知识图谱-生物信息学-医学论文(Chip-2022)-BCKG-基于临床指南的中国乳腺癌知识图谱的构建与应用
16.(2022)Chip-BCKG-基于临床指南的中国乳腺癌知识图谱的构建与应用
论文标题: Construction and Application of Chinese Breast Cancer Knowledge Graph Based on Clinical Guidelines
论文会议: Chip 2022
- 16.(2022)Chip-BCKG-基于临床指南的中国乳腺癌知识图谱的构建与应用
- 摘要
- 1.引言
- 2.相关工作
- 2.1 知识提取
- 2.2 医学KG
- 3.乳腺癌知识图谱构建
- 3.1 本体建模
- 3.2 知识提取
- 3.2.1 基于联合学习的文本指南知识提取
- 3.2.2 基于文本匹配的表格指南知识抽取
- 3.3 知识融合
摘要
知识图谱是医学智能的重要资源。普通医学知识图谱试图囊括所有疾病,包含大量医学知识。然而,人工评测所有的三元组是困难的,因此知识的准确性通常不能支持智能医疗应用。
乳腺癌是目前发病率最高的癌症之一。通过人工智能技术提高乳腺癌诊疗效率,改善乳腺癌患者术后健康状况迫在眉睫。针对这一需求,本文提出了一个基于临床指南构建乳腺癌KG的框架。
具体地说,从临床指南的文本和表格中提取三元组知识,并通过知识融合将不同指南的知识融合在一起,构建乳腺癌KG(BCKG)。实验结果表明,BCKG可以支持乳腺癌知识问答、乳腺癌术后随访和医疗保健,提高乳腺癌诊断、治疗和管理的质量和效率。
1.引言
2020年,世界卫生组织发布了癌症数据统计数据。新发乳腺癌人数首次超过肺癌,成为世界上最常见的癌症,占所有新发癌症患者的11.7%。乳腺癌也是中国发病率最高的癌症之一,特别是在北京、上海、广州、深圳等一线城市,乳腺癌发病率超过40‰,并以每年约5%的速度增长。从以上数据可以看出,乳腺癌已成为对人们生命健康的本质威胁。与肺癌不同,乳腺癌是一种可治愈的疾病,存活率较高。美国乳腺癌患者的五年生存率超过90%,而中国的乳腺癌患者五年生存率只有70%-80%。因此,中国在医疗、保险、健康管理等各个领域对乳腺癌的治疗都下了很大功夫。例如,中国国家卫生健康委员会2022年发布的《乳腺癌诊疗指南》旨在提高乳腺癌诊疗的标准化。保险公司开发了一些针对乳腺癌患者的保险产品,可以更好地解决乳腺癌治疗的费用问题。
乳腺癌的诊断和治疗依赖于专业的乳腺癌医学知识。例如,在营销乳腺癌保险产品时,保险代理人经常被要求回答患者提出的专业问题,如:Her2阳性、肿瘤大小为10mm×8mm×3mm的乳腺癌第一阶段是否可以投保?这份保险的保费是多少?等问题,代理人需要具备乳腺癌知识和保险知识。然而,医疗专业人才短缺是中国的普遍现象,如何通过智能化手段提高乳腺癌诊疗和健康管理质量,是亟待解决的问题。
专业疾病KG可以提高特定疾病知识的准确性和覆盖率,因此可以更好地支持临床决策、药物研发、基于知识的问答、智能营销等。英文版有比较完整的乳腺癌KG,包括乳腺癌知识和病历数据,对乳腺癌的诊断、健康管理和临床治疗具有重要价值。目前,缺乏中文乳腺癌相关的研究和KG,这限制了中国的人工智能技术在乳腺癌疾病领域的应用。
针对上述问题,本文提出了一种基于临床指南的乳腺癌KG构建方法,该方法能够从高质量的乳腺癌临床指南知识中提取知识,通过融合不同指南的知识来构建乳腺癌KG。具体地说,我们利用联合学习方法从临床指南的文本信息中提取实体和关系以形成三元组知识,并从临床指南的表中提取知识。最后,通过知识融合算法,将不同指南的知识进行融合,构建乳腺癌KG。实验结果表明,本文提出的方法可以从指南中提取高质量的三元组知识,形成乳腺癌KG。通过问答和智能随访的应用,实验结果表明,乳腺癌KG可以支持乳腺癌诊断、治疗和健康管理的智能化。本文的主要贡献有三个:
- 据我们所知,本文首先提出从临床指南构建中文乳腺癌KG,试图提高乳腺癌诊疗的效率和质量;
- 根据临床指南文本和表格数据的特点,采用两种不同的模型从临床指南中提取知识;
- 乳腺癌知识问答和术后随访的应用表明,乳腺癌KG可以支持乳腺癌的诊断、治疗服务等应用。
2.相关工作
本文主要研究乳腺癌指南中知识的提取,并通过知识融合构建KG。主要的相关工作包括知识提取和医学KG。这一部分将分别介绍主要的相关工作。
2.1 知识提取
知识是机器语义理解的重要基础,对实现高级人工智能具有重要意义,一直是NLP领域的研究热点。
在知识抽取中有三种类型的任务,包括命名实体识别、关系抽取和事件抽取。知识抽取方法基本上经历了三个阶段:(1)基于规则的知识抽取;(2)基于统计学习的知识抽取;(3)基于深度学习的知识抽取。近年来,随着深度学习和大规模预训练语言模型(PLM)的发展和广泛应用,PLM被广泛应用于命名实体识别和关系抽取等任务中。传统的方法将命名实体识别和关系提取建模为一个“流水线”任务,即首先识别文本中的命名实体,然后根据识别的实体对提取关系。
这种方法存在错误传播问题,不能利用关系信息来优化命名实体识别性能等。为了解决上述问题,研究人员提出了一种基于联合学习的命名实体识别和关系提取方法。该方法将名称、实体识别和关系抽取建模在同一任务和模型中。该模型利用命名实体信息进行关系识别,并利用关系信息对命名实体识别结果进行约束,以获得更好的知识抽取结果。近年来,事件抽取受到了研究人员和企业的广泛关注。传统的事件抽取方法试图通过不同的策略来抽取一个完整的事件结构,这些方法可以分为四类:(1)流水线分类法,(2)联合学习方法,(3)语义结构根基方法和(4)问答方法。
2.2 医学KG
KG以结构化的形式描述世界上的概念、实体及其相互关系,便于人类和机器的理解,降低了知识应用的难度。谷歌在2012年提出了KG,KG受到了产业界和学术界的广泛关注,并在信息检索、问答、语义理解、智慧医疗等领域发挥了至关重要的作用。KG通常分为通用KG和领域KG。通用KG涵盖了各个领域的知识,而且知识的规模通常非常大,通过自动抽取或协同收集的方式生成。NELL是一个典型的基于自动提取方法构建的KG。它不断地从互联网上抓取文本,并通过名称实体识别和关系提取从文本中提取知识。 Wikipedia是从维基百科中提取的大规模KG。通用KG具有覆盖面广、覆盖面广的特点,但人工复核难度大。因此,由于医学领域对知识的准确性要求很高,KG的准确率会很低,这不能支持医学领域的智能化。
相反,领域KG聚焦于特定领域,例如金融KG、法律KG、诗歌KG和医学KG。领域KG通常只覆盖特定领域的知识,知识的规模比通用KG要小,但该领域的KG的准确度和覆盖率会更好。OpenKG已经发布了多个中文领域的KG,涉及医疗、出行、金融、法律等领域。
现在已经发布了几个医学KG。例如,清华IDEA实验室发布了从PubMed文献中提取的大规模医学KG。Omaha发布了基于临床数据的医学KG,鹏城实验室发布了中国医学KG–Cmekg。然而,这些KG试图涵盖所有疾病知识。由于医学的复杂性,现有的医学KG所涵盖的知识仍然非常有限。例如,在Cmekg中只有一个实体“乳腺癌”属于乳腺癌类别。然而,通过我们对乳腺癌疾病的回顾,乳腺癌涵盖了700多种疾病,如“扩散型乳腺癌”、“乳房上腹恶性肿瘤”等,这些疾病都属于乳腺癌的范畴。根据专科疾病的复杂性和医学特点,专科疾病KG已成为当前研究的热点。KGBC构建了一个包含乳腺癌知识和病历信息的英文乳腺癌知识库。目前,中国还缺乏相关工作。本文尝试基于深度学习知识抽取技术构建中文乳腺癌KG。
3.乳腺癌知识图谱构建
本文试图从临床指南出发,构建高质量的乳腺癌知识图谱。乳腺癌知识图谱的构建分为三个阶段:
- 乳腺癌知识图谱的本体建模;
- 从临床指南中提取知识;
- 知识融合:融合来自不同指南的知识三元组,构建乳腺癌知识图谱。
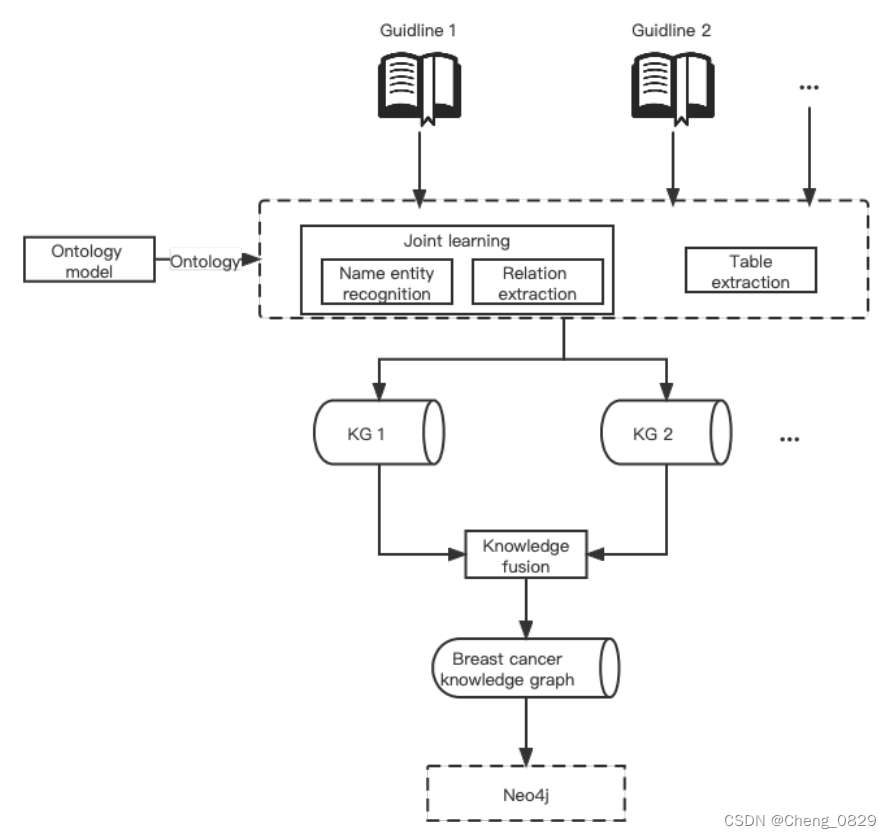
图1:算法结构
3.1 本体建模
本体是知识图的模式,用来确定知识图中涉及的实体类型和关系类型,这通常由领域专家和知识图专家共同确定。我们邀请中国医学科学院肿瘤医院的乳腺癌专家参与乳腺癌本体的建设,该本体包括28个大类实体,如临床发现、外科手术、检查和标本。也有实体类型的子类,例如,“检查”实体还包括“影像检查”、“实验室检查”、“病理检查”、“内窥镜检查”等6类实体。实体通过关系联系在一起,例如,疾病和确诊通过关系影像检查联系起来,形成(疾病、影像检查、确诊)三元组。除了关系之外,实体还包含一些属性信息,比如疾病通常都有这样的属性:(乳腺癌,它是可遗传的,True)。
本文使用Protege作为本体建模工具,本体结构如图2所示。
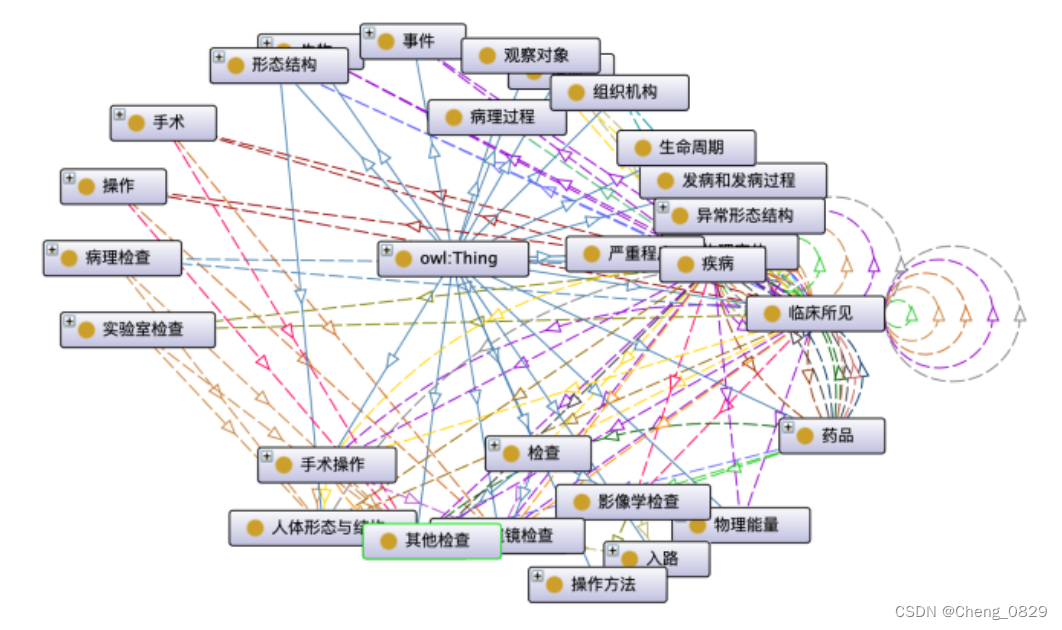
图2:中国乳腺癌KG本体。正方形表示实体类型,正方形上的+号表示该实体类型中有子类实体类型,连接线表示实体之间的关系。
3.2 知识提取
基于上述乳腺癌知识图谱本体,我们从临床指南中提取知识三元组。三元组包含三个部分:头部实体、关系和尾部实体,如(乳腺癌,症状,乳房疼痛),其中“乳腺癌”是头部实体,“症状”是关系,“乳房疼痛”是尾部实体。
为了从临床指南中提取三元组,模型需要提取实体和关系。传统的知识抽取方法将三元组抽取建模为一个流水线:(1)该模型首先识别文本中的实体,(2)然后提取每个候选实体对的关系。临床指南的写作风格不同于其他文本,指南中包含大量知识的信息有两类:一类是文本信息,包括大量的实体及其关系,如图3(a)所示;另一类是表格数据,其中临床指南以表格形式总结了许多基本知识,如图3(b)所示。因此,我们试图从临床指南的文本和表格信息中提取知识。

图3:不同类型的临床指南。
本部分将详细描述从临床指南的文本信息和表格信息中提取知识的方法。
3.2.1 基于联合学习的文本指南知识提取
临床指南中有大量的文本信息,如图3(a)所示,传统的知识抽取方法首先在文本中进行名称实体识别,然后对每个实体对进行关系提取。这种流水线方法存在错误传播问题,即当命名实体识别模型不能正确识别文本中的实体时,后续的关系提取结果必然是错误的。
为了解决这种错误传播问题,研究人员提出了一种基于联合学习的知识提取框架,该框架同时进行实体识别和关系提取,如图4所示。
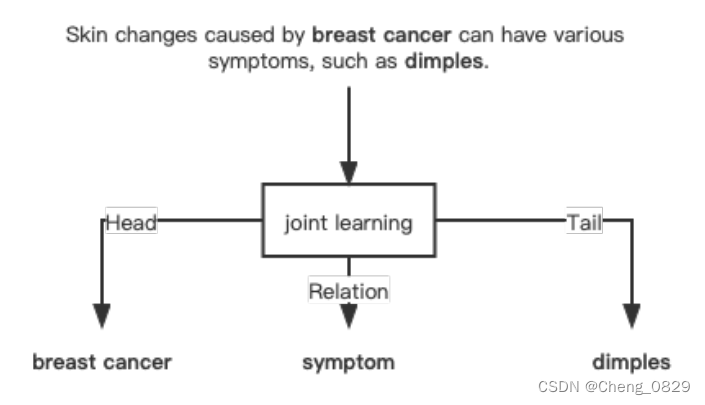
图4:联合学习。
将命名实体识别和关系提取建模为联合学习后,利用提取的关系信息对实体识别结果进行优化。例如,如果头/尾实体的类型与关系类型不匹配,则提取的三元组更有可能是错误的。因此,可以利用关系抽取的结果来优化命名实体识别的结果,从而提高知识抽取的整体性能。有许多用于三元组知识提取的联合学习模型。根据临床指南的特点,将命名实体识别和关系提取建模为标记对分类任务(TPC)。我们将用一个具体的例子来描述TPC,如图5所示,临床指南中的文本 “紫杉醇可以治疗乳腺癌”。我们将句子建模为M个n×n矩阵,其中n是句子中的字符数量,M是关系的数量。每个矩阵代表一个关系,矩阵中的n×n个单元格分别表示该关系中是否存在实体信息。矩阵中的单元格有四个标签,用于定位实体在文本中的位置,标签的对应含义为:
- (1) “-”表示该单元格中没有实体开始/结束信息;
- (2) “HB-TB”表示头部实体的开始字符;
- (3) “HE-TB”表示头部实体的结束字符和尾部实体的开始字符;
- (4) “HE-TE”表示尾部实体的结束字符。
从标签“HB-TB”开始到结束于标签“HE-TB”的字符串是头部实体,如图5中的“紫杉醇”;纵坐标以“HE-TB”开头,以“HE-TE”为结尾的是尾实体,如图5中的“乳腺癌”,该矩阵的对应关系为“治疗药物”。根据头部实体和尾部实体的类型,将两个实体的位置颠倒,从而可以提取三元组(乳腺癌、治疗药物、紫杉醇)。
我们设计的联合学习模型的功能就是用BERT和Bi-LSTM把文本输出成“HB-TB”等4类标签标识的字符串,进而可以识别实体和关系,提取三元组。
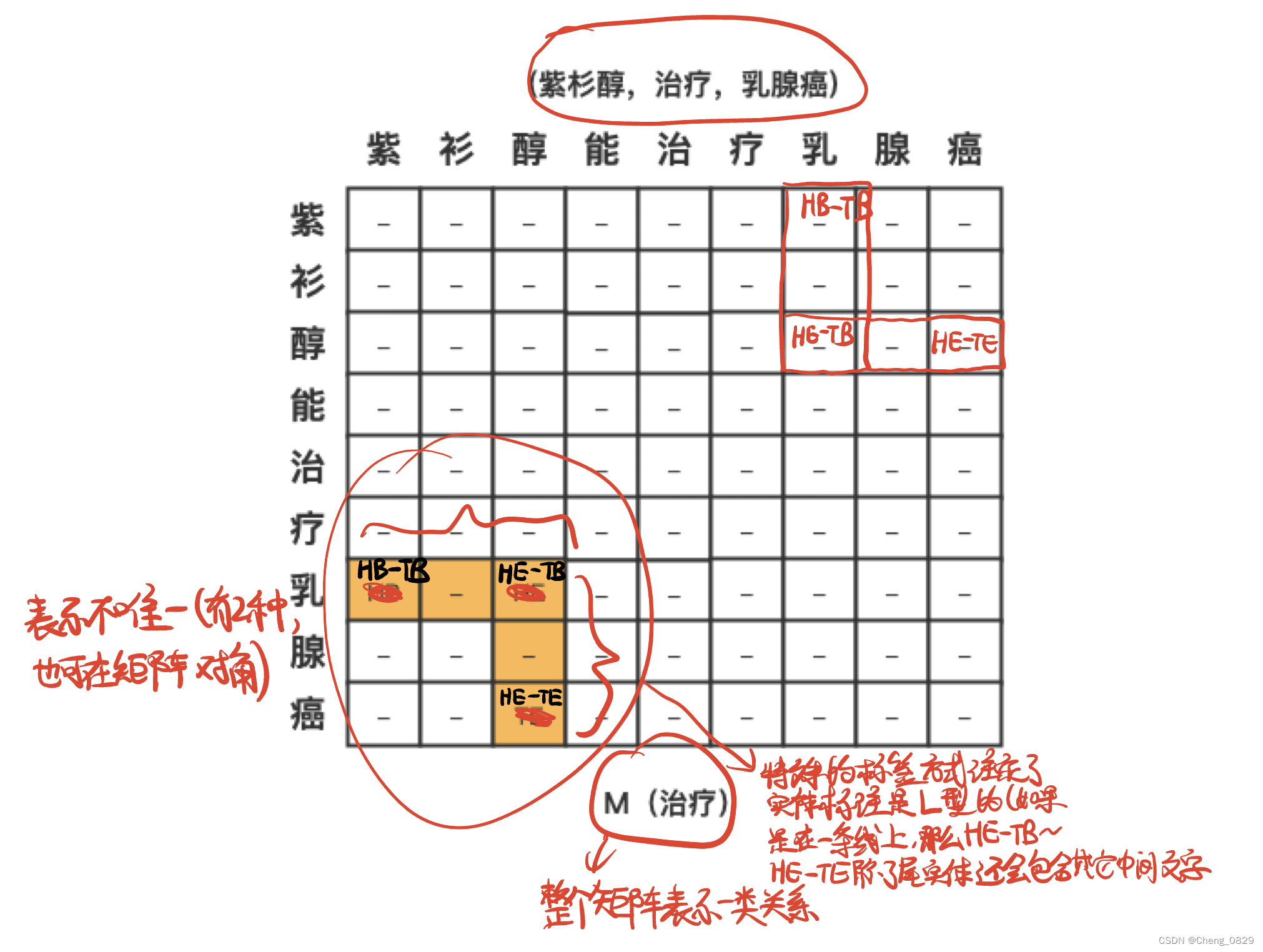
图5:联合学习矩阵示意图
具体来说,本文基于BERT学习token的表示,采用BiLSTM对token的上下文信息进行建模,然后使用全连接层(FCL)把每个标记分为四类。模型的整体架构如图6所示。
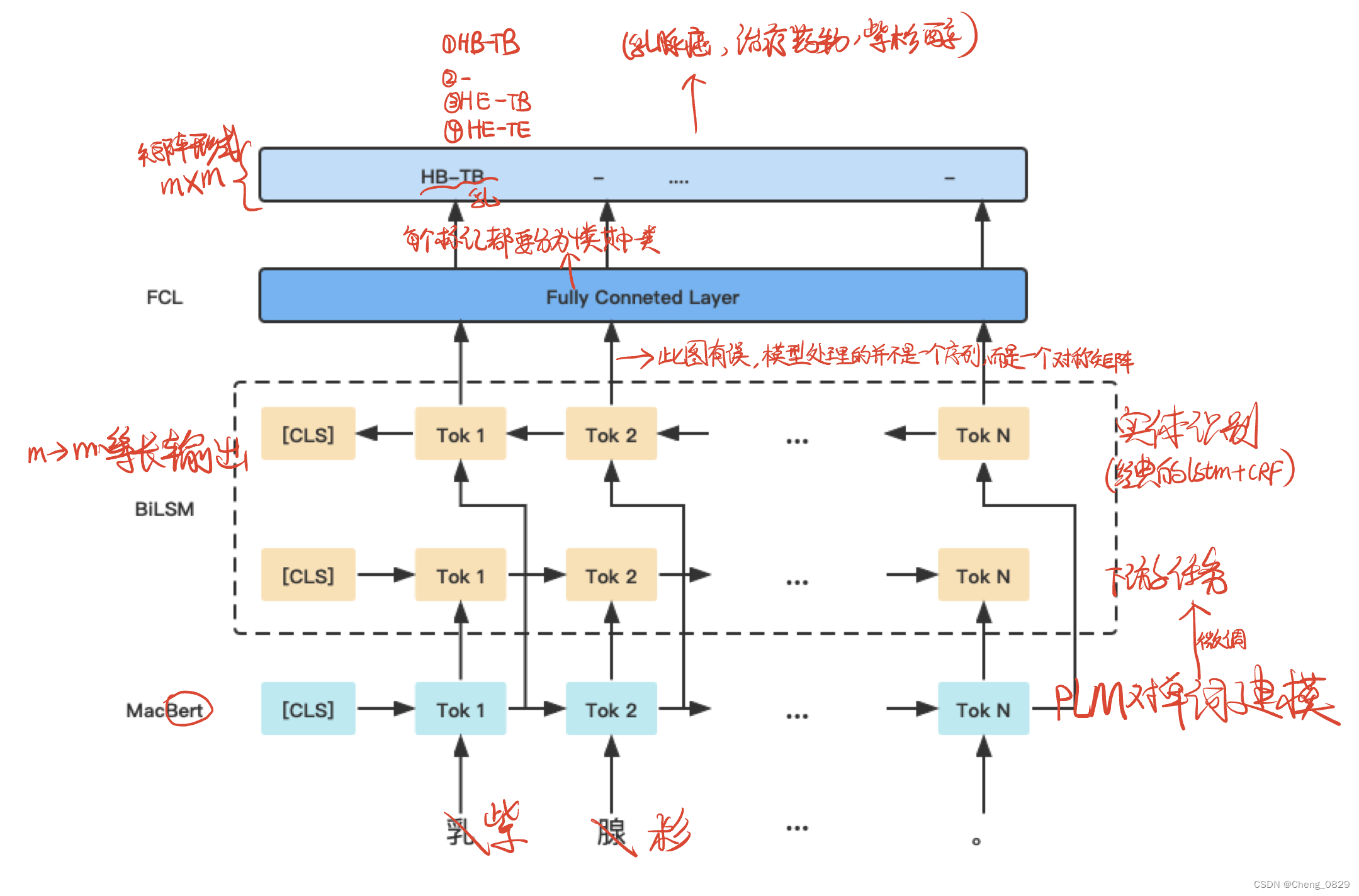
图6:联合学习框架
3.2.2 基于文本匹配的表格指南知识抽取
临床指南通常包含很多表格。这些表格浓缩了专家的医学知识,对疾病的诊断和治疗具有重要价值。表1是乳腺癌临床指南中的示例表数据。该表包含了诊断早期乳腺癌所需的检查。该表主要包括标题和表内容两部分。标题通常包含重要的实体和关系信息,如标题“早期乳腺癌诊断检查”中包含实体“早期乳腺癌”和关系“诊断检查”,后者决定了表知识的范围和要提取的实体类型(检查类型的实体)。表内容通常包含多个实体,与标题的实体和关系形成三元组。例如,可以从表1中提取(早期乳腺癌、诊断检查、体检)、(早期乳腺癌、诊断检查、双侧乳房X光检查)等知识。如上所述,表数据的提取主要涉及命名实体识别和关系识别。
与上述联合抽取任务不同,表格标题只包含一个实体和关系,同时与表内容中的多个实体建立关系。因此,本文将表格知识抽取建模为标题实体抽取、关系识别、表格内容实体抽取。从表内容中提取的所有实体都由三元组组成,分别带有标题实体和关系。因此,表格提取主要涉及实体识别和关系识别两个任务。具体而言,在实体识别方面,本文利用BERT+BiLSTM+CRF进行实体识别,提取表头实体信息作为三元组头实体,将表格内容中的实体识别为候选尾实体。
在关系分类方面,由于缺乏大规模的有监督的训练数据,我们将关系分类建模为一个文本匹配问题,并使用BERT+ESIM模型计算标题文本与所有关系名称之间的相似度,从而获得相似度,相似度最高的关系被视为目标关系。其中,BERT可以学习单词的上下文相关表示,ESIM计算两个文本的相似度,它使用注意力机制来计算句子中单词之间的相关性,从而提高了文本相似度的性能。
简单来说,用BERT+BiLSTM+CRF进行表格标题和内容的实体识别,分别用作三元组头尾实体,使用BERT+ESIM模型计算标题文本与所有关系名称之间的相似度,选出最相似的关系。
ESIM:增强序列推导模型=BiLSTM+Attention,常用于文本匹配,即判断两段文本是否有某种关系。

表1:早期乳腺癌的诊断检查。
3.3 知识融合
知识融合是将来自不同来源的知识融合在一起,形成一个更大规模的知识图谱。知识融合可以分为两个层次:本体融合和实体融合。本体融合是指当不同的知识图谱具有不同的本体结构时,需要在本体层面上对齐。本文采用统一的本体结构,从不同的疾病指南中抽取三元组知识,不涉及本体融合。
实体融合试图在不同的知识图谱中为同一实体的概念对齐不同的名称,如“导管原位癌”和“非浸润性乳腺癌”指的是同一种疾病,但不同的临床指南中的名称是不同的。实体层面的融合术,如“导管原位癌”和“非浸润性乳腺癌”指的是同一种疾病,但名称不同,需要对齐,成为医学领域的标准术语。
具体而言,本文以《疾病分类与编码国家临床2.0版》作为疾病标准术语库,将不同指南中提取的实体映射到标准术语库中。在医学术语规范化任务中存在三个挑战:
- 标准库规模庞大:《国家临床版疾病分类与编码2.0版》包含约4万个疾病术语,外加10万多个检查和药物标准术语;
- 字面上相似的实体可能存在不同语义:医学术语中存在大量字面上相似但不相同的实体。例如,“副乳腺癌”和“左乳腺癌”的文本相似度为0.8,但“副乳腺癌”甚至不是乳腺癌,因此描述的是完全不同的实体;
- 同一实体的名称可以有很大差异:还有大量实体在医学术语中具有完全不同但语义相同的实体,例如“老年痴呆症”和“阿尔兹海默症”是相同的疾病,但字面上完全不同。
针对医疗实体名称的这些特点,提出了一种三阶段实体解析算法(Three Stage Entity Resolve, TSER)。总体框架如图8所示,主要包括三个部分:候选词召回、核心词提取、语义相似度计算。
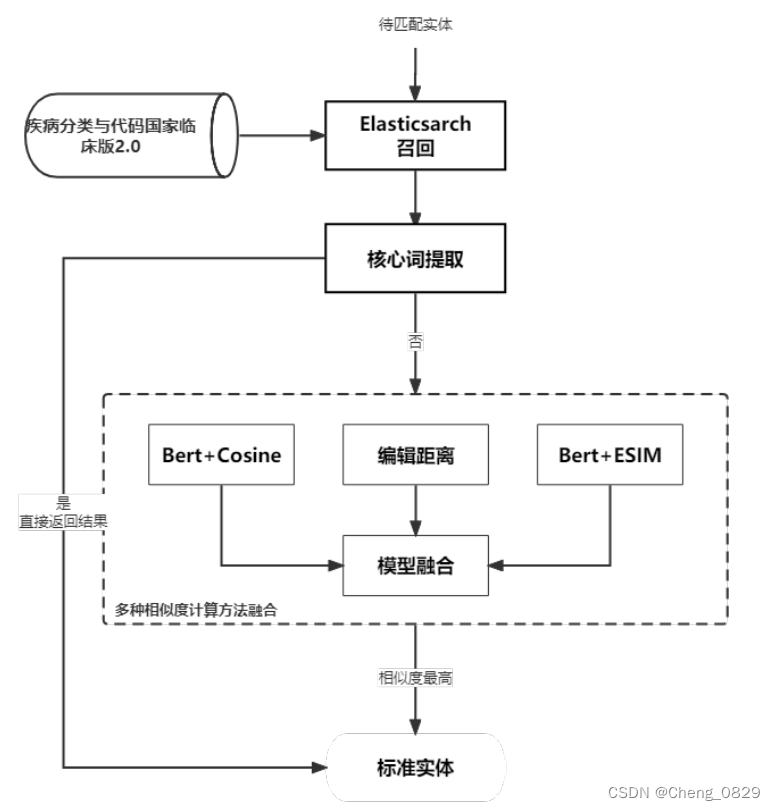
图8:知识融合框架。
- 第一阶段是实体召回:基于搜索引擎(Elasticearch)进行基于TF-IDF的文本匹配,从标准库中返回前100个候选实体。这一阶段可以显著提高实体融合的速度来应对挑战1(标准库规模庞大) 。
- 第二阶段是核心词提取:医学术语通常由多个部分组成,如疾病词“左乳原位癌”,包括方位词“左侧”、身体词“乳房”、属性词“原位”和疾病词“癌症”。不同类型的词对术语的重要性程度不同,其中疾病词、身体词和属性词的重要性更大。因此,本文基于构件词典对术语进行拆分,然后为不同的构件赋予不同的权重。这个阶段通过区分不同的疾病词如“浸润性乳腺癌”和“浸润性胰腺癌”核心以及部位词“乳房”和“胰腺”来应对挑战2(字面上相似的实体可能存在不同语义)。
- 第三阶段是语义匹配:该阶段基于上述召回和核心词提取模块,在核心词拆分后获取候选词,然后使用各种语义相似度计算方法,包括基于文本距离的算法(字面相似度)、基于独立表示学习的相似度计算方法(BERT+Cosine)和基于交互表示学习的相似度计算方法(BERT+ESIM),其中BERT+Cosine和BERT+ESIM主要从语义层面而非文字表面进行相似度计算以应对挑战3(同一实体的名称可以有很大差异)。
- 最后通过公式(2)对上述三种相似度进行融合,得到最终的相似度,然后根据相似度进行排序。其中, w 1 w_1 w1、 w 2 w_2 w2和 w 3 w_3 w3是可学习参数,它们的值是通过模型训练学习的。
s i m = w 1 ∗ s i m e d i t + w 2 ∗ s i m c o s + w 3 ∗ s i m e s i m (2) sim=w_1*sim_{edit}+w_2*sim_{cos}+w_3*sim_{esim} \tag{2} sim=w1∗simedit+w2∗simcos+w3∗simesim(2)