来给博客除草了:Learned Indexes for a Google-scale Disk-based Database


1. 引言
这是一篇业界发表在NeurlIPS 2020的Wip论文《Google规模的基于磁盘的数据库的学习索引》。自从学习索引祖师爷Tim Kraska@MIT在SIGMOD 2018发表了第一篇learned index的工作之后,有关学习索引的paper呈现 increasing trend。目前,较多的工作focus在in-memory的层面,直到最近才出现一些工作,研究将学习索引从内存拓展到更远的存储(NVM、SSD、RDMA等)。在内存外学习索引的研究工作中,LSM-tree存储结构是一个令人excited的方向。得益于LSM-tree的设计哲学,LSM-tree中的SSTable组件是read-only的,这种读写特性与学习索引相当契合(学习索引最初也是为了优化读性能而生,原始学习索引并不支持写插入、写更新)。LSM-tree是Google三驾马车之一——BigTable的原型,BigTable是Google研发的分布式海量数据存储系统。Google将学习索引和BigTable进行结合,提升了BigTable的读性能。
2. 问题
作者介绍了目前BigTable中使用索引的现状:
- 使用B-Tree来确定key存储在哪个data block中
- 不能使用哈希索引,因为BigTable要支持范围查询,哈希索引无法满足这一需求
- B-Tree在读取数据时存在一定程度的读放大(为了查找一个key,可能需要几次读取index block,最后再读取data block到内存)
问题:
- BigTable实例的size很大,所以index没法fit into memory
- 一台机器上有多个BigTable实例,进一步减少了可用的内存空间
- 在大数据量面前,可用的cache也会告急
- 并不是所有BigTable实例都会经常被用到(冷热BigTable)
作者认为,learned index天生的存储优势(smaller index space)有助于缓解cache压力,减少index从外存fetch的次数(尤其有利于减少tail latency),从而减少存储资源的占用,提升BigTable的吞吐量。
祖师爷最早提出的内存学习索引并不适用于BigTable。为此,作者们训练了一种将key映射到BigTable中对应的data block的学习索引结构。
3. 背景
LSM-tree LSM-tree是一种非常经典、流行的键值存储结构,具有极其高效的写入效率,和较高的读取效率。其介绍参见:
https://blog.51cto.com/u_15127582/2749141
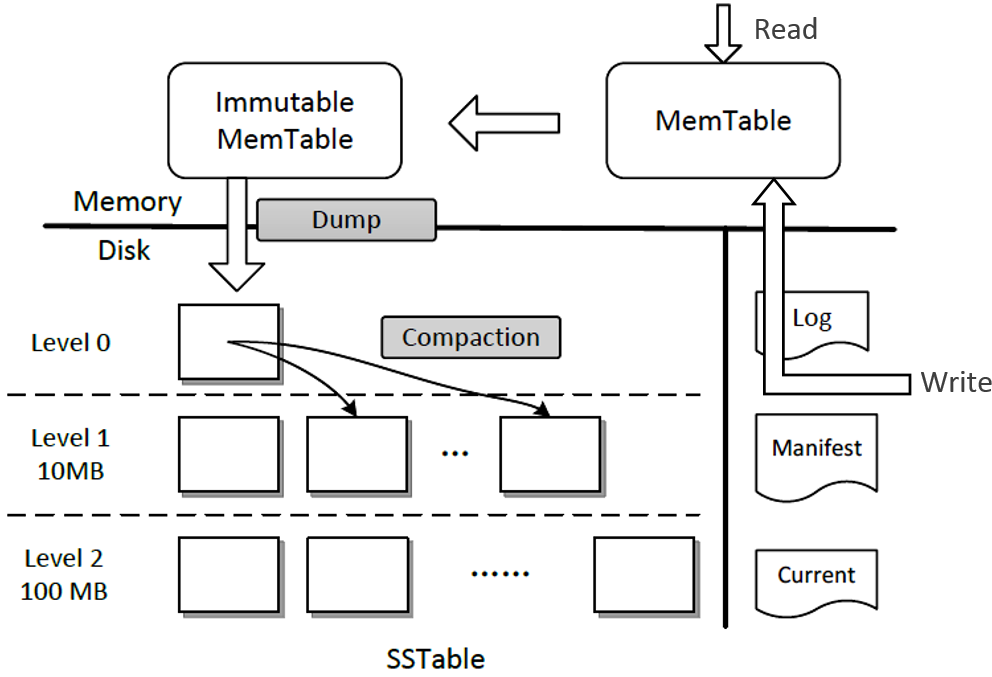
BigTable BigTable是PB级别的分布式存储系统,支持低延迟、高吞吐。BigTable的结构原型为LSM-tree,谷歌大牛Jeff Dean在十年前将LSM-tree/BigTable的实现开源为LevelDB。
SSTable SSTable是LSM-tree持久化存储的组件。SSTable存储众多键值对,按key进行排序。为了支持对数据集进行有效的操作,SSTable将数据分割成data block,并保留索引,说明哪些键位于哪些数据块中。读取时可以使用SSTable索引,来找到一个key所在的数据块。
SSTable索引被存储在index block中。索引条目包含了每一数据块的位置和大小。利用这些信息,数据块可以被有效地加载到内存中。索引块被keep in memory,这意味着读取,特别是连续读取,可以通过查询索引块来完成,并且只对请求的数据进行磁盘读取。
SSTable索引是在构建SSTables的同时创建的。在构建过程中,一旦一个数据块被填满,该数据块的代表性item(通常会是该数据块的首个item或者最后一个item)就被添加到索引中。之后,该数据块连同其索引被持久化到文件。
随着SSTable大小的增加,索引块的大小也会增加。为了提高索引效率,SSTable使用两级索引,包括一个0级索引和一个1级索引。0级索引跨越多个索引块,并且总是驻留在内存中,指向1级索引块。第1级索引是一个1级索引块的序列,它指向数据块。当1级索引块所指向的数据块被访问时,一级索引块被加载到内存中。
4. Learned Index for Disk-based Databases
设计 SSTable原本的索引,能够确定所给key存储在哪个data block中。而学习索引根据key预测到其存储的location。作者认为,预测到具体的location对BigTable没用,因为即便预测到了location,还是要把这个location所在的data block加载到内存。因此,作者设计的学习索引。将key映射到data block这个粒度。
但即便是预测到data block,作者认为预测错误的代价大,因为要重新读取周围的data block,这将带来更大的开销(存疑:不可以增加元信息来辅助判断么?)
于是,本文学习索引任务表示为:
训练学习索引f(*),接受key作为输入,以key所在的data block number作为输出。作者在此用了一个trick:在SSTable构建的过程中动态确定学习索引预测的误差值e,以确保<k,v>能够落在f(k)预测的data block内。因此,这就确保了后续访问SSTable时,学习索引总是能给出确切的key所在的data block。
训练 上文提到,学习索引最后预测到的是data block number,但是现在的情况是压根不知道哪个key对应哪个data block number。
因此,换一种方式,先将key映射到字节偏移量。引入下面的记号:
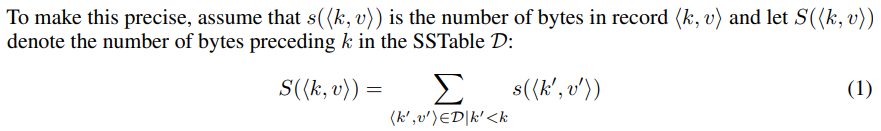
因此,f(k)预测出byte offset之后,就可以得到其存储的data block number为:

(存疑:除以平均block size就能得到准确的block number了么?这里应该有更多的说明或论证)
在预测到block number之后,通过取B[block number],可得到数据在磁盘上存储的位置,进一步将data block读取进内存中。这里B是作者预先处理好的磁盘位置数组。
模型 LR模型(线性回归)。
5. 实验
- Baseline:two-level index(BigTable’s Default)
- HW Config:5 tablet servers, each with 4G RAM
- Trace:256百万行
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Jm7mXCua-1674032217741)(https://files.mdnice.com/user/10629/f19ab7be-893d-44b7-bc53-58f85473c5ec.png)]
6. 相关工作
- Bourbon:Bourbon是威斯康星麦迪逊分校Remzi组的工作,发表于2020年的OSDI。Bourbon在WiscKey键值分离的基础上,设计了一种简单而行之有效的学习索引,加速了LSM-tree的查询性能。
Dai Y, Xu Y, Ganesan A, et al. From {WiscKey} to Bourbon: A Learned Index for {Log-Structured} Merge Trees[C]//14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). 2020: 155-171.