MySQL索引
文章目录
- 索引
- MySQL
- 认识磁盘
- MySQL与磁盘交互的基本单位
- 建立共识
- 索引的理解
- 单个page
- 多页情况
- 什么是主键索引
- 为什么只能是B+树
- 聚簇索引vs非聚簇索引
- 非聚簇索引
- 聚簇索引
索引
索引:提高数据库的性能,提高数据库的检索速度,不用加内存,不用改sql,不用改程序,速度可以提高成败上千倍,但是插入,更新,删除的速度就比较慢
常见的索引
- 主键索引(primary key)
- 唯一键索引(unique)
- 普通索引(index)
MySQL
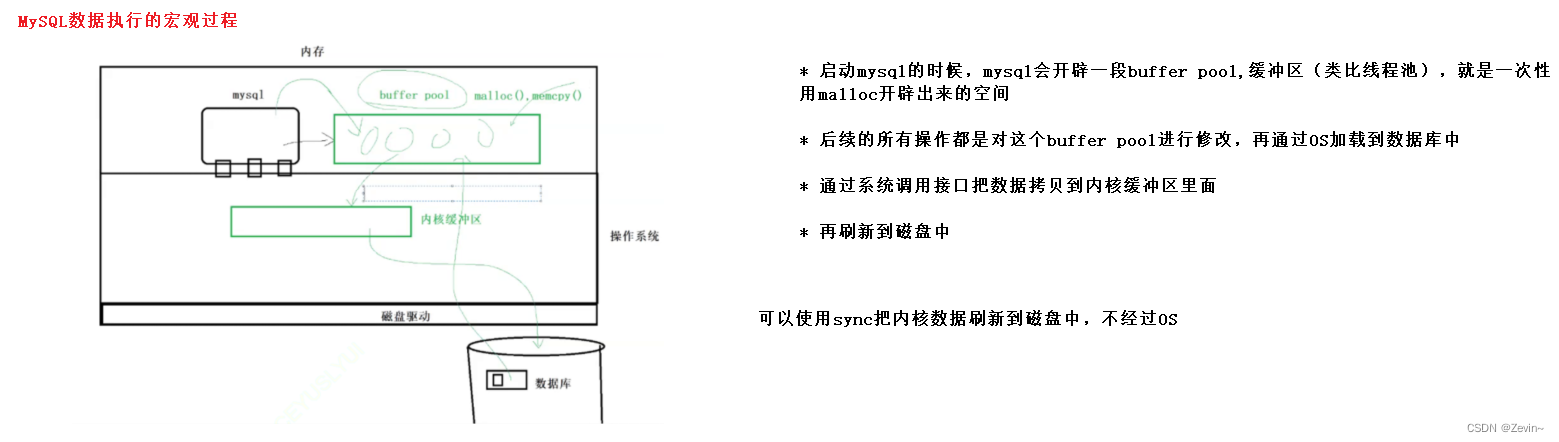
MySQL的工作过程
- mysql对数据做的CURD的操作,根据冯诺依曼体系,mysql是不可能直接去访问磁盘的
- 实际上数据库对数据做的所有访问,全部都是在内存中进行的,
- 如果数据有变化,再定期的把数据刷新到磁盘里面
- sync使用,使用这个系统调用,把内核数据刷新到磁盘里面,不经过OS
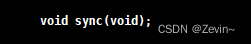
- 示例,添加索引前
我们插入了大量的数据,然后从里面进行查找数据,这样我们就会发现了查询的结果会查很久
- 查询员工号2=998877
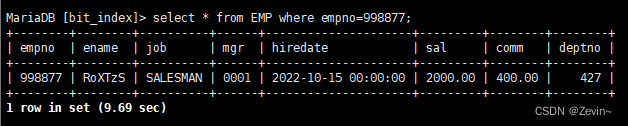

我们发现很慢,时间过了很久才能查询出来
- 示例,添加索引后
alter table EMP add index(empno);
我们在添加索引之后,发现查找的非常块,几乎每花什么时间
select * from EMP where empno=998877;

我们会发现搜索的时间不到一秒
认识磁盘
数据存储效率很低,路上还要有带宽限制,因为我们在传输数据的时候,不仅要在自己的磁盘中传送,还要在网络中进行跨网络传输
所有的数据都是基于LInux文件系统的
要找到一个文件的全部,本质上,就是在磁盘中找到所有保存文件的扇区
磁盘里面:磁头确认的是哪一个面,磁盘确认的是哪个圈,扇区来进行确认是哪一块区域,来定位到某一个扇区(CHS定位方案),磁盘使用的方案
磁盘的使用,使用的LBA,逻辑块地址(可以理解为虚拟地址和物理地址),这个是操作系统使用的方案
-
结论
我们已经能够在硬件层面上定位到对应的地址了,任何一个数据块(扇区),在系统软件上,直接按照扇区(512字节,会造成过度寻址,所以我们基本都是使用4096来进行寻址,4页) -
如果OS直接用硬件提供的数据大小进行交互,那么系统软件,
磁盘的交互都是使用4KB进行交互
连续磁盘访问
MySQL与磁盘交互的基本单位
MySQL作为一款软件,可以想象成一个特殊的文件系统,它有更高的IO 场景,为了提高效率,
- MySQL数据交互的基本单位:16KB
也就是说,磁盘这个硬件的基本单位是512字节,而MySQL使用16kb进行IO交互,即
MySQL和磁盘进行数据交互(通过OS)的基本单位是16KB,这个基本数据单位在mysql里面叫做page
如果它的基本单位和磁盘一样的话,万一磁盘的基本单位变了,它也要跟着变,兼容性不行
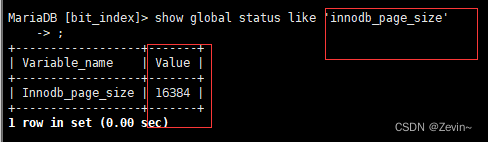
所以这里规定MySQL数据交互的基本单位是16KB=1page
建立共识
- MySQL中数据文件,一定是在磁盘当中的,以page为基本单位
- MySQL的CURD操作,都需要计算,找到对应的插入位置,或者找到对应要修改或者查询的数据
- 只要涉及计算,就要有CPU参与,为了cpu参与,一定把数据加载到内存,cpu只和内存打交道(根据需要把数据从外设掉到内存中,不是所有数据都加载进去)
- 所以在特定时间内,数据一定是在磁盘中有,内存中也有,后序操作完内存数据之后,以特定的刷新策略,刷新到磁盘里面,这个时候就涉及磁盘和内存数据的交互,此时基本单位就是page(即便只改一个字节,也要以16kb的大小来进行交互)
- 为何更高的效率,一定要减少系统和内存之间的IO请求次数
IO请求----系统中一定存在大量的IO 请求————操作系统一定也要管理这些IO请求
先描述再组织
struct request_io
{
char * start,*end;
pid_t id;
}
磁盘中,磁盘中一定是要对这些io请求进行管理的
struct disk
{
struct requestt_io* queue;//访问对应的磁盘,都有对应的对应进行保存起来
};
索引的理解
创建表
create table user(
-> id int primary key,--再id这个地方添加主键,建立了一个主键索引
-> age int not null,
-> name varchar(16) not null
-> );
我们这里是故意乱序的进行数据的插入
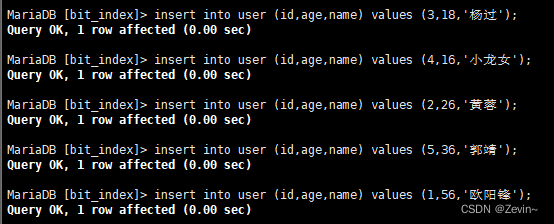
我们select之后,发现:查询的结果是按照主键顺序进行排序的
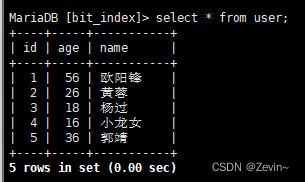
我们中断一下,排序的工作是由谁操作的,为什么要这样干呢?
为何IO交互要使用page?
每次交互都使用page(16 KB),这样一次可以预加载很多,可以充分利用局部性原理。1
单个page
为何MySQL和磁盘进行IO交互的时候,要采用page的方案进行交互,用多少,加载多少的方式不香吗?
如上面的5条数据,MySQL要查id=2,第一次加载,id=1,第二次加载id=2,一次一条数据,就要进行2次IO,如果要找id=5,就需要5次IO
但是如果5条数据都被保存再page里面(16kb能保存很多记录),第一次IO查找的时候,整个page就直接加载MySQL的buffer pool里面了,这里完成了一次IO,但是往后的id=1,3,4,5等,就不需要进行IO了,而是直接再内存里面进行了,大大减小了IO 的次数
你怎么保证,用户下次找的数据,就再这个page里面,我们不能保证,但是会由很大的概率,因为由局部性原理,往往IO 效率低下唉,最主要矛盾不是单次IO的数据量大小,而是IO 的次数
正式理解索引结构,一定会存在page结构体
- mysql会预先开辟一段空间来保留这些page
- MySQL在,任何一个时刻,一定会存在大量的page页,存在MySQL内部
- MySQL本身也要对page进行管理,也是要先描述再组织
struct page { struct page * prev;//指向前一个page struct page * next;//指向后一个page char buff(16kb-其他字段占用的大小); }对page的管理,就是对链表的管理
之后的操作都是再内存当中实现的
mysql插入数据时按照主键来进行排序,插入后,page里面就是有序的,查找的时候,就能优化查找算法,有序的就可以提高查找效率,如二分查找,方便我们进行查找
理解多个page
- 在page之间和page里面查找数据,都是基于链表的,线性遍历,一个遍历一遍,没找到,下一个继续遍历,效率非常的低,还是O(N)的方式进行遍历
页内目录
用目录查找,效率就很高,第一章是什么,在第几页,这样查找就很快,以空间换时间
先在一个page里面提高搜索效率,那么在所有page里面,效率也提高了很多
有了目录,就能一次淘汰很多数据,这样就会导致单页中数据减少,我们是先遍历数据目录,再去便利数据记录,这样提高的效率就很大,我们先遍历目录,
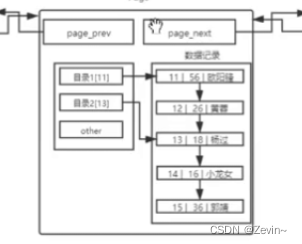
假如说数据500条,我们目录10条,这样就是只要遍历10次目录,遍历50次目录中对应的数据,大大减少了遍历的次数
- 所以有主键的时候,默认的进行排序,可以方便我们引入页内目录,方便查询
page之间也是线性的,怎么提高page之间的搜索效率
-
page内部的效率问题
-
page和page之间的效率问题!
多页情况
数据不断的插入新增,mysql很容易容量不足,所以就需要开辟一个新的page来保存数据,然后通过指针的方式,来将所有的page组织起来
问题
-
因为我们要保证一个整体有序,所以新来的数据,不会放在新的page里面,
-
这样我们就可以通过多个page的遍历,page内部用目录进行定位数据,可是这样也有效率问题,在page里面我们也需要用mysql进行遍历,这样就显得我们之前的page,有点没用了,我们查找一个数据,需要把前面的所有page遍历一遍,
解决方案
给我们的一个一个page也带上目录,
把每个page里面最小的记录,作为每个page的键值,这样page和page之间键值就不会重复了
在page里面中在开一个page,里面就只保存下面所管理的主键和指针,只保存一个一个目录
用一个page专门来保存page目录,和page对应的地址,一个page可以管理2000多个page
直接到顶层的page目录
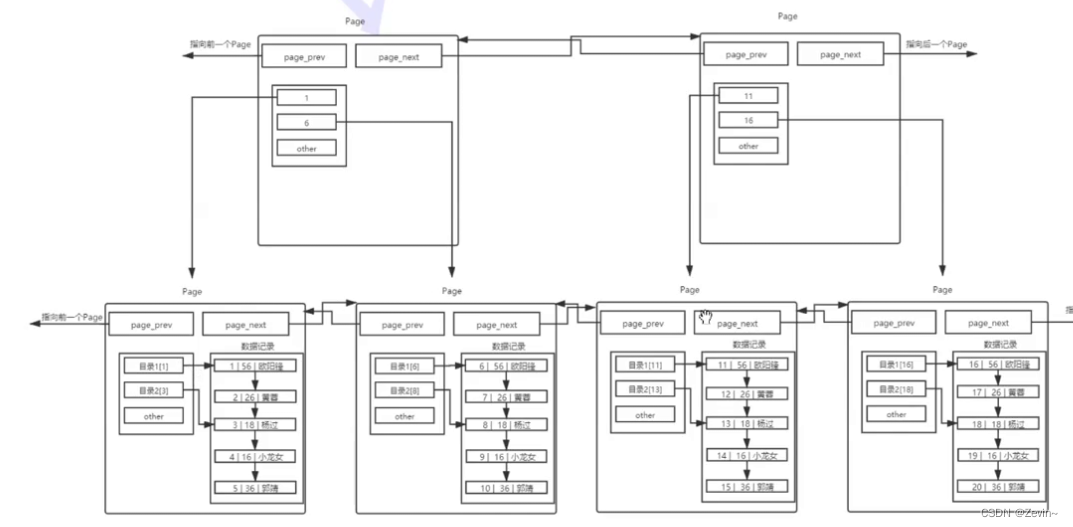
数据量很大的话,还要继续在中间增加page目录
相当于一个b+树,一个节点可以索引到很多地址,至此, 我们就已经可以给我们的表user构建完主键索引了
随便找一个id=?,我们发现,现在查找的page树一定减少了,说明我们IO次数也减少了,那么效率也高了
在page之间,和page内部都添加目录结构,这样就能构建一个b+树
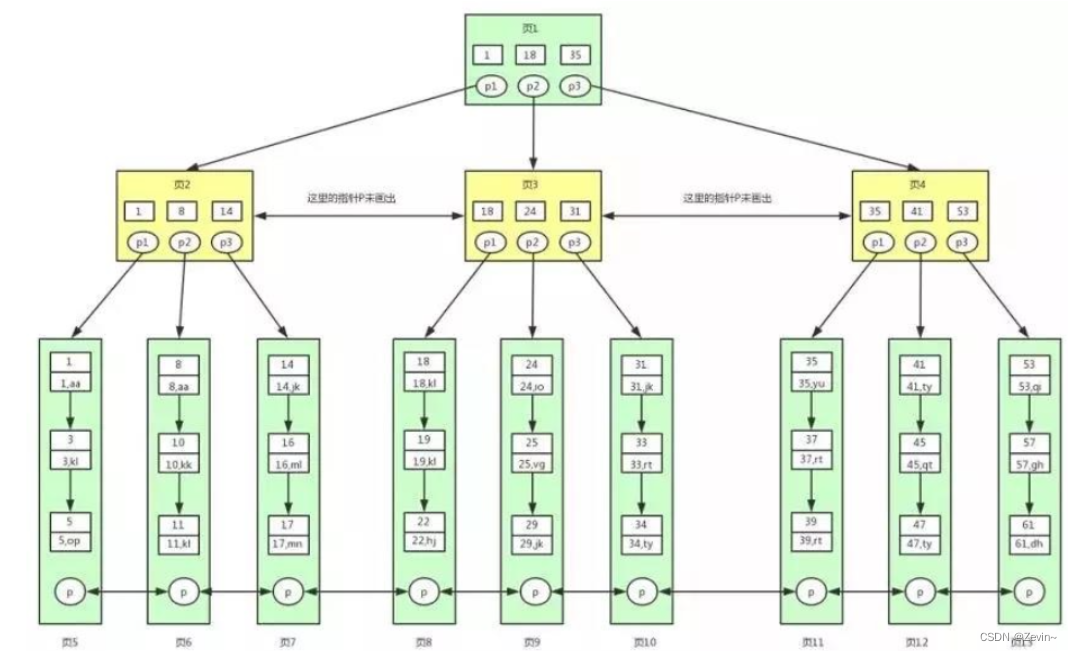
什么是主键索引
- 所有的数据最终都可以在磁盘中,也可以在mysql的buffer pool内存中
- 我们所有的数据,都必须要以page为单位进行IO,以page为单位组织
在MySQL内部,将热点数据,以B+树的形式将所有的page页进行组织,形成的数据结构与其配套的查找算法,叫做索引
添加索引,就给业内加目录,给顶层添加目录结构,方便对数据进行筛查
如果没有添加索引,所有的数据都是以链表的形式串联起来,数据没有做优化,没有排序,插入什么样就是什么样的,
有了b+树,每次从叶子节点中,进行搜索,一路找下去,就可以查找到对应的数据了
现在我们就不用加载很多数据到内存中,不需要查找的page就不需要加载到内存中了,我们需要哪个page加载哪个page即可,一路把我们查询过程中的路径page加载进去即可
只要我们把页目录加载进去之后,这些目录就常驻了,以后就不需要再加载到内存了,减少了IO的次数
但是其实目录页本来就没多少,所以可以直接都加载进来,
但是如果插入数据,删除数据的时候,会影响一下效率,因为会影响整个页目录的结构,
修改了一个数据,都要以整个page进行刷新到磁盘中
为什么只能是B+树
- 链表:线性遍历,效率太低
- 二叉树:可能会退化成线性结构
- AVL/RBtree:二叉树,相较于多阶B+树,意味着,整体的树比较高,需要系统与磁盘进行的IO page更多,而B+,矮胖的,层级低,数据量大,访问次数少
- Hash:有的索引就是基于Hash,但是Innodb,hash有的时候也能O(1),但是最大的问题,不能够支持区间性的范围查找,比如我们要查找(40,60),但是hash是乱序的,无法实现区域性哈希,但是b+树,只需要知道自己找40,到40里面查找即可
- B树,B+树下面的叶子节点都被链表连起来,这样page之间,都能够查找,跨范围,而且非叶子节点也会携带数据,增加的空间大小,逻辑上没有解耦
B+树
- 只有叶子节点有数据
- 叶子节点相连,非常便于进行范围查找
- IO次数较少

创建了一个索引,它就会创建一个文件叫.ibd,index_block_data,这个说明数据和索引合在一起的
把索引和数据都加载进去了
B+树在哪里
- 在磁盘上,有完整的B+和数据
- 在内存中有局部高频被访问的B+核心Page
- mysql查找一定会伴生着mysql进行根据B+进行page的换入换出!
同样,文件也是,内存中,一定是被打开的文件
聚簇索引vs非聚簇索引
非聚簇索引
:数据和索引分离
myisam的叶子节点不存储数据,只存储数据对应的地址,这样就能保存更多键值和索引关系,把数据放到对应的一个地方,用指针进行索引
把索引page和数据page进行分离,也就是叶子节点没有数据,只有对应数据的地址
聚簇索引
innodb就是聚簇索引
把数据和索引聚合在一起
辅助索引
MySQL除了会建立主键索引之外,还会建立按照其他列信息建立索引,一般这叫做辅助索引,其他字段也能建立索引
和主键索引没有差别,无非是主键不能重复,而非主键可以重复
主键就是叶子有地址,有索引
同样是构建b+树,innodb非主键索引中叶子节点保存对应地址的索引,但是没有保存数据,太浪费空间了,包含的是对应主键,再根据主键进行查询索引,回调索引,两边索引,先获得主键,再主键索引,获得索引的记录,
附上数据,太浪费空间了,会造成数据的冗余,但是myisam不需要进行回表,查询效率还是回更高一点,但是innodb支持事务,而mysiam不保证事务
下一次访问的数据,有很大概率会和上一次访问的数据重叠 ↩︎