【Transformers】第 4 章:自回归和其他语言模型
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
技术要求
使用 AR 语言模型
使用 GPT 介绍和训练模型
原始 GPT 的继任者
Transformer-XL
XLNet
使用 Seq2Seq 模型
T5
介绍 BART
AR语言模型训练
使用 AR 模型的 NLG
使用 simpletransformers 进行汇总和 MT 微调
概括
我们在第 3 章“自动编码语言模型”中查看了自动编码器( AE ) 语言模型的详细信息,并研究了如何从头开始训练 AE 语言模型。在当前章节中,您将看到自回归( AR ) 语言模型的理论细节,并学习如何在您自己的语料库上对它们进行预训练。您将学习如何在您自己的文本上预训练任何语言模型,例如Generated Pre-trained Transformer 2 ( GPT-2 ),并将其用于各种任务,例如自然语言生成( NLG )。您将了解 A 的基础知识文本到文本传输转换器( T5 ) 模型并在您自己的机器翻译( MT ) 数据上训练多语言 T5 ( mT5 ) 模型。完成本章后,您将大致了解 AR 语言模型及其在text2text应用程序中的各种用例,例如摘要、释义和机器翻译。
本章将涵盖以下主题:
- 使用 AR 语言模型
- 使用序列到序列( Seq2Seq ) 模型
- AR语言模型训练
- 使用 AR 模型的 NLG
- 使用simpletransformers进行汇总和 MT 微调
技术要求
成功完成本章需要以下库/包:
- Anaconda
- transformers 4.0.0
- pytorch 1.0.2
- tensorflow 2.4.0
- datasets 1.4.1
- tokenizers
- simpletransformers 0.61
使用 AR 语言模型
变压器架构最初旨在对 Seq2Seq 任务(例如 MT 或摘要)有效,但此后它已被用于各种 NLP 问题,从令牌分类到共指解析。随后的作品开始分别并更有创意地使用建筑的左右部分。这客观的,也被称为去噪目标,是以双向方式从损坏的输入中完全恢复原始输入,如图 4.1左侧所示,您将很快看到。从 Transformers ( BERT ) 架构的双向编码器表示中可以看出,这是 AE 模型的一个显着示例,它们可以结合单词两边的上下文。然而,第一个问题是在预训练阶段使用的破坏性[MASK]符号在微调阶段的数据中不存在,导致预训练-微调差异。其次,BERT 模型可以说是假设被掩码的标记是相互独立的。
另一方面,AR 模型远离这种关于独立性的假设,并且自然不会受到训练前微调差异的影响,因为它们依赖于目标预测下一个以先前标记为条件的标记而不掩盖它们。他们只是利用变压器的解码器部分蒙面的自注意力。它们阻止模型以正向访问当前单词右侧的单词(或反向访问当前单词左侧的单词),这称为单向性。他们也是由于其单向性,因此称为因果语言模型( CLM )。
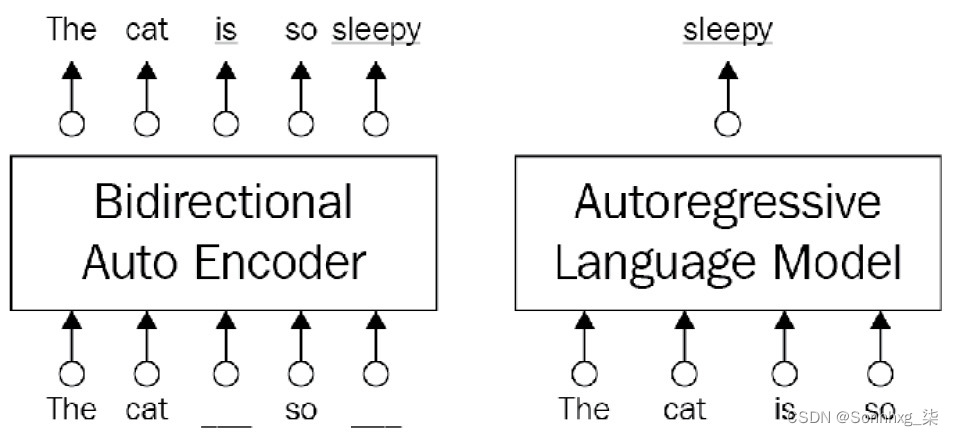
图 4.1 – AE 与 AR 语言模型
GPT 及其两个继任者(GPT-2、GPT-3)Transformer-XL和XLNet是当今流行的 AR 模型。文学。甚至尽管 XLNet 基于自回归,但它以某种方式设法在基于排列的语言目标的帮助下以双向方式利用了单词的两个上下文方面。现在,我们开始介绍它们并展示如何通过各种实验来训练模型。让我们先看看 GPT。
使用 GPT 介绍和训练模型
AR 模型由多个变压器块组成。每个块都包含一个带掩码的多头自注意力层以及一个逐点前馈层。最终转换器块中的激活被输入到 softmax 函数中,该函数在整个单词词汇表上产生单词概率分布,以预测下一个单词。
在原始 GPT 中在通过生成式预训练提高语言理解(2018) 的论文中,作者解决了传统基于机器学习( ML ) 的自然语言处理( NLP ) 的几个瓶颈) 管道受。例如,这些管道首先需要大量的特定于任务的数据和特定于任务的架构。其次,很难在对预训练模型的架构进行最小更改的情况下应用任务感知输入转换。由 OpenAI 团队设计的原始 GPT 及其继任者(GPT-2 和 GPT-3)专注于缓解这些瓶颈的解决方案。原始 GPT 研究的主要贡献在于,预训练模型取得了令人满意的结果,不仅适用于单一任务,而且适用于多种任务。从未标记的数据中学习生成模型,这称为无监督预训练,模型通过相对少量的任务特定数据简单地微调到下游任务,称为监督微调. 这个两阶段方案广泛用于其他变压器模型,其中无监督预训练之后是监督微调。
保留 GPT架构尽可能通用,只有输入被转换为特定于任务的方式,而整个架构几乎保持不变。这种遍历式的方法根据任务将文本输入转换为有序序列,以便预训练模型可以从中理解任务。图 4.2的左侧部分(受原始论文的启发)说明了原始 GPT 工作中使用的变压器架构和训练目标。右侧部分显示了如何转换输入以在多个任务上进行微调。
简单来说,对于文本分类等单序列任务,输入按原样通过网络,线性层采用最后的激活来做出决策。对于文本蕴涵等句子对任务,由两个序列组成的输入用分隔符标记,如图 4.2中的第二个示例所示。在这两种情况下,架构都看到统一的令牌序列由预训练的模型处理。此转换中使用的分隔符有助于预训练模型在文本蕴涵的情况下知道哪个部分是前提或假设。由于输入转换,我们不必跨任务对架构进行实质性更改。
您可以在此处看到输入转换的表示:
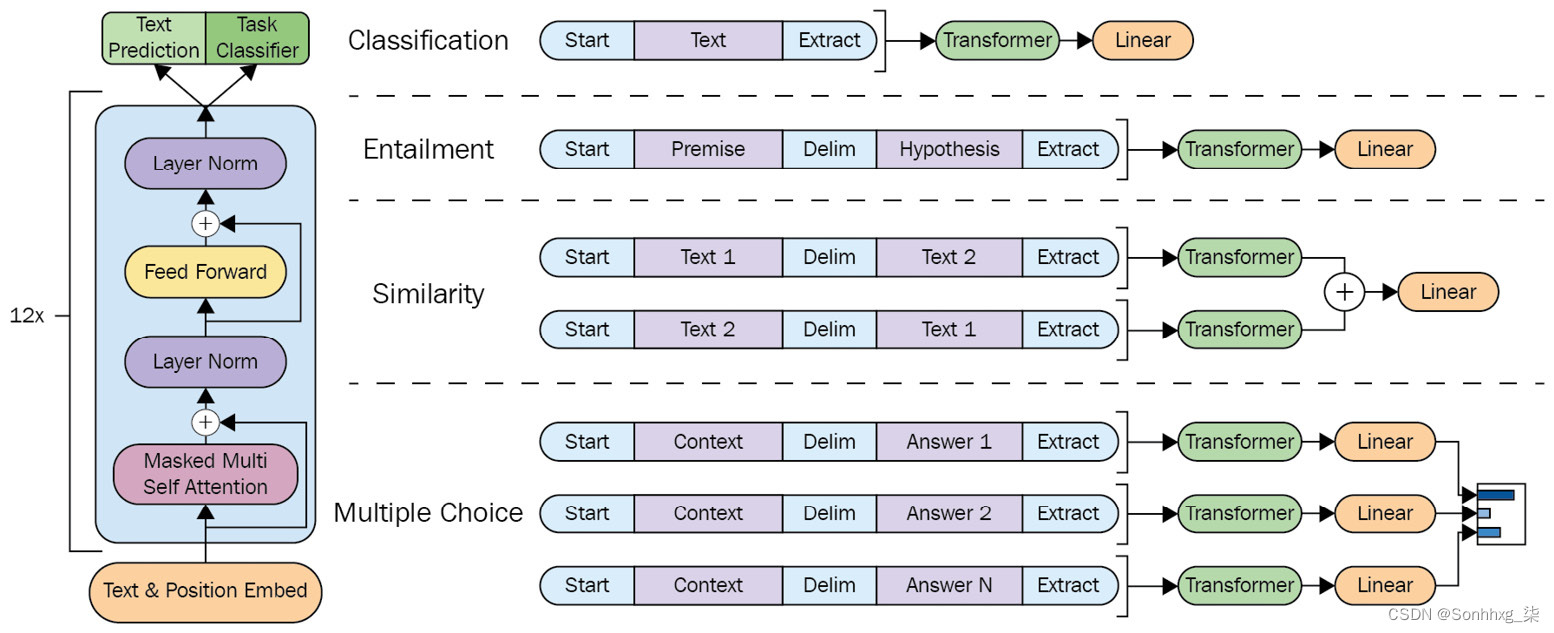
图 4.2 – 输入转换(受论文启发)
GPT 及其两位继任者主要专注于寻求不需要微调阶段的特定建筑设计。它基于这样一种想法,即模型可以非常熟练,因为它可以在预训练阶段学习有关语言的大部分信息,而在微调阶段几乎没有工作。因此,微调过程可以在三个时期内完成,并且大多数任务的示例相对较少。在极端情况下,零样本学习旨在禁用微调阶段。基本思想是该模型可以在预训练期间学习有关语言的大量信息。对于所有基于变压器的模型尤其如此。
原始 GPT 的继任者
GPT-2(参见论文Language Models are Unsupervised Multitask Learners (2019)),继任者原始 GPT-1 是一个更大的模型,它使用比原始模型更多的训练数据(称为 WebText)进行训练。它在其中七项中取得了最先进的结果零样本设置中的八项任务,其中没有应用微调,但在某些任务中取得的成功有限。它在用于测量长期依赖的较小数据集上取得了可比的结果。GPT-2 作者认为语言模型不一定需要明确的监督来学习任务。相反,他们可以在对庞大而多样的网页数据集进行训练时学习这些任务。它被认为是一个通用系统,将原始 GPT 中的学习目标P(output|input)替换为P(output|input, task-i),其中模型为相同的输入产生不同的输出,以特定任务为条件——也就是说,GPT-2 通过训练相同的无监督模型来学习多个任务。一个单一的预训练模型仅通过学习目标来学习不同的能力。我们在其他研究中也看到了多任务和元任务设置中的类似公式。这种向多任务学习( MTL ) 的转变使得为相同的输入执行许多不同的任务成为可能。但模型如何确定要执行的任务?他们通过零样本任务转移来做到这一点。
与原版相比GPT、GPT-2 没有针对特定任务的微调,并且能够在零样本任务转移设置中工作,其中所有下游任务都是预测条件概率的一部分。该任务以某种方式在输入中制定,并且该模型有望了解下游任务的性质并相应地提供答案。例如,对于英语到土耳其语的 MT 任务,它不仅取决于输入,还取决于任务。输入被安排成一个英语句子后跟一个土耳其语句子,并带有一个分隔符,模型从中可以理解该任务是英语到土耳其语的翻译。
OpenAI 团队训练了 GPT-3具有 1750 亿个参数的模型(参见论文Language models are little-shot learningers (2020)),比 GPT-2 大 100 倍。GPT-2 和 GPT-3 的架构相似,主要区别通常在于模型大小和数据集数量/质量。由于数据集中的海量数据和训练的大量参数,它在零样本、单样本和少样本 ( K=32 ) 设置下的许多下游任务上取得了更好的结果,无需任何基于梯度的微调。该团队表明,对于许多任务,包括翻译、问答( QA ) 和掩码任务,模型性能随着参数大小和示例数量的增加而提高。
Transformer-XL
变压器型号尽管它们能够学习长期依赖,但由于初始设计和上下文碎片缺乏重复性而遭受固定长度上下文的困扰。大多数转换器将文档分解为固定长度(大多数为 512)段的列表,其中任何信息都无法跨段流动。因此,语言模型无法捕获超出此固定长度限制的长期依赖关系。此外,分割过程在不关注句子边界的情况下构建片段。一个句段可以荒谬地由句子的后半部分和其后继词的前半部分组成,因此语言模型在预测下一个标记时可能会错过必要的上下文信息。这个问题被称为上下文碎片研究的问题。
为了解决和克服这些问题,Transformer-XL 作者(参见论文Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context (2019))提出了一种新的转换器架构,包括分段级递归机制和新的位置编码方案。这种方法启发了许多后续模型。它不限于两个连续的片段,因为有效上下文可以延伸到两个片段之外。递归机制在每两个连续的段之间起作用,导致在一定程度上跨越几个段。模型可以参与的最大可能依赖长度受层数和段长度的限制。
XLNet
蒙面语言建模( MLM ) 占主导地位基于transformer的预训练阶段架构。然而,它在过去受到了批评,因为掩码标记存在于预训练阶段但在微调阶段不存在,这导致预训练和微调之间存在差异。由于这种缺失,模型可能无法使用在预训练阶段学到的所有信息。XLNet(参见论文XLNet:Generalized Autoregressive Pretraining for Language Understanding (2019))取代了 MLM使用置换语言建模( PLM ),它是输入标记的随机排列,以克服这个瓶颈。置换语言建模使每个标记位置利用来自所有位置的上下文信息,从而捕获双向上下文。目标函数仅置换分解顺序并定义标记预测的顺序,但不改变序列的自然位置。简而言之,该模型在置换后选择一些标记作为目标,并进一步尝试以剩余的标记和目标的自然位置为条件来预测它们。它使得以双向方式使用 AR 模型成为可能。
XLNet 同时利用了 AE 和 AR 模型。它确实是一个广义的 AR 模型;然而,由于基于排列的语言建模,它可以处理左右上下文中的标记。除了其目标函数外,XLNet 还由两个重要机制组成:它将 Transformer-XL 的分段级递归机制集成到其框架中,并包括针对目标感知表示的双流注意机制的精心设计。
让我们讨论模型,在下一节中使用 Transformer 的两个部分。
使用 Seq2Seq 模型
左编码器和右编码器转换器的解码器部分通过交叉注意力连接,这有助于每个解码器层参与最终的编码器层。这自然会推动模型产生与原始输入密切相关的输出。Seq2Seq 模型,即原始转换器,通过使用以下方案实现了这一点:
输入令牌->嵌入->编码器->解码器->输出令牌
Seq2Seq 模型保持变压器的编码器和解码器部分。T5、双向和自回归变压器( BART ) 以及用于抽象摘要序列到序列模型( PEGASUS ) 的提取间隔句的预训练(PEGASUS)流行的 Seq2Seq 模型。
T5
大多数 NLP 架构,范围从 Word2Vec 到转换器,通过使用上下文(相邻)词预测掩码词来学习嵌入和其他参数。我们将 NLP 问题视为单词预测问题。一些研究将几乎所有 NLP 问题都视为 QA 或令牌分类。同样,T5(参见论文Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (2019))提出了一个统一框架,通过将许多任务转换为文本到文本问题来解决许多任务。T5 的基本思想是将所有 NLP 任务转换为文本到文本 (Seq2Seq) 问题,其中输入和输出都是标记列表,因为已发现文本到文本框架有利于应用相同的模型从质量保证到文本摘要的各种 NLP 任务。
下图受原论文启发,展示了 T5 如何在统一框架内解决四个不同的 NLP 问题——机器翻译、语言可接受性、语义相似性和摘要:
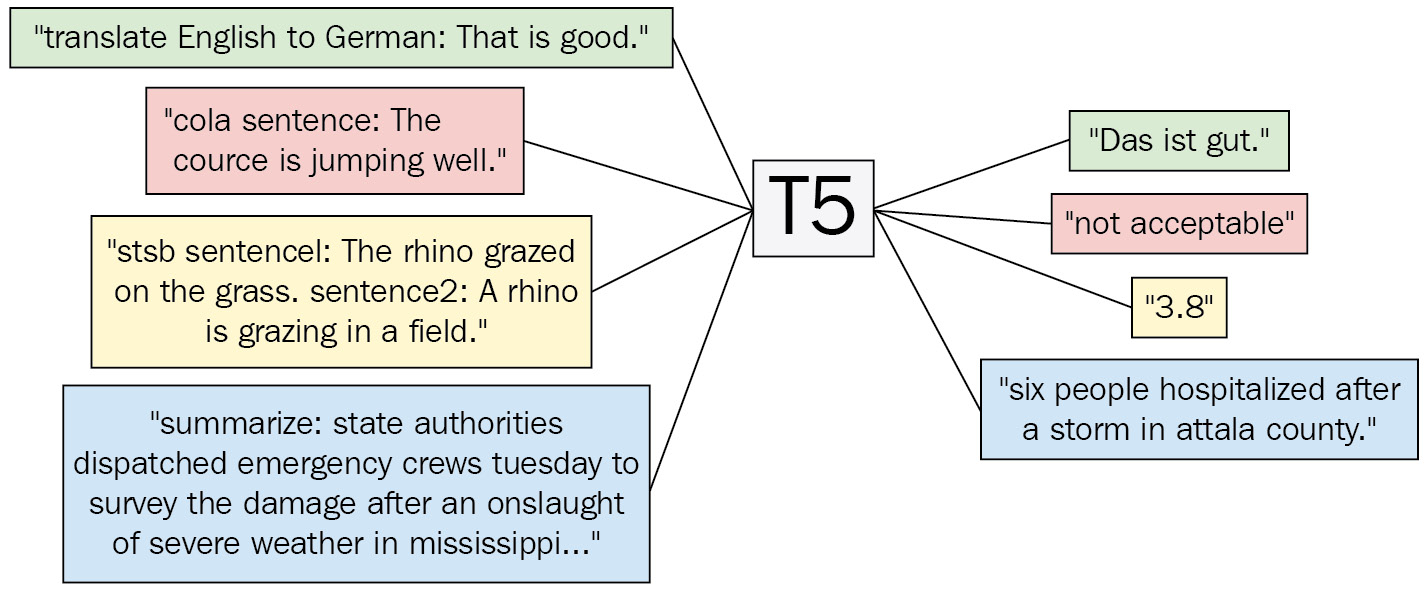
图 4.3 – T5 框架图
T5 型号大致遵循原始的编码器-解码器转换器模型。修改是在层归一化和位置嵌入方案中完成的。T5 没有使用正弦位置嵌入或学习嵌入,而是使用相对位置嵌入,这在变压器架构中变得越来越普遍。T5 是一个单一模型,可以处理多种任务,例如语言生成。更重要的是,它将任务转换为文本到文本的格式。模型被输入由任务前缀和附加到它的输入组成的文本。我们将带标签的文本数据集转换为{'inputs': '....', 'targets': ...'}格式,我们在输入中插入目的作为前缀。然后,我们用带标签的数据训练模型,以便它了解要做什么以及如何去做。如上图所示,对于英德翻译任务,“把英语翻译成德语:那很好”。输入将产生“das is gut”。. 同样,任何带有“summarize:”前缀的输入都会被模型汇总。
介绍 BART
与 XLNet 一样,BART 模型(参见论文BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (2019))利用了 AE 和 AR 模型的方案。它使用标准的 Seq2Seq 转换器架构,稍作修改。BART 是一个预训练模型,使用了各种破坏文档的噪声方法。该研究对该领域的主要贡献是它允许我们应用几种类型的创造性腐败方案,如下图所示:
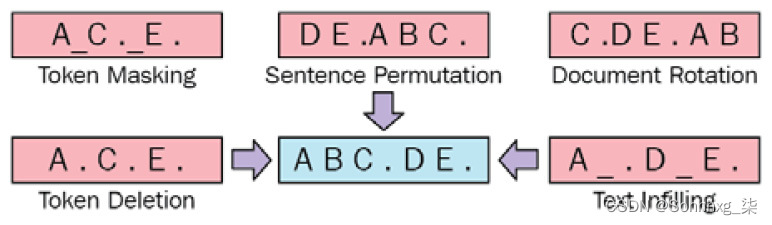
图 4.4 – 受原始 BART 论文启发的图表
我们将详细查看每个方案,如下所示:
- Token Masking : Token 用[MASK]符号随机屏蔽,与 BERT 模型相同。
- 令牌删除:从文档中随机删除令牌。模型被迫确定移除了哪些位置。
- 文本填充:在 SpanBERT 之后,对多个文本跨度进行采样,然后将它们替换为单个[MASK]标记。还有[MASK]令牌插入。
- 句子排列:输入中的句子按随机顺序分段和打乱。
- 文件轮换:文档被旋转,以便它以随机选择的标记开始,在上图中的情况下为C。目标是找到文档的起始位置。
BART 模型可以通过多种方式针对 BERT 等下游应用进行微调。对于序列分类任务,输入通过编码器和解码器,解码器的最终隐藏状态被认为是学习表示。然后,一个简单的线性分类器可以进行预测。同样,对于令牌分类任务,整个文档被送入编码器和解码器,最终解码器的最后状态是每个令牌的表示。基于这些表示,我们可以解决令牌分类问题,我们将在第 6 章,用于令牌分类的微调语言模型中讨论。命名实体识别( NER ) 和词性(POS ) 任务可以使用这个最终表示来解决,其中NER 识别实体,例如个人和组织在文本中,POS 将每个标记与其词汇类别相关联,例如名词、形容词等。
对于序列生成,解码器块BART 模型是一种 AR 解码器,可以直接针对序列生成任务进行微调,例如抽象 QA 或摘要。BART 作者(Lewis、Mike 等人)使用两个标准摘要数据集训练模型:CNN/DailyMail 和 XSum。作者还表明,可以同时使用编码器部分(使用源语言)和解码器部分(生成目标语言中的单词)作为 MT 的单个预训练解码器。他们用一个新的随机初始化的编码器替换了编码器嵌入层,以便学习源语言中的单词。然后,模型以端到端的方式进行训练,训练新的编码器将外来词映射到 BART 可以去噪到目标语言的输入中。新的编码器可以使用单独的词汇表,包括外语,
在 HuggingFace 平台中,我们可以通过以下代码行访问原始的预训练 BART 模型:
AutoModel.from_pretrained('facebook/bart-large')当我们调用转换器库的标准汇总管道时,如以下代码行所示,加载了经过蒸馏的预训练 BART 模型。此调用隐式加载“sshleifer/distilbart-cnn-12-6”模型和相应的分词器,如下所示:
summarizer = pipeline("summarization")以下代码显式加载相同的模型和相应的分词器。代码示例采用要汇总的文本并输出结果:
from transformers import BartTokenizer, BartForConditionalGeneration, BartConfig
from transformers import pipeline
model = BartForConditionalGeneration.from_pretrained('sshleifer/distilbart-cnn-12-6')
tokenizer = BartTokenizer.from_pretrained('sshleifer/distilbart-cnn-12-6')
nlp=pipeline("summarization", model=model, tokenizer=tokenizer)
text='''
We order two different types of jewelry from this
company the other jewelry we order is perfect.
However with this jewelry I have a few things I
don't like. The little Stone comes out of these
and customers are complaining and bringing them
back and we are having to put new jewelry in their
holes. You cannot sterilize these in an autoclave
as well because it heats up too much and the glue
does not hold up so the second group of these that
we used I did not sterilize them that way and the
stones still came out. When I use a dermal clamp
to put the top on the stones come out immediately.
DO not waste your money on this particular product
buy the three mm. that has the claws that hold the
jewelry in those are perfect. So now I'm stuck
with jewelry that I can't sell not good for
business.'''
q=nlp(text)
import pprint
pp = pprint.PrettyPrinter(indent=0, width=100)
pp.pprint(q[0]['summary_text'])
(' The little Stone comes out of these little stones and customers are complaining and bringing ' 'them back and we are having to put new jewelry in their holes . You cannot sterilize these in an ' 'autoclave because it heats up too much and the glue does not hold up so the second group of ' 'these that we used I did not sterilize them that way and the stones still came out .')
在下一节中,我们将亲自动手并学习如何训练此类模型。
AR语言模型训练
在本节中,您将学习如何训练自己的 AR 语言模型。我们将从 GPT-2 开始,使用转换器库更深入地了解其不同的训练功能。
你可以找到任何特定的语料库来训练你自己的 GPT-2,但对于这个例子,我们使用了 Jane Austen 的Emma,这是一部浪漫小说。强烈建议在更大的语料库上进行训练以生成更通用的语言。
在开始之前,需要注意的是,我们使用了 TensorFlow 的原生训练功能来证明所有 Hugging Face 模型都可以直接在 TensorFlow 或 PyTorch 上进行训练,如果您愿意的话。按着这些次序:
- 您可以使用以下命令下载艾玛小说原始文本:
wget https://raw.githubusercontent.com/teropa/nlp/master/resources/corpora/gutenberg/austen-emma.txt - 第一步是在您打算训练 GPT-2 的语料库上训练 GPT-2的BytePairEncoding标记器。以下代码将从标记器库中导入BPE标记器:
from tokenizers.models import BPE from tokenizers import Tokenizer from tokenizers.decoders import ByteLevel as ByteLevelDecoder from tokenizers.normalizers import Sequence, Lowercase from tokenizers.pre_tokenizers import ByteLevel from tokenizers.trainers import BpeTrainer - 如你所见,在这个例如,我们打算通过添加更多功能(例如小写规范化)来训练更高级的分词器。要制作分词器对象,您可以使用以下代码:
tokenizer = Tokenizer(BPE()) tokenizer.normalizer = Sequence([ Lowercase() ]) tokenizer.pre_tokenizer = ByteLevel() tokenizer.decoder = ByteLevelDecoder()范化部分,添加了小写,并将pre_tokenizer属性设置为ByteLevel以确保我们有字节作为输入。解码器属性也必须设置为ByteLevelDecoder才能正确解码。
- 接下来,将使用50000的最大词汇量和来自ByteLevel的初始字母表来训练标记器,如下所示:
trainer = BpeTrainer(vocab_size=50000, inital_alphabet=ByteLevel.alphabet(), special_tokens=[ "<s>", "<pad>", "</s>", "<unk>", "<mask>" ]) tokenizer.train(["austen-emma.txt"], trainer) - 也有必要添加要考虑的特殊标记。要保存分词器,您需要创建一个目录,如下所示:
!mkdir tokenizer_gpt - 您可以通过运行以下命令来保存标记器:
tokenizer.save("tokenizer_gpt/tokenizer.json") - 现在分词器已保存,是时候预处理语料库并使用保存的分词器为 GPT-2 训练做好准备了,但首先,重要的导入不能忘记。以下代码片段说明了执行导入的代码:
from transformers import GPT2TokenizerFast, GPT2Config, TFGPT2LMHeadModel - 并且可以使用GPT2TokenizerFast加载分词器,如下所示:
tokenizer_gpt = GPT2TokenizerFast.from_pretrained("tokenizer_gpt") - 添加带有标记的特殊标记也很重要,如下所示:
tokenizer_gpt.add_special_tokens({ "eos_token": "</s>", "bos_token": "<s>", "unk_token": "<unk>", "pad_token": "<pad>", "mask_token": "<mask>" }) - 您还可以通过运行以下代码来仔细检查一切是否正确:
tokenizer_gpt.eos_token_id2
此代码将输出句末( EOS ) 令牌标识符( ID ),对于当前的分词器,它是2 。
- 你也可以测试一下通过执行以下代码获得一个句子:
tokenizer_gpt.encode("<s> this is </s>")[0, 265, 157, 56, 2]
对于这个输出,0是句子的开头,265、157和56与句子本身相关,EOS标记为2,即</s>。
- 创建配置对象时必须使用这些设置。以下代码将创建一个配置对象和 GPT-2 模型的 TensorFlow 版本:
config = GPT2Config( vocab_size=tokenizer_gpt.vocab_size, bos_token_id=tokenizer_gpt.bos_token_id, eos_token_id=tokenizer_gpt.eos_token_id ) model = TFGPT2LMHeadModel(config) - 在运行配置对象时,您可以看到字典格式的配置,如下所示:
configGPT2Config { "activation_function": "gelu_new", "attn_pdrop": 0.1, "bos_token_id": 0, "embd_pdrop": 0.1, "eos_token_id": 2, "gradient_checkpointing": false, "initializer_range": 0.02, "layer_norm_epsilon": 1e-05, "model_type": "gpt2", "n_ctx": 1024, "n_embd": 768, "n_head": 12, "n_inner": null, "n_layer": 12, "n_positions": 1024, "resid_pdrop": 0.1, "summary_activation": null, "summary_first_dropout": 0.1, "summary_proj_to_labels": true, "summary_type": "cls_index", "summary_use_proj": true, "transformers_version": "4.3.2", "use_cache": true, "vocab_size": 11750}
如您所见,其他设置没有触及,有趣的是vocab_size设置为11750。这背后的原因是我们将最大词汇量设置为50000,但语料库的数量较少,并且其字节对编码( BPE ) 令牌创建了11750。
- 轮到你了可以让你的语料库为预训练做好准备,如下:
with open("austen-emma.txt", "r", encoding='utf-8') as f: content = f.readlines() - 内容现在将包括原始文件中的所有原始文本,但需要从每行中删除'\n'并删除少于10 个字符的行,如下所示:
content_p = [] for c in content: if len(c)>10: content_p.append(c.strip()) content_p = " ".join(content_p)+tokenizer_gpt.eos_token - 删除短线将确保模型在长序列上进行训练,以便能够生成更长的序列。在前面的代码片段的末尾,content_p将带有eos_token的串联原始文件添加到末尾。但是你也可以遵循不同的策略——例如,你可以通过在每一行添加</s>来分隔每一行,这将有助于模型识别句子何时结束。但是,我们打算让它在不遇到 EOS 的情况下工作更长的序列。代码如以下片段所示:
tokenized_content = tokenizer_gpt.encode(content_p) - 现在,是时候制作训练样本了,如下所示:
sample_len = 100 examples = [] for i in range(0, len(tokenized_content)): examples.append(tokenized_content[i:i + sample_len]) - 前面的代码使每个示例的大小为100,从给定的文本部分开始,到100 个标记后结束:
train_data = [] labels = [] for example in examples: train_data.append(example[:-1]) labels.append(example[1:])在train_data中,从 start 到第 99 个 token 会有一个大小为 99 的序列,标签会有一个从1到100的 token 序列。
- 为了更快的训练,需要将数据做成TensorFlow数据集的形式,如下:
import tensorflow as tf buffer = 500 batch_size = 16 dataset = tf.data.Dataset.from_tensor_slices((train_data, labels)) dataset = dataset.shuffle(buffer).batch(batch_size, drop_remainder=True)缓冲区是用于混洗数据的缓冲区大小,batch_size是训练的批大小。drop_remainder用于删除小于16的余数。
- 现在,您可以指定您的优化器、损失和指标属性,如下所示:
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0) loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy') model.compile(optimizer=optimizer, loss=[loss, *[None] * model.config.n_layer], metrics=[metric]) - 并且模型已编译并准备好使用您希望的 epoch 数进行训练,如下所示:
epochs = 10 model.fit(dataset, epochs=epochs)您将看到如下所示的输出:
图 4.5 – 使用 TensorFlow/Keras 进行 GPT-2 训练
我们现在将研究使用 AR 模型的 NLG。现在您已经保存了模型,它将在下一节中用于生成句子。
到目前为止,您已经了解了如何为 NLG 训练自己的模型。在下一节中,我们将描述如何利用 NLG 模型进行语言生成。
使用 AR 模型的 NLG
在上一节中,您已经了解了如何在您自己的语料库上训练 AR 模型。结果,您已经训练了自己的 GPT-2 版本。但是我如何使用它?遗迹。为了回答这个问题,让我们进行如下操作:
- 让我们从刚刚训练好的模型开始生成句子,如下:
def generate(start, model): input_token_ids = tokenizer_gpt.encode(start, return_tensors='tf') output = model.generate( input_token_ids, max_length = 500, num_beams = 5, temperature = 0.7, no_repeat_ngram_size=2, num_return_sequences=1 ) return tokenizer_gpt.decode(output[0])前面代码片段中定义的generate函数接受一个起始字符串和生成该字符串之后的序列。您可以更改参数,例如max_length以设置为较小的序列大小或num_return_sequences以具有不同的代。
- 让我们用一个空字符串试试,如下:
generate(" ", model)我们得到以下输出:

图 4.6 – GPT-2 文本生成示例
从前面的输出可以看出,生成了一个长文本,即使文本的语义不是很讨人喜欢,但在很多情况下语法几乎是正确的。
- 现在,让我们试试不同的开始,将max_length设置为较低的值,例如30,如下所示:
generate("wetson was very good")'wetson was very good; but it, that he was a great must be a mile from them, and a miss taylor in the house;'
你还记得韦斯顿是小说中的人物之一。
- 要保存模型,您可以使用以下代码使其可重用于发布或不同的应用程序:
model.save_pretrained("my_gpt-2/") - 为确保您的模型正确保存,您可以尝试加载它,如下所示:
model_reloaded = TFGPT2LMHeadModel.from_pretrained("my_gpt-2/")保存了两个文件——一个配置文件和一个用于 TensorFlow 版本的model.h5文件。我们可以在以下屏幕截图中看到这两个文件:
图 4.7 – 语言模型 save_pretrained 输出
- 还抱脸有一个必须使用的文件名标准——这些标准文件名可通过以下导入获得:
from transformers import WEIGHTS_NAME, CONFIG_NAME, TF2_WEIGHTS_NAME然而,当使用save_pretrained函数时,不需要放置文件名——只要目录就足够了。
- Hugging Face 也有AutoModel和AutoTokenizer类,正如您在前面的部分中看到的那样。您也可以使用此功能保存模型,但在此之前仍有一些配置需要手动完成。第一件事是以AutoTokenizer使用的正确格式保存标记器。您可以使用save_pretrained来执行此操作,如下所示:
tokenizer_gpt.save_pretrained("tokenizer_gpt_auto/")这是输出:
图 4.8 – Tokenizer save_pretrained 输出
- 显示文件列表在您指定的目录中,但必须手动更改tokenizer_config才能使用。首先,您应该将其重命名为config.json,其次,您应该添加一个JavaScript Object Notation ( JSON ) 格式的属性,表明model_type属性为gpt2,如下所示:
{"model_type":"gpt2", ... } - 现在,一切准备就绪,您可以简单地使用这两行代码来加载模型和分词器:
model = AutoModel.from_pretrained("my_gpt-2/", from_tf=True) tokenizer = AutoTokenizer.from_pretrained("tokenizer_gpt_auto")但是,不要忘记将from_tf设置为True,因为您的模型以 TensorFlow 格式保存。
到目前为止,您已经了解了如何使用tensorflow和转换器预训练和保存自己的文本生成模型。您还了解了如何保存预训练模型并准备将其用作汽车模型。在下一节中,您将学习使用其他模型的基础知识。
使用 simpletransformers 进行汇总和 MT 微调
到目前为止,您已经学习了训练语言模型的基础知识和高级方法,但是从头开始训练自己的语言模型并不总是可行的,因为有时会存在计算能力低等障碍。在本节中,您将了解如何微调您自己的数据集上的语言模型,用于 MT 的特定任务和总结。请按照以下步骤操作:
- 首先,您需要安装simpletransformers库,如下所示:
pip install simpletransformers - 下一步是下载包含您的并行语料库的数据集。这个并行语料库可以是任何类型的 Seq2Seq 任务。对于本示例,我们将使用 MT 示例,但您可以将任何其他数据集用于其他任务,例如释义、摘要,甚至将文本转换为结构化查询语言( SQL )。
您可以从Turkish to English Translation Dataset | Kaggle下载数据集。
- 下载并解压数据后,需要在列标题处添加EN和TR,以便于使用。您可以使用pandas加载数据集,如下所示:
import pandas as pd df = pd.read_csv("TR2EN.txt",sep="\t").astype(str) - 需要将特定于 T5 的命令添加到数据集以使其理解正在处理的命令。您可以使用以下代码执行此操作:
data = [] for item in digitrons(): data.append(["translate english to turkish", item[1].EN, item[1].TR]) - 之后,您可以改造 DataFrame,如下所示:
df = pd.DataFrame(data, columns=["prefix", "input_text", "target_text"])这结果是如以下屏幕截图所示:

图 4.9 – 英语-土耳其语 MT 平行语料库
- 接下来,运行以下代码来导入所需的类:
from simpletransformers.t5 import T5Model, T5Args - 定义参数培训是使用完成的以下代码:
model_args = T5Args() model_args.max_seq_length = 96 model_args.train_batch_size = 20 model_args.eval_batch_size = 20 model_args.num_train_epochs = 1 model_args.evaluate_during_training = True model_args.evaluate_during_training_steps = 30000 model_args.use_multiprocessing = False model_args.fp16 = False model_args.save_steps = -1 model_args.save_eval_checkpoints = False model_args.no_cache = True model_args.reprocess_input_data = True model_args.overwrite_output_dir = True model_args.preprocess_inputs = False model_args.num_return_sequences = 1 model_args.wandb_project = "MT5 English-Turkish Translation" - 最后,你可以加载您想要的任何模型微调。这是我们选择的一个:
model = T5Model("mt5", "google/mt5-small", args=model_args, use_cuda=False)如果您没有足够的计算统一设备架构( CUDA ) 内存用于 mT5,请不要忘记将use_cuda设置为False 。
- 可以使用以下代码拆分train和eval DataFrame:
train_df = df[: 470000] eval_df = df[470000:] - 最后一步是使用以下代码开始训练:
model.train_model(train_df,eval_data=eval_df)训练结果将显示如下:

图 4.10 – mT5 模型评估结果
这表明评估和训练损失。
- 您可以使用以下代码简单地加载和使用模型:
model_args = T5Args() model_args.max_length = 512 model_args.length_penalty = 1 model_args.num_beams = 10 model = T5Model("mt5", "outputs", args=model_args, use_cuda=False)model_predict函数_现在可以用于从英语翻译成土耳其语。
Simple Transformers 库 ( simpletransformers ) 使得训练许多模型,从序列标记到 Seq2Seq 模型,都非常简单和可用。
做得好!我们已经学会了如何训练我们自己的 AR 模型,并且已经到了本章的结尾。
概括
在本章中,我们学习了 AR 语言模型的各个方面,从预训练到微调。我们通过训练生成语言模型和对 MT 等任务进行微调来研究此类模型的最佳特性。我们了解了更复杂模型(例如 T5)的基础知识,并使用这种模型来执行 MT。我们还使用了simpletransformers库。我们在自己的语料库上训练 GPT-2 并使用它生成文本。我们学习了如何保存它并将其与AutoModel一起使用。我们还使用标记器库更深入地了解了如何训练和使用 BPE 。
在下一章中,我们将看到如何微调文本分类模型