SGA与PGA的区别
前几天有被别人问到什么是SGA和PGA,说实在的,之前一直搞分布式,已经基本把单机里面的这两个概念忘记的差不多了,不过当时还是根据自己的一点数据库经验说了点七七八八,后来网上查了一下相关说明,发现自己的理解也大概能对的上,只不过没有那么详细。
下图是一张Oracle的体系结构图,
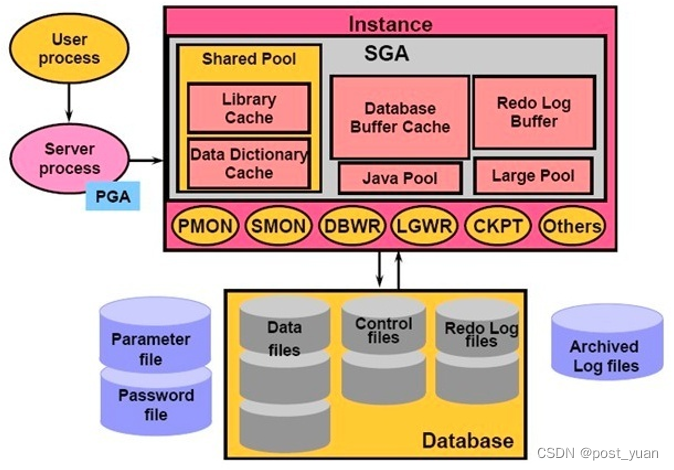
PGA
PGA(Process Global Area),是为每个连接到数据库的用户进程保存的内存区。
当用户进程连接到数据库并创建一个对应的会话时,数据库服务进程会为这个用户专门设置一个PGA区,用来存储这个用户会话的相关内容。当这个用户会话终止时,数据库系统会自动释放这个PGA区所占用的内存。
PGA区对数据库的性能有比较大的影响,特别是对于排序操作的性能。所以在必要时合理管理PGA区,能够很大程度上提高数据库的性能。
PGA内部又包括以下几个区域:
-
排序区
当用户需要对数据进行排序时,系统会将要排序的数据保存在PGA中的排序区内,然后在里面排序。因此设置较大的排序区可以提高用户访问数据的效率。 -
会话区
会话区保存了会话所具有的权限、角色、性能统计等信息,通常由数据库系统自我维护。 -
堆栈区
保存绑定变量、会话变量、SQL语句运行时的内存结构等重要信息,通常也由数据库自我维护。 -
游标区
游标区是一个动态的区域,当用户执行游标语句打开游标时,系统会在PGA中创建游标区,关闭游标时时这个区域被释放。创建及释放需要占用一定的系统资源和时间,所以频繁的打开和关闭游标会降低语句的执行性能。
SGA
SGA(System Global Area),系统全局区,是一组共享内存结构。如果多个用户同时连接到同一个实例,那么实例的SGA中的数据将在用户之间共享。因此SGA有时也被称为共享全局区域。
一个实例由SGA进程和其他进程共同组成。数据库在启动实例时自动为SGA分配内存,在关闭实例时操作系统回收内存。每个实例都有自己的SGA。
SGA为读写状态,连接到多进程数据库实例的所有用户都可以读取该SGA中包含的信息,并且在数据库执行期间有多个进程写入SGA。
根据以上架构图,SGA内部还分成了多个小的内存区,各个小内存区存放不同的信息。
-
共享池 Shared Pool
(1)数据字典缓存区 Data Dictionary Cache
用于存放SQL语句相关的数据文件、表、索引、列、用户、其他的数据对象定义和权限信息等等。
(2)库缓存区 Library Cache
存放共享SQL和PLSQL代码。服务器进程在执行语句时,首先会匹配库缓存,如果存在相同语句则无需编译直接使用已编译的执行计划。
绑定变量不是在编译阶段赋值的,而是在运行阶段赋值的,因此含有绑定变量的SQL语句可以不用重启编译。
(3)SQL和PLSQL结果缓存 -
大池 Large Pool
大池是可选的内存区,可提供一个大的缓冲区供数据库备份与恢复操作过程使用。数据库的备份恢复、执行具有大量排序操作的SQL语句、并行化的操作时可能需要用到大池。 -
数据库缓存区 Database Buffer Cache
用于缓存当前或最近使用的从磁盘读取的数据块的拷贝,来优化数据库的IO减少物理读写。Oracle依据LRU算法对该内存区域进行block-level的更新。
(1)脏缓存块
数据被修改过并且已经commit但还未写入磁盘的数据缓存块,最终会被DBWn进程写入到磁盘并永久保存。
(2)命中缓存块
最近正在被访问的缓存块,始终被保留在数据调整缓存中,不会被写入数据文件。
(3)空闲缓存块
该缓存没有数据,等待被写入数据。Oracle从数据文件中读取数据后,寻找空闲缓存块,以便写入其中。 -
Java池 Java Pool
Java池在数据库中支持JAVA的运行,存放Java代码和Java语句的语法分析表 -
流池 Stream Pool
用于缓存流进程在数据库间移动/复制数据时使用的队列消息。一般从重做日志中提取变更记录的进程和应用变更记录的进程会用到。 -
日志缓存 Redo Log Buffer
比较小的内存区,用来短期存储将写入到磁盘中的重做日志信息。日志缓冲区也是为了减少磁盘IO,减少用户的等待时间。