leetcode 1813. 句子相似性 III【python3双指针的实现思路及过程整理】
题目
一个句子是由一些单词与它们之间的单个空格组成,且句子的开头和结尾没有多余空格。比方说,“Hello World”,“HELLO”,"hello world hello world"都是句子。每个单词都只包含大写和小写英文字母。
如果两个句子 sentence1和sentence2,可以通过往其中一个句子插入一个任意的句子(可以是空句子)而得到另一个句子,那么我们称这两个句子是相似的。比方说,sentence1 = "Hello my name is Jane"且sentence2 = “Hello Jane”,我们可以往sentence2中"Hello"和"Jane"之间插入"my name is"得到sentence1。给你两个句子sentence1和sentence2,如果sentence1和sentence2是相似的,请你返回true,否则返回false。
示例 1
- 输入:sentence1 = “My name is Haley”, sentence2 = “My Haley”
- 输出:true
- 解释:可以往 sentence2 中 “My” 和 “Haley” 之间插入 “name is” ,得到 sentence1 。
题解
题目倒是很好理解。刚开始是判断哪个串是子串,子串的word对另一个串进行划分,划分的非空个数超过1即为False,为1则为True。发现这么实现非常麻烦。后来对题目进行仔细分析,发现如果两个句子相似的话有如下三种情况。
1 一个sentence的单词分别按顺序出现在另一个sentence的头与尾
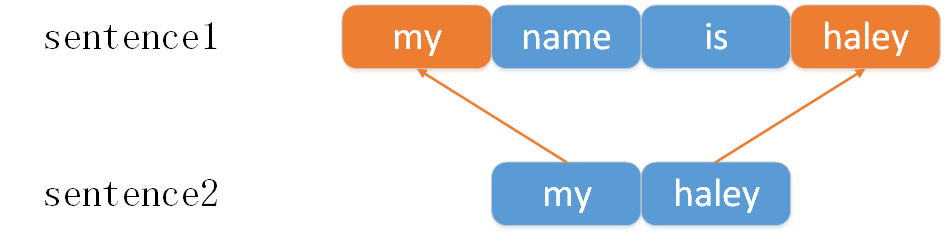
2 一个sentence的单词分别按顺序只出现在另一个sentence的头部
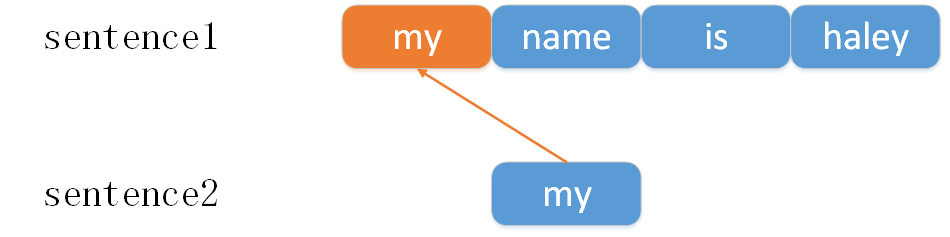
3 一个sentence的单词分别按顺序只出现在另一个sentence的尾部

因此,只需要匹配两个句子头部与尾部相似的word,如果匹配中的个数与其实一个小的sentence相同则认为相似,否则不相似。
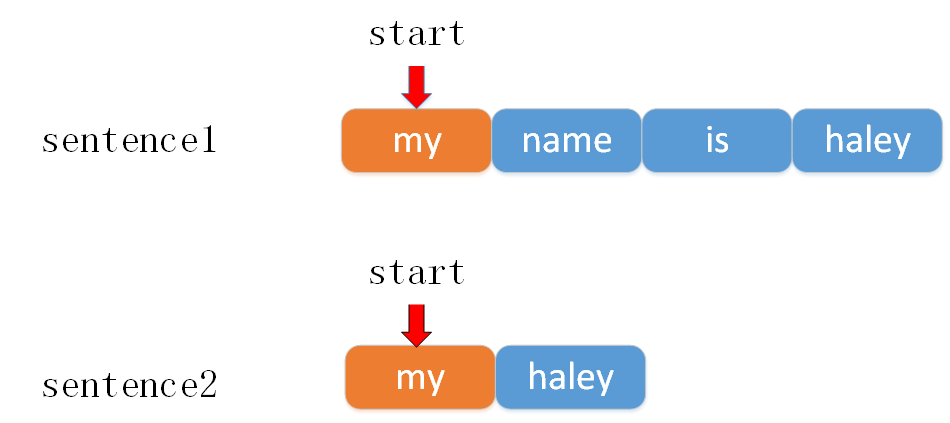
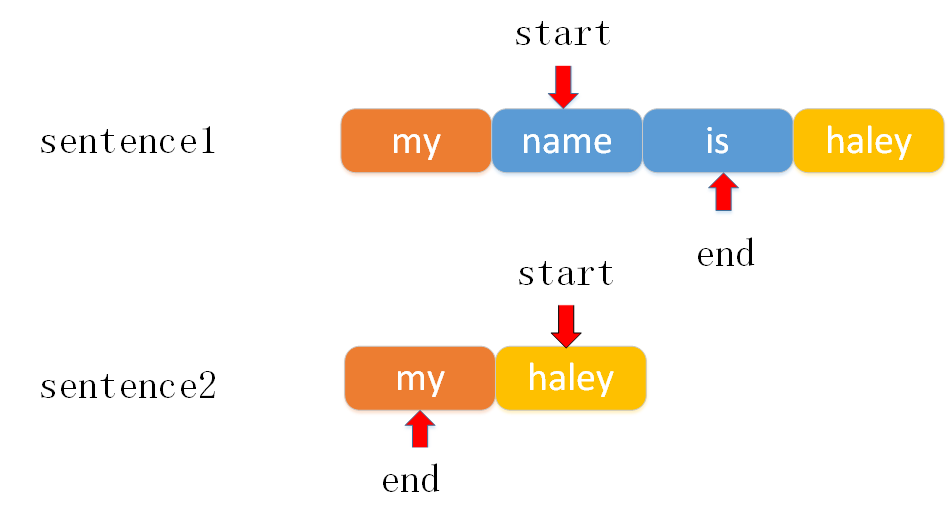
以示例1为例来说明执行过程。
初始如下图所示。

start索引用来判断两个句子前比缀相同的单词数。
当两个句子的start指针对应的word不相同时,开始从后到前遍历两个句子的end指针。
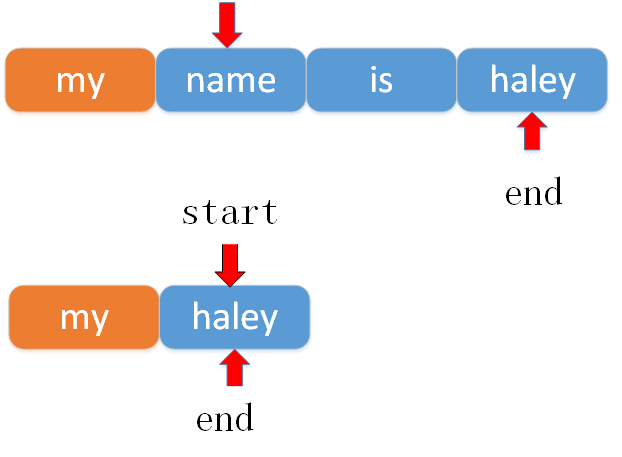
最后当end指针不移动时,比较一下前缀匹配的word数与后缀匹配的word数据之和是否与两个句子中的最不长度的word数相同。
代码
接下来可以直接写代码:
class Solution:
def areSentencesSimilar(self, sentence1: str, sentence2: str) -> bool:
sentence1_list=sentence1.split()
sentence2_list=sentence2.split()
start,end=0,0
while start<len(sentence1_list) and start<len(sentence2_list) and sentence1_list[start]==sentence2_list[start]:
start+=1
while end<len(sentence1_list)-start and end<len(sentence2_list)-start and sentence1_list[-end-1]==sentence2_list[-end-1]:
end+=1
return start+end==min(len(sentence1_list),len(sentence2_list))
计算复杂度
- 时间复杂度,m 是 sentence1的长度,n 是 sentence2的长度。字符串分割和双指针判断操作都需要遍历 O ( m + n ) O(m+n) O(m+n)个字符。
- 空间复杂度, 主要是分割句子需要 O ( m + n ) O(m+n) O(m+n)的空间,双指针的空间是 O ( 1 ) O(1) O(1),因此整体的空间复杂度为 O ( m + n ) O(m+n) O(m+n)。