《Linux Shell脚本攻略》学习笔记-第二章
2.1 简介
本章将为你介绍一些最值得关注同时也是最实用的命令。
2.2 用cat进行拼接
cat命令能够显示或者拼接文件内容。cat能够将标准输入数据与文件数据组合在一起。
通常的做法是将stdin重定向到一个文件,然后再合并两个文件。而cat命令一次就能搞定这些操作。
1)打印文件内容

2)从标准输入中读取

下面的命令将stdin和另一个文件中的数据组合在一起,加入到文件的开头部分。

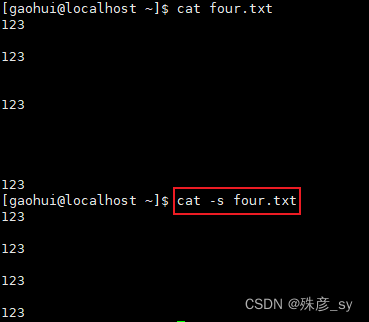
3)去掉多余的空白行
有时候文本中可能包含多处连续的空白行。如果想要删除这些额外的空白行,可以使用cat -s。
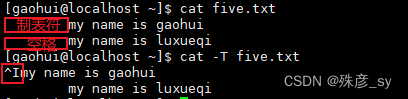
4)将制表符显示为^I
对于Python而言,制表符和空格的区别是区别对待的。在文本编辑器中,两者看起来差不多,但是解释器将其视为不同的缩进。
cat有一个特性,可以将制表符识别出来。这有助于排查缩进错误。
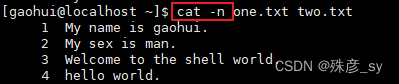
5)行号
cat命令的-n选项会在输出的每一行内容之前加上行号。
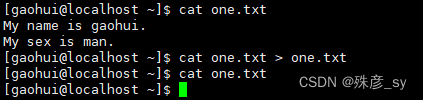
6)cat命令绝对不会修改你的文件,它只是根据用户提供的选项在stdout中生成一个修改过的输出而已。
不要尝试用重定向来覆盖输入文件。shell在打开输入文件之前会创建新的输出文件。利用管道并重定向输出会清 空输入文件。
2.3 录制并回放终端会话
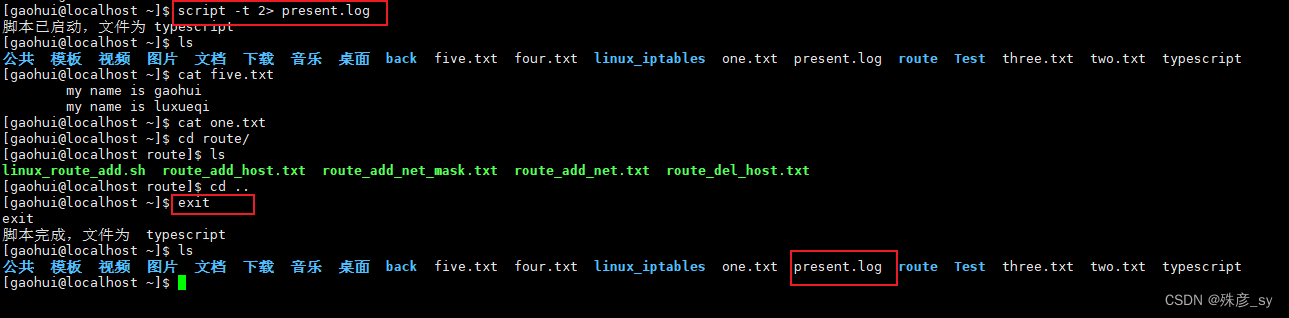
script命令能够录制你的击键以及击键时机,并将输入和输出结果保存在对应的文件中。
scriptreply命令可以回放会话。
1)你可以通过录制终端会话来制作命令行技巧视频教程,也可以与他人分享会话记录文件,研究如何使用命令行完成某项任务。你甚至可以调用其他解释器并录制发送给该解释器的击键。但是你无法记录vi、emacs或者其他将字符映射到屏幕特定位置的应用程序。
2)如果指定了-t选项,script命令会把时序数据发送到stdout。可以将这些数据重定向到其他文件中,这样该文件中就记录了每次击键的时机以及输出信息
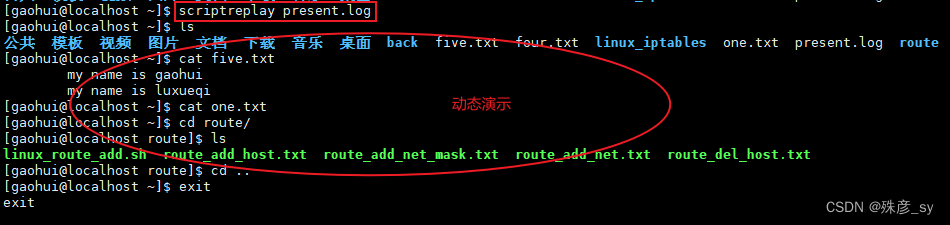
2)你可以把present.log文件分享给任何想要在自己的终端上回放这段终端回话的人。
2.4 查找并列出文件
find命令的工作方式如下:沿着文件层次结构向下遍历,匹配符合条件的文件,执行相应的操作。
默认的操作是打印出文件和目录,这也可以使用-print选项来指定。
1)列出给定目录下的所有文件和子目录
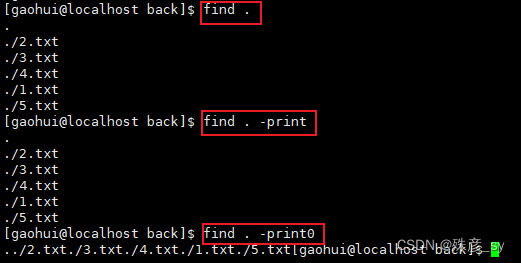
.指定当前目录,..指定父目录
print选项使用\n(换行符)分隔输出的每个文件或目录名,而print0选项则使用空字符'\0'来分隔。
2)根据文件名或正则表达式进行搜索
-name选项指定了待查文件名的模式。这个模式可以是通配符,也可以是正则表达式。
shell会扩展没有引号或是出现在双引号中的通配符(存疑)。单引号能够阻止shell扩展,使得该字符串能够原封不动地传给find命令。
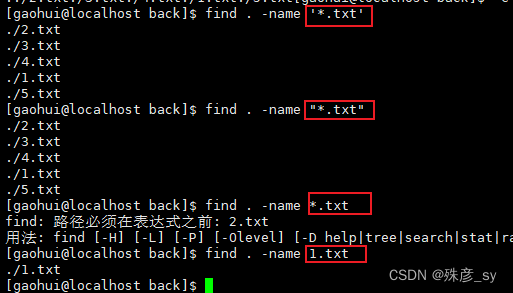
find还有一个选项-iname,该选项的作用和-name类似,只不过在匹配名字时会忽略大小写。
3)逻辑操作符
find命令支持逻辑操作符。-a和-and选项可以执行逻辑与操作;-o和-or选项可以执行逻辑或操作。
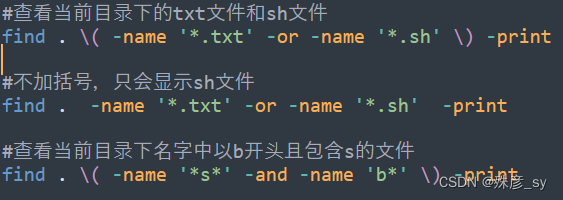
4)限制所匹配文件的路径
![]()
5)正则表达式
email地址通常采用name@host.root这种形式,所以可以将其一般化为[a-z0-9]+@[a-z0-9]+\.[a-z0-9]+。
中括号中的字符表示的是一个字符组;符号+指明在它之前的符号组中的字符可以出现一次或者多次;点号是一个元字符,因此必须使用反斜线对其进行转义。
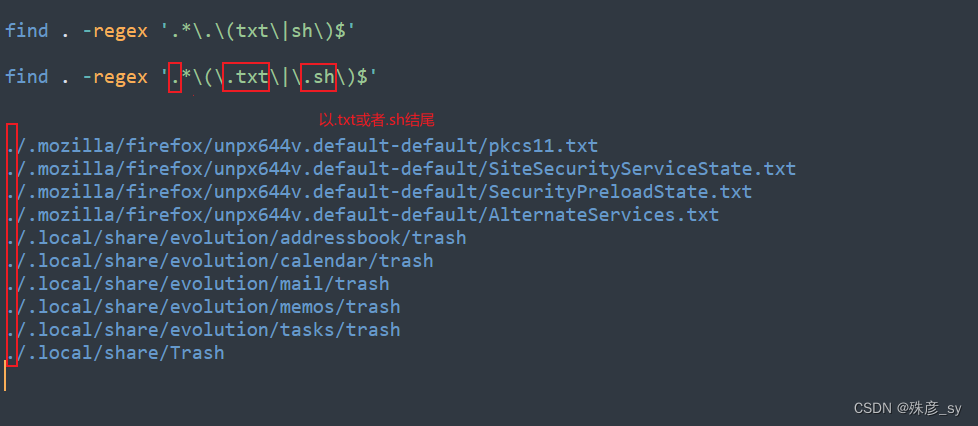
6)否定参数

7)基于目录深度的搜索
find命令在查找时会遍历万所有的子目录。默认情况下,find命令不会跟随符号链接。-L选项可以强制其改变这种行为。但是如果碰上了指向自身的链接,find命令就会陷入死循环中。
-maxdepth和-mindepth选项可以限制find命令遍历的目录深度;应该在find命令中及早出现。
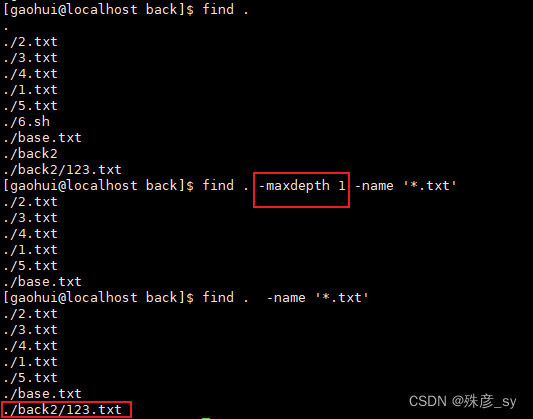
-mindepth设置的是find开始进行查找的最小目录深度。这个选项可以用来查找并打印那些距离起始路径至少有一定深度的文件。
![]()
8)根据文件类型进行搜索
find命令可以使用-type选项对文件搜索进行过滤。
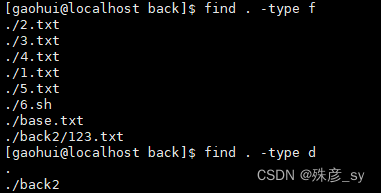

9)根据文件的时间戳进行搜索
linux文件系统中的每个文件都有三种时间戳,如下所示:①访问时间-atime:用户最近一次访问文件的时间
②修改时间-mtime:文件内容最后一次被修改的时间
③变化时间-ctime:文件元数据(如权限或所有权)最后一次改变的时间
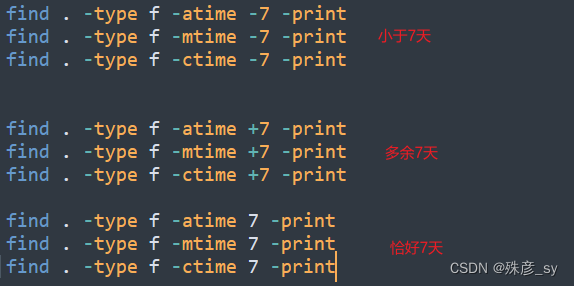
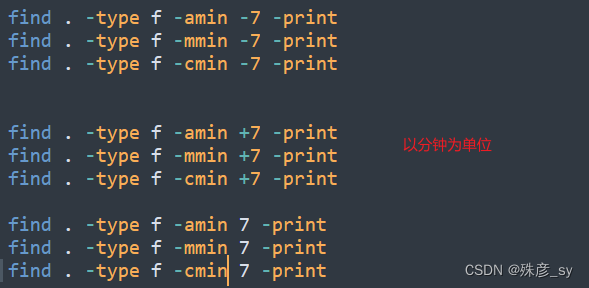
-newer选项可以指定一个用于比较修改时间的参考文件,然后找出比参考文件更新的所有文件。

10)基于文件大小的搜索
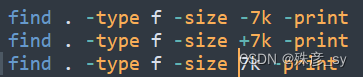
除了k之外,还可以使用其他的文件大小单位。
11)基于文件权限和所有权的匹配
-perm选项指明find应该只匹配具有特定权限值的文件。
![]()
-user选项就能够找出由某个特定用户所拥有的文件。
![]()
12)利用find命令执行相应操作
①删除匹配的文件
![]()
②-exec执行命令
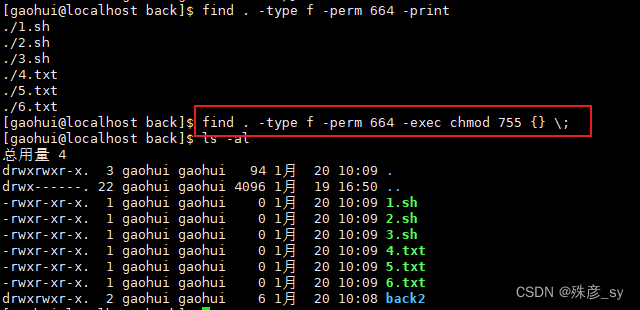
一定要注意命令行结尾的\;。必须对分号进行转义,否则shell会将其视为find命令的结束,而非chmod命令的结束。

无法在-exec选项中直接使用多个命令。该选项只能接受单个命令,不过可以将多个命令写入shell脚本,然后在exec中执行该脚本。
-exec ./command.sh {} \;
13)让find跳过指定的目录

2.5 玩转xargs
xargs命令从stdin处读取一系列参数,然后使用这些参数来执行指定命令。它能将单行或多行输入文本转换成其他格式,比如单行变多行或者多行变单行。
xargs命令应该紧跟在管道操作符之后。它使用标准输入作为主要的数据源,将从stdin中读取的数据作为指定命令的参数来执行该命令。
![]()
从一组sh源码文件中搜索字符2。
1)xargs默认的echo命令可以用来将多行输入转换成单行输出
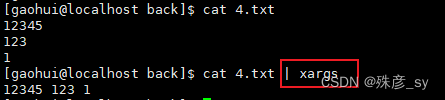
将单行输入变成多行输出
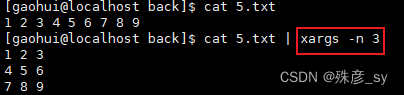
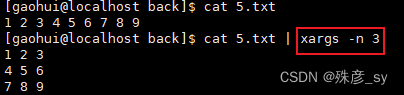
2)xargs命令接受来自stdin的输入,将数据解析成单个元素,然后调用指定命令将这些元素作为该命令的参数。
xargs命令默认使用空白字符分隔输入并执行/bin/echo。
我们可以定义一个用来分隔参数的分隔符,-d选项可以为输入数据指定自定义的分隔符。
3)find的输出可以通过管道传给xargs,由后者执行-exec选项所无法处理的复杂操作。如果文件系统的有些文件名中包含空格,find命令的-print0选项可以使用0(NULL)来分隔查找到的元素,然后再用xargs对应的-0选项进行解析。
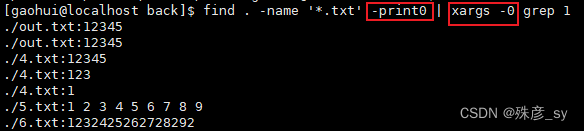
4)

xargs有一个选项-I,可以用于指定替换字符串,这个字符串会在xargs解析输入时被参数替换掉。如果将-I与xargs结合使用,对应每一个参数,指定命令只会执行一次。

5)结合find使用xargs
![]()
6)统计源代码目录中所有sh程序文件的行数

7)结合stdin,巧妙运用while语句和子shell
xargs将参数放置在指定命令的尾部,因此无法为多组命令提供参数。
可以通过创建子shell来处理这种复杂情况。
①cmd0 | (cmd1;cmd2;cmd3) | cmd4
②shell的-c选项可以用来调用子shell来执行命令行脚本。它可以与xargs结合解决多次替换的问题。

2.6 用tr进行转换
tr可以对来自标准输入的内容进行字符替换、字符删除以及重复字符压缩。
tr能够通过stdin(标准输入)接收输入(无法通过命令行参数接收)
tr [options] set1 set2
来自stdin的输入字符会按照位置从set1映射到set2(set1中的第一个字符映射到set2中的第一个字符,以此类推),然后将输出写入stdout(标准输出)。
如果两个字符组的长度不相等,那么set2会不断复制其最后一个字符,知道长度与set1相同。如果set2的长度大于set1,那么在set2中超出set1长度的那部分字符会全部被忽略。
1)用tr进行替换
![]()
如果“起始字符-终止字符”不是有效的连续字符序列,那么它就会被视作含有三个元素的集合。(起始元素、-、终止元素)
2)用tr进行加密和解密

![]()

将制表符转换成到单个空格:
![]()
3)tr有一个选项-d,可以通过指定需要被删除的字符集合,将出现在stdin中的特定字符清楚掉。
![]()
4)字符组补集
利用选项-c来使用set1的补集
tr -c [set1] [set2]
如果使用了-c选项,set1和set2必须都给出。如果-c与-d选项同时出现,你只能使用set1,其他所有字符都会被删除。
![]()
![]()
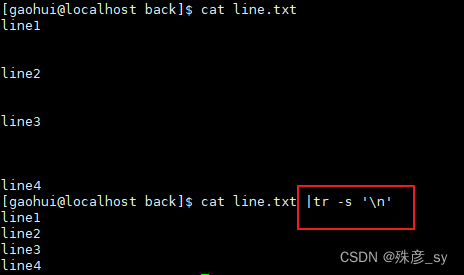
5)用tr压缩字符
![]()
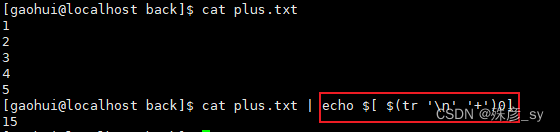
使用tr用一种巧妙地方法将文件中的数字列表进行相加:
6)字符类
tr可以将不同的字符类作为集合使用:如tr '[:lower:]' '[:upper:]'
2.7 校验和与核实
校验和程序用来从文件中生成相对较小的唯一密钥。校验和能够让我们核实文件中所包含的数据是否和预期一样。
unix和linux支持多种校验和程序,但强健性最好且使用最广泛的校验和算法是MD5和SHA-1。md5sum和sha1sum程序可以对数据应用对应的算法来生成校验和。
1)计算md5sum
md5sum是一个长度为32个字符的十六进制串。

2)输出校验和是否匹配
![]()
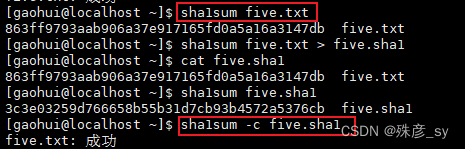
3)SHA-1是另一种常用的校验和算法。它从给定的输入中生成一个长度为40个字符的十六进制串。
4)对于对个文件,校验和同样可以发挥作用。
md5deep和shaldeep命令可以遍历目录树,计算其中所有文件的校验和。
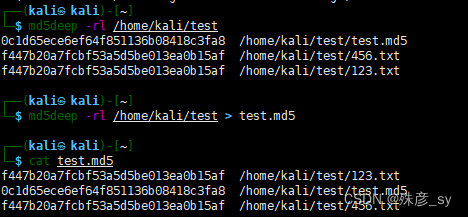
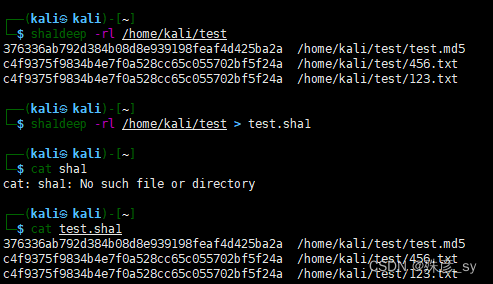
5)利用find命令来计算校验和
![]()
2.8 加密工具与散列
加密技术主要用于防止数据遭受未经授权的访问。
1)gpg是一种应用广泛的工具,它使用加密技术来保护文件,以确保数据在送达目的地之前无法被读取。
用gpg加密文件:
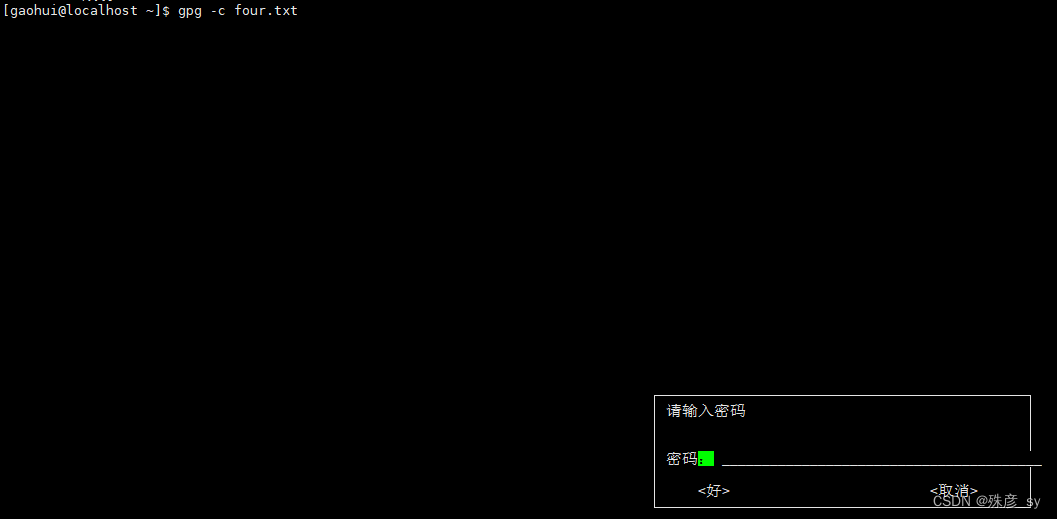
解密gpg文件:

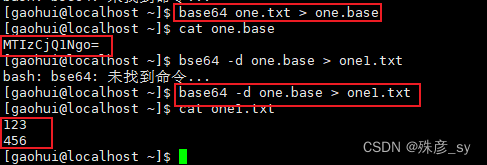
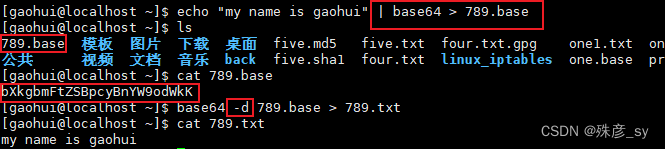
2)base64加密
base64加密和解密:
从stdin中读取后加密解密:
2.9 行排序
sort命令能够对文本文件和stdin进行排序。uniq经常和sort一起使用,提取不重复(或重复)的行。
sort命令和uniq命令可以从特定的文件或stdin中获取输入,并将输出写入stdout。
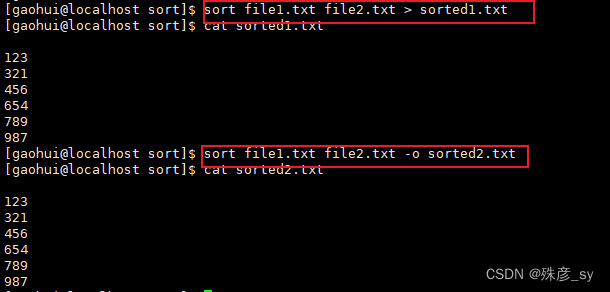
1)排序一组文件内容
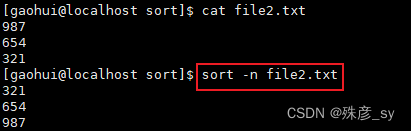
2)按照数字顺序排序
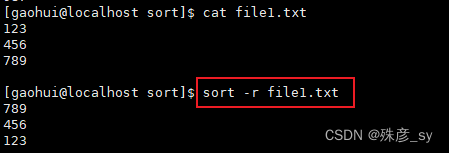
3)按照逆序排序
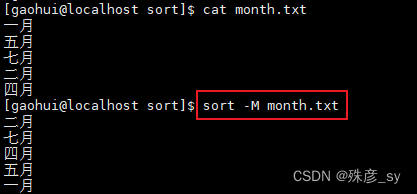
4)按照月份排序
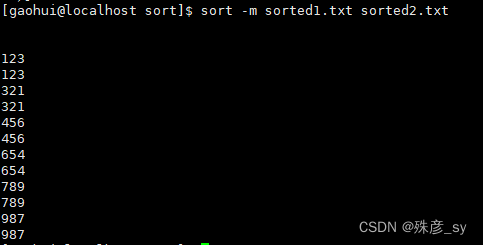
5)合并两个已经排序过的文件
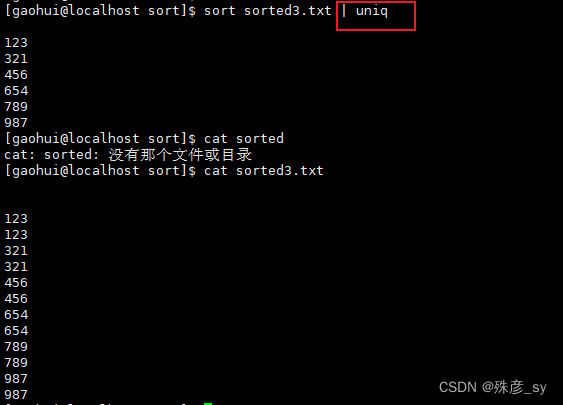
6)找出已排序文件中不重复的行
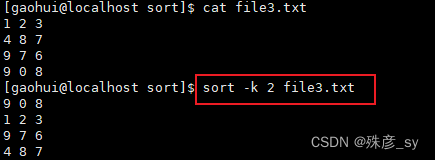
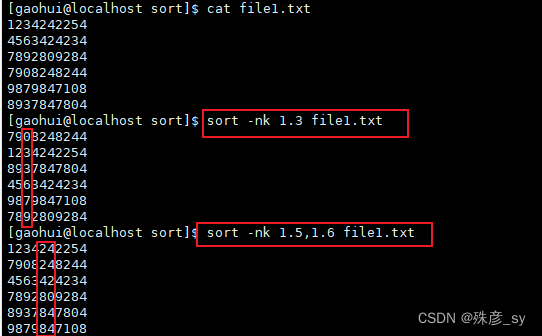
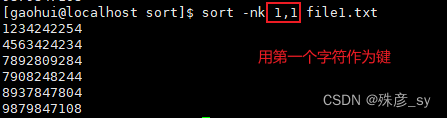
7)依据指定列数进行排序
-k指定了排序所依据的字符,如果是单个数字,则指的是列号。
8)unqi
uniq可以从给定输入中找出唯一的行,报告或删除那些重复的行。uniq只能用于排过序的数据,因此,uniq通常都与sort命令结合使用。
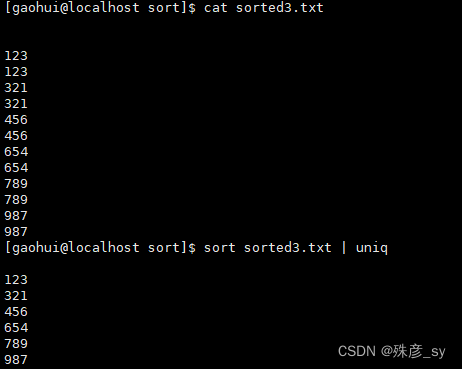
只显示唯一的行:
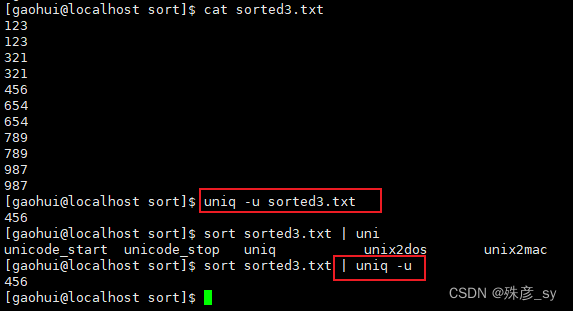
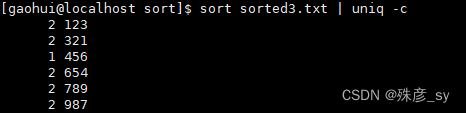
统计各行在文件中出现的次数:
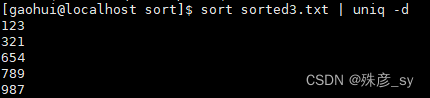
找出重复的行:
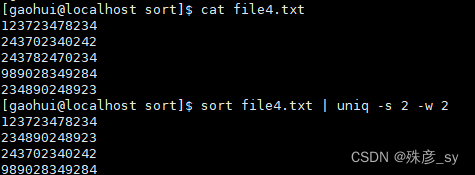
-s指定跳过的前N个字符;-w指定用于比较的最大字符
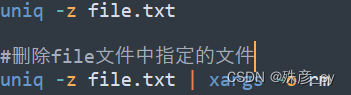
-z选项可以生成由0值字节终止的输出:
2.10 临时文件命名与随机数
shell脚本经常需要存储临时数据,最适合存储临时数据的位置是/temp。
mktemp命令可以为临时文件或目录创建唯一的名字。
1)创建临时文件、临时目录
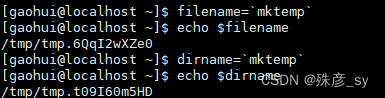
2)仅仅是想生成文件名,不希望创建实际的文件或目录

3)基于模板创建临时文件名
![]()
X会被随机的字符替换,注意mktemp正常工作的前提是保证模板中至少要有三个X。
2.11 分割文件与数据
1)split命令可以用来分割文件。
split默认使用字母后缀:

如果想要使用数字后缀,-d选项。-a length指定后缀长度。

指定前缀:

指定行数:

2)csplit实用工具能够基于上下文来分隔文件


分割后得到的第一个文件没有任何内容,所以我们需要删除了server00.log。
2.12 根据文件扩展名切分文件名
借助%操作符可以从name.extension这种格式中提取name部分;借助#操作符可以从name.extension这种格式中提取extension部分
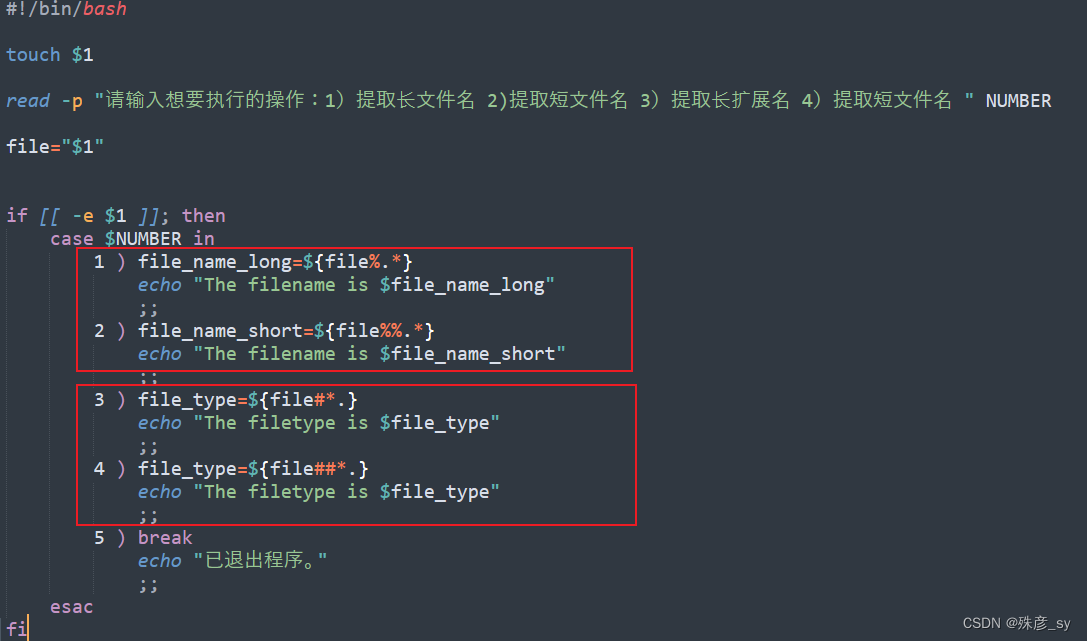
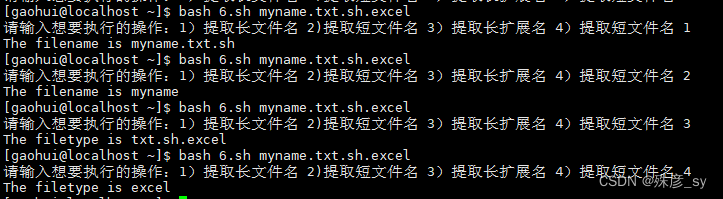
${VAR%.*}:从$var中删除位于%右侧的通配符所匹配的字符串,通配符从右向左进行匹配。
${VAR#*.}:从$var中删除位于#右侧的通配符所匹配的字符串,通配符从左向右进行匹配。
%属于非贪婪操作,它从右向左找出匹配通配符的最短结果;%%属于贪婪操作,这意味着它会匹配符合通配符的最长结果。
#属于非贪婪操作,它从左向右找出匹配通配符的最短结果;##属于贪婪操作,这意味着它会匹配符合通配符的最长结果。
2.13 多个文件的重命名与移动
1)利用find查找文件,然后使用##操作符和mv将查找到的文件重命名
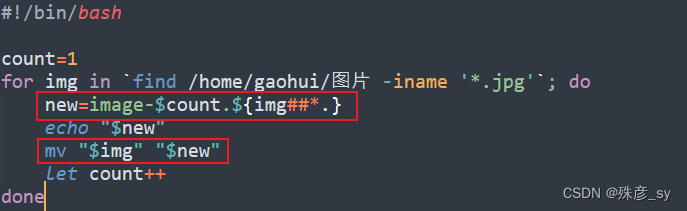
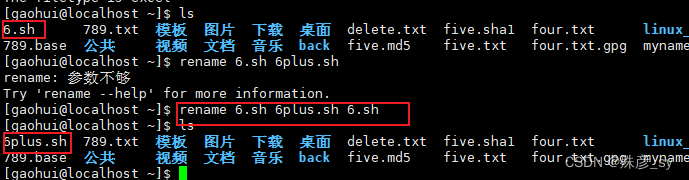
2)在C版本的rename中使用
2.14 拼写检查与字典操作
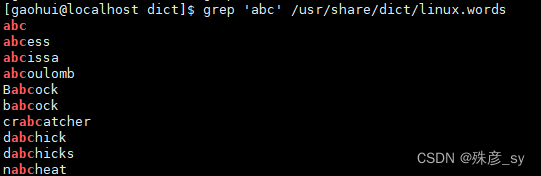
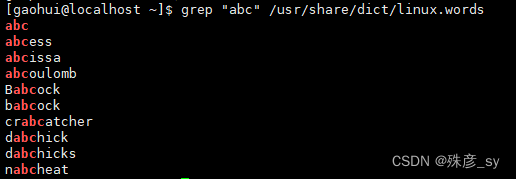
1)实用工具aspell命令,其作用是进行拼写检查。
目录/user/share/dict中包含了一些词典文件。所谓词典文件就是包含了单词列表的文本文件,我们可以利用它来检查某个单词是否在词典中。
![]()

^表示单词的开始,$表示单词的结束。
2)当给定的输入不是一个词典单词是,aspell list命令会生成输出,否则不产生任何输出。
![]()
对文件进行交互式拼写检查:
![]()
3)look命令可以显示出以特定字符串起始的行,look命令默认搜索/usr/share/dict/words
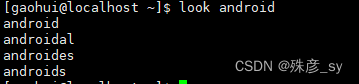
![]()
2.15 交互式输入自动化
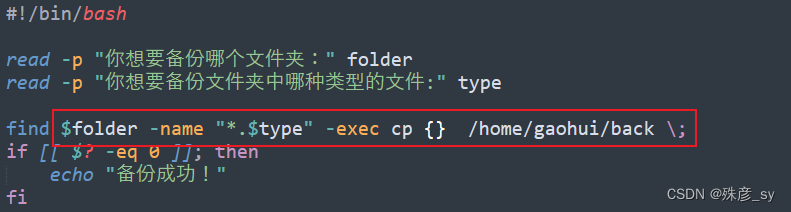
执行方式:
①:

②:
![]()
③:
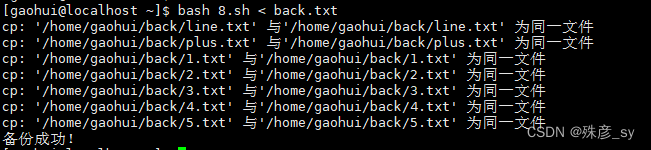
2.16 利用并行进程加速命令执行
可以使用$!来获得进程的PID,在bash中,$!保存着最近一个后台进程的PID。
我们可以将这些PID放入数组,然后使用wait命令等待这些进程结束。
2.17 检查目录以及其中的文件与子目录
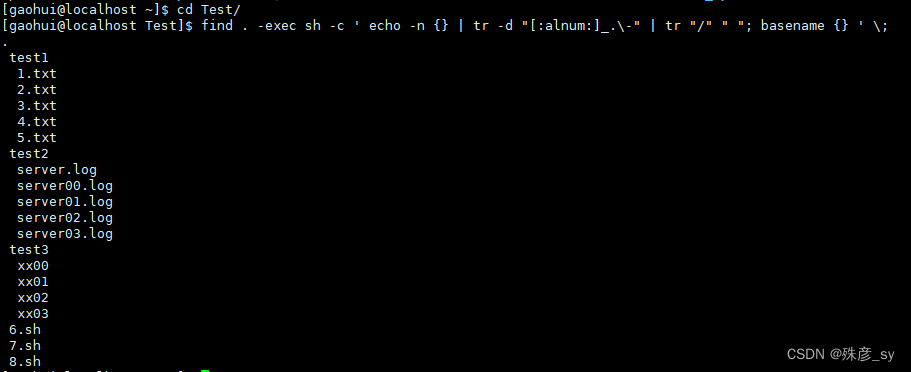
![]()
打印目录下所有文件:
![]()
删除所有字母:
![]()
删除所有/:
![]()
显示所有文件名:
![]()
结果: