kaggle竞赛 | Instant Gratification
kaggle比赛链接:
https://www.kaggle.com/competitions/instant-gratification/data
目录
- 普通方案
- 优胜方案
- 1. 用方差筛选特征
- 2.QDA二次判别分析
- 3.数据分组(伪标签)
- 4.查看结果
- 赛题总结
普通方案
# 数据集路径
INPUT_PATH = '../input/'
import numpy as np
import pandas as pd
# 画图
import matplotlib.pyplot as plt
import seaborn as sns
# 警告不输出
import warnings
warnings.filterwarnings("ignore")
import time
import gc
# 进度条
from tqdm import tqdm
# 数据划分,评价指标
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import roc_auc_score
# 数据集path
train = pd.read_csv(INPUT_PATH + 'train.csv')
test = pd.read_csv(INPUT_PATH + 'test.csv') # 公开的测试集
train.shape, test.shape

train.head()
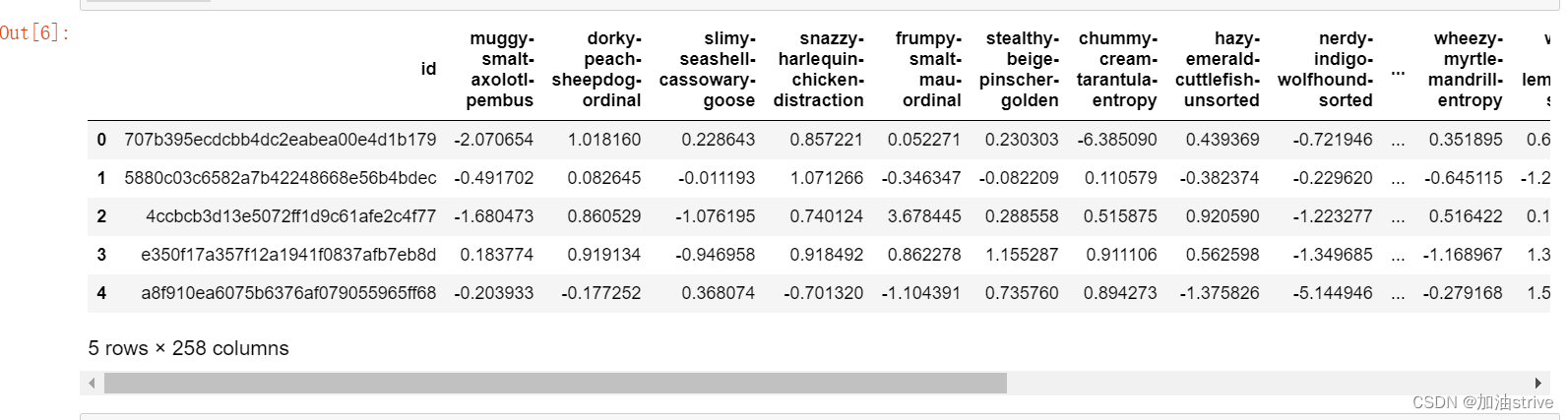
test.head()
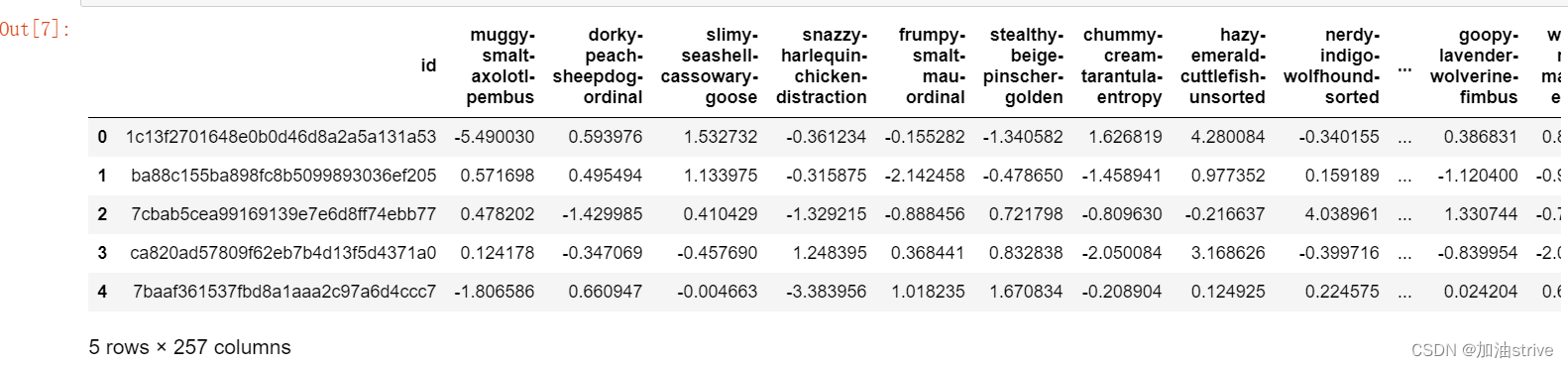
train.describe()
查看所有列名,以及对应的列名
(nunique()方法)返回不同值的个数
for col in train.columns[1:-1]:
print(col, train[col].nunique())
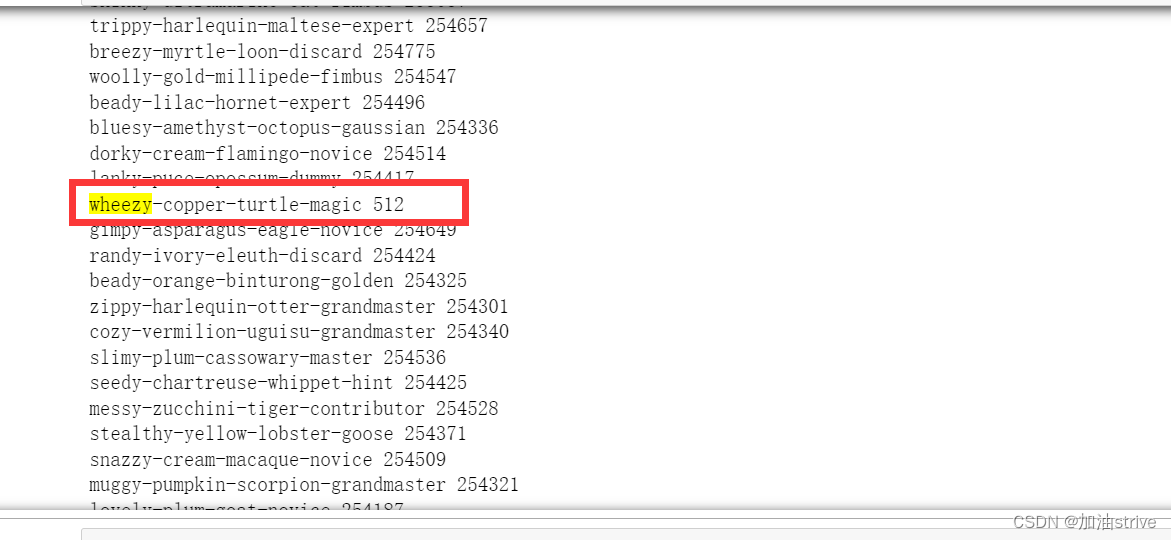
可以看到这一列的不同值的个数是512个
train['wheezy-copper-turtle-magic'].value_counts()

col = 'wheezy-copper-turtle-magic'
sns.displot(train[col])
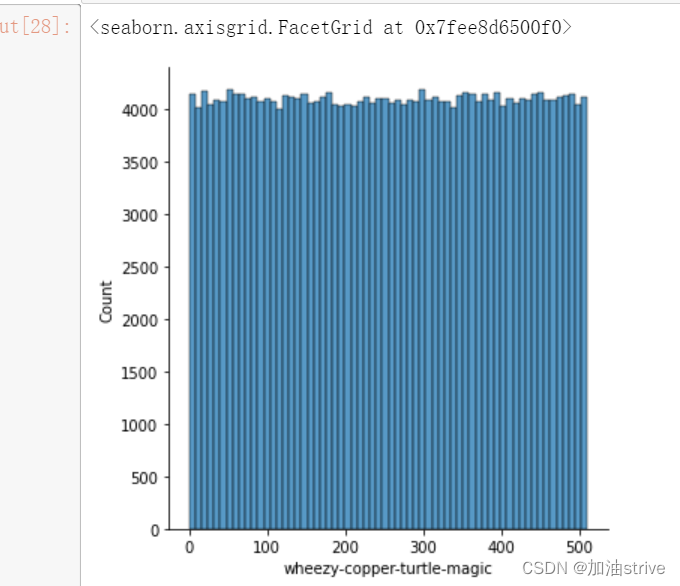
查看wheezy-copper-turtle-magic固定的情况下,其他字段的分布情况
col = 'dorky-peach-sheepdog-ordinal'
sns.displot(train[train['wheezy-copper-turtle-magic'] == 12][col])
sns.displot(train[train['wheezy-copper-turtle-magic'] == 10][col])
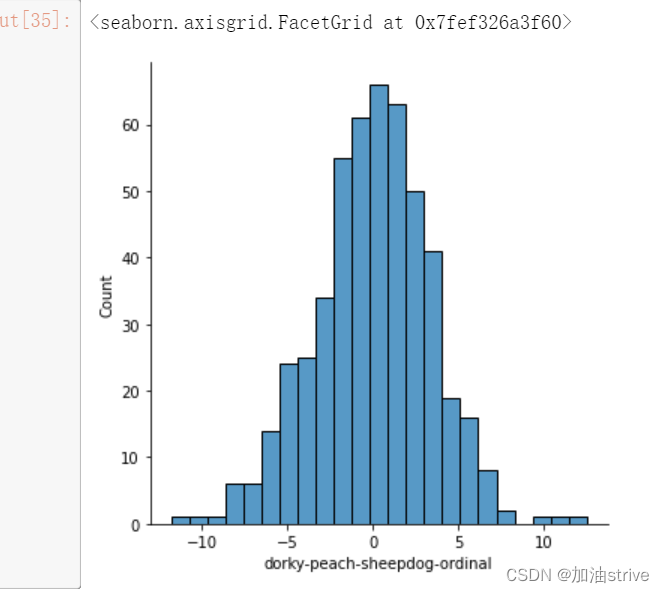
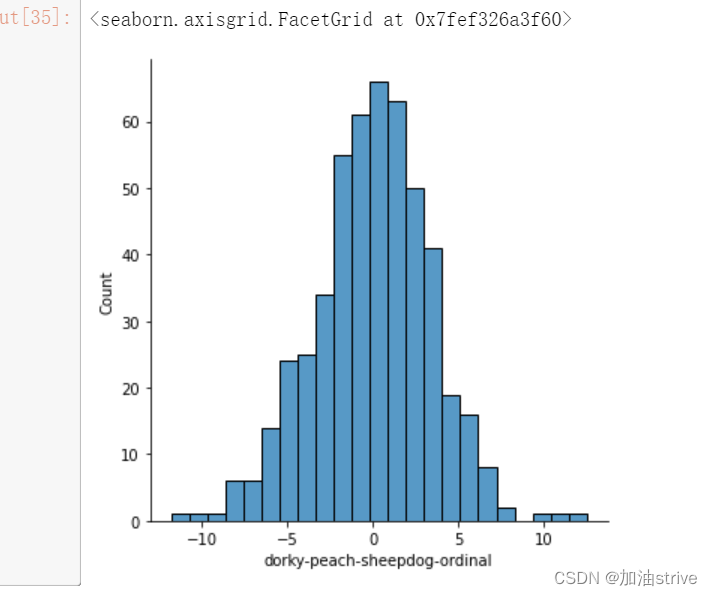
基本均满足正太分布,很规范的数据集
训练一个逻辑回归模型
feature_names = train.columns[1:-1]
target = train['target']
skf = StratifiedKFold(n_splits=10, shuffle=True)
train_oof = np.zeros(train.shape[0])
test_oof = np.zeros(test.shape[0])
from sklearn.linear_model import LogisticRegression
for trn_idx, val_idx in skf.split(train.values, target.values):
# print(target.iloc[val_idx].value_counts())
x_train, y_train = train.iloc[trn_idx][feature_names], target.iloc[trn_idx]
x_val, y_val = train.iloc[val_idx][feature_names], target.iloc[val_idx]
# 模型定义+训练
clf = LogisticRegression()
clf.fit(x_train, y_train)
# 验证集预测
val_pred = clf.predict_proba(x_val)[:, 1]
train_oof[val_idx] = val_pred
# 测试集预测
test_oof += clf.predict_proba(test[feature_names])[:, 1]
# 验证集的roc分数
print(roc_auc_score(y_val, val_pred))
test_oof /= 10

结果基本是瞎猜的准确率(0.5)
考虑到wheezy-copper-turtle-magic是一个很重要的特征,并且,基于wheezy-copper-turtle-magic分组之后,基于分组的其他特征又符合正态分布,尝试用分组后的训练集和验证集训练。
for trn_idx, val_idx in skf.split(train.values, target.values):
# 数据集交叉验证划分
x_train = train.iloc[trn_idx]
x_val, y_val = train.iloc[val_idx][feature_names], target.iloc[val_idx]
for i in tqdm(range(512)):
x_train2 = x_train[x_train['wheezy-copper-turtle-magic'] == i]
x_val2 = x_val[x_val['wheezy-copper-turtle-magic'] == i]
test2 = test[test['wheezy-copper-turtle-magic'] == i]
clf = LogisticRegression()
clf.fit(x_train2[feature_names], x_train2.target)
train_oof[x_val2.index] = clf.predict_proba(x_val2)[:, 1]
test_oof[test2.index] += clf.predict_proba(test2[feature_names])[:, 1]
# 验证集上的ROC分数
roc_auc_score(target[val_idx], train_oof[val_idx])
# 只训练一轮
# break

明显优于没有分组之前的方案
优胜方案
1. 用方差筛选特征
train1 = train[train['wheezy-copper-turtle-magic'] == 91]
df = train1.drop(['id', 'wheezy-copper-turtle-magic', 'target'], axis=1).std()
train1.drop(['id', 'wheezy-copper-turtle-magic', 'target'], axis=1).std().plot()
df.sort_values().plot(kind='bar')
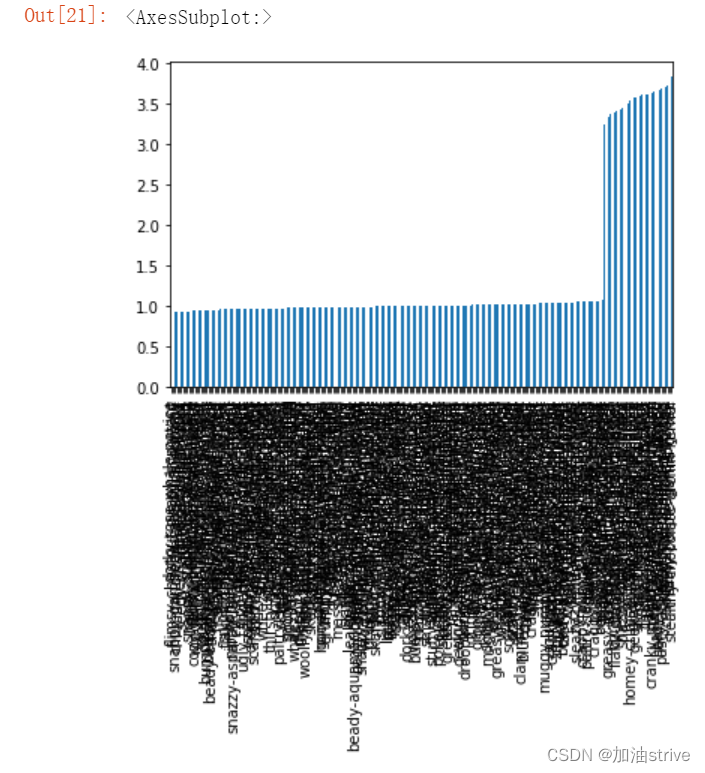
df.sort_values()

删除方差小于2的特征,其他的保留下来
from sklearn.feature_selection import VarianceThreshold
data2 = VarianceThreshold(threshold=2).fit_transform(train1.drop(['id', 'wheezy-copper-turtle-magic', 'target'], axis=1))
2.QDA二次判别分析
关于QDA
https://www.kaggle.com/c/instant-gratification/discussion/93843#latest-541113
从某种意义上说,KNN 太灵活而 LR 太简单,而 QDA 是最好的方法,因为它假设(正确?)决策边界是二次的。因此,我们得到了更好的偏差方差权衡,从而给出了更好的预测。
3.数据分组(伪标签)
train_oof = np.zeros(train.shape[0])
test_oof = np.zeros(test.shape[0])
from sklearn.model_selection import StratifiedKFold
col = [c for c in train.columns if c not in ['id', 'wheezy-copper-turtle-magic', 'target']]
# 先划分训练和验证集 -》按照turtle-magic取值进行划分
# 按照turtle-magic取值进行划分 -》先划分训练和验证集
from tqdm import tqdm
for i in tqdm(range(512)):
# 伪标签
train2 = train[train['wheezy-copper-turtle-magic'] == i]
test2 = test[test['wheezy-copper-turtle-magic'] == i]
from sklearn.feature_selection import VarianceThreshold
train3 = VarianceThreshold(threshold=0.1).fit_transform(train2[col])
test3 = VarianceThreshold(threshold=0.1).fit_transform(test2[col])
skf = StratifiedKFold(n_splits=5)
for tr_idx, val_idx in skf.split(train2, train2.target):
# 二次判别分析
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
clf = QuadraticDiscriminantAnalysis()
# train3是筛选后的数据集,train3中没有target
# train2中包含原来的标签
clf.fit(train3[tr_idx], train2.target.iloc[tr_idx])
#
train_oof[train2.iloc[val_idx].index] = clf.predict_proba(train3[val_idx])[:, 1]
test_oof[test2.index] = clf.predict_proba(test3)[:, 1] / 5
4.查看结果
from sklearn.metrics import roc_auc_score
auc = roc_auc_score(train['target'], train_oof)
print(f'AUC: {auc:.5}')

赛题总结
