大数据分案例-基于随机森林算法构建返乡人群预测模型

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.项目简介
2.1研究目的及意义
2.2研究方法与思路
2.3技术工具
3.算法原理
4.项目实施步骤
4.1理解数据
4.2探索性数据分析
4.3数据预处理
4.4特征工程
4.5模型构建
4.6模型评估
5.实验总结
源代码
1.项目背景
随着经济的快速发展,北上广等一线城市快速崛起,主要的原因还是靠近沿海以及之前的打工潮,大批的内地人背井离乡来到大城市发展。俗话说的好,先富带动后富,现在一些二三四线城市也慢慢发展起来了,而且在疫情的背景下,一线城市经济收到较大的影响,越来越多的人们开始选择返乡发展,本次实验用Python工具来构建返乡发展模型,分析未来的趋势。
2.项目简介
2.1研究目的及意义
由于乡村发展措施的完善以及国家大力支持乡村振兴发展战略,越来越多的人们响应国家的政策,开始返乡发展,本次实验利用python大数据工具来分析人们返乡意愿,预测未来的返乡趋势,以便各地可以及时指定更好的发展策略。
2.2研究方法与思路
使用pandas读取数据、分析数据、做数据预处理,然后使用sklearn构建逻辑回归和随机森林模型,最高对模型做出评估。
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
4.项目实施步骤
4.1理解数据
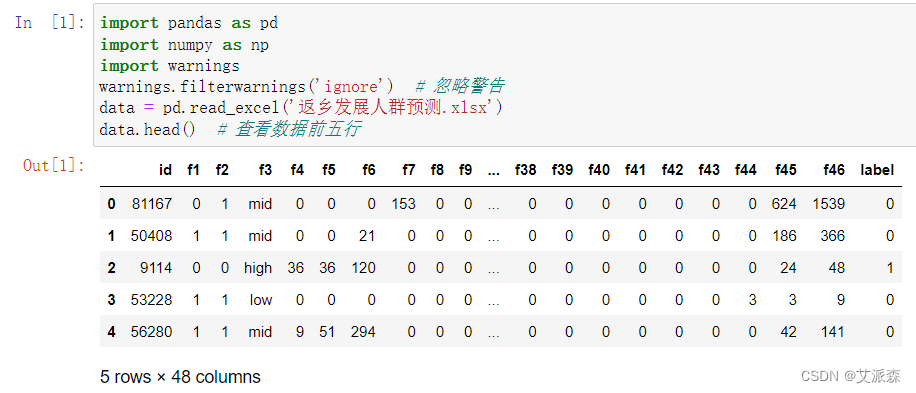
首先导入数据并查看数据前五行
查看数据形状

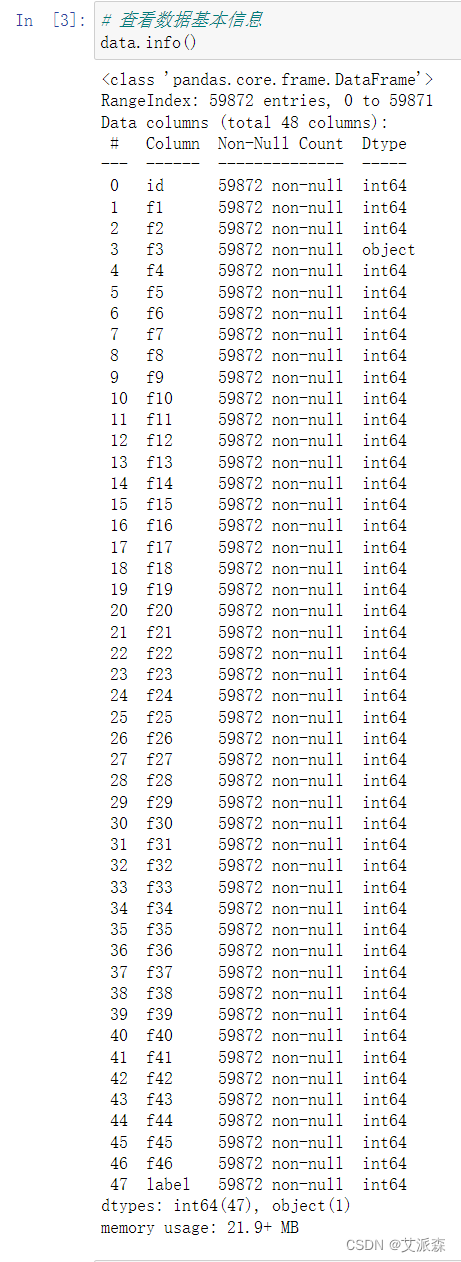
数据共有59872行,48列
查看数据基本信息
4.2探索性数据分析
使用seaborn可视化查看label的比例
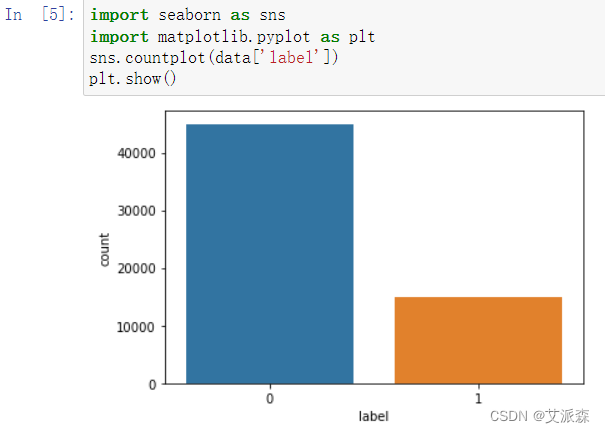
可以发现0的比例较多,大约是1的三倍。
4.3数据预处理
查看数据是否存在缺失值
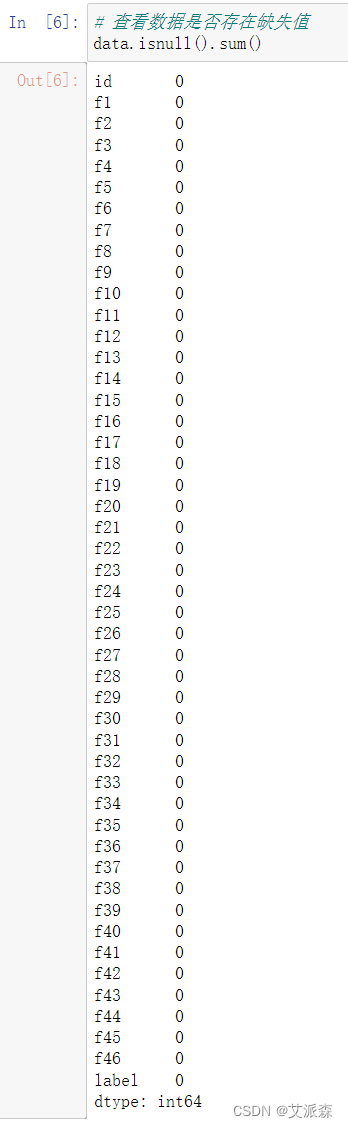
可以发现每一列数据都不存在缺失值,不需要处理。
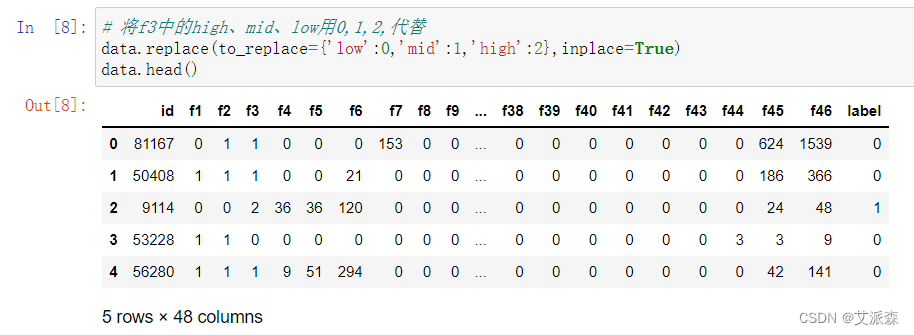
这里将f3中的low、mid、high用0,1,2代替。
4.4特征工程

这里特征选择的时候,选取除了id和label列作为自变量X,选取了label列作为因变量。然后划分数据数据集,测试集比例为0.2,训练集比例为0.8。
4.5模型构建
构建逻辑回归模型

逻辑回归的模型准确率为0.80
接着构建随机森林模型
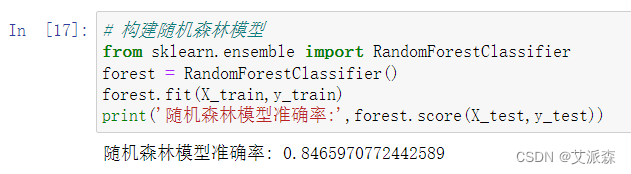
可以看见随机森林模型的准确率为0.84大于逻辑回归模型的准确率,所有应该选择使用随机森林模型。
4.6模型评估
使用confusion_matrix混淆矩阵来评估模型
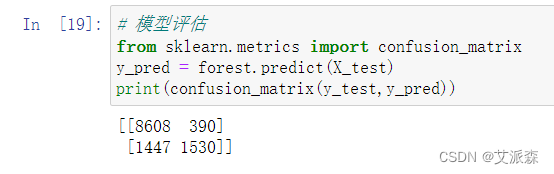
从打印的结果看出,模型在分类0的时候正确的个数有8608个,错误的个数有390;在分类1的时候正确的个数有1447个,错误的有1530个。
5.实验总结
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
源代码
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore') # 忽略警告
data = pd.read_excel('返乡发展人群预测.xlsx')
print(data.head()) # 查看数据前五行
# 打印数据形状
print(data.shape)
# 查看数据基本信息
print(data.info())
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(data['label'])
plt.show()
# 查看数据是否存在缺失值
print(data.isnull().sum())
# 将f3中的high、mid、low用0,1,2,代替
data.replace(to_replace={'low':0,'mid':1,'high':2},inplace=True)
print(data.head())
# 准备建模的数据
X = data.iloc[:,1:-1] # 提取出f1-f46的数据作为自变量
y = data['label'] # 选取label作为因变量
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2) # 划分数据集
# 构建逻辑回归模型
from sklearn.linear_model import LogisticRegression
lg = LogisticRegression()
lg.fit(X_train,y_train)
print('逻辑回归模型准确率:',lg.score(X_test,y_test))
# 构建随机森林模型
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier()
forest.fit(X_train,y_train)
print('随机森林模型准确率:',forest.score(X_test,y_test))
# 模型评估
from sklearn.metrics import confusion_matrix
y_pred = forest.predict(X_test)
print(confusion_matrix(y_test,y_pred))