正确,密码加密后对比
正确登录成功,根据用户的id和名称,用jwt生成token字符串返回给前端
注册接口
获取用户注册的数据,手机号,验证码,名称,密码
获取redis里面的验证码(存到时候手机号为key,根据手机号来去验证码)
那手机号去数据库查有就不能添加,判断手机号是不是唯一
不唯一就添加
七、项目功能
后台系统功能
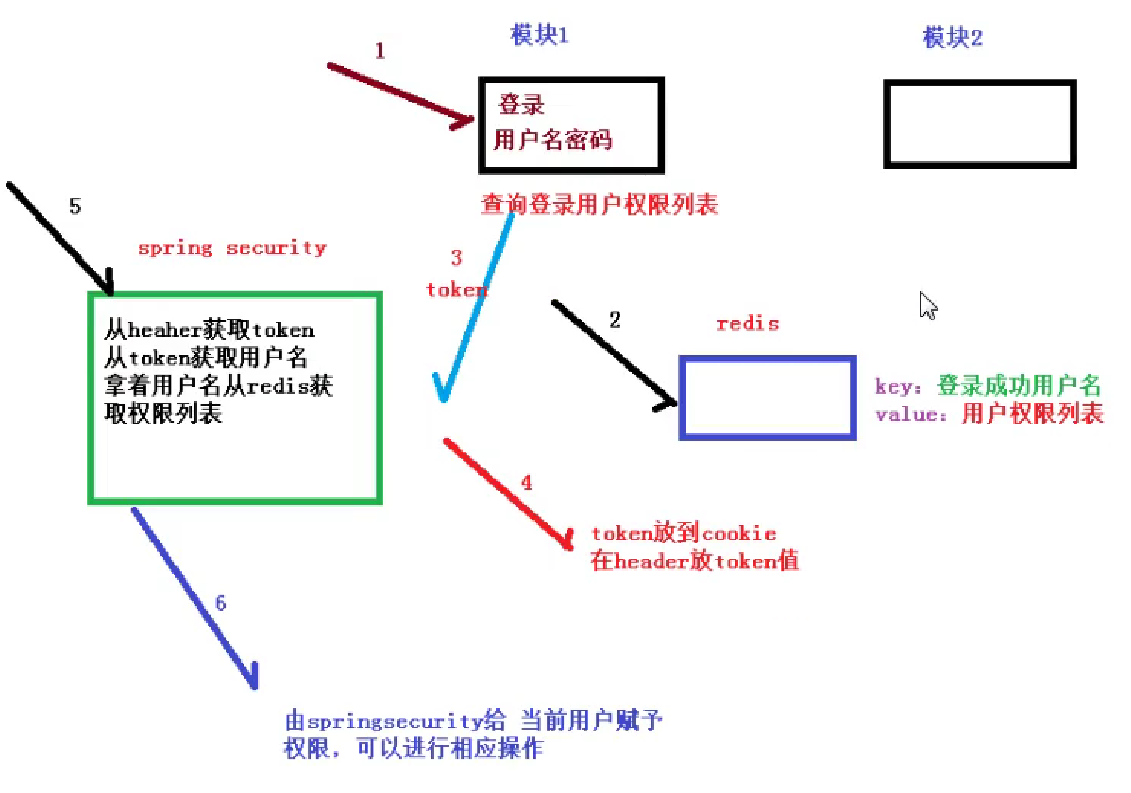
- 登录功能(SpringSecurity)
- 权限管理功能(重点)
功能:
菜单管理
角色管理
用户管理
重点:权限管理表和关系,用了5张表,要搞懂他们之间的关系
- 讲师管理模块
- 课程分类模块
添加课程分类:读取excel里面的课程分类数据添加到数据库中
这里要注意用到什么技术读取excel(面试)
- 课程管理模块
添加课程
如何判断课程是否已经发布了?因为有一个字段来判断状态,当我发布成功后就改状态为1
添加课程中,中途退出停止添加,重新添加新的课程,如何找到之前没有发布完成的课程,进行发布呢?到课程列表中根据课程状态查询未发布的课程,点击课程右边的超链接把课程进行完成发布。
添加小节的时候上传视频
- 统计分析模块
生成统计数据
统计数据图表显示 echat
前台系统功能
- 首页数据显示(显示热门课程 显示名师)
- 注册功能
获取手机验证码 用到阿里云的短信服务
3、登录功能
普通登录sso
SSO(单点登录)三种方式
session广播
在项目中任何一个模块登录,登录皇后把数据存这两个地方
cookie:把redis里面生成key值放到cookie里面
redis在key生成唯一随机值(ip、用户id等),在value存用户数据
访问项目中其他模块,发送请求带着cookie进行发送,获取cookie的值到redis查询,根据ke查,如果查询数据就是登录
使用token实现。在项目摸个模块登录后,按照规则生成字符串,把登录之后用户包含到生成字符串里面,把字符串返回,可以把字符串通过cookie返回,也可以字符串通过地址栏返回
再去访问其他模块,每次访问在地址栏带着生成的字符串,在访问模块里面获取地址栏字符串,根据字符串获取用户信息。可以获取到就是登录成功。
token是怎么生成的?
使用jwt生成token字符串
jwt有三部分组成:头信息+有效载荷(用户信息)+签名哈希(防伪标志)
登录和登录成功后显示数据实现过程?
先调用接口登录返回token字符串
把返回的token字符串放到cookie里面
创建前端拦截器,判断cookie是否有token字符串,有就放到header请求头里
根据token的值调用接口,根据token获取用户信息,为了首页面显示,把调用接口返回的用户信息也放到cookie里面
在首页显示用户信息,从cookie获取用户信息
微信扫描登录
OAuth2
主要解决两个问题:开发系统间授权,分布式访问(单点登录)
如果获取扫码人信息
扫码之后,执行本地的callback方法,在callback获取两个值,在跳转时候传递过来,state原样传递,code类似于手机验证码,随机唯一值
拿着获取的code请求微信固定地址,获取到两个值access_token访问凭证,openid每个微信唯一标识
拿着第二部的两个值再去访问一个微信提供固定地址,最终可以看到扫码人信息,比如微信名称头像等
4、课程列表功能
条件查询分页列表功能
5、课程视频播放
(阿里云的视频点播)
6、课程支付功能
微信支付
生成课程订单
生成微信支付二维码
微信支付(支付之后,每隔3秒去查询支付状态看是否成功,如果没有支付成功等待,如果支付成功,先去更新订单状态,改为成功,向支付记录表添加支付成功记录)
八、后端技术总结
- 微服务架构
Nacos:使用Nacos做注册中心,配置中心
Feign:服务调用,一个微服务的模块去调用另一个微服务的模块,实现远程调用,课程模块调用订单模块看课程是否已经购买,课程模块掉视频模块拿凭证播放视频等
熔断器
Gateway网关
2、
- EasyExcel
阿里巴巴提供的操作excel工具,代码简洁,效率高,easyexcel采用sax方式解析,对poi框架进行封装,一行一行进行读取进行操作,不会出现内存溢出问题,解决了poi很多性能的问题。
项目:课程分类模块导入课程分类的时候可以导入excel表格,读取excel数据
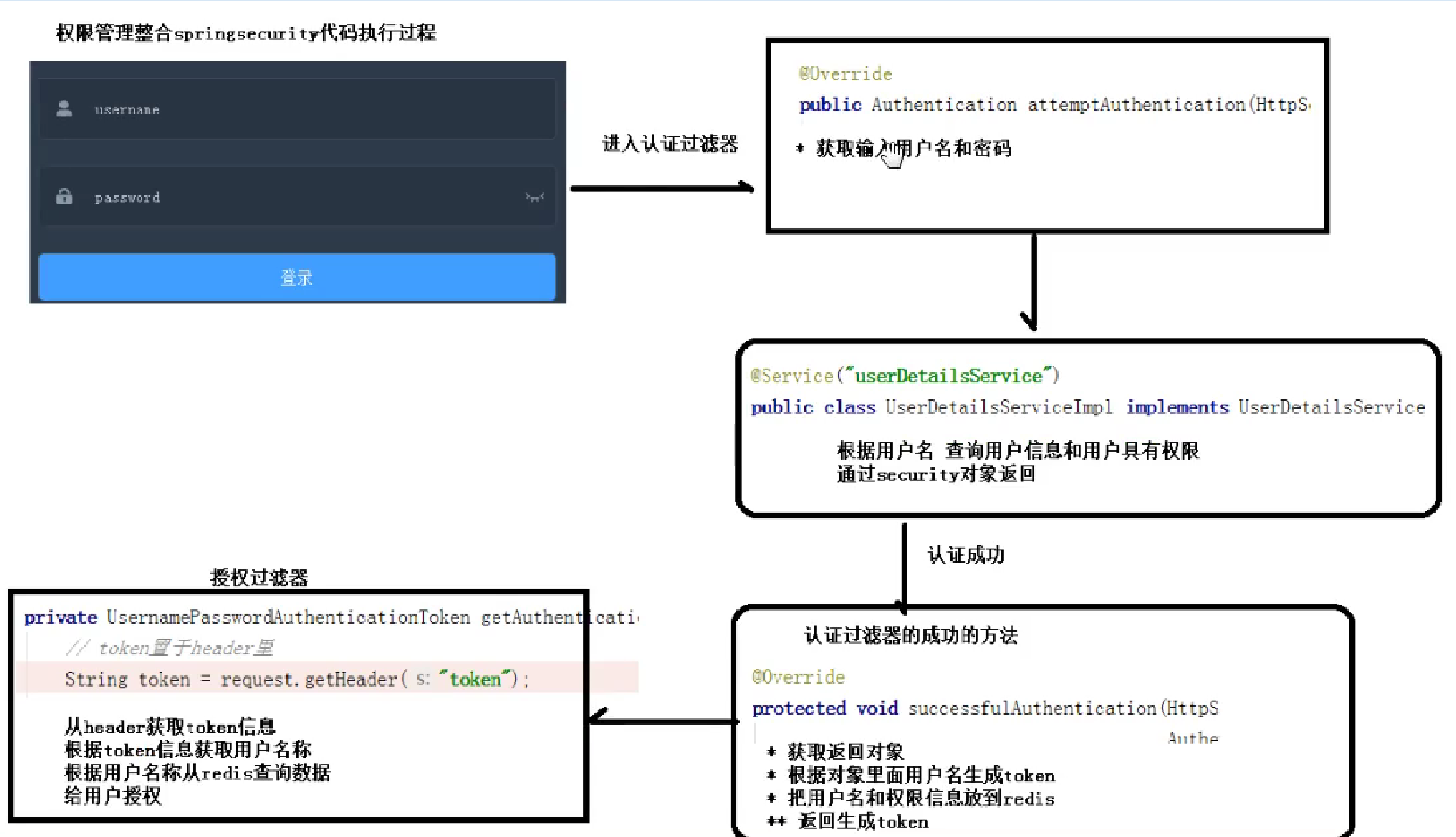
- SpringSecurity
实现权限管理功能
组成:认证和授权
登录认证过程
代码执行过程
- redis
首页数据缓存
redis数据类型
redis作为缓存,什么样的数据适合缓存,不太重要不经常改动的数据放到redis缓存
- Nginx
反向代服务器
做请求转发
面试可以提到负载均衡,一样的模块,轮询和权重
- OAuth2+JWT
针对特点问题解决方案
JWT包含三部分
- HttpClient
发送请求和返回响应的工具,不需要浏览器可以完成请求和响应的过程
项目:微信登录获取扫码人信息的时候,微信支付查询支付状态的时候
- 微信
微信登录
微信支付
- 阿里云
OSS文件存储:讲师头像
视频点播:视频上传、删除、播放、整合阿里云的视频播放器、使用视频播放凭证
短信服务:注册的时候,发送手机验证码
10、docker
九、项目遇到的问题
跨域问题
在controller上加注解解决
通过网关解决
413问题
上传视频的时候,因为Nginx上传文件大小限制,如果超过Nginx大小,就会出现413问题
413错误:请求体过大
在Nginx里面配置客户端大小
请求状态码常见还有:403跨域问题,302重定向
Maven加载问题
maven默认加载项目的时候,默认不会加载src-java文件里面xml文件,我们写的mapperxml就没有,我就手动复制到target里面去
mp生成19位id问题
mp的主键策略雪花算法生成19位id,这个19位id如果是用long类型返回到前端JavaScript最多只能解析16位,我们必须把id设置为String类型,然后雪花算法注解也得加上Str