Python学习笔记-网络爬虫基础
一、网络爬虫概述
- 网络爬虫概述
网络爬虫又称网络蜘蛛、网络机器人,在某社区中经常被称为网页追逐者。
网络爬虫可以按照指定规则自动浏览或抓取网络中的信息,python可以很轻松的编写爬虫程序或脚本。
网络爬虫基本工作流程:
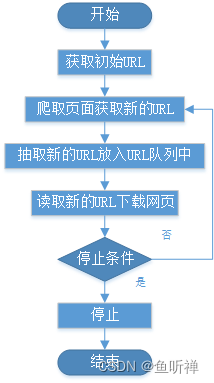
- 网络爬虫的常用技术
2.1 Python的网络请求
Python实现Http网络请求的三种常见方式:rullib、urllib3和requests模块。
2.1.1 urllib模块
urllib是python的自带模块,提供urlopen()方法,通过指定URL发送网络请求获取数据。
rullib模块的子模块
模块名称 | 描述 |
urllib.request | 定义打开url(主要为http)的方法和类,例如:身份验证,重定向,cookie等 |
urllib.error | 定义异常类,基本的异常为URLError |
urllib.parse | 分为两大类:URL解析和URL引用 |
urllib.robotparser | 用于解析robots.txt文件 |
通过urllib.request模块发送请求: