【机器学习之模型融合】Voting投票法简单实践

目录
前言💜
1、使用sklearn实现投票法💔
1.1、导入工具库,准备数据💕
1.2、定义交叉验证评估函数💖
1.3、建立基于交叉验证的benchmark、做模型选择🌟
1.4、构建多组分类器、进行融合💥
1.5、构建多样性🎶
1.5.1、多种多样性混合👋
1.5.2、剔除表现不良的算法🐷
1.5.3、尝试精简多样性🐟
2、分类器加权🌷
3、总结💝
前言💜
Voting投票法基础知识参考:http://t.csdn.cn/1DVVl
1、使用sklearn实现投票法💔

1.1、导入工具库,准备数据💕
#常用工具库
import re
import numpy as np
import pandas as pd
import matplotlib as mlp
import matplotlib.pyplot as plt
import time
#算法辅助 & 数据
import sklearn
from sklearn.model_selection import KFold, cross_validate
from sklearn.datasets import load_digits #分类 - 手写数字数据集
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
#算法(单一学习器)
from sklearn.neighbors import KNeighborsClassifier as KNNC
from sklearn.neighbors import KNeighborsRegressor as KNNR
from sklearn.tree import DecisionTreeRegressor as DTR
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.linear_model import LinearRegression as LR
from sklearn.linear_model import LogisticRegression as LogiR
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.ensemble import GradientBoostingRegressor as GBR
from sklearn.ensemble import GradientBoostingClassifier as GBC
from sklearn.naive_bayes import GaussianNB
import xgboost as xgb
#融合模型
from sklearn.ensemble import VotingClassifier
from sklearn.ensemble import VotingRegressor使用sklearn自带的手写数字数据集,是一个10分类数据集。
data = load_digits()
X = data.data
y = data.target
- 我们将在Xtrain,Ytrain上进行交叉验证,并在Xtest,Ytest上进行最后的测试。
- 我们的目标是:交叉验证的结果尽量好(理论泛化能力强),同时测试集上的结果也需要尽量好(理论泛化能力的验证,但不完全严谨)。当两者不可兼得时,我们优先考虑交叉验证的结果(理论泛化能力强)。
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.2,random_state=1412)1.2、定义交叉验证评估函数💖
def individual_estimators(estimators):
"""
对模型融合中每个评估器做交叉验证,对单一评估器的表现进行评估
"""
for estimator in estimators:
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
results = cross_validate(estimator[1],Xtrain,Ytrain
,cv = cv
,scoring = "accuracy"
,n_jobs = -1
,return_train_score = True
,verbose=False)
test = estimator[1].fit(Xtrain,Ytrain).score(Xtest,Ytest)
print(estimator[0]
,"\n train_score:{}".format(results["train_score"].mean())
,"\n cv_mean:{}".format(results["test_score"].mean())
,"\n test_score:{}".format(test)
,"\n")
- train_score:模型在训练集上进行训练的得分表现的均值
- cv_mean:模型通过交叉验证在验证集上的得分表现的均值
- test_score:训练好的模型在测试集上的得分表现
def fusion_estimators(clf):
"""
对融合模型做交叉验证,对融合模型的表现进行评估
"""
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
results = cross_validate(clf,Xtrain,Ytrain
,cv = cv
,scoring = "accuracy"
,n_jobs = -1
,return_train_score = True
,verbose=False)
test = clf.fit(Xtrain,Ytrain).score(Xtest,Ytest)
print("train_score:{}".format(results["train_score"].mean())
,"\n cv_mean:{}".format(results["test_score"].mean())
,"\n test_score:{}".format(test)
)1.3、建立基于交叉验证的benchmark、做模型选择🌟
一般在模型融合之前,我们需要将所有可能的算法都先简单运行一次,然后从中选出表现较好的算法作为融合的基础。同时,我们还可能在分数最高的单一算法上进行精确的调优,找到单一算法可以实现的最好分数来作为benchmark。毕竟,融合要求使用多个算法、自然也会在运算时间和算力上有所要求,如果单一算法的结果能够胜过融合,那我们优秀选择单一算法。我们使用备选分类器中的逻辑回归作为benchmark。
logi = LogiR(max_iter=3000, n_jobs=8) #初始情况下给与一个较大的max_iter,方便迭代到收敛
fusion_estimators(logi) #正处于过拟合状态,需要调整
1.4、构建多组分类器、进行融合💥
- 第一组分类器:放任自由,收敛为主,有较高过拟合风险
- 逻辑回归+随机森林+梯度提升树
clf1 = LogiR(max_iter = 3000,random_state=1412,n_jobs=8)
clf2 = RFC(n_estimators= 100,random_state=1412,n_jobs=8)
clf3 = GBC(n_estimators= 100,random_state=1412)
estimators = [("Logistic Regression",clf1), ("RandomForest", clf2), ("GBDT",clf3)]
clf = VotingClassifier(estimators,voting="soft")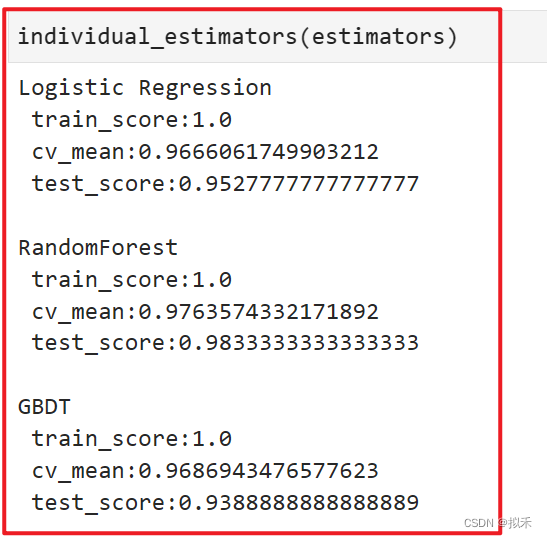
- 不难发现,每个模型在训练集上的分数都达到了1,但交叉验证分数大约在96%~97%之间,与逻辑回归的benchmark展现出来的结果相同。
- 模型都存在一定的过拟合情况,其中GBDT在测试数据上表现出来的泛化能力有很大的问题,需要较为激进的调整。
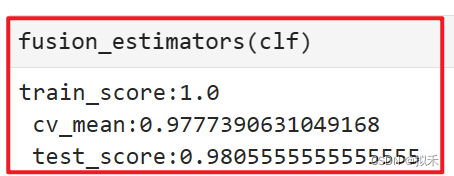
很明显,通过集成模型的表现有了显著提升,交叉验证分数(97.77%)比任何单一学习器都高,且在测试集上的表现提升到了98.05%,可见当前数据下模型融合的效果十分显著。
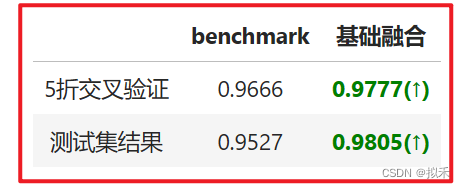
并不是任意评估器、任意数据上都能够看到如此一目了然的结果。如果你进行投票或平均融合之后,融合的结果反而没有单个算法好,那你可能是落入了投票法与平均法会失效的几大陷阱:
- 评估器之间的学习能力/模型表现差异太大。在融合中,一个表现很差的模型会拉低整个融合模型的上限,尤其是回归类算法,当一个模型的表现很差时,平均法得出的结果很难比最好的单一算法还好。因此我们必须要使用表现相似的模型进行融合。如果你的评估器中有拖后腿的模型,无论这个模型有多么先进,都应该立刻把它剔除融合模型。
- 评估器在类型上太相似,比如、全是树模型、都是Boosting算法,或都是线性评估器等。如果评估器类别太相似,模型融合会发挥不出作用,这在直觉上其实很好理解:如果平均/投票的评估器都一致,那融合模型最终得出的结果也会与单个评估器一致。
- 对评估器进行了过于精密的调优。一般来说,我们可能会认为,先对模型进行调优后再融合,能够进一步提升模型的表现。经过粗略调优的评估器融合确实能提升模型表现,但如果对评估器进行过于精密的调优,可能会让融合后的算法处于严重过拟合的状态。因此,一般我们不会在评估器上进行太精准的调优。
- 第二组分类器:略微调参(非精细化调参),限制过拟合
- 模型融合是一个可能加剧过拟合的手段,因此我们必须保证每一个学习器本身的过拟合不严重,为此我们需要对模型进行抗过拟合的处理。需要注意的是,对抗过拟合可能会削弱模型的预测效果,因此我们必须根据过拟合的情况、泛化能力的展现来进行选择。
- 对于逻辑回归,我们需要缩小参数C,对随机森林我们选择max_depth,对GBDT我们则选择
max_features。
clf1 = LogiR(max_iter = 3000, C=0.1, random_state=1412,n_jobs=8) #这一组合可能说明我们的max_iter设置得太大了
clf2 = RFC(n_estimators= 100,max_depth=12,random_state=1412,n_jobs=8)
clf3 = GBC(n_estimators= 100,max_features="sqrt",random_state=1412)
estimators = [("Logistic Regression",clf1), ("RandomForest", clf2), ("GBDT",clf3)]
clf = VotingClassifier(estimators,voting="soft")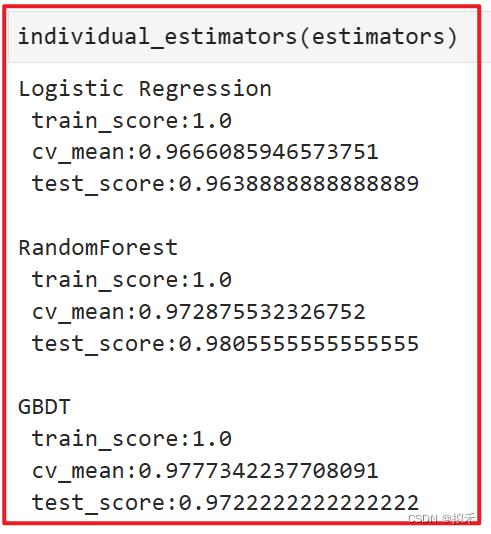
- 针对逻辑回归的调整效果不是非常明显,交叉验证的分数并未得到明显提升,但测试集上的结果上升,说明模型的泛化能力变得更加稳定了。但C参数是很少小于0.5的,我们现在得出的结果可能说明模型的权重是非常非常小的数,所以我们必须给与很小的C才能够加强过拟合的影响。
- 随机森林的过拟合变得更加严重了,这说明我们限制过拟合对模型带来的伤害大于对模型的帮助,因此随机森林的过拟合是失败的,应该取消这种过拟合限制。
- GBDT的过拟合调整是非常成功的,交叉验证分数上升的同时,测试集上的分数也得到了大幅提升。
- 结论是,我们保留对逻辑回归和GBDT的调整,撤销对随机森林的调整
clf1 = LogiR(max_iter = 3000, C=0.1, random_state=1412,n_jobs=8) #这一组合可能说明我们的max_iter设置得太大了
clf2 = RFC(n_estimators= 100,random_state=1412,n_jobs=8)
clf3 = GBC(n_estimators= 100,max_features="sqrt",random_state=1412)
estimators = [("Logistic Regression",clf1), ("RandomForest", clf2), ("GBDT",clf3)]
clf = VotingClassifier(estimators,voting="soft")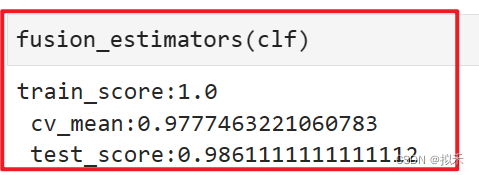
可以看到,经过过拟合调整后,模型的交叉验证分数与测试集上的分数都上升了,不过交叉验证分数是轻微上升(从0.9777392上升至0.9777463),这轻微的上升可以忽略不计。测试集上的分数则有了0.06%的提升,是一个显著的进步。
1.5、构建多样性🎶
无论是投票法还是平均法,都与Bagging算法有异曲同工之妙,因此我们相信“独立性”也有助于提升投票融合与平均融合的效果。在模型融合当中,独立性被称为“多样性”(diversity),评估器之间的差别越大、彼此之间就越独立,因此评估器越多样,独立性就越强。完全独立的评估器在现实中几乎不可能实现,因为不同的算法执行的是相同的预测任务,更何况大多数时候算法们都在相同的数据上训练,因此评估器不可能完全独立。但我们有以下关键的手段,用来让评估器变得更多样、让评估器之间相对独立:
- 训练数据多样性:完成多组有效的特征工程,使用不同的特征矩阵训练不同的模型。该方法一般能够得到很好的效果,但如何找出多组有效的特征工程是难题。
- 样本多样性:使用相同特征矩阵,但每次训练时抽样出不同的样本子集进行训练。当数据量较小时,抽样样本可能导致模型效果急剧下降。
- 特征多样性:使用相同特征矩阵,但每次训练时抽样出不同的特征子集进行训练。当特征量较小时,抽样特征可能导致模型效果急剧下降。
- 随机多样性/训练多样性:使用相同的算法,但使用不同的随机数种子(会导致使用不同的特征、样本、起点)、或使用不同的损失函数、使用不同的不纯度下降量等。这一方法相当于是在使用Bagging集成。
- 算法多样性:增加类型不同的算法,如集成、树、概率、线性模型相混合。但需要注意的是,模型的效果不能太糟糕,无论是投票还是平均法,如果模型效果太差,可能大幅度降低融合的结果。
增加多样性的操作或多或少都阻止了模型学习完整的数据,因此会削弱模型对数据的学习,可能降低模型的效果。因此我们使用多样性时,需要时刻关注着模型的结果。
1.5.1、多种多样性混合👋
#逻辑回归没有增加多样性的选项
clf1 = LogiR(max_iter = 3000, C=0.1, random_state=1412,n_jobs=8)
#增加特征多样性与样本多样性
clf2 = RFC(n_estimators= 100,max_features="sqrt",max_samples=0.9, random_state=1412,n_jobs=8)
#特征多样性,稍微上调特征数量
clf3 = GBC(n_estimators= 100,max_features=16,random_state=1412)
#增加算法多样性,新增决策树、KNN、贝叶斯
clf4 = DTC(max_depth=8,random_state=1412)
clf5 = KNNC(n_neighbors=10,n_jobs=8)
clf6 = GaussianNB()
#新增随机多样性,相同的算法更换随机数种子
clf7 = RFC(n_estimators= 100,max_features="sqrt",max_samples=0.9, random_state=4869,n_jobs=8)
clf8 = GBC(n_estimators= 100,max_features=16,random_state=4869)
estimators = [("Logistic Regression",clf1), ("RandomForest", clf2)
, ("GBDT",clf3), ("Decision Tree", clf4), ("KNN",clf5)
, ("Bayes",clf6), ("RandomForest2", clf7), ("GBDT2", clf8)
]
clf = VotingClassifier(estimators,voting="soft")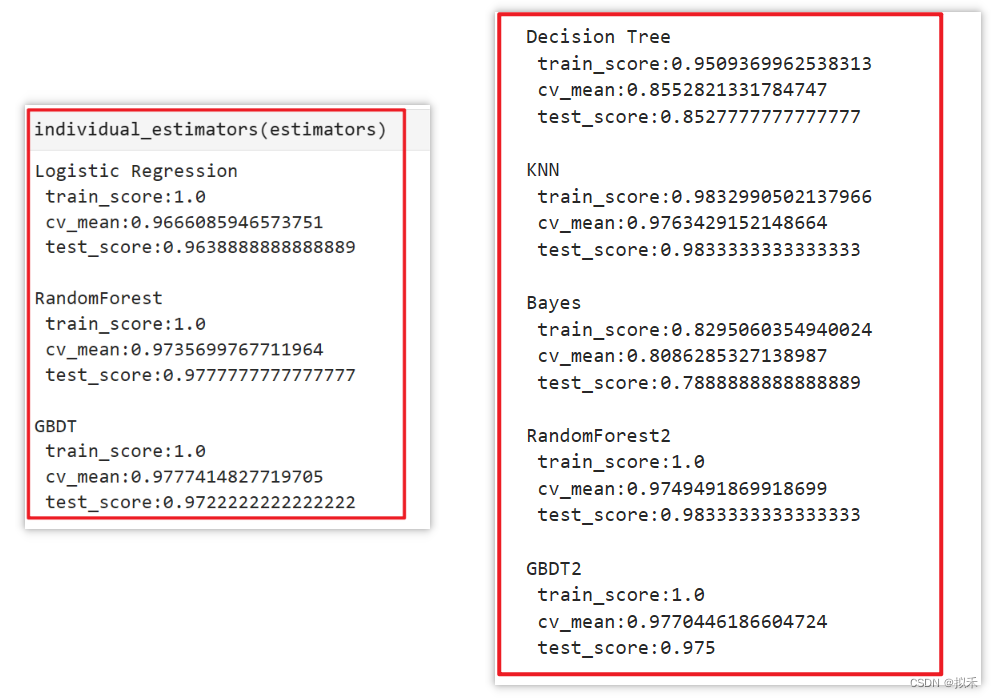
贝叶斯在训练集上的分数很低,这说明模型的学习能力不足
1.5.2、剔除表现不良的算法🐷
estimators = [("Logistic Regression",clf1), ("RandomForest", clf2)
, ("GBDT",clf3), ("Decision Tree", clf4), ("KNN",clf5)
#, ("Bayes",clf6) 贝叶斯在训练集上的分数很低,这说明模型的学习能力不足
, ("RandomForest2", clf7), ("GBDT2", clf8)
]
clf = VotingClassifier(estimators,voting="soft")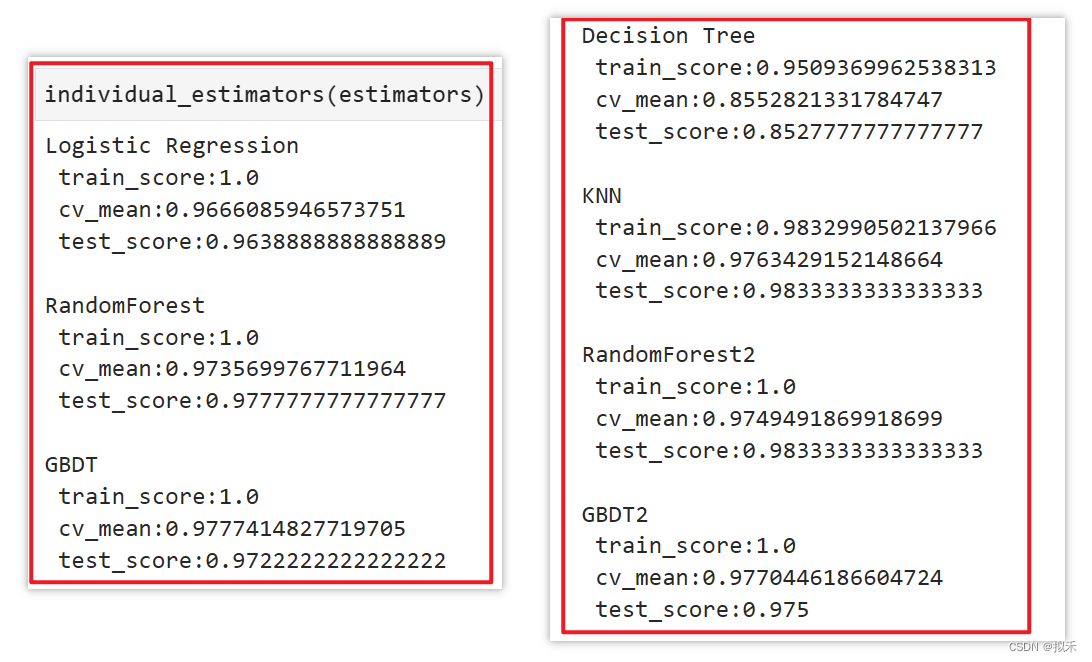
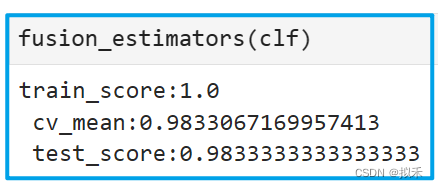
1.5.3、尝试精简多样性🐟
estimators = [("Logistic Regression",clf1), ("RandomForest", clf2)
, ("GBDT",clf3), ("Decision Tree", clf4), ("KNN",clf5)
#, ("Bayes",clf6), ("RandomForest2", clf7), ("GBDT2", clf8)
]
clf = VotingClassifier(estimators,voting="soft")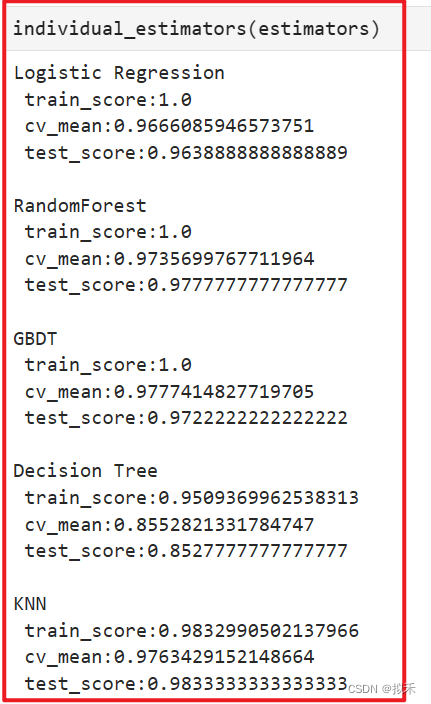
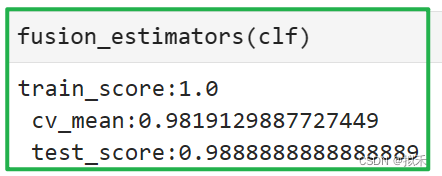
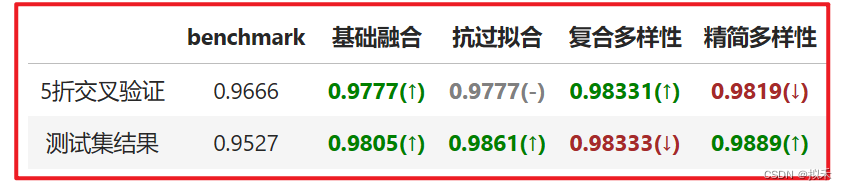
- 在增加算法多样性的过程中,我们尝试了多种算法组合。我们发现朴素贝叶斯对算法的伤害大于贡献,只要将朴素贝叶斯包括在融合算法内,算法的表现就持续停留在97%左右,无法继续上升。因此我们删除了朴素贝叶斯算法。
- 同时,包含随机多样性的算法组合在交叉验证与测试集结果上的表现高度一致,其中测试集结果略有降低、交叉验证结果提升了不少,这是一组可以使用的结果。但考虑到运算的效率,我们尽量不增加运算缓慢的集成算法,因此我们又将随机多样性删除,观察只包含5个算法的融合模型,最终交叉验证上的结果略有降低、测试集结果突破新高,这也是一组可以使用的结果。从模型的稳定性来考虑,还是包含随机多样性的组合更好,但为了更快的运算速率,我们可以使用精简多样性继续往下计算。
2、分类器加权🌷
- 对分类器加权是一个常见的操作,但如何选择权重却是整个模型融合过程中最令人头疼的问题——头疼主要在于,没有可以完全依赖的理论基础或数学公式去进行权重推导(或者说推导出来的权重基于过多假设、无法使用),同时费了很大精力求解出的权重可能对模型的效果完全没有影响。因此,在融合中加权是一个不经济的选项。但一般来说,我们还是会尝试几组权重来探索一下,模型是否还有提升的空间。
- 在机器学习算法中,只有一类算法对于评估器权重有自己的见解,那就是Boosting算法。在大部分Boosting集成过程中,我们会对每一个弱评估器求解其权重,并让权重作为迭代的一部分构建模型。那我们通常如何决定模型权重呢?在AdaBoost和XGBoost当中,我们都设立了用于衡量单个弱评估器置信度的某个指标,如果一个弱评估器的置信度越高,我们给与这个评估器的权重就越大。在Boosting算法中,置信度往往使用损失函数或损失函数的某种变体进行衡量,如果损失函数越大,则说明评估器的置信度越低,反之,则说明评估器的置信度越高。我们可以沿用这个思路,在模型融合中,我们会考虑的第一组权重,就是模型实际评估结果之间的比例。
- 如果模型评估指标是准确率这样的正向指标,则直接使用准确率作为权重。如果模型评估指标是MSE这样的负向指标,则使用1-指标或负指标作为权重。这样做的风险在于,模型可能陷入严重过拟合,但值得一试。
- 第一种选项:使用各个模型交叉验证结果本身作为权重,有过拟合风险
estimators = [("Logistic Regression",clf1), ("RandomForest", clf2)
, ("GBDT",clf3), ("Decision Tree", clf4), ("KNN",clf5)]
clf_weighted = VotingClassifier(estimators,voting="soft",weights=[0.96660,0.97357,0.97774,0.85528,0.97634])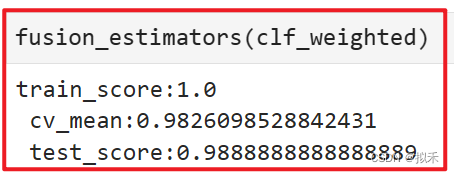
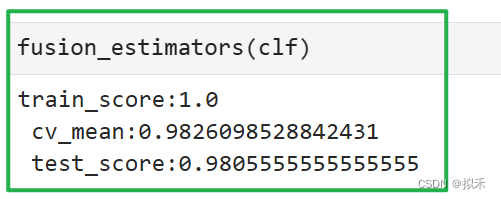
- 可以看到,模型在交叉验证上的效果提升了!模型没有陷入过拟合,这是一个很好的消息。
- 接下来,我们可以尝试使用更粗糙的权重来提升模型表现。一般来说,这个操作可以一定程度上缓解模型的过拟合。
- 第二种选项:稍微降低权重精度,或许可以一定程度上抵消过拟合
clf_weighted = VotingClassifier(estimators,voting="soft",weights=[0.95,0.95,0.95,0.85,0.98])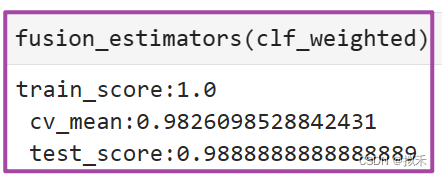
- 可以看到,模型的表现并无变化,这说明对当前数据来说,精确的权重与粗略的权重差异不大。
- 接下来,我们可以尝试调整模型中效果最好、或效果最差的算法的权重。一般,可以尝试加大效果好的算法的权重,减小效果差的算法的权重。
- 第三种选项:加大效果好的算法的权重,减小效果差的算法的权重。
clf_weighted = VotingClassifier(estimators,voting="soft",weights=[0.95,0.95,0.95,0.85,1.2]) #增大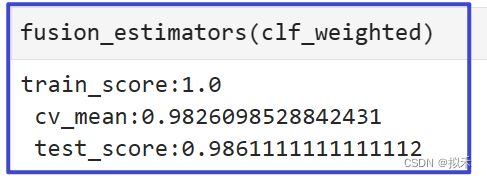
不难发现,过拟合开始发生了,测试集上的结果开始降低。因此我们选择不加大效果好的算法的权重
clf_weighted = VotingClassifier(estimators,voting="soft",weights=[0.95,0.95,0.95,0.3,0.98]) #减小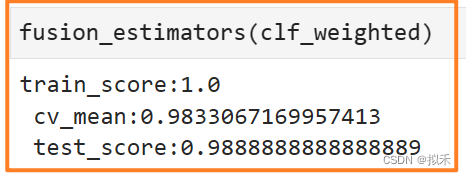
模型达到了目前为止,在5折交叉验证及测试分数上的最高值。现在我们给与决策树的权重非常小,说明现在决策树只是在提供多样性,在实际预测方面做出的贡献较少。提供多样性可以让模型的泛化能力增强,让实际预测方面的贡献变小又可以降低决策树本身较低的预测分数带来的影响。至此,我们就得到了一个很好的融合结果。

3、总结💝
- 模型融合是一个不断探索、不断对抗过拟合的过程。
- 有的时候经过复杂的调参后,融合模型的效果可能还不如调整之前的表现。
- 构建多样性,放大模型之间的独立性,是提高融合模型效果的不错选择。
- Voting投票法原理不难,但是在实际应用中追求模型的最优表现,是要有经验的、是得花功夫的。
- 对于Averaging平均法而言,与Voting投票法原理和应用很相似,sklearn中的sklearn.ensemble.VotingRegressor就是对未拟合估计器的预测投票回归,所以不再赘述。