基于机器学习 实现APT 检测(附完整代码)
项目环境概述
以机器学习的方式,可以通过多种模型对 APT 组织所使用的恶意代码进行训练学习,同时由于训练的多样化,检测效果也会比家好。本项目采用的随机森林以及不同采样策略进行模型训练。详细设计见md文件。
1.系统描述
本系统主要是针对大量APT恶意代码进行学习,通过学习后从而对更多的APT恶意代码能够检测分类。
2.系统功能
对APT组织所使用的恶意代码进行动态分析,提取动态分析结果中的关键特征,使用随机森林并采用不同采样策略进行模型训练,最后能对恶意代码所属APT进行检测。
3.系统环境
3.1 硬件环境
i7以上CPU+4G内存+320G硬盘
3.2 软件环境
Ubuntu18.04操作系统
3.3 网络环境
4.一般约束
工具性能性能约束,开发技术支持,软件约束范围等。
三、软件业务需求描述
1.软件需求
软件需求 A
需求编号 | 01 | 需求名称 | 对 APT 使用恶意代码分析 |
需求说明 | 将恶意代码转换成能进行学习的数据结构 | ||
需求属性 | |||
数据流程 | 通过给定的恶意代码将其二进制转换为 01 图 | ||
展现类型 | 一系列衡量代码的 01 转换图 | ||
是否补录 | 是 | ||
存储周期 | 3 周 | ||
需求数据精度 | 无 | ||
权限需求 | 管理员 |
软件需求 B
需求编号 | 02 | 需求名称 | 提取动态分析中的关键特征 |
需求说明 | 由于代码可能过于庞大,因此部分需要进行提取 | ||
需求属性 | |||
更新频度 | 2 天 | ||
数据流程 | 经过上一步的分析,对数据结构进行删减 | ||
展现类型 | 一系列衡量代码的 01 转换图 | ||
是否补录 | 是 | ||
存储周期 | 3 周 | ||
需求数据精度 | 无 | ||
权限需求 | 管理员 |
软件需求 C
需求编号 | 03 | 需求名称 | 模型训练 |
需求说明 | 使用随机森林并采用不同采样策略进行训练(小样本) | ||
需求属性 | |||
更新频度 | 每天多次,训练时间应较短 | ||
数据流程 | 确定好模型以及输入进行训练和参数调优 | ||
展现类型 | 分类的准确率以及训练时间 | ||
存储周期 | 3 周 | ||
权限需求 | 管理员 |
软件需求 D
需求编号 | 04 | 需求名称 | 模型预测 |
需求说明 | 测试所训练的模型,对给定恶意代码所属 APT 组织进行判定 | ||
需求属性 | |||
更新频度 | 无 | ||
数据流程 | 模型训练好后对待测代码进行判定即可 | ||
展现类型 | 预测结果 | ||
是否补录 | 无 | ||
存储周期 | 3 周 | ||
权限需求 | 管理员 |
输入参数
输入参数名称 | 参数类型 | 缺省数值 | 有无显示同级的要求 | 备注 |
待预测恶意代码 | 恶意代码二进制表示 | 无 | 无 | 无 |
软件需求 E
需求编号 | 05 | 需求名称 | 可视化界面 |
需求说明 | 基本可视化,方便用户查询 | ||
需求属性 | |||
更新频度 | 无 | ||
数据流程 | 模型预测好存入数据库后直接进行回显 | ||
展现类型 | 预测结果 | ||
是否补录 | 无 | ||
存储周期 | 3 周 | ||
权限需求 | 管理员 |
四、技术需求描述
1.初始数据质量标准
由于数据会直接导致模型的好坏,因此初始数据噪声值应尽量小,数据量尽可能大
2.高性能
预测时响应速度小于1s
3.可移植性
不同操作系统均能进行训练预测。
4.可扩展性
对于不同输入数据规模,能够对相应的样本进行预测,同时能使用不同的数据进行预测。
5.可维护性
模型参数丢失以及数据库信息损失能及时回补
五、开发模型选择
开发模型我们选择瀑布式模型,主要原因是有利于软件开发过程中人员的组织、管理,有利于软件开发方法和工具的研究,从而提高了大型软件项目开发的质量和效率。
概要设计
1.引言
1.1 编写目的
本说明书目的在于明确说明系统所需环境、各模块的实现方式,以及指导开发员进行编码。
1.2 预期读者
本说明书预期读者包括:
● 项目经理;
● 开发人员;
● 测试人员;
● 文档编写人员;
2. 技术设计
2.1 系统运行环境
分类 | 名称 | 版本 | 语种 |
主机操作系统 | Ubuntu | 18.04 | 英文 |
客户机操作系统 | Windows 7 | SP1 | 简体中文 |
沙箱环境 | Cuckoo | 2.0.7 | 英文 |
数据库平台 | Gauss DB | - | 简体中文 |
主机主要开发平台 | Python | python2.7 & python3.6 | 英文 |
客户机主要开发平台 | Python | python2.7 | 英文 |
开发主要环境 | Anaconda(tenserflow) | 3 (2.X) | 简体中文 |
2.2 主要硬件环境
分类 | 配置需求 |
数据库服务器 | 8vCPU 2.6GHzMem:8GBHD:40G |
本地开发计算机 | 4-6vCPU Mem:≥8GBHD:≥128GB |
3. 模块设计
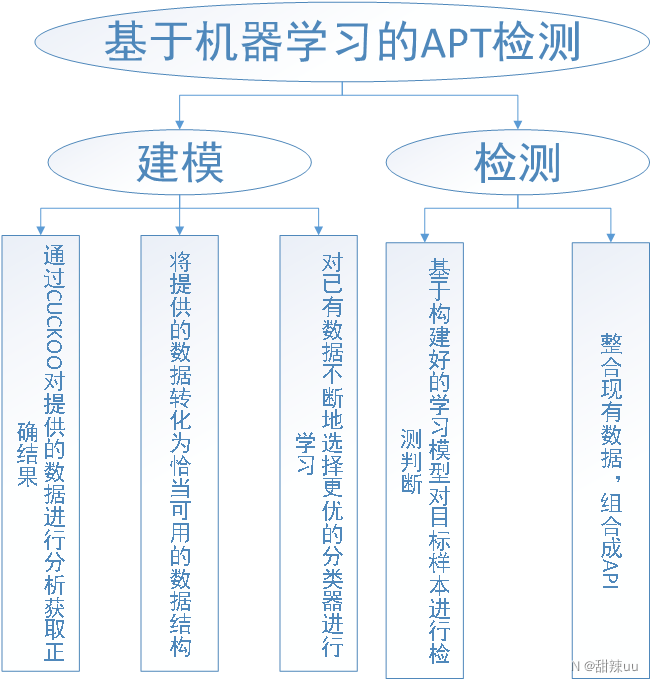
4. 图形化界面设计
4.1 结构设计
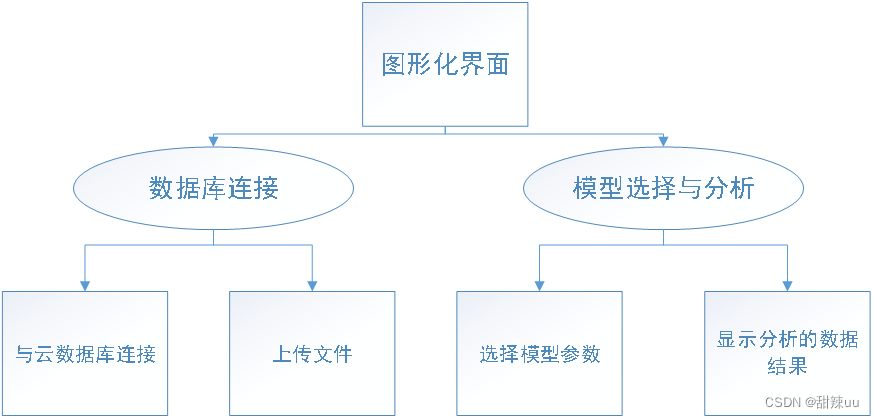
4.2 实际界面设计

5. 数据库设计
5.1 实际设计情况
通过实际操作与测试,最终选择数据库仅进行存储已经预测完的文件相关信息的功能。
具体设计如下:
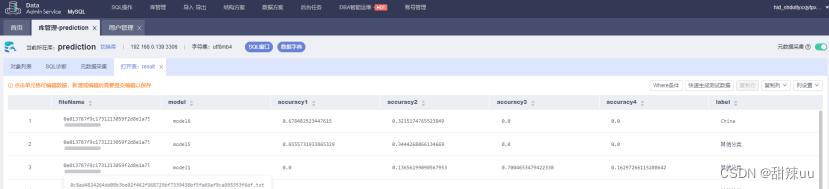
5.2 数据库表结构说明
fileName:上传文件的文件名。
model:文件预测时选择的模型编号。
accuracy1、2、3、4:分别对应着训练集中的 4 个组织的相关程度。
label:预测后,认为他所属的国家。