总结 62 种在深度学习中的数据增强方式
数据增强
数据增强通常是依赖从现有数据生成新的数据样本来人为地增加数据量的过程
这包括对数据进行不同方向的扰动处理
或使用深度学习模型在原始数据的潜在空间(latent space)中生成新数据点从而人为的扩充新的数据集
这里我们需要区分两个概念,即增强数据和合成数据
》合成数据
指在不使用真实世界图像的情况下人工生成数据
合成数据可由 GAN 或者现如今大火的 AGI 技术 Diffusion Model 生成
》增强数据
从原始图像派生而来,并进行某种较小的几何变换(例如翻转、平移、旋转或添加噪声等)
或者色彩变换(例如亮度、对比度、饱和度或通道混洗等),以此来增加训练集的多样性
数据增强的作用
在实际的应用场景中,数据集的采集、清洗和标注在大多数情况下都是一个非常昂贵且费时费力且乏味的事情
有了数据增强技术,一方面可以减轻相关人员的工作量,另一方面也可以帮助公司削减运营开支
此外,有些数据由于涉及到各种隐私问题可能用钱都买不到,又或者一些异常场景的数据几乎是极小概率时间
这时候数据增强的优势便充分的体现出来了
还有就是模型性能的提升
卷积神经网络对平移、视点、大小或光照均具有不变性
也正因此,CNN 能够准确地对不同方向的物体进行分类
在深度学习中,CNN 通过对输入图像进行卷积运算来学习图像中的不同特征,从而在计算机视觉任务上表现非常出色
随着 ViT 的提出,一系列 Vision Transformer 模型被提出并被广泛地应用
然而,无论是 CNN 还是 Transformer,均离不开数据的支持
特别是,当数据量较小时 CNN 容易过拟合,Transformer 则无法学习到良好的表征
数据增强的方式
数据增强方式大致分为两类:基础数据增强和高级数据增强
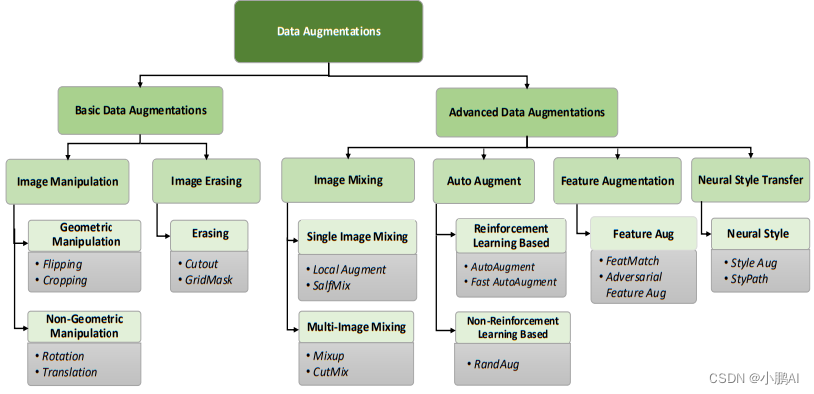
>>基础数据增强方法<<
图像处理(Image Manipulation)
图像处理(Image Manipulation)是指在图像中对其位置或颜色所做的更改
- 位置操作是通过调整像素的位置来进行的
- 颜色操作是通过改变图像的像素值来进行的

1. 几何数据增强(Geometric Data Augmentation)
它是指对图像几何形状所做的更改
几何指的是位置,比如以一定角度移动等
这种技术改变了图像中像素值的位置,例如旋转、平移和剪切
(1)旋转(Rotation)
其让图像在 0 到 360 度之间旋转
此处旋转度数是一个超参数,应该根据实际需要选择
举个例子,就像大家最熟悉的 MNIST 一样,我们不能旋转 180 度,不然数字 6 旋转 180 就变成 9,这就离谱了
(2)平移(Translation)
它是另一种几何类型的数据增强,通过向上、向下、向右或向左移动图像以提供不同的视图
(3)错切(Shearing)
错切,其字面意思是沿轴扭曲图像
错切是一种数据增强技术,可以将图像的一部分向一个方向移动,而另一部分则向相反方向移动
从技术上讲,它分为两类,即沿x轴切和y轴切
对于 x 轴,图像的顶部沿一个方向移动,底部沿完全相反的方向移动
而在 y 轴中,图像的左侧部分沿一个方向移动,右侧部分沿相反方向移动
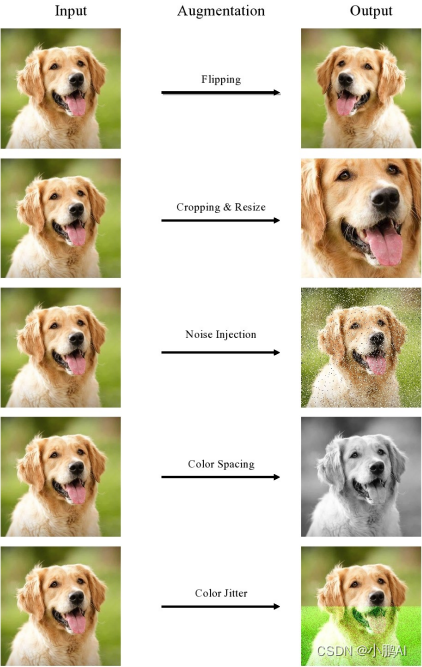
2. 非几何数据增强(Non-Geometric Data Augmentations)
这种增强方式侧重于图像的视觉外观而不是其几何形状
例如噪声注入、翻转、裁剪、调整大小和色彩空间操作是均是非几何增强技术的范畴
(4)翻转(Flipping)
翻转,它是一种水平或垂直翻转图像的数据增强技术,几乎会应用在许多视觉任务上
一般来说,我们常用的是水平翻转,垂直翻转在大多数情况下会导致目标歧义
例如一个人翻转过来就很不协调和自然,当然还是那句话,根据你的实际应用场景调整
(5)裁剪(Cropping and resizing)
裁剪,属于另一种数据增强技术,常用作预处理增强
使用随机裁剪或中心裁剪作为数据增强
该技术会减小图像的大小,然后执行调整大小以匹配图像的原始大小,同时不会平滑图像的标签
(6)注入噪声(Noise Injection)
注入噪声是另一种数据增强技术,它有助于神经网络学习稳健的特征,对抵御对抗性攻击非常有帮助
(7) 光度增强(Color Space)
一般来说,图像通常是由 RGB 三颜色通道组成的
这里如果我们单独操纵每个通道值以控制亮度也是一种数据增强方式,有时也称为光度增强
这种增强有助于避免模型偏向 lightning 条件
执行颜色空间增强的最简单方法是隔离任何通道并添加 2 个填充任何随机值或 0 或 255 的通道
颜色空间常用于照片编辑应用程序,即用于控制亮度或暗度
(8) 扰动(Jitter)
扰动,是一种通过随机改变图像的亮度、对比度、饱和度和色调的数据增强方式
对于这四个是超参数,我们应仔细选择它们的取值范围
如果我们不小心多度提高了肺部疾病检测的X光图像亮度
会使肺部在X光中变白混杂,对疾病诊断实际是没有帮助的
(9)核过滤(Kernel Filters)
这是一种用来锐化或模糊图像的数据增强方式
我们可以滑动大小为 n x n 的窗口 Kernel 或高斯模糊过滤器和边缘过滤器的矩阵
高斯模糊滤镜可以使图像变得更加模糊,而边缘滤镜则使图像的水平或垂直边缘锐化
3. 图像擦除的数据增强方式(Image Erasing Data Augmentations)
(10)Cutout
Cutout 是通过在训练期间随机擦除子区域并在图像中填充 0 或 255 的一种数据增强技术
(11)Random erasing

Random erasing 是一种像剪切一样随机擦除图像中子区域的一种增强方式
但它也随机决定是否屏蔽,并决定屏蔽区域的纵横比和大小
我们可以在人脸识别任务中,通过这项数据增强技术来模拟戴口罩的效果
(12)Hide-and-Seek
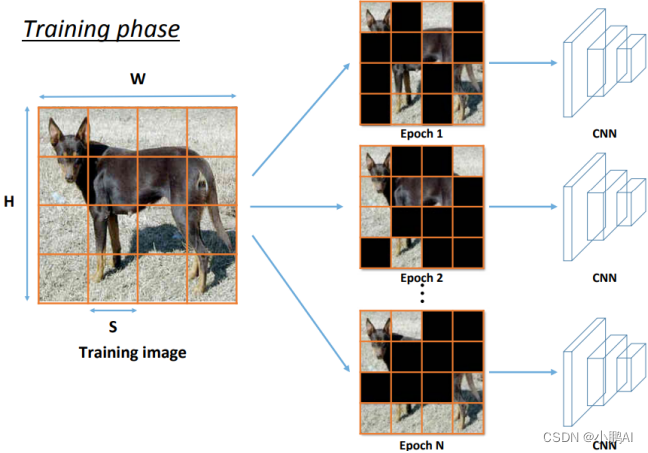
捉迷藏(Hide-and-Seek)数据增强的关键思想是将图像划分为随机大小的均匀正方形,并随机删除随机数量的正方形
当重要信息被隐藏时,它迫使神经网络学习相关特征
在每个epoch,它都会给出图像的不同视图
(13)GridMask
基于网格掩码的数据增强方式
先前的方法尝试解决随机删除可能会存在完全擦除对象或删除上下文信息区域的问题
为了在这些问题之间进行权衡,GridMask 创建统一的掩码,然后将其应用于图像,如下图所示

此图显示了 GridMask 增强的过程,具体的做法是生成一个掩码,然后将其与输入图像相乘
Image Mixing Data Augmentations
图像混合数据增强在过去几年一直是一个热门话题
图像混合数据增强是关于将图像与其他图像或相同图像混合
在本文中,我们将其大致分为两类
即单图像混合(Single image mixing)增强和非单图像混合(Non-single image mixing)增强
4. 单图像混合(Single image mixing)增强
单一图像混合技术顾名思义便是仅使用一个图像,并从不同的视角对其进行处理
最近在单图增强方面做了很多工作,比如LocalAugment、SelfAugmentation、SalfMix等
(14) Local Augment
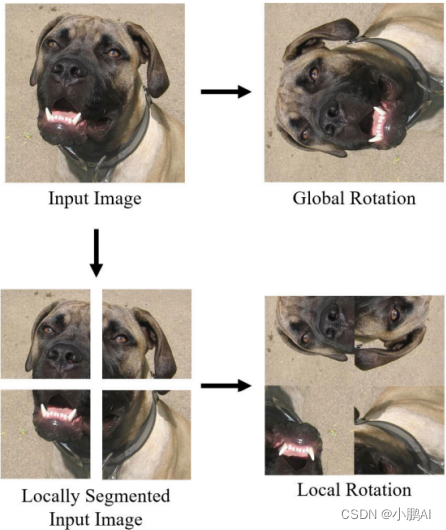
Local Augment,即局部增强的原理是将图像切分成小块,并在每个小块上应用不同类型的数据增强
目的是潜在地改变目标偏差属性,但产生显着的局部特征
虽然这种增强并不主宰全局结构,但提供了非常多样化的图像特征,这对于神经网络以更通用的方式学习局部特征至关重要
(15)Self Augmentation
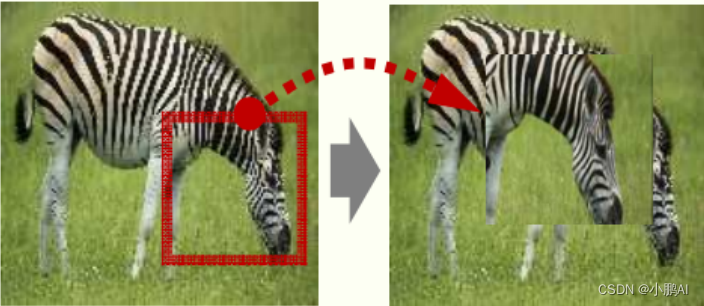
在 Self Augmentation 中,图像的随机区域会被裁剪并随机粘贴到图像中,以提高小样本学习的泛化能力
(16)SalfMix
SalfMix 提出的背景主要是关注是否可以泛化基于单图像混合增强的神经网络
其思想是找到图像的第一个显示部分来决定应该删除哪个部分以及应该复制哪个部分
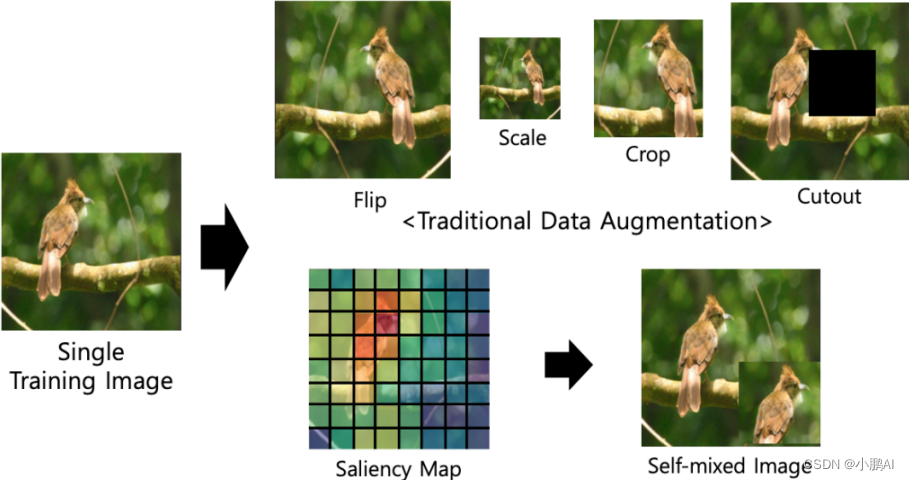
如上图所示,SalfMix 是通过显着性图将图像中显著的区域裁剪出来并放入非显着区域
(17) KeepAugment

引入 KeepAugment 是为了防止分布偏移降低神经网络的性能
KeepAugment 的想法是通过保留图像的显着特征和增强非显着区域来提高保真度
其中,被保留的特征进一步允许在不改变分布的情况下增加多样性
(18)YOCO

YOCO,即You Only Cut Once,它可以从部分信息中识别对象并提高增强的多样性,从而鼓励神经网络表现得更好
YOCO 制作了两张图像,每张都应用了一个增强,然后将每张图像连接成一张图像
YOCO 易于实现,且不会引入任何参数,同时也易于使用
(19)Cut-Thumbnail

Cut-Thumbnail,即缩略图,是一种新颖的数据增强
它将图像调整到一定的小尺寸,然后用调整后的图像随机替换图像的随机区域,旨在减轻网络的形状偏差
Cutthumbnail 的优点是它不仅保留了原始图像,而且在调整后的小图像中保持全局
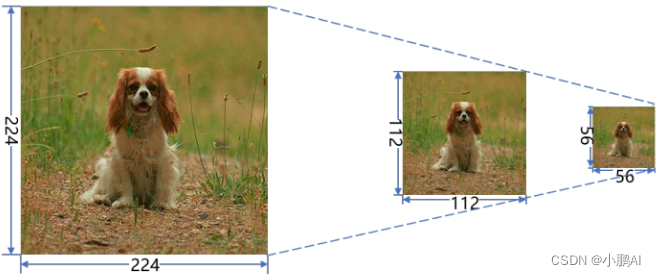
此图像显示了缩略图的缩小图像示例
其方式是将图像缩小到一定尺寸 112×112 或 56×56 后
尽管丢失了很多局部细节,但图像中的目标(狗)仍然可以识别
5. 非单图像的混合数据增强(Non-Single Image Mixing Data Augmentations)
非单图像的混合数据增强涉及的内容比较丰富
(20)Mixup
Mixup 是根据混合因子(alpha)来混合任意两个随机图像,这些图像的相应标签也以相同的方式混合
混合数据增强不仅在准确性方面而且在鲁棒性方面都可持续地提高了性能
(21)CutMix
CutMix 解决了信息丢失和区域丢失问题
它的灵感来自 Cutout,其中任何随机区域都用 0 或 255 填充
而在 cutmix 中,不是用 0 或 255 填充随机区域,而是用另一个图像的补丁填充该区域
相应地,它们的标签也根据混合的像素数按比例混合
(22)SaliencyMix

SaliencyMix 基本上解决了 Cutmix 的问题,并认为用另一个补丁填充图像的随机区域并不能保证补丁具有丰富的信息
因此混合未保证补丁的标签会导致模型学习关于图像的不必要信息 修补
为了解决这个问题,SaliencyMix 首先选择图像的显着部分并将其粘贴到随机区域或另一幅图像的显着或非显着区域
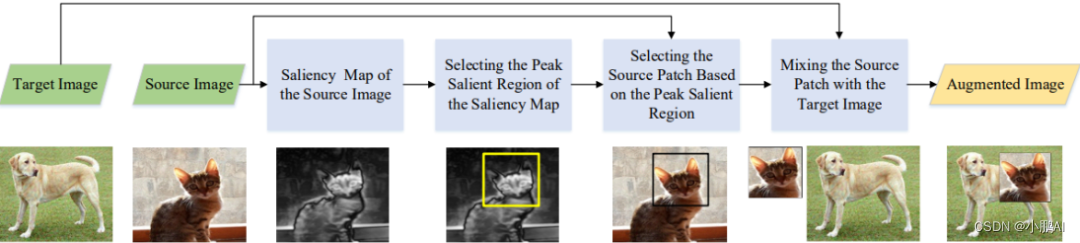
上面这张图展示了该方法的实现过程
(23)Puzzle Mix
Puzzle Mix 提出了一种拼图混合数据增强技术,该技术侧重于灵活地使用图像的显着信息和基本统计数据
目的是打破神经网络对现有数据增强的误导监督

uzzle Mix 确保包含足够的目标类信息,同时保留每个样本的局部统计信息
(24)SnapMix
SnapMix 是一种基于语义比例的混合数据增强,它利用类激活图来降低标签噪声水平
SnapMix 根据实际参与增强图像的显着像素创建目标标签,确保增强图像和混合标签之间的语义对应
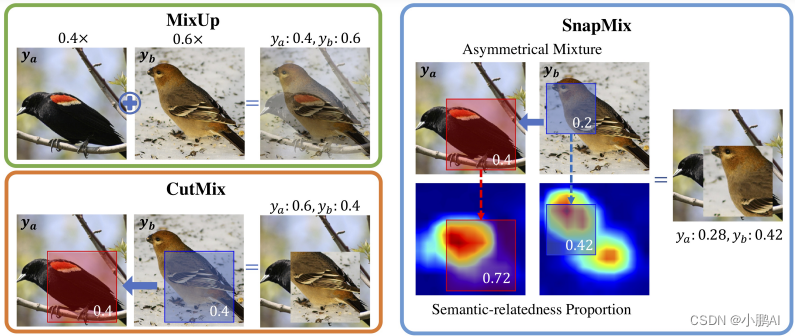
该图给出了一个基本示例,可以看出
与 CutMix 和 Mixup 相比,SnapMix 生成的标签在视觉上更符合混合图像的语义结构
(25)FMix
FMix 也是一种混合样本数据增强(MSDA),利用随机二分类掩码
这些随机二分类掩码是通过对从傅立叶空间获得的低频图像应用阈值来获取的
一旦获得掩码,一个颜色区域将应用于其中一个输入,另一个颜色区域将应用于另一个输入
整体流程如下图所示

(26)MixMo
MixMo 侧重于通过子网络学习多输入多输出。该方法的主要动机是采用更可靠的机制代替直接的隐藏求和操作
MixMo 的具体做法是将 M 个输入嵌入到共享空间中,将它们混合并将它们传递到更深的层进行分类
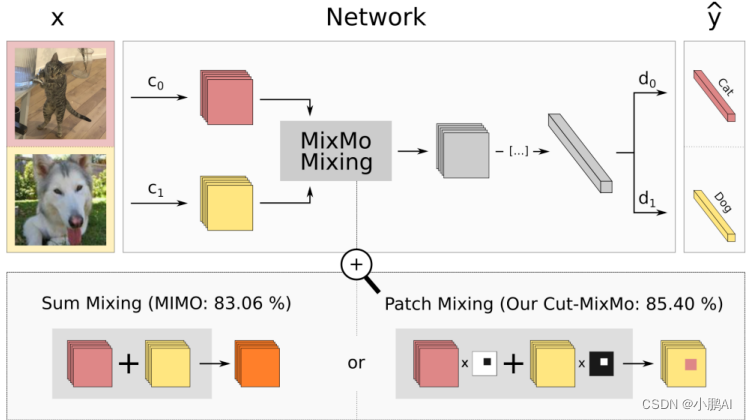
(27)StyleMix
StyleMix 针对以前的方法问题,即不区分内容和样式特征
为了解决这个问题提出了两种方法 styleMix 和 StyleCutMix
这是第一个非常详细地分别处理图像的内容和样式特征的工作,并且它在流行的基准数据集上显示出令人印象深刻的性能

(28)RandomMix
RandomMix 可用于提高模型的泛化能力
它从一组增强中随机选择混合增强并将其应用于图像,使模型能够查看不同的样本。整体演示如下图所示
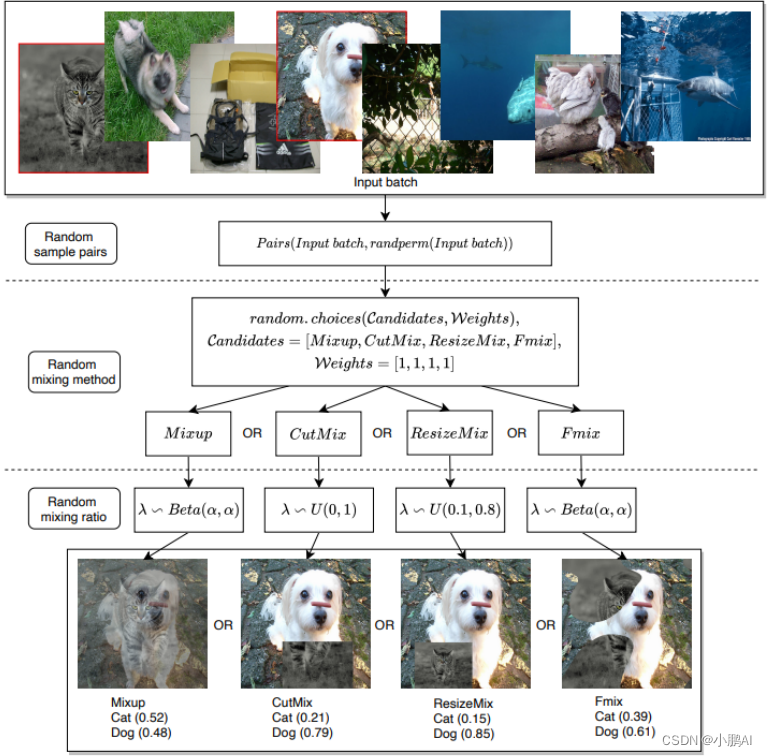
(29)MixMatch
MixMatch 是一种应用于半监督学习的数据增强技术
其将单个图像增加 K 次并将所有 K 个图像传递给分类器,对它们的预测进行平均
最后,通过调整它们的分布温度项来增强它们的预测

(30)ReMixMatch
ReMixMatch 是混合匹配的扩展,通过引入分布对齐和增强锚定使先前的工作变得高效
分布对齐任务是使未标记数据的预测边缘分布接近 ground truth 的边缘分布
并鼓励未标记数据的预测边缘分布接近 ground truth 标签的边缘分布
增强锚定将输入的多个强增强版本提供给模型,并鼓励每个输出接近同一输入的弱增强版本的预测
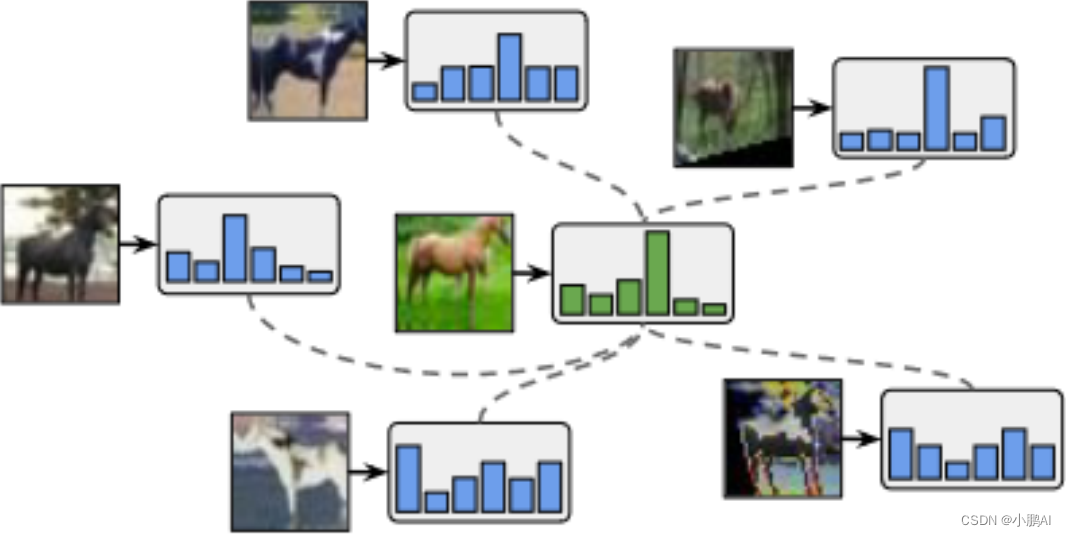
ReMixMatch 使用弱增强图像(中间绿色部分)的预测来预测同一图像(图中蓝色部分)的强增强
(31)FixMatch
FixMatch 通过在有限的标记数据上进行训练,然后使用经过训练的模型将标签分配给未标记数据
Fixmatch 首先将伪标签分配给概率高于某个阈值的未标记图像
该模型被迫对未标记图像的强增强版本进行预测,以使用交叉熵损失将其预测与伪标签相匹配
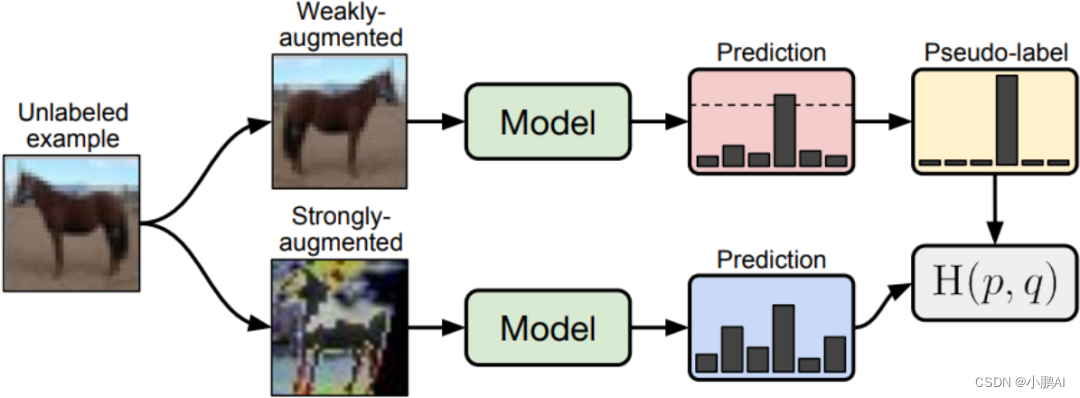
(32)AugMix
AugMix 是一种简单有效的数据增强,可减少训练和测试(未见)数据分布之间的差距
AugMix 操作以相应的随机增强幅度执行
最后,所有这些图像被合并以生成一个新图像,该图像广泛探索图像周围语义等效的输入空间
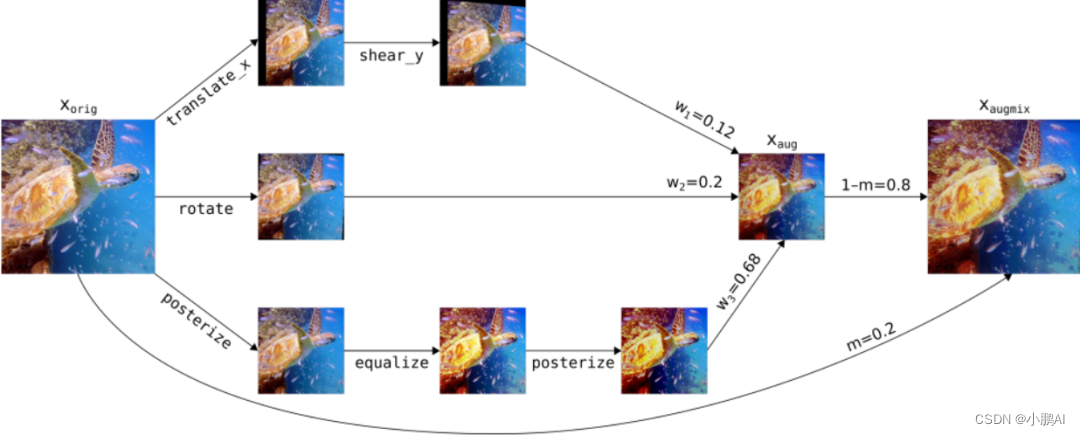
如上图所示,在三个分支中分别进行了三个操作,最后,将所有图像混合生成新图像,这有利于提升模型的鲁棒性
(33)Copy-Paste
Copy-Paste 只是将一个图像的掩码实例复制并粘贴到另一个图像
其实现起来非常简单,但效果出众,特别是对于小目标检测来说
当然,我们也可以采用 BBox 级的实例来实现

上图展示了两个图像的实例以不同的比例相互粘贴
(34)Mixed-Example

混合样本数据增强算法的核心思想是
按一定的比例随机混合两个训练样本及其标签
这种混合方式不仅能够增加样本的多样性,并且能够使不同类别的决策边界过渡更加平滑
减少了一些难例样本的误识别,模型的鲁棒性得到提升,训练时也比较稳定
(35)RICAP
RICAP,即随机图像裁剪和修补,是一种新的数据增强技术
它切割和混合四张图像而不是两张图像,并且图像的标签也被混合
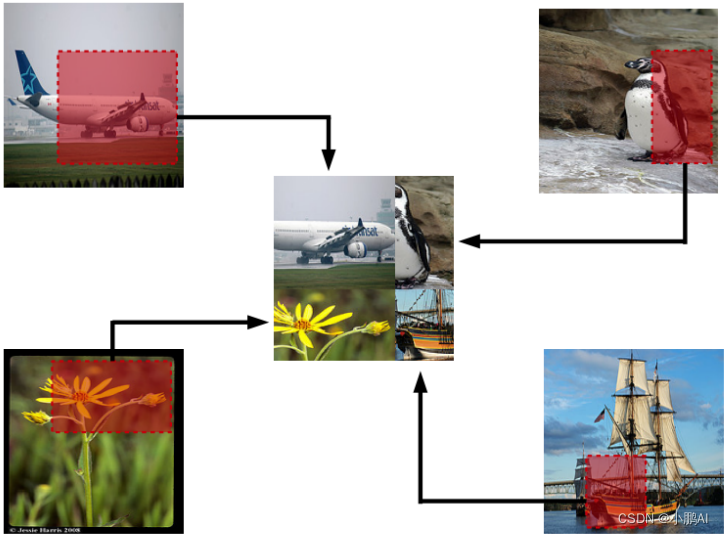
(36)CutBlur
CutBlur 探索和分析了现有的超分辨率数据增强技术
并提出了另一种新的数据增强技术,通过切割高分辨率图像块并粘贴到相应的低分辨率图像,反之亦然
Cutblur 在超分辨率方面表现出色

下面是它的实现原理示意图
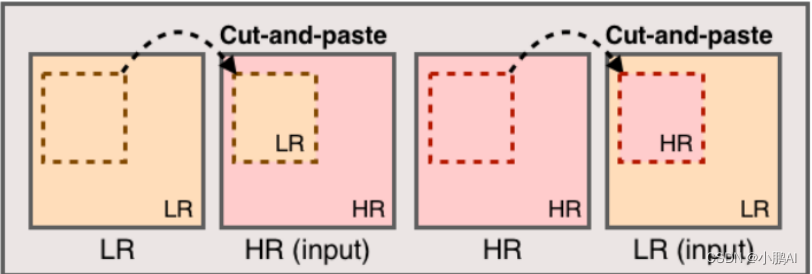
(37)ResizeMix
ResizeMix 是一种将数据与保留的对象信息和真实标签混合的数据增强方法
其通过直接以四种不同的方式剪切和粘贴源数据以针对图像
这里,四种不同的方式,包括显着部分、非部分、随机部分或调整源图像大小来修补,它主要解决了两个问题
- 如何从源图像中获取补丁
- 将源图像的补丁粘贴到目标图像的什么位置
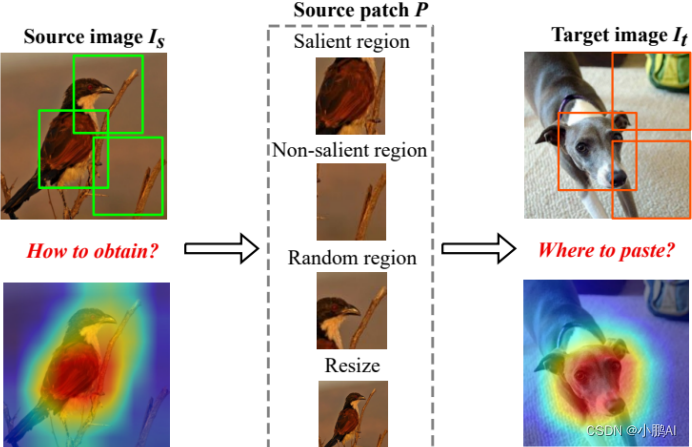
此外,ResizeMix 发现显着性信息对于促进混合数据扩充并不重要
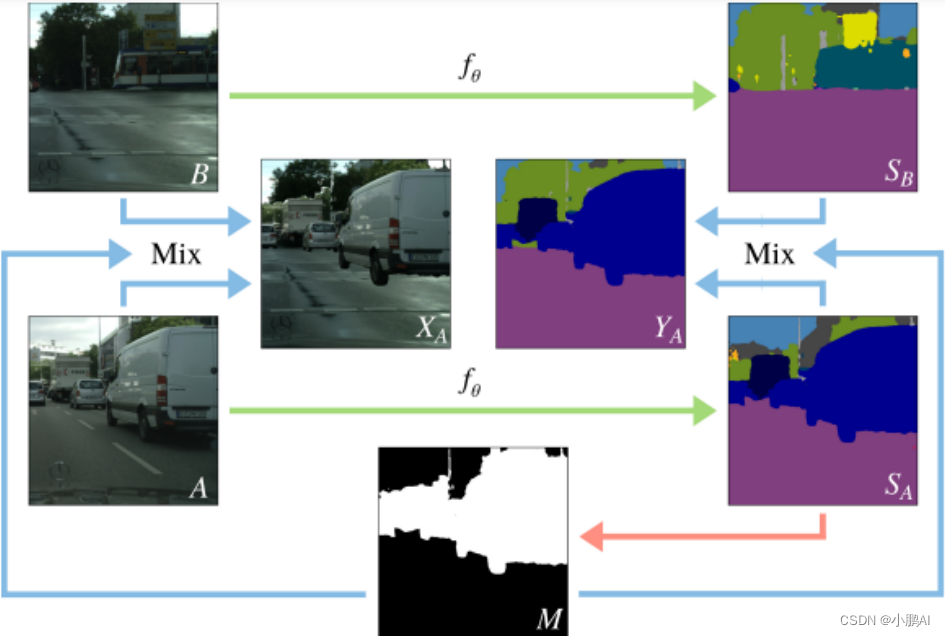
(38)ClassMix
ClassMix 是一种用于半监督学习的基于分割的数据增强方法
传统的数据增强对语义分割并不像图像分类那样有效
ClassMix 通过在考虑对象边界的同时利用网络预测,通过混合未标记样本来扩充训练样本
(39) CDA
CDA,即 Context Decoupling Augmentation,是一种用于弱监督语义分割的上下文解耦增强技术
解决 WSSS 领域传统数据技术性能不佳的问题
这些通过增加相同上下文数据语义样本不会在对象区分中贡献太多价值
对于图像分类任务来说,目标识别是由于目标本身及其周围环境
这不鼓励模型只关注当前目标,而要结合上下文
为了打破这一点,CAD 使特定对象出现的位置多样化
并引导网络打破对象和上下文信息之间的依赖关系
在这种情况下,它还提供增强和网络焦点到对象实例而不是对象实例和上下文信息的方式

(40)ObjectAug
ObjectAug 是一种用于语义分割的对象级增强,解决了混合图像级数据增强策略的问题
以前的策略无法用于分割,因为对象和背景是耦合的
其次对象的边界由于它们与背景的固定语义联系而没有被增强
为了缓解这个问题,首先,它借助语义标签将对象和背景从图像中分离出来
然后使用翻转和旋转等流行的数据增强技术对每个对象进行增强
由于这些数据增强而导致的像素变化可以使用图像修复来恢复
最后,对象和背景耦合以创建增强图像,从而有效的提升分割的性能

>>高级数据增强方法<<
高级数据增强的一个典型代表便是自动数据增强
其目标是从训练数据中找到数据增强策略
它将寻找最佳增强策略的问题转化为离散搜索问题
由搜索算法和搜索空间组成,主要包含四部分
- 基于强化学习的数据增强(Reinforcement learning data augmentation)
- 基于非强化学习的数据增强(Non-Reinforcement learning data augmentation)
- 基于风格迁移的数据增强(Neural Style Transfer)
- 基于特征空间的数据增强(Feature space data augmentations)
基于强化学习的数据增强(Reinforcement learning data augmentation)
(41)AutoAugment
AutoAugment 的目标是通过自动搜索策略找到最好的数据扩充而不是通过手动进行数据扩充
为了解决这个限制,其设计了搜索空间并具有由许多子策略组成的策略
每个子策略都有两个参数,一个是图像处理函数,第二个是概率和大小
这些子策略是使用强化学习作为搜索算法找到的,整体流程如下所示:

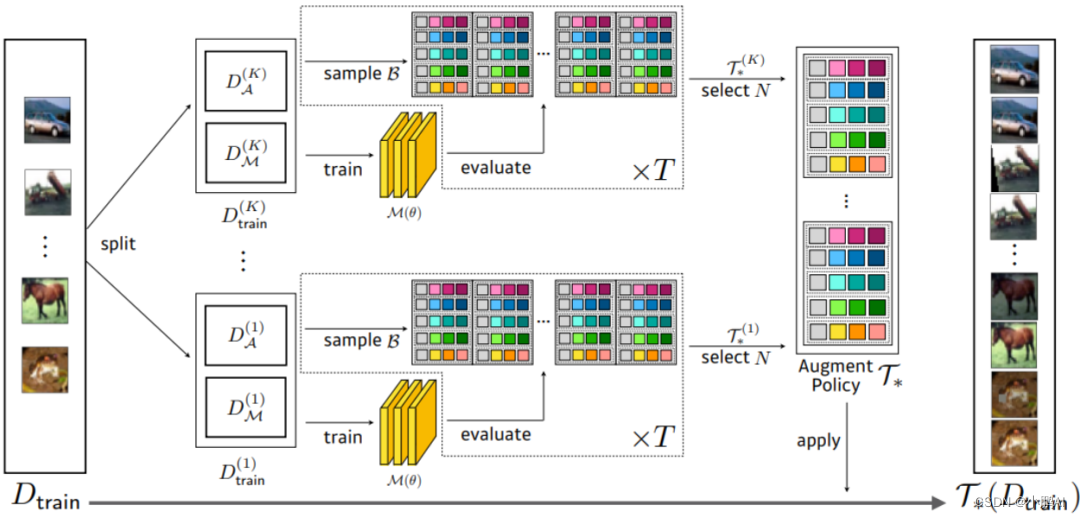
(42)Fast Autoaugment
Fast Autoaugment 解决了 AutoAugment 需要花费大量时间才能找到最佳的数据增强策略的问题
该方法的解决方案是通过利用基于密度匹配的高效搜索策略找到更优的数据扩充,从而减少了高阶训练时间
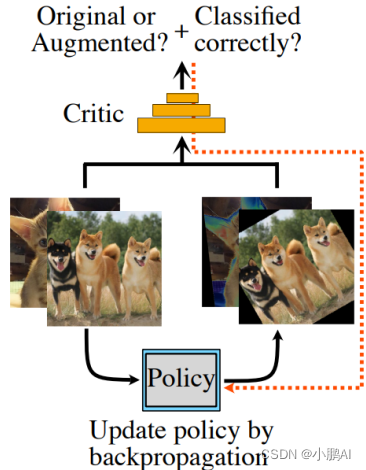
(43)Faster AutoAugment
Faster AutoAugment 旨在非常高效地找到有效的数据增强策略,其基于可区分的增强搜索策略
此外,它不仅为许多具有离散参数的转换操作估计梯度,而且还提供了一种有效选择操作的机制
最终,它引入了一个训练目标函数,旨在最小化原始分布和增广分布之间的距离,该函数也是可微的
需要注意的是,其增强的参数是在反向传播期间更新的,整体流程图定义如下
(44)RAD
RAD,即增强数据强化学习,其易于插入有效提升了强化学习算法的性能。
RAD 主要考虑两个问题:1. 学习数据效率; 2. 新环境的泛化能力
此外,它表明传统的数据增强技术使 RL 算法能够在基于像素的控制和基于状态的控制方面胜过复杂的 SOTA 任务
下面是它的总体流程图:

(45)MARL
MARL,即多代理强化学习,是一种基于多代理协作的局部补丁自动增强方法
这是第一个使用强化学习找到补丁级别数据增强策略的方法
MARL 首先将图像分成小块,然后共同为每个小块找到最佳数据增强策略

(46)LDAS
LDAS 建议使用自动增强来学习目标检测的最佳策略
它解决了目标检测增强的两个关键问题
- 分类学习策略不能直接应用于检测任务,如果应用几何增强,它会增加处理边界框的复杂性;
- 与设计新的网络架构相比,数据增强增加的价值要少得多,因此受到的关注较少,但应谨慎选择用于目标检测的增强
下图展示了基于此数据扩充的一些子策略

(47)Scale-Aware Automatic Augmentation
Scale-Aware Automatic Augmentation,是一种用于目标检测的数据增强策略
首先,它定义了一个搜索空间,其中图像级和框级数据增强为尺度不变性做好了准备
其次,这项工作还提出了一种新的搜索度量,名为有效且高效地搜索增强的帕累托比例平衡
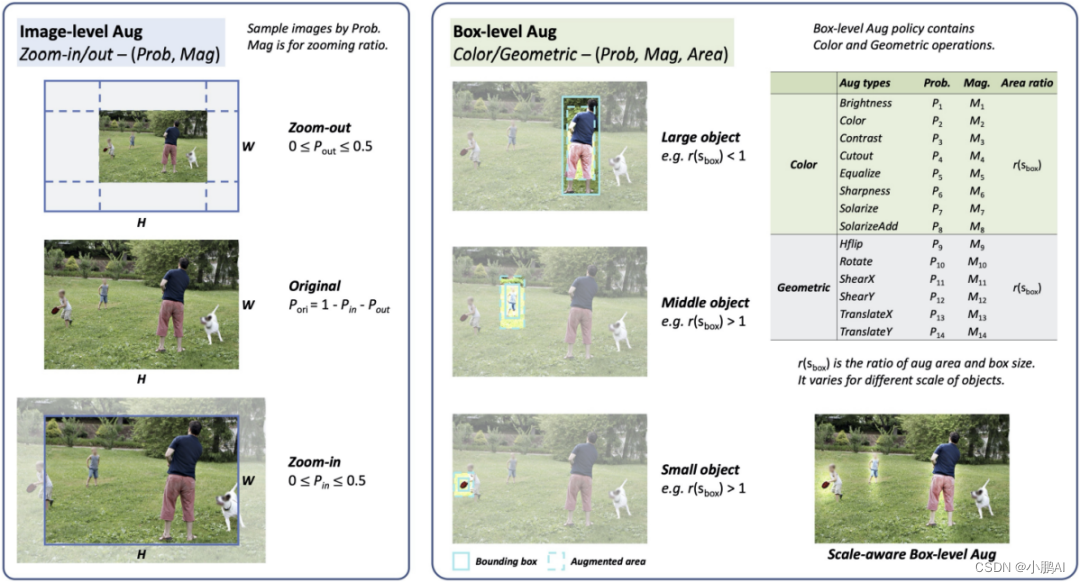
(48)ADA
ADA 提供了一种系统的方法来从目标检测的角度找到数据增强的最佳对抗性扰动
该方法基于数据的博弈论解释,即纳什均衡
纳什均衡提供了最佳边界框预测器和数据扩充的最佳设计
最优对抗性扰动是指 ground truth 的最差扰动,它迫使框预测器从最困难的样本分布中学习

从上图可以看出,ADA 偏向于选择尽可能与 GT 不同但又包含关键对象特征的边界框
(49)Deep CNN Ensemble
Deep CNN Ensemble 提出了一种新的 R-CNN 模型变体
在训练和评估方面进行了两个核心修改
首先,它使用几个不同的 CNN 模型作为 R-CNN 中的集成器
其次,它通过从 Microsoft COCO 数据集中选择与 PASCAL VOC 一致的子集
巧妙地用 Microsoft COCO 数据增强 PASCAL VOC 训练示例
原理图如下所示
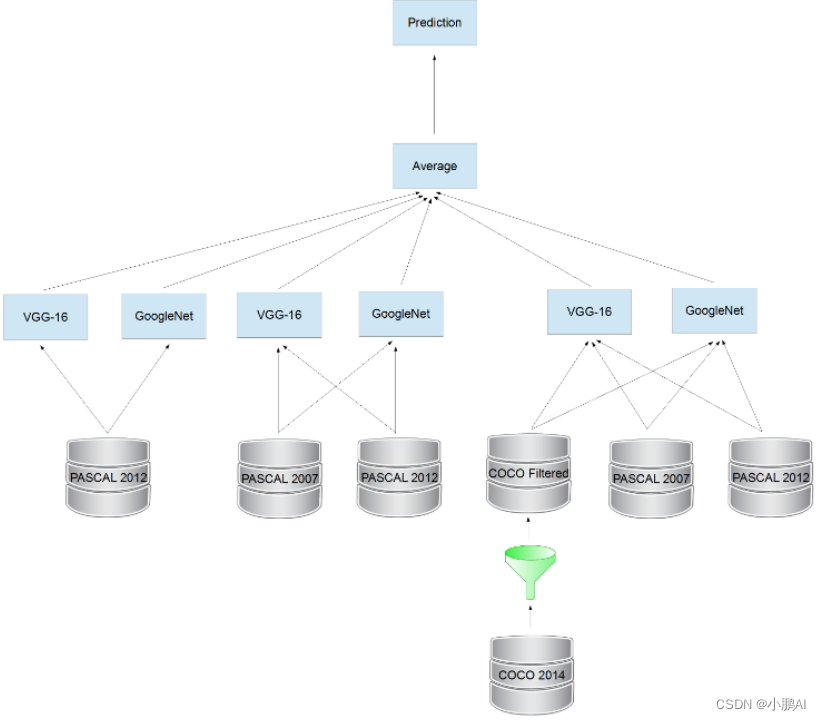
(50)RADA
通过对抗性学习可以获取稳健而准确的目标检测
先前方法展示了当对目标检测任务进行微调时分类器性能从不同的数据增强中获得增益
并且在准确性和稳健性方面的性能没有提高
RADA 提供了一种探索对抗性样本的独特方法,有助于提高性能
为此,它在目标检测器的微调阶段通过探索对抗性样本来增强示例,这被认为是依赖于模型的数据增强
首先,它从检测器分类和定位层中选择更强的对抗样本
这些样本会随着检测器的变化而变化,以确保增强策略保持一致
该方法在不同目标检测任务的准确性和鲁棒性方面显示出显着的性能提升

上图分别展示了 RADA 分别提高了目标检测器在干净图像上的准确性、检测器对自然损坏的鲁棒性以及对跨数据集域偏移的鲁棒性
(51)PTDA
PTDA,即 Pespective Transformation Data Augmentation
同样也是一种用于目标检测的新数据增强,简称为透视变换
它可以生成以不同角度捕获的新图像
因此,它模仿图像,就好像它们是在相机无法捕获这些图像的特定角度拍摄的一样
该方法在多个目标检测数据集上显示出有效性
(52)DADA
DADA,Deep Adversarial Data Augmentation,即深度对抗性数据增强
它将数据增强被表述为训练类条件和监督 GAN 的问题
此外,它还引入了新的鉴别器损失,目的是保证数据扩充是真实的
并且扩充样本被迫平等参与并在寻找决策边界时保持一致
基于非强化学习的数据增强(Non-Reinforcement learning data augmentation)
(53)RandAugment
以前的最佳增强方法大都是一些使用强化学习或一些复杂的学习策略
因此需要花费大量时间才能找到合适的增强方法和确定增强因子
这些方法消除了单独搜索阶段的障碍,这使得训练更加复杂,从而增加了计算成本开销
为了打破这一点,RandAugment 是一种新的数据增强方法,比 AutoAugment 简单又好用
主要思想是随机选择变换,并调整它们的大小

基于风格迁移的数据增强
基于风格迁移的数据增强是一种独特的数据增强方式
可以在不改变高层语义的情况下将一幅图像的艺术风格转移到另一幅图像
它为训练集带来了更多多样性
这种神经风格迁移的主要目标是从两张图像生成第三张图像
其中一张图像提供纹理内容,另一张图像提供高级语义内容
(54)STaDA
STaDA,Style Transfer as Data Augmentation,顾名思义便是基于风格迁移的数据增强方法
这是一种彻底评估了不同的 SOTA 神经风格转移算法作为图像分类任务的数据增强
此外,它还将神经风格迁移算法与传统的数据增强方法相结合,下面给出相关的示意图

(55)NSTDA
NSTDA,Neural Style Transfer as Data Augmentation
是一种将神经风格迁移作为改进 COVID-19 诊断分类的数据增强方法
这项工作显示了循环生成对抗网络的有效性,该网络主要用于神经风格迁移
增强 COVID-19 负
X
X
X射线图像以转换为正 COVID 图像以平衡数据集并增加数据集的多样性
该方法充分表明了使用 Cycle GAN 增强图像可以提高几种不同 CNN 架构的性能
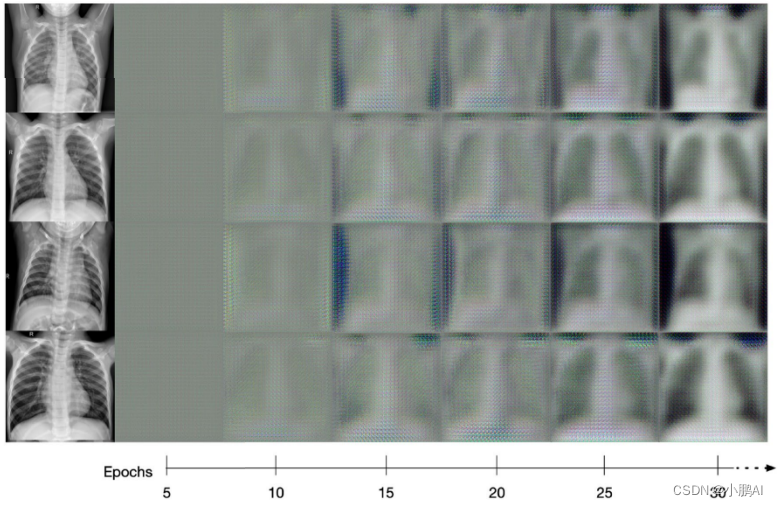
(56)SA
这项工作提出了一种新的数据增强,称为基于风格神经转移的风格增强
SA 随机化颜色、对比度和纹理,同时在训练期间保持形状和语义内容
这是通过选择任意样式传输网络来随机化样式并从多元正态分布嵌入中获取目标样式来完成的
它提高了三个不同任务的性能:分类、回归和域适应

从上图可以明显的看出,基于 SA 的数据增强方式可以将形状保留下来,但样式(包括颜色、纹理和对比度)是随机的
(57)StyPath
StyPath 是一种用于稳健组织学图像分类的风格迁移数据增强策略,旨在减少偏见的风格

(58)AS
这项工作介绍了一种基于深度神经网络的人工系统,可生成具有高感知质量的艺术图像
AS 创建神经嵌入,然后使用嵌入来分离图像的风格和内容,最后再重新组合目标图像的内容和风格以生成艺术图像

基于特征空间的数据增强
基于特征空间的数据增强首先将图像转换为嵌入或表示,然后对图像的嵌入执行数据增强,最后再向大家介绍下这部分内容
(59)Dataset Augmentation in Feature Space
这项工作首先使用编码器-解码器来学习表示
然后在表示上应用不同的变换
例如添加噪声、插值或外推。所提出的方法已经显示出静态和顺序数据的性能改进

(60)Feature Space Augmentation for Long-Tailed Data
该方法提出了基于特征空间中的新数据增强
以解决长尾问题并提升代表性不足的类样本
所提出的方法首先在类激活图的帮助下将类特定特征分为通用特征和特定特征
代表性不足的类样本是通过将代表性不足的类的类特定特征与来自其他混淆类的类通用特征注入而生成的
这使得数据多样化,也解决了代表性不足的类别样本的问题
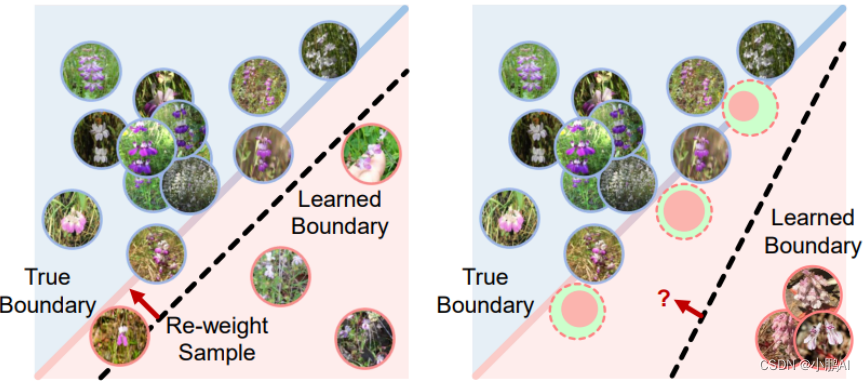
(61)Adversarial Feature Augmentation for Unsupervised Domain Adaptation
生成对抗网络在无监督域适应中显示出可喜的结果,以学习与源域无法区分的目标域特征
这项工作扩展了 GAN 以强制特征提取器成为域不变的,并通过特征空间中的数据增强来训练它,称为特征增强
总的来说,该工作探索了 GAN 在特征层面的数据增强
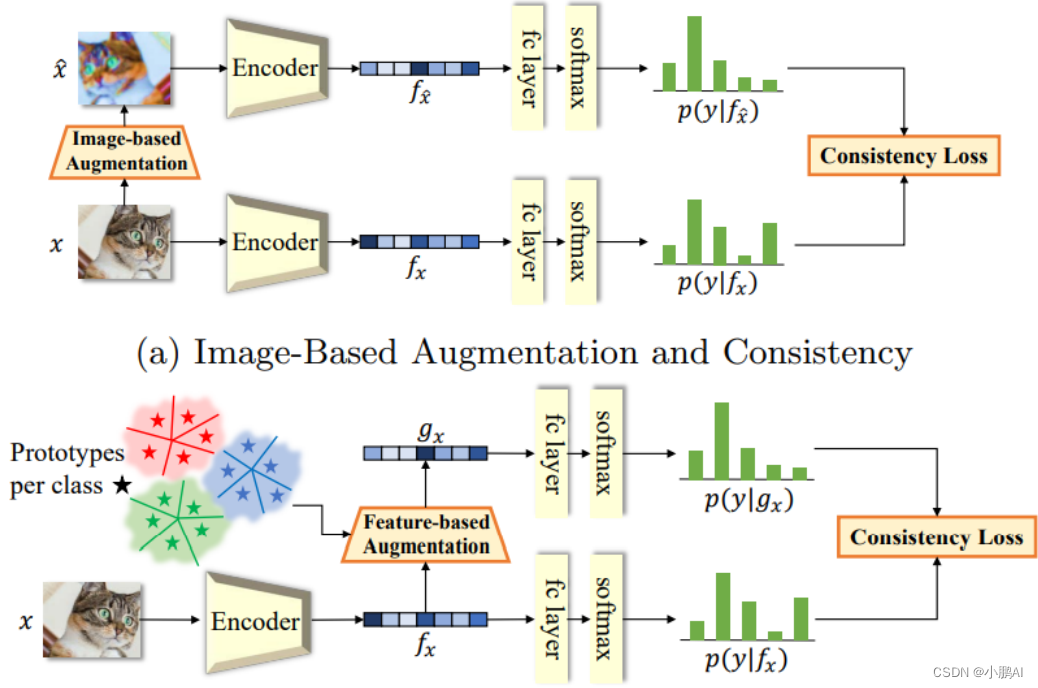
(62)FeatMatch
FeatMatch 提出了一种新的 SSL 特征空间数据增强方法,其灵感来自基于图像的 SSL 方法
该方法结合了图像增强和一致性正则化
基于图像的 SSL 方法仅限于传统的数据增强
为了打破这一目标,基于特征的 SSL 方法从复杂的数据扩充中产生了不同的特征
一个关键点是,这些高级数据增强利用了通过聚类提取的类内和类间表示的信息
所提出的方法仅在 min-Imagenet 上显示出显着的性能增益
在 miniImageNet 上绝对增益 17.44%,而且还显示了对分布外样本的鲁棒性
此外,图像级和特征级增强和一致性之间的差异如下图所示:
参考文献
[1]Advanced Data Augmentation Approaches: https://arxiv.org/pdf/2301.02830.pdf
[2]Cutout: https://arxiv.org/abs/1708.04552
[3]Random erasing: https://arxiv.org/abs/1708.04896
[4]Hide-and-Seek: https://arxiv.org/abs/1811.02545
[5]GridMask: https://arxiv.org/abs/2001.04086
[6]Local Augment: https://ieeexplore.ieee.org/document/9319662
[7]Self Augmentation: https://arxiv.org/pdf/2004.00251.pdf
[8]SalfMix: https://www.mdpi.com/1424-8220/21/24/8444
[9]KeepAugment: https://arxiv.org/abs/2011.11778
[10]YOCO: https://arxiv.org/abs/2201.12078
[11]Cut-Thumbnail: https://arxiv.org/abs/2103.05342
[12]Mixup: https://arxiv.org/abs/1710.09412
[13]CutMix: https://arxiv.org/abs/1905.04899
[14]SaliencyMix: https://arxiv.org/abs/2006.01791
[15]Puzzle Mix: https://arxiv.org/abs/2009.06962
[16]SnapMix: https://arxiv.org/abs/2012.04846
[17]FMix: https://arxiv.org/abs/2002.12047
[18]MixMo: https://arxiv.org/abs/2103.06132
[19]StyleMix: https://openaccess.thecvf.com/content/CVPR2021/papers/Hong_StyleMix_Separating_Content_and_Style_for_Enhanced_Data_Augmentation_CVPR_2021_paper.pdf
[20]RandomMix: https://arxiv.org/abs/2205.08728
[21]MixMatch: https://arxiv.org/abs/1905.02249
[22]ReMixMatch: https://arxiv.org/abs/1911.09785
[23]FixMatch: https://arxiv.org/abs/2001.07685
[24]AugMix: https://arxiv.org/abs/1912.02781
[25]Copy-Paste: https://arxiv.org/abs/2012.07177
[26]Mixed-Example: https://arxiv.org/abs/1805.11272
[27]RICAP: https://arxiv.org/abs/1811.09030
[28]CutBlur: https://arxiv.org/abs/2004.00448
[29]ResizeMix: https://arxiv.org/abs/2012.11101
[30]ClassMix: https://arxiv.org/abs/2007.07936
[31]Context Decoupling Augmentation: https://arxiv.org/abs/2103.01795
[32]ObjectAug: https://arxiv.org/abs/2102.00221
[33]AutoAugment: https://arxiv.org/abs/1805.09501
[34]Fast Autoaugment: https://arxiv.org/abs/1905.00397
[35]Faster AutoAugment: https://arxiv.org/abs/1911.06987
[36]Reinforcement Learning with Augmented Data: https://arxiv.org/abs/2004.14990
[37]MARL: https://arxiv.org/pdf/2105.00310.pdf
[38]Learning Data Augmentation Strategies for Object Detection: https://arxiv.org/abs/1906.11172
[39]Adversarial augmentation: https://ieeexplore.ieee.org/abstract/document/8658998
[40]Deep CNN Ensemble with Data Augmentation for Object Detection: https://arxiv.org/abs/1506.07224
[41]RADA: https://arxiv.org/abs/2112.02469
[42]PTDA: https://ieeexplore.ieee.org/document/8943416
[43]DADA: https://arxiv.org/abs/1809.00981
[44]STaDA: https://arxiv.org/abs/1909.01056
[45]NSTDA: https://link.springer.com/article/10.1007/s42979-021-00795-2
[46]SA: https://arxiv.org/abs/1809.05375
[47]StyPath: https://arxiv.org/abs/2007.05008
[48]AS: https://arxiv.org/abs/1508.06576
[49]Dataset Augmentation in Feature Space: https://arxiv.org/abs/1702.05538
[50]Adversarial Feature Augmentation: https://arxiv.org/abs/1711.08561
[51]FeatMatch: https://arxiv.org/abs/2007.0850