多线程 3
多线程 3 :
文章目录
- 1.线程安全
- 2. 产生线程安全的原因
- 3. synchronized - 加锁操作
- 4.可重入
- 5.死锁问题
- 6. volatile 关键字
- 7.wait 和 notify
1.线程安全
为啥会出现线程安全 ?
罪魁祸首,还是多线程的抢占式执行, 正因为抢占式执行,所以会带来很多的随机性.
这里先来看单个线程的情况
因为是单个线程,所以代码的执行就是固定的(只有一条路) ,代码的顺序固定,那么结果必然也是固定的.
所以在单线程的情况下,只需要清楚这一条路即可 .
多线程的情况
因为多线程会抢占式执行, 那么代码的执行顺序,就会出现很多的变数,导致代码的执行顺序就会有很多种情况, 此时要在无数种线程调度的情况下(线程调度的顺序不同产生的结果也不同) 要保证我们的代码执行结果都正确是非常难的 。
此时只要有一种情况下代码的结果不正确, 都会被认为 有 bug 线程不安全
光看文字可能不太好了解下面就来看看代码:

下面运行 :
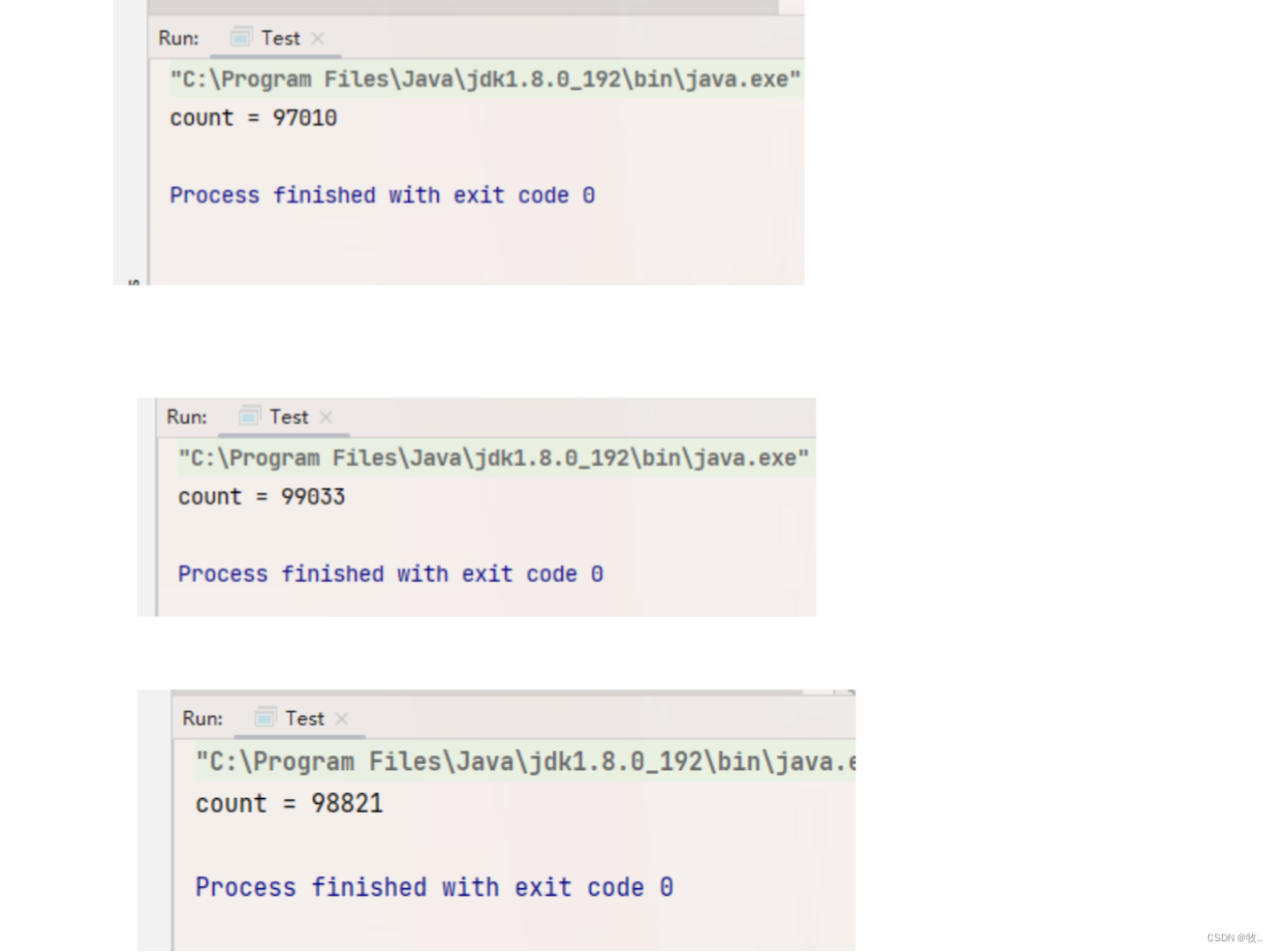
我 们预期 的结果 是 10w 但是这里 都是 9w 多 明显是出现了 bug( bug : 实际结果与预期结果不同 就称为 bug ) 同时这也是一个典型的线程安全问题.
下面就来解释一下为啥程序会出现这种情况
++ 操作 很熟悉把 ,这里就通过他来入手.
++ 操作本质上要分成三步
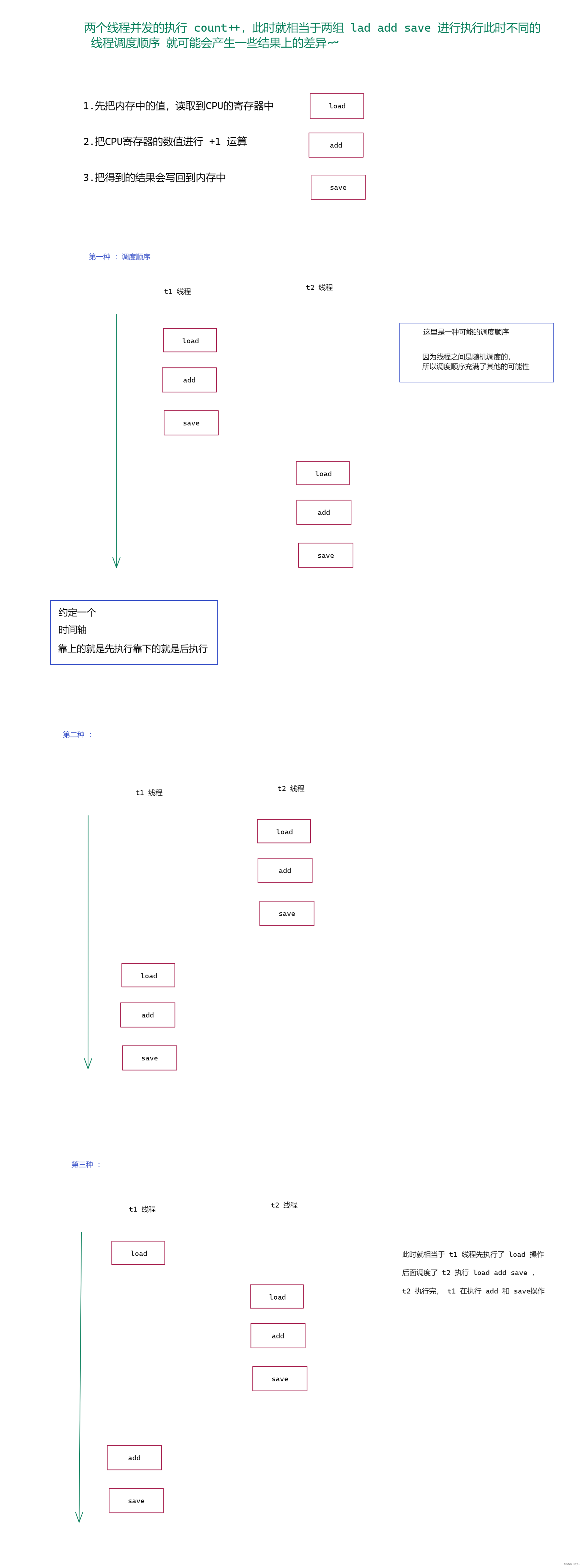
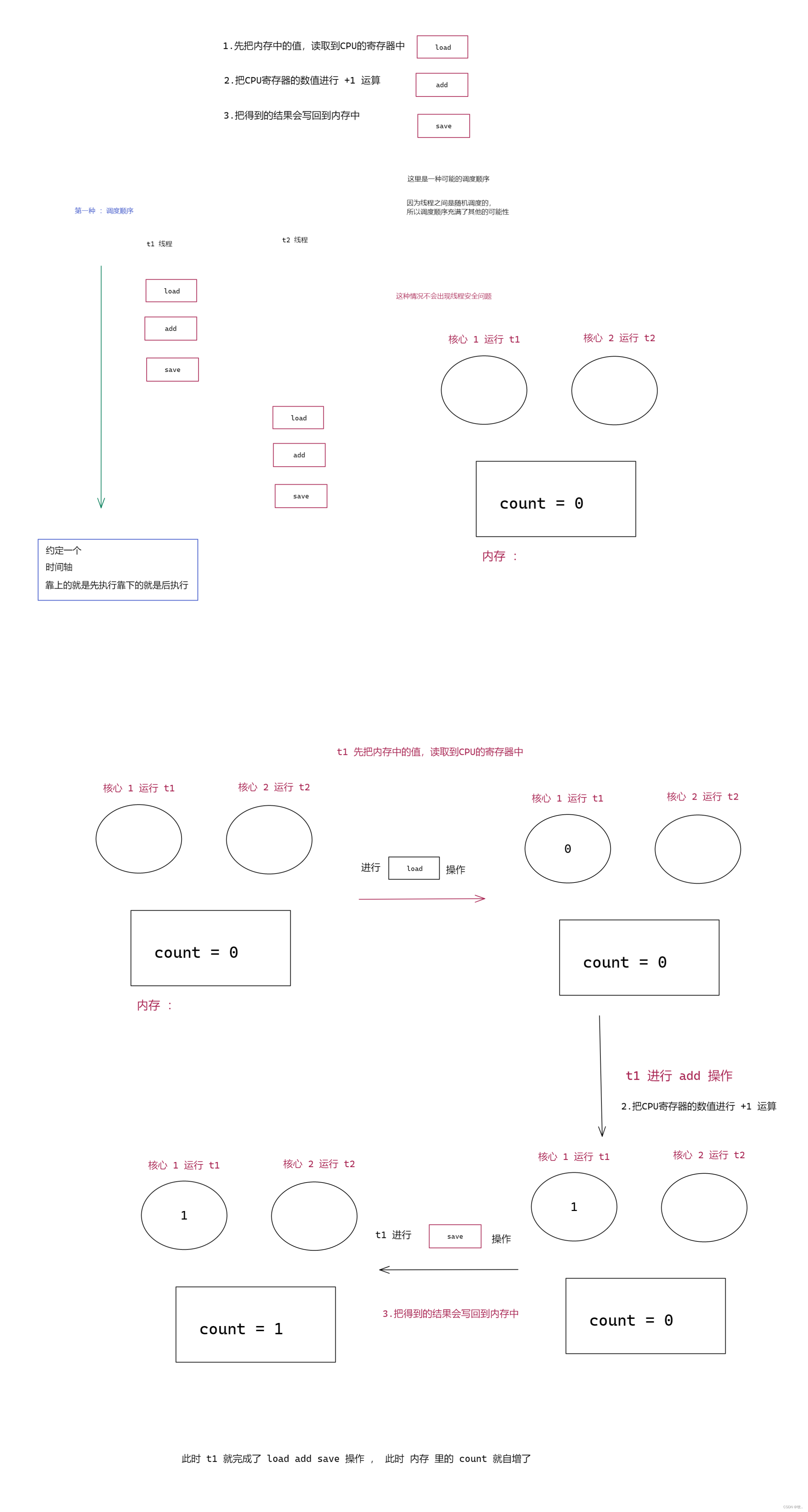
1.先把内存中的值,读取到CPU的寄存器中
2.把CPU寄存器的数值进行 +1 运算
3.把得到的结果会写回到内存中
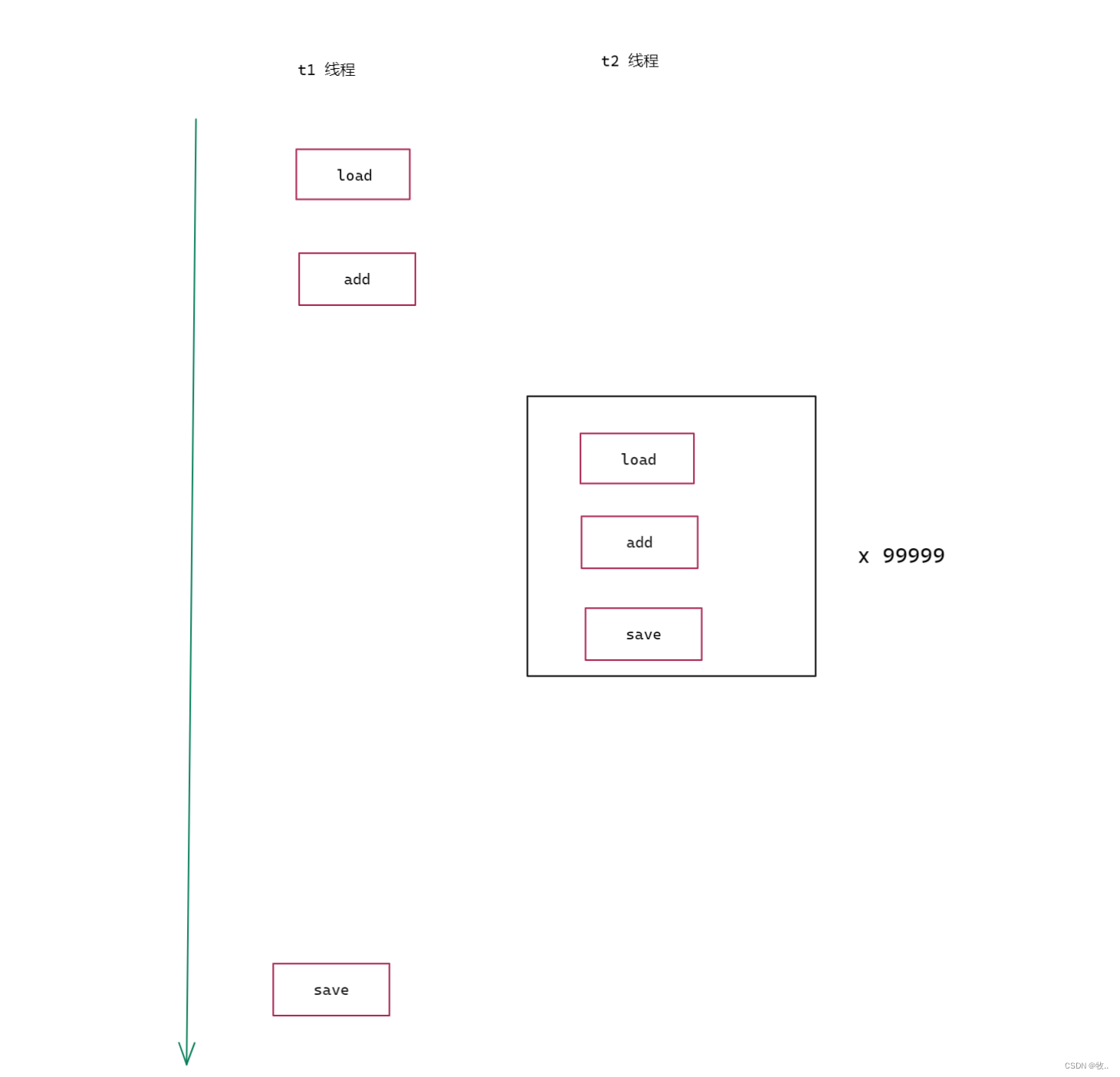
这里为了后面画图方便,将第一步 称为 load 第二步称为 add , 第三步 称为 save
另外 : load , add , save 三个操作 就是 CPU 上执行的三个指令 (指令可以视为 机器语言 ).
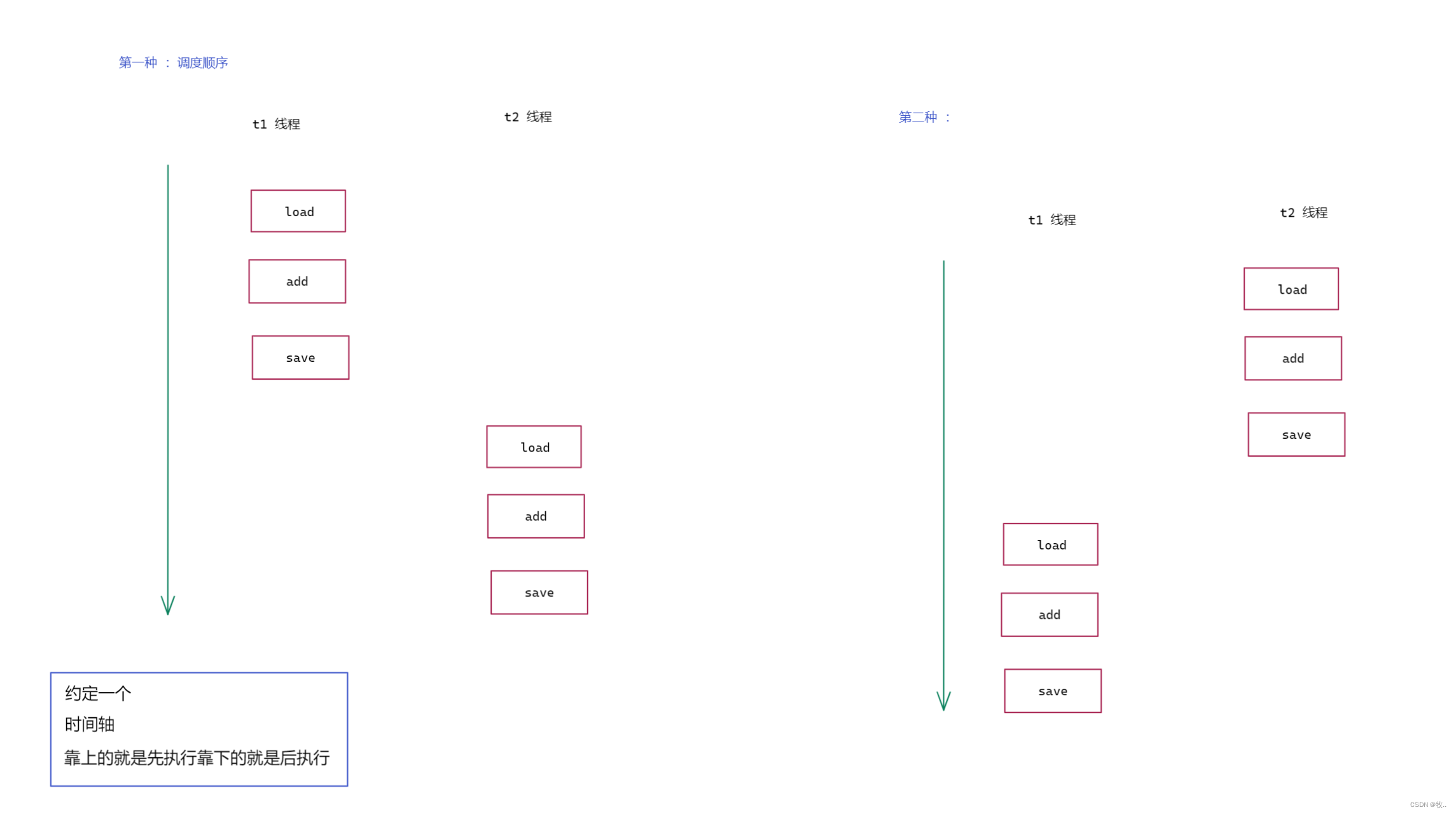
上面我们写的代码就是通过两个线程进行 load ,add , save 这三步操作 , 下就画图来 看看 是如何执行的 。
图一 :
图二 :
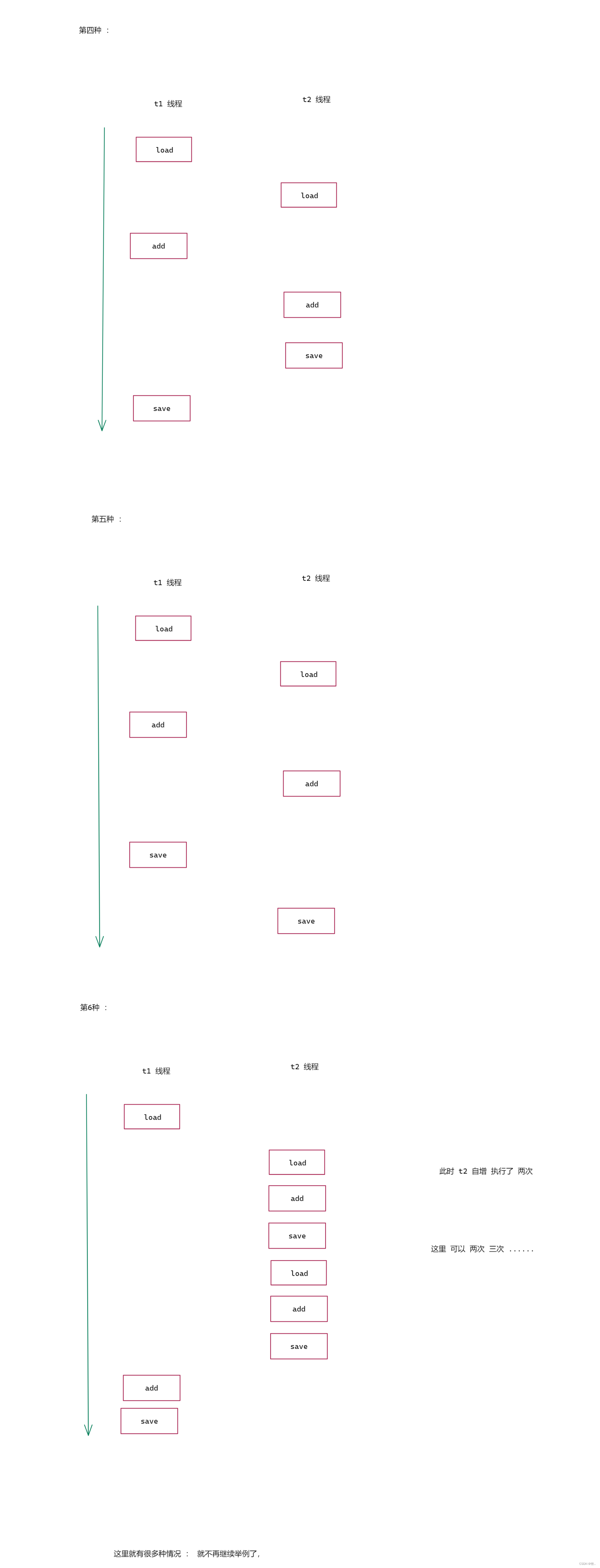
线程安全的情况 上图第一种 和 第二种
图一 :
图二 :
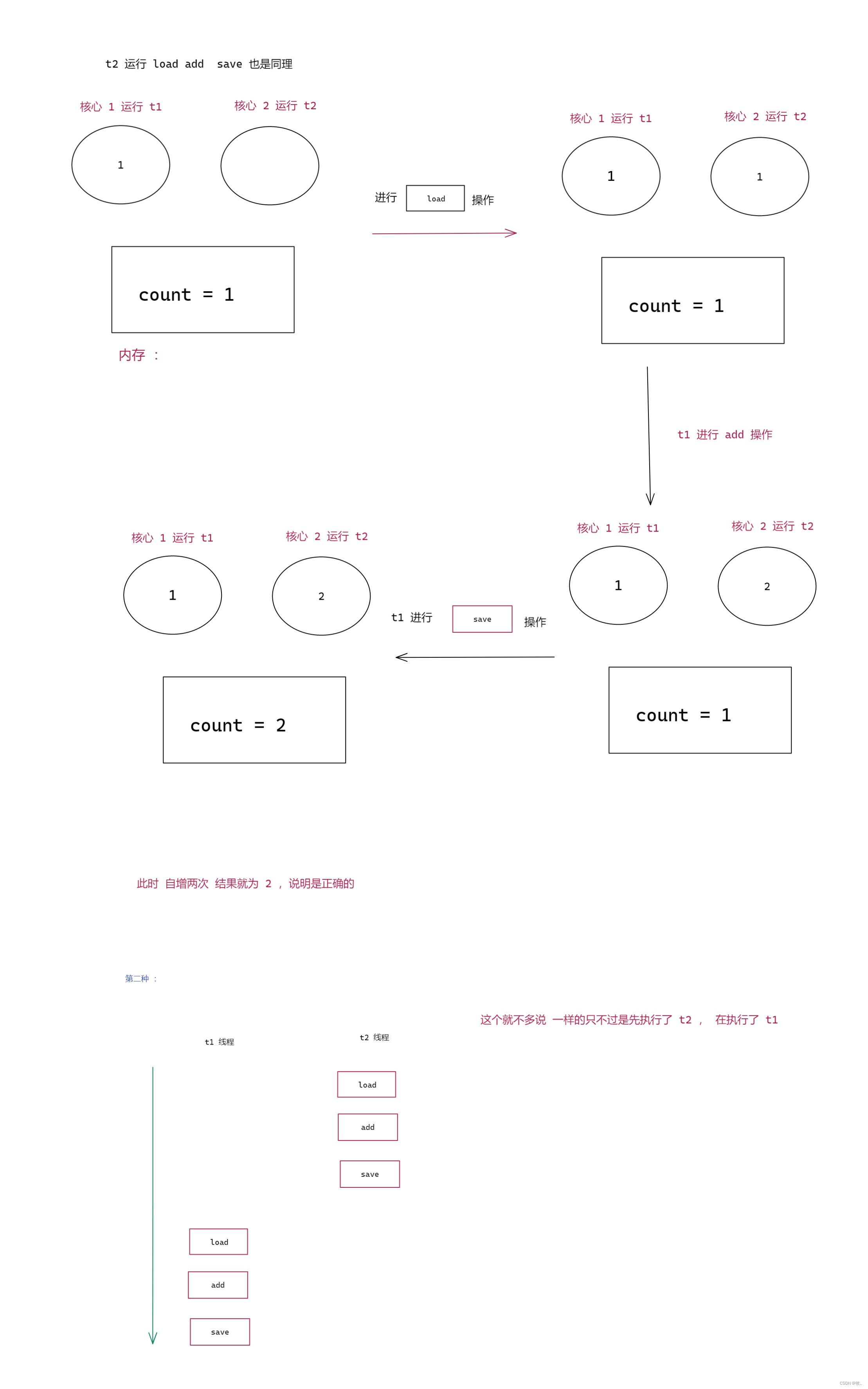
下面就来看看线程不安全的情况, 这里随便挑选了一种, 看懂了下面 其他的也是一样的
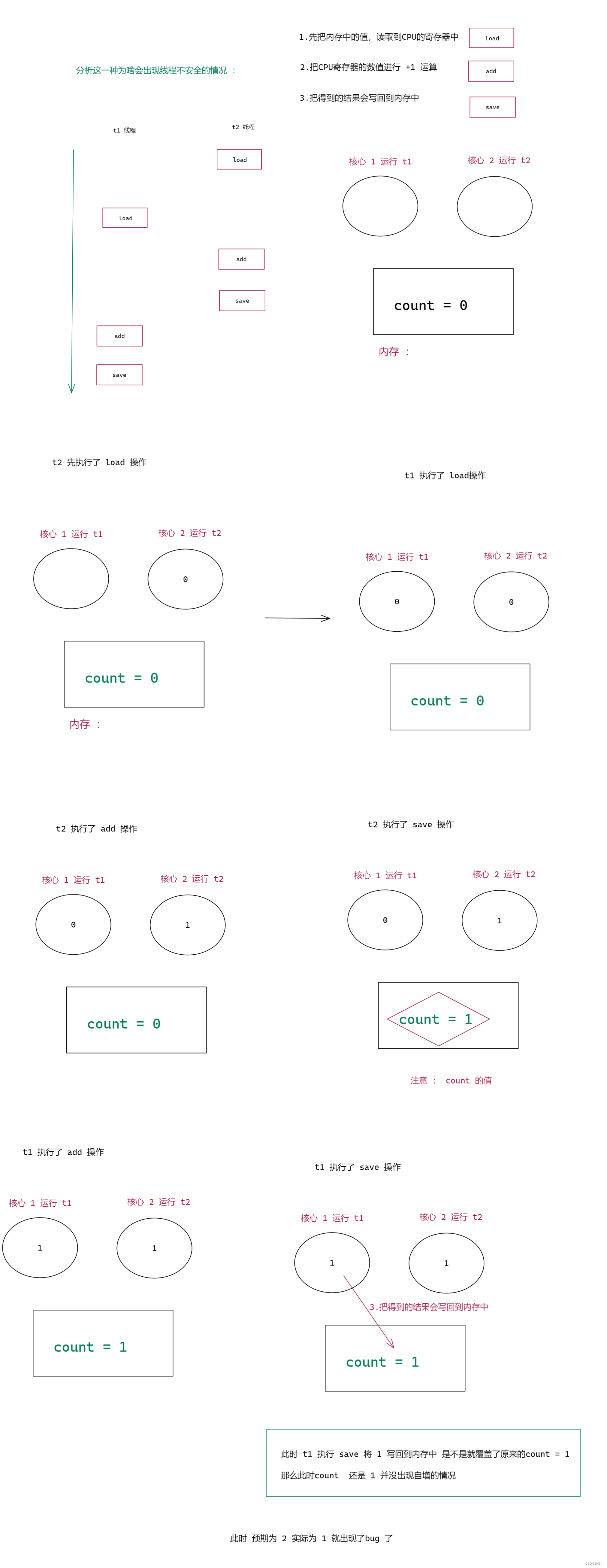
下面就来提问 : 当前的这个代码有没有可能结果正好是 10w呢?

答案 : 是有可能的 , 只要我们每次都是下面这两种情况那么结果就是 10w ,这里的概率是非常小的.
那么下面再来 一个问题 : 既然 10 w 有概率 ,那么 我们的结果一定会大于 5w 吗 ?
答案 : 这里是不一定的, 举一个最极端的例子, t1 自增1次的时候, t2 自增了 99999 次 ,最后 t1 执行 save 操作,那么结果就为 1 了 。
通过这段代码, 回头来看我们的线程安全,就可以总结出几点出现线程安全的原因.
2. 产生线程安全的原因
1. 根本 原因 线程抢占式执行 , 随机调度 .
2. 代码结构 : 多个线程同时修改同一个变量
补充 :
2.1一个线程修改一个变量 ,
2.2 多个线程读同一个变量 ( 只涉及到了 读操作,并没有修改) ,
扩充 : String 是不可变对象 ,他天然是线程安全的 , 不可变吗 ,所以只能读,所以即便是多个线程 也只涉及到了读操作, 所以是使用 String 线程安全的 .
2.3 多个线程修改多个不同的变量 (好比 有3个人 想要上厕所 ,正好有三个厕所,此时一人一个厕所 就不会出现抢 厕所的问题 ).
上面这三个都不会涉及到 线程安全 ,
3. 针对变量的操作不是原子的
原子性 :在的 MySQL 中的事务就出现了 , 主要就是将几个操作打包成为一个整体,要么全部执行,要不就一个都不执行。
原子: 是不可拆分的基本单位 .
在我们的上述代码中 count++ 可以拆分成 load ,add , save 三个操作 (load , add , save 已经是 单个指令无法再进行拆分了) , 正因为 count ++ 能够拆分出 这三步 ,导致 t1 还没自增完 t2 就开始执行了。
这里的本质 其实 就是脏读问题 , 张三修改的结果还没提交,t2 就已经读了。
关于 原子性 就是我们解决线程安全的最主要手段 , 将非原子的操作,变成原子.
咋变成呢?
嘿嘿 这里买个关子 , 在后面我们学到了 加锁操作的时候就会说到 .
最后在来看一个 导致线程安全的原因 , 上述的代码中并没有体现这个问题.
4.内存可见性
在上面 的那个代码中,是两个线程 对同一个变量进行修改操作, 此时改成 一个线程 修改, 一个线程读 ,同样也可能会出现问题 ,出现读的结果不太符合预期 (在后面 volatile 中说到)
最后还有一种情况 , 是编译器优化导致的线程安全问题 .
5.指令重排
指令重排 : 本质上是编译器优化出 bug 了 , 这里编译器认为我们写的代码太 垃圾了 ,就将我们的代码自作主张的调整了, 此时会在保持逻辑不变的情况下 进行调正 ,从而加快程序的执行效率 .
例子 :
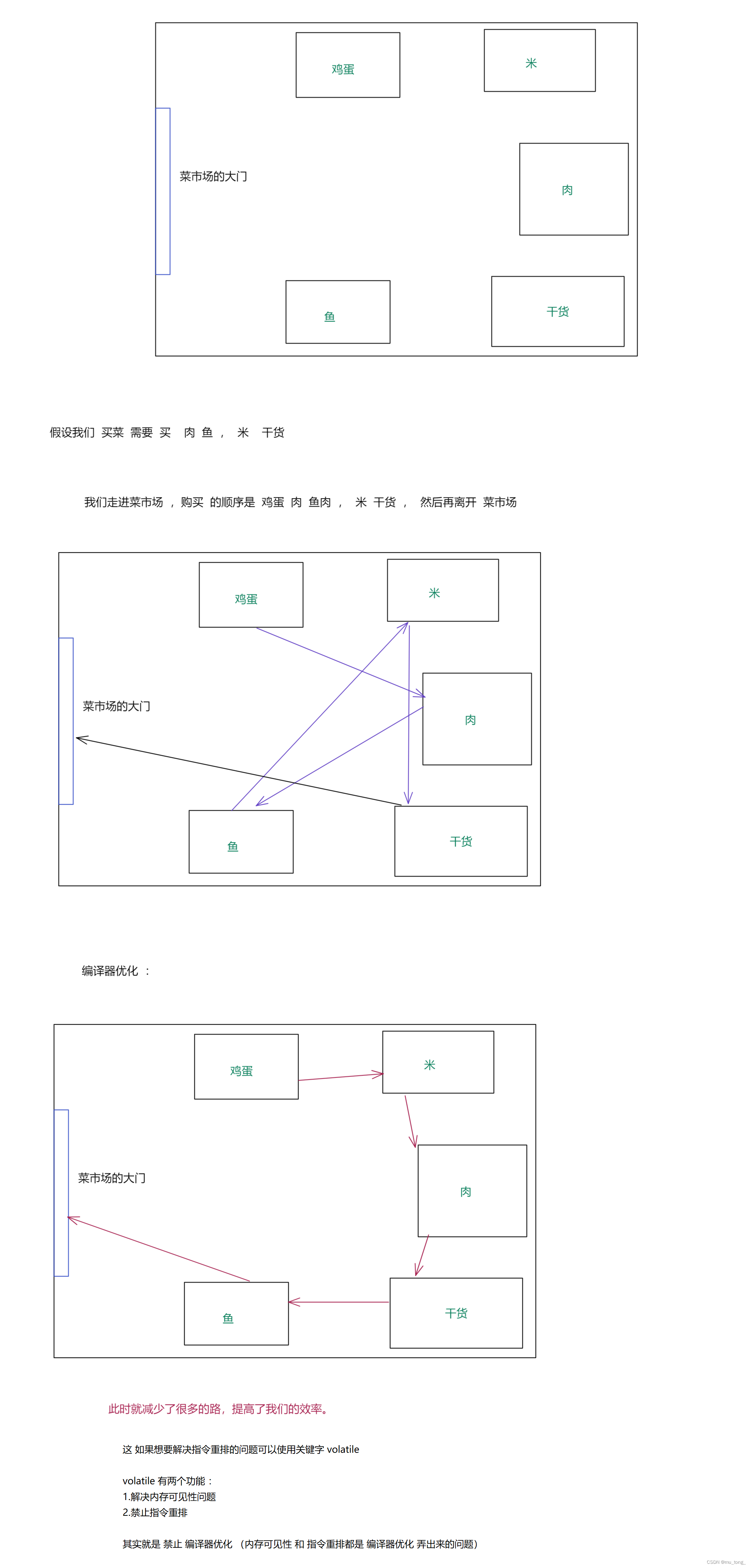
注意 : 上面列举的只是 5个典型的原因 并不是全部, 一个代码究竟是线程安全还是不安全,都得具体问题具体分析,难以一概而论,
总来说: 使用多线程运行代码后,不出现bug 就是安全的.
下面就从原子性来解决线程安全 :
主要 通过 加锁 , 将 不是原子的 转化为 “原子” 的 。
3. synchronized - 加锁操作
补充 : 一旦加锁之后 , 代码的执行效率一定是大打折扣的 。
这里虽然加锁操作 执行效率大打折扣,但是还是比单线程是要快的。
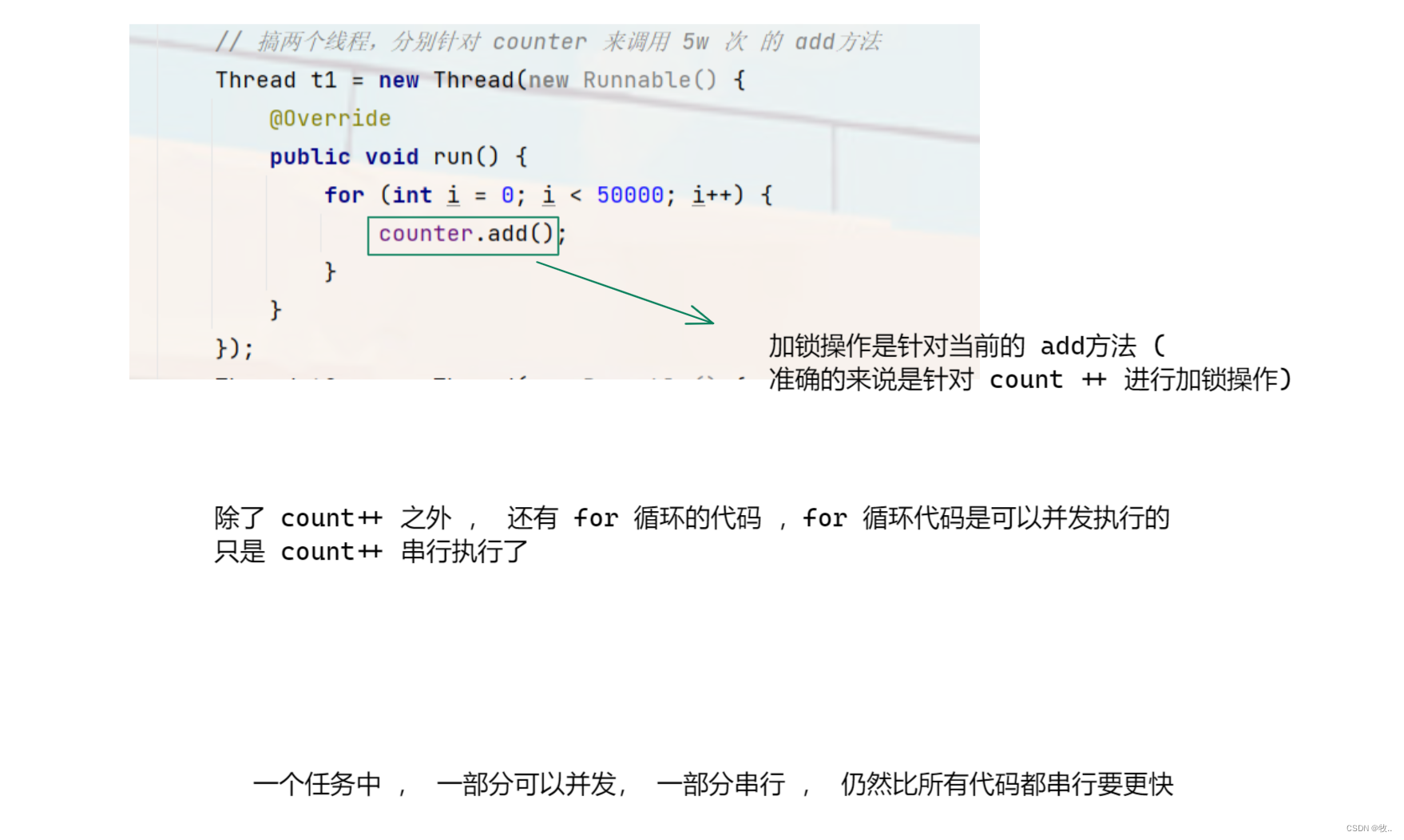
最后 执行 来看一下 结果 :
此时就计算出 10w 了.
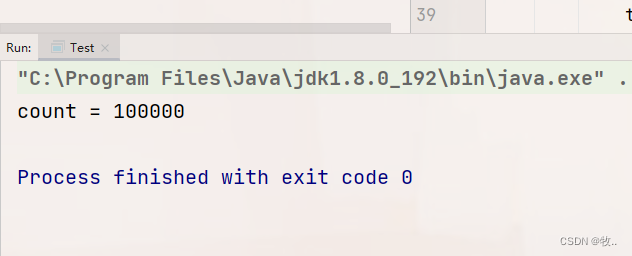
下面我们来看一下 synchronized 的使用方法
1.修饰方法
- 修饰普通方法 :进入方法就加锁 , 离开方法就解锁
修饰普通方法针对的锁对象就是当前对象this

- 修饰静态方法 :进入方法就加锁 , 离开方法就解锁 , 这里就与修饰普通方法,是一样的, 只不过针对的对象不同 .
修饰静态方法针对的锁对象就是类对象(类.class)
关于锁对象 ,这里举个例子加深影响 .
假设 : 我有一个女神,我想让她当我的女朋友,我就去追她, (此时 这个女孩就相当于一个锁对象,我就相当于线程去获取锁) , 但是这个女孩有男朋友 , 名字叫老王,那么这里就相当于 , 锁已经被别人获取到了,此时不管是我想追她还是其他人想要追她都是不可以(锁已经被获取,老王进行了加锁操作),只能等女神分手 (解锁操作),我们才能继续追。
但突然有一天,我看到到了另外一个人,与她一见钟情,我的想法就改变了,我不追女神了, 此时我的锁对象是不是就改变了, 那么老王对女神加的锁就对我无效了.但是 老王的加锁 操作还会对那些想要追女神的人生效,让他们阻塞等待.
因为这个一见钟情的女孩是无锁状态,我就可以直接获取到锁 ,那么其他追这个女孩的 人 ,就只能等待我和女孩分手(解锁操作),他们才能获取锁。
上面的例子主要 说的就是 加锁 是要明确执行对那个对象加锁的 , 如果两个线程针对同一个对象加锁,会产生阻塞等待(锁竞争 / 锁冲突) .
如果两个线程针对不同对象 加锁, 不会阻塞等待(不会锁冲突/ 锁竞争)
再换句话来说: 无论这个对象是啥样的对象 ,原则就一条,锁对象相同 就会产生 锁竞争(产生阻塞等待) , 锁对象不同就不会产生锁竞争(不会阻塞等待)
2.修饰代码块
修饰代码块是手动指定加到那个对象上 。
图一 :
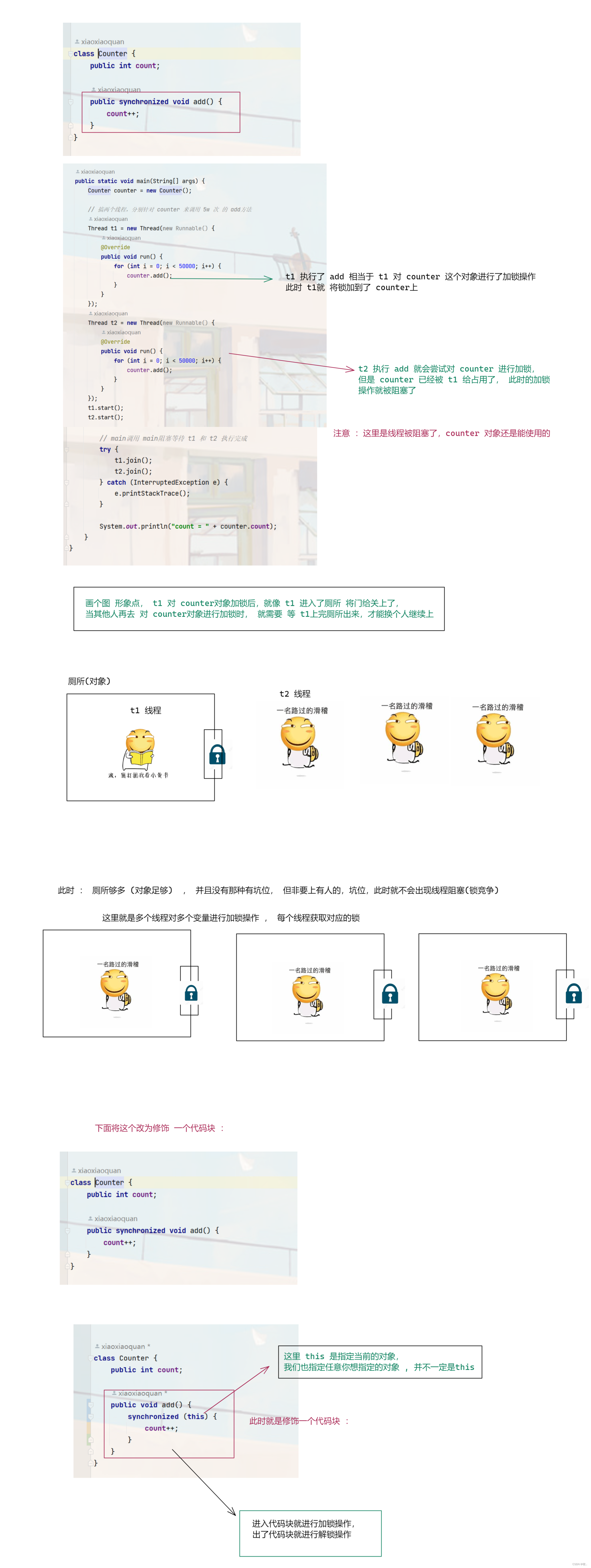
图二 :

看完 synchronized 的使用,下面来可重入锁 ,另外看完上面你会看到我 这里写了很多 , 但大部分都是重复的,主要的重点还是多个线程,对同一个对象进行加锁,会出现锁竞争,导致线程阻塞, 如果每个线程,都对应这自己的锁对象,那么就不出出现锁竞争,就不会线程阻塞.
4.可重入
可重入 : 简单的来说, 就是一个线程对同一个对象,连续加锁两次, 如果没出现问题,就是可重入 ,出现了问题就称为不可重入锁 。

下面就来了解 一下 死锁的问题 :
5.死锁问题
死锁 是一个非常意向程序员幸福感的问题 , 一旦层序出现死锁,就会导致线程就给跪了(无法继续执行后续工作了) 层序势必会有严重 bug .
另外: 死锁是非常隐蔽的, 在开发阶段,不经意间就会写出死锁代码, 不容易测试出来 (死锁经常是一个概率性问题, 过一会 出现了死锁,过一会 没有,).
下面就来看一下死锁的典型场景
1.一个线程 , 一把锁 ,连续加锁两次, 如果锁是不可重入锁,就会死锁.
在我们java 中 synchronized 和 ReentrantLock 都是可重入锁, 所以这个死锁的现象, 在java中就不好演示 , 所以这里知道即可 (java程序猿也不太涉及到这个问题).
2.两个线程两把锁 , t1 和 t2 各自先针对 锁 A 和 锁 B 加锁,在尝试获取对方的锁 .
图一 :

图二 :
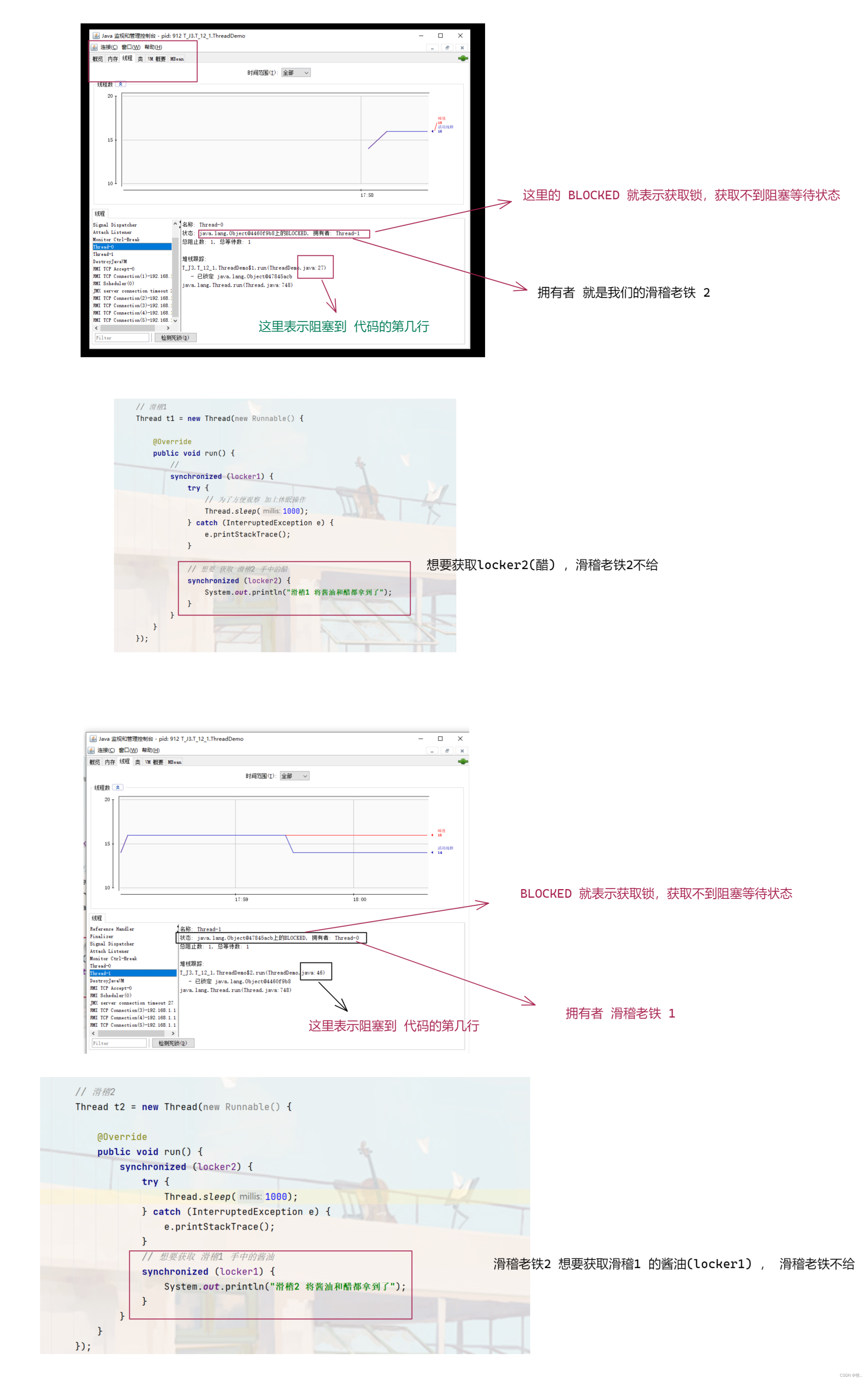
小细节 :

3.多个线程,多把锁
图一 :使用教科书上的例子
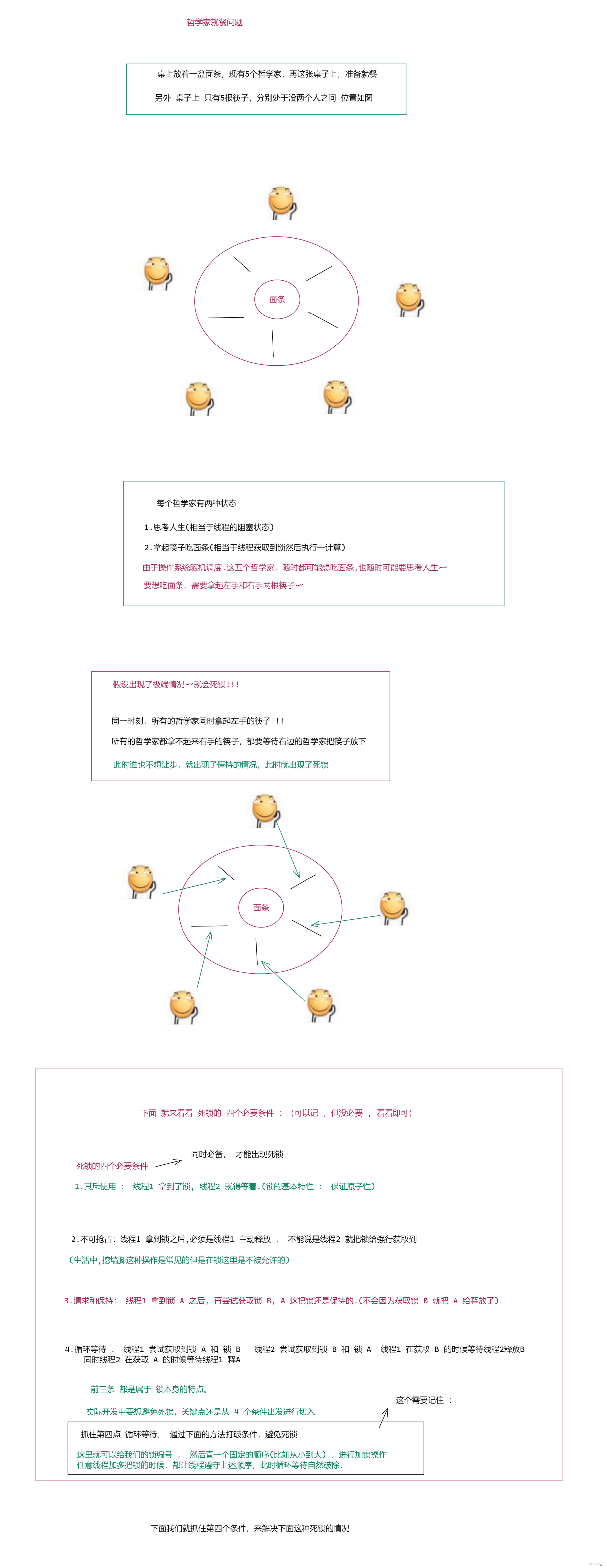
图二 :
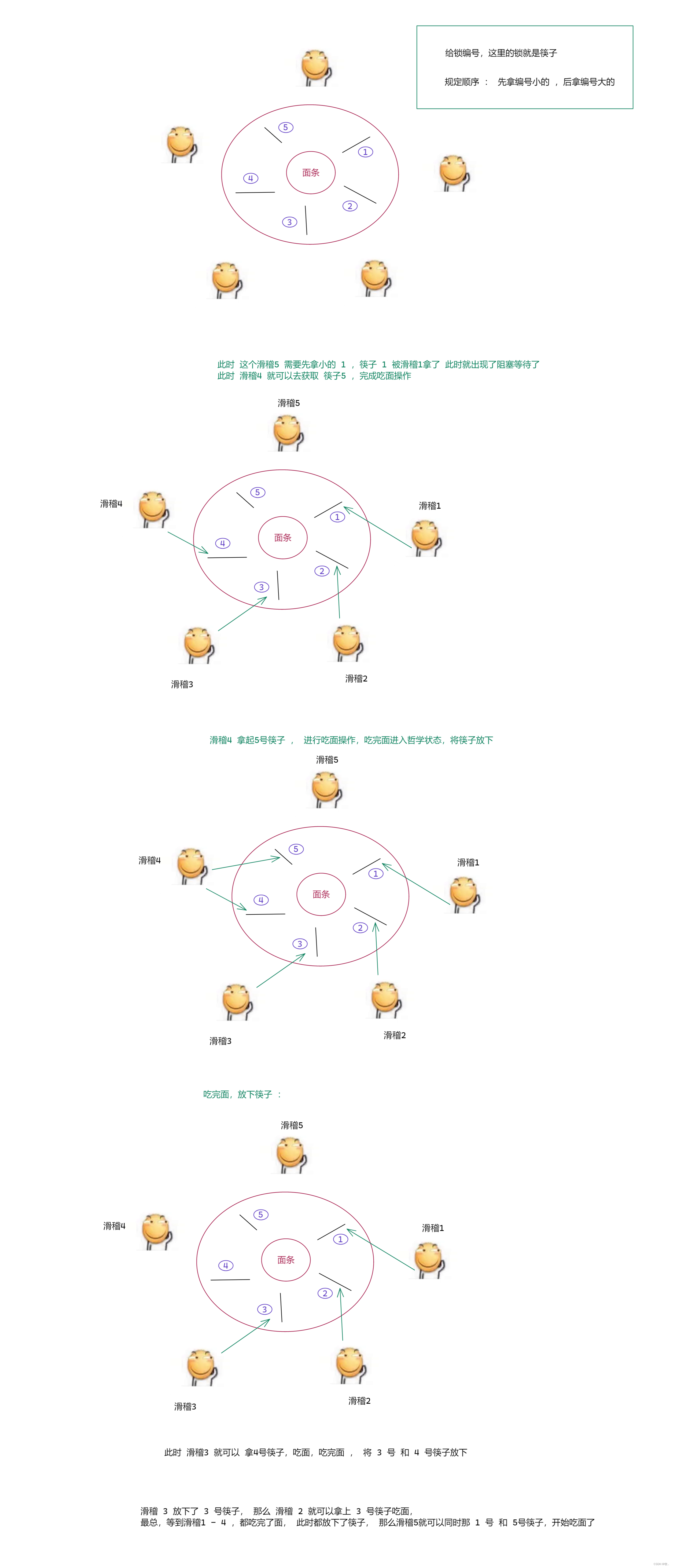
教科书上除了哲学家就餐问题这个例子,还有一个 银行家算法 能解决死锁问题,但是实际开发中并不推荐 , 因为太复杂了,即便费了好大的劲 , 实现了这个算法,结果算法里面有 bug,此时是否解决了死锁不知道,但引入了其他问题.
这里死锁问题看完, 下面稍微了解一下 , 我们java 标准库中,那些类是属于线程安全的,那些是不属于线程安全的.
线程不安全的类
1.ArrayList
2.LinkedList
3.HashMap
4.TreeMap
5.HashSet
6.TreeSet
7.StringBuilder
线程安全的类
1.Vector
2.HashTable
3.ConcurrentHahsMap
4.StringBuffer
5.String
这里的 4个类 是采用了 加锁操作在关键的方法上加上了 synchronized 修饰保证线程安全的 .
String 类 , 比较特殊的, 在String 那文中 ,就提到过, String 类是不可修改的, 所以使用 String 就不涉及到写操作, 之前还说过, 多个线程之间读同一个变量是不会涉及到线程安全的,所以 使用String类也是线程安全的.
关于线程安全,我们还有一个内存可见性没有说,现在就来说一说 .
6. volatile 关键字

通过 代码演示 内存可见性
图一 :
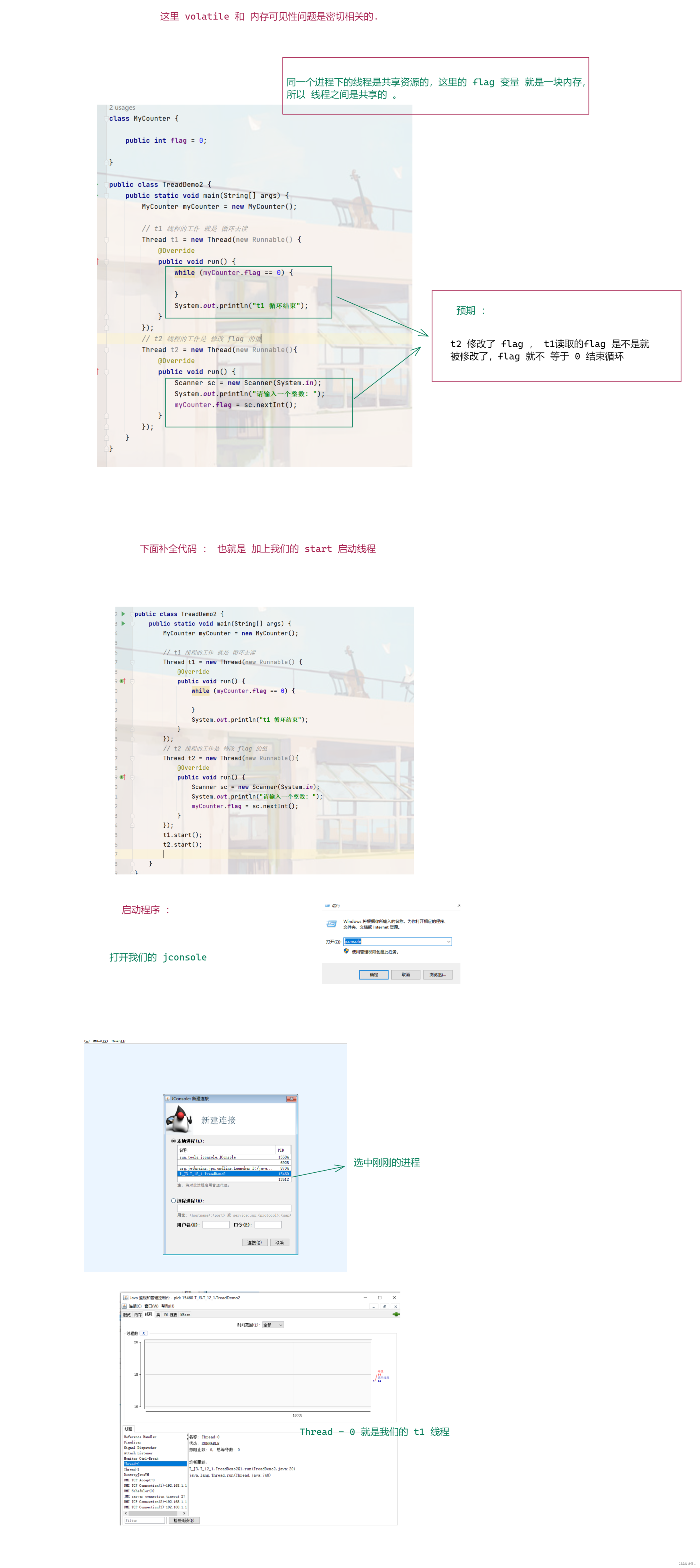
图二 :

图三 : 分析为啥会出现内存可见性问题
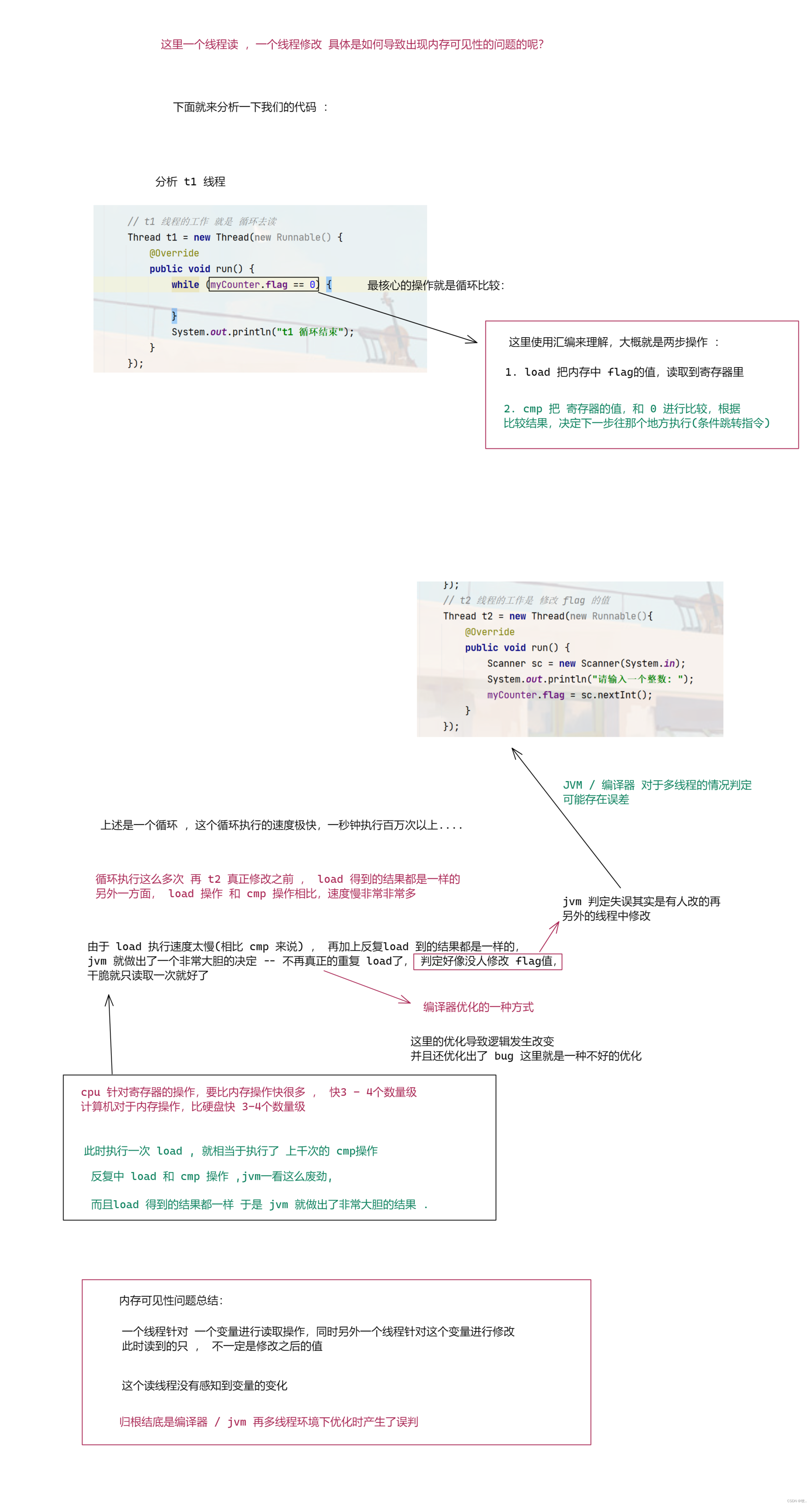
知道了 一个线程读 ,一个线程写,可能出现内存可见性问题,那么如何来解决呢 ?
内存可见性问题本质上是编译器优化导致的问题,这里我们就可以手动干预让编译器不取优化,这里就可以 给 flag变量 加上 volatile 关键字 . 此时加上了 volatile 意思就是告诉编译器这个变量 是 易变的 , 你一定要每次都重新读取这个变量的内存内容,指不定啥时候就变了,可不敢再进行激进的优化了.
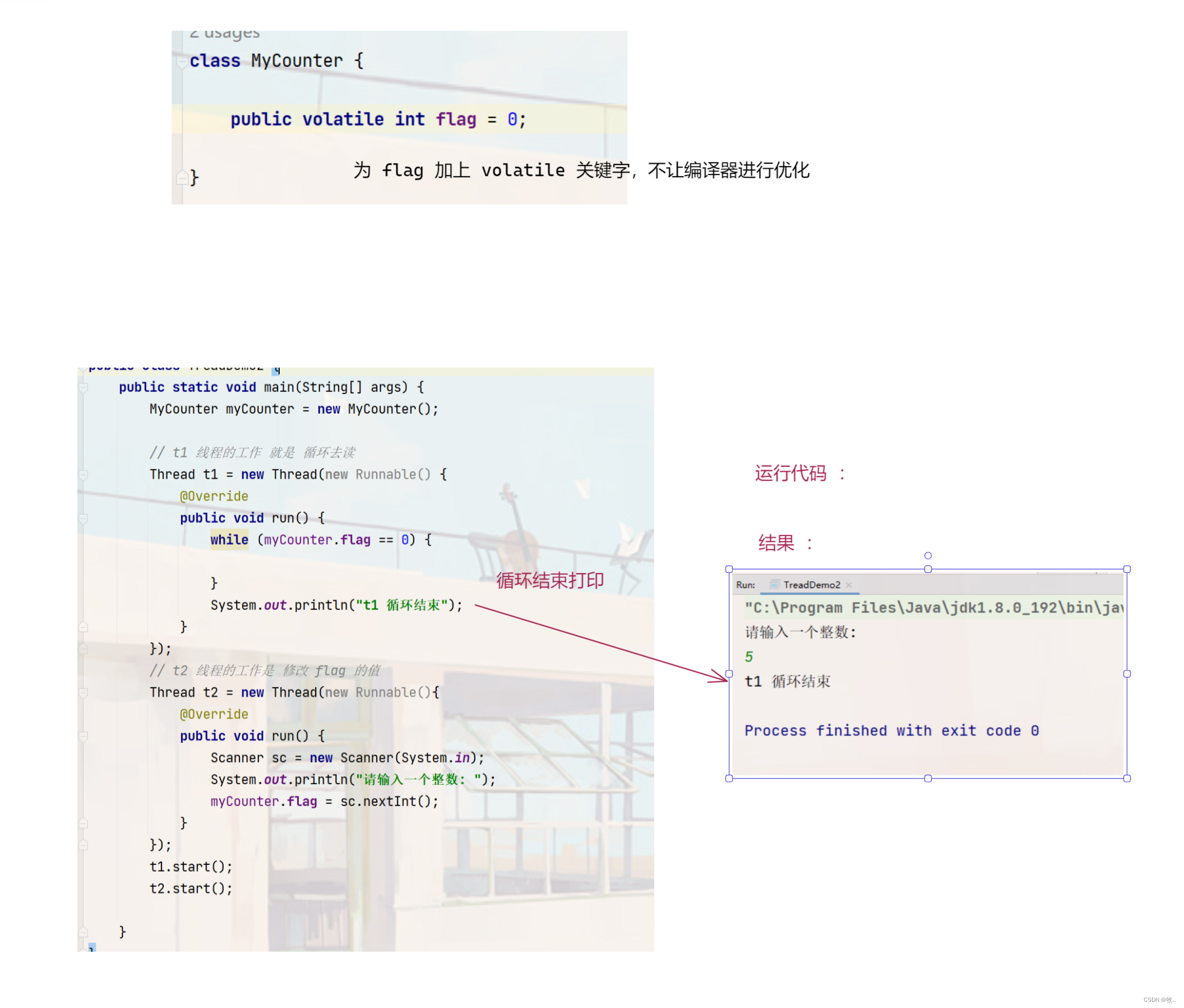
注意 : volatile 只能修饰变量 ,不能取修饰方法
再扩充一点 :
volatile 不能给方法里的局部变量使用 , 在方法中定义的变量只能在你当前的线程里面用 , 就不会有多线程之间同时读取/修改 此时就天然的避开了线程安全问题
局部变量 : 只能在当前方法里面使用,出了方法变量就没了,方法内部的变量在 栈 这样的内存空间上 ,
每个线程都有自己的栈空间 (栈 记录了方法之间的调用关系 ) .
即使是同一个方法,在多个线程中被调用,这里的局部变量也会处在不同的栈空间中,本质上是不同变量.
下面来看另外一段代码 :

可以看到 加上sleep 后 控制了循环的速度之后,即便没有加 volatile 也没出现 内存可见性的问题.
这段代码只要想说 ,编译器优化的问题,并不是始终会出现的 , 编译器可能存在误判,但是并不是100% 就误判.
大多时候 编译器的优化,就比较玄学,站在 应用程序这个角度是无法感知到的 , 所以针对内存可见性的问题,最稳妥的做法还是将该加volatile 的地方都加上 .
拓展 (了解即可)
关于内存可见性 在一些资料 中 会谈到 JMM 也就是 java Memory Model ,java 内存模型 .
从 JMM 的角度 重新表述内存可见性问题 :
java 程序里 ,有一个主内存, 每个线程还有自己的工作内存(t1 和 t2 的工作内存 不是同一个东西)
t1 线程进行读取的时候,只是读取了工作内存的值
t2 线程进行修改的时候,先修改的工作内存的值, 然后再把工作内存的内容同步到主内存中.
但是由于编译器优化 导致 t1 没有重新的从主内存同步到工作内存,读到的结果就是 修改之前的结果
上述这里的表述来自java的官方文档 、 我们看上面这一段就非常抽象, 啥主内存, 工作内存 等 很难理解.
这里将 主内存 替换成 内存 , 工作内存 替换成 CPU 寄存器 就于我们上面一样的.
那么这里就有一个问题 既然都是一样的 为啥 java 自己非得弄一些新的词 呢 ? 啥主内存,啥工作内存,这工作内存又不是内存等 。
之所以上面这段话这么别扭, 其实是翻译导致的, 翻译的结果让人误会了 。
主内存 : main memory 主存 ,其实就是 内存
工作内存 : work memory 这里翻译成成工作内存不好 ,翻译成 工作 存储区 就顺了。
另外 : work memory 并非我们所说的内存,而是 cpu上存储数据的单元(寄存器)
既然 work memory 是 cpu上存储的数据单元(寄存器) ,那么为啥 java 这里 不直接叫做 CPU 寄存器 而是专门搞了工作内存 说法呢 ?
因为 我们的工作内存 并不一定只是 CPU 的寄存器 ,还可能包含CPU的缓存 chache
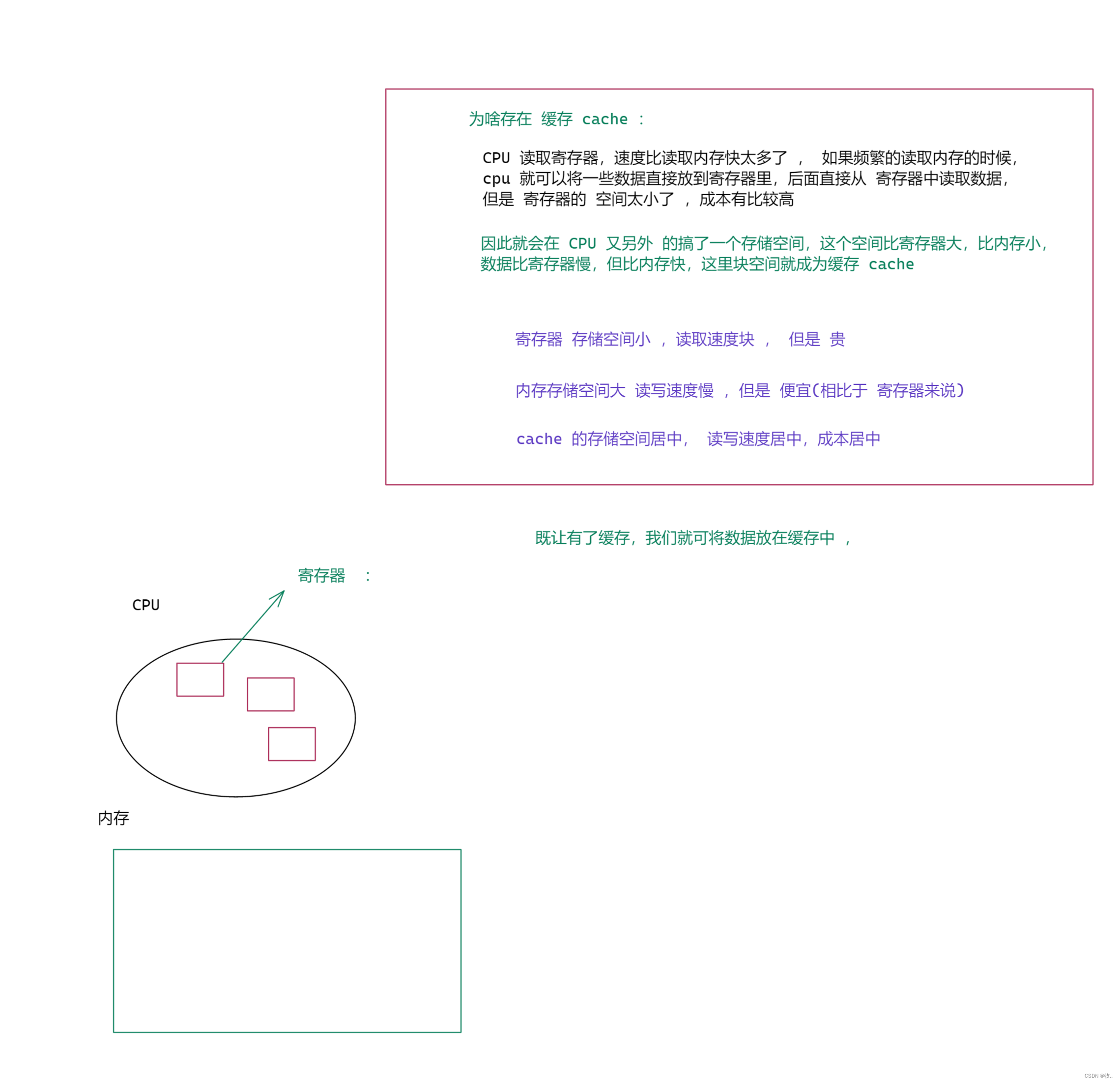
另外 注意 我上面写的措辞 是可能 含有 cpu的缓存 , 这是因为 有的 cpu 上可能没有 cache ,有的有 , 这里 还能有多个, 再我们现在这个时代, 普遍是 3级缓存 L1 ,L2 , L3 。
java 为了表述简单和避免涉及到硬件的细节和差异,java 就使用 工作内存这一词一言蔽之了。
关于 volatile 还有一点 需要 重点记一下 :
volatile 不能保证 原子性, 原子性是靠 synchronized来保证的,
另外 : volatile 和 synchronized 都能保证线程安全 , 他们解决线程安全的场景是不一样的.
如 : volatile 是解决一个线程 读, 一个线程写的场景。
synchronized ,两个线程对 同一个变量进行修改的操作, 这里使用 volatile 线程还是会出现线程安全的问题 .
演示 :
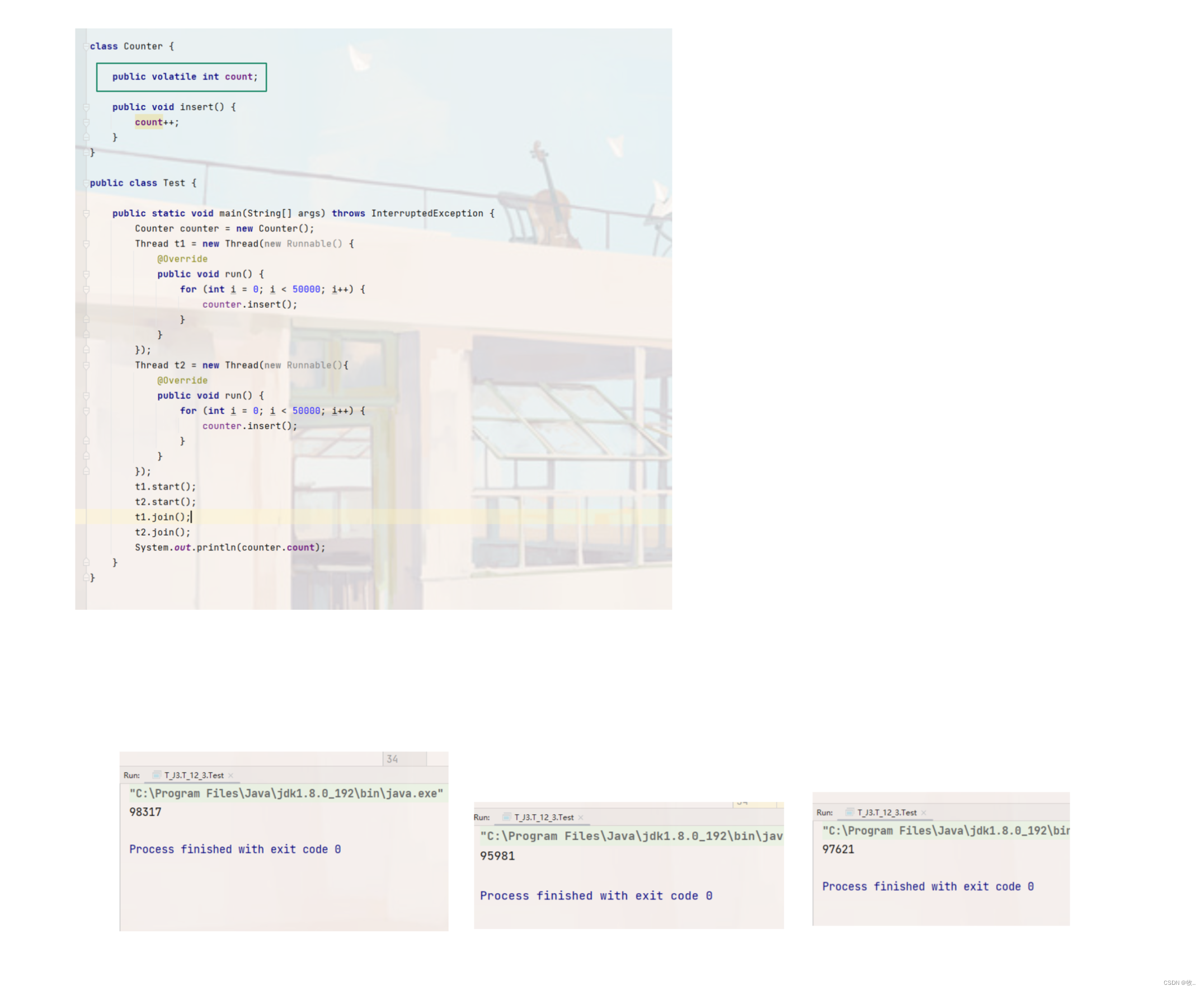
这里 volatile 就看完了,下面进入下一个话题 ,
7.wait 和 notify
wait 和 notify 为了处理线程调度随机性的问题。
线程最大的问题 就是抢占式执行, 随即调度, 程序猿写代码,并不喜欢随机的, 而是喜欢确定的。
所以 程序猿 就发明了一些办法,来控制线程之间的执行顺序 ,虽然 线程在内核里的调度是随机的,但是可以通过一些 api 让线程主动阻塞,主动放弃 CPU ,给其他线程让路.
举个例子 :
t1 和 t2 两个线程 ,希望 t1 先干活 , 干的差不多, 再让 t2 来干 ,此时就可以让 t2 先 wait (阻塞 , 主动放弃 cpu) ,等 t1 的活 干的差不多了, 再通过notify 通知 t2 ,把t2 唤醒 ,让 t2 接着干 .
这里就有一个问题 : 这里我们使用 join 和 sleep 不也能够 让两个线程 一个先执行一个后执行吗 ?
这里我只能说, 小伙 要仔细看例子了, 这里是 t1先干一大半的活,t2 再执行.
如果 使用 join 则必须要 t1彻底执行完 ,t2 才能运行 ,
此时希望 t1 先干 50% 就让 t2 开始行动 , join 就无能为力了。
另外 : 使用 sleep 也是不行的 。
使用 sleep 可以指定 一个休眠时间的,但是t1 执行的这些活,需要花费多少时间不好估计 , 想要让t1执行 一半 , sleep 休眠的时间 就不要确定。
总的来说 wait 和 notify 是用来协调线程的执行顺序, 关于协调线程的执行顺序 其实是有三个 除了 wait 和 notify 还有一个 notifyAll , 这三个方法都是属Object 类的方法 (所有的类 都默认继承 Object 所以 所以一个类 都会有 这三个方法 ).
下面就来 看看这三个方法如何使用 :
1.wait 进行阻塞
某个线程调用 wait 方法 , 就会进入阻塞 (注意 : 不管是那个对象调用的 wait 都会进入阻塞) , 此时 就处于 WAITING 状态 。
图一 :

图二 :
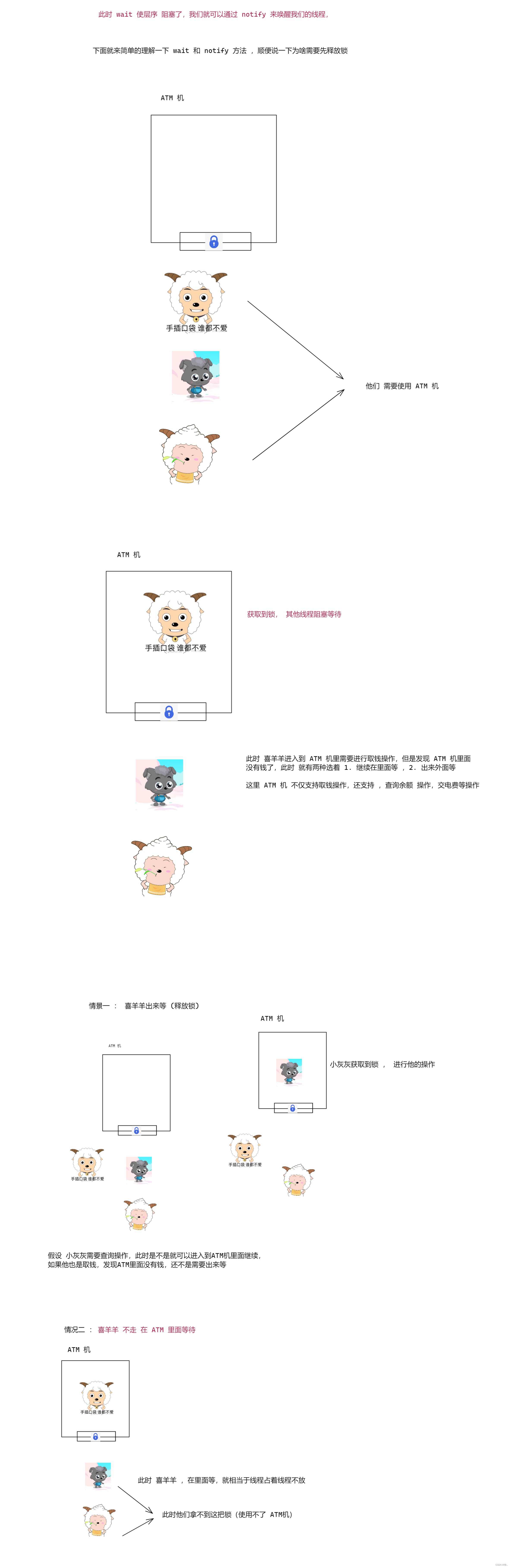
图三 :
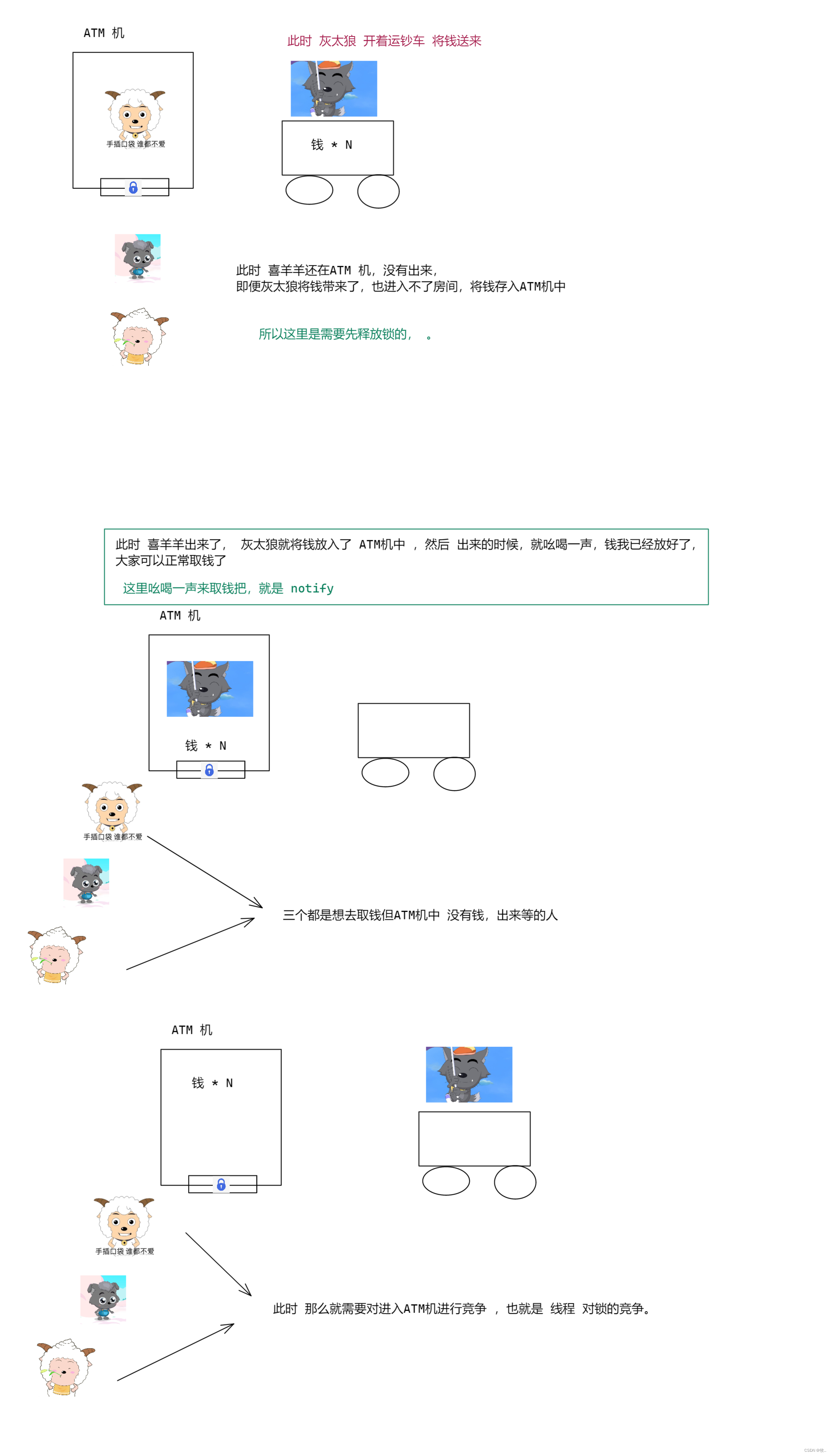
看完上面的图 就能知道 notify 方法的作用 其实就是 将等待的线程唤醒
注意:
- 方法notify()也要在同步方法或同步块中调用,该方法是用来通知那些可能等待该对象的对象锁的其它线程,对其发出通知notify,并使它们重新获取该对象的对象锁。
- 如果有多个线程等待,则有线程调度器随机挑选出一个呈 wait 状态的线程。(并没有 “先来后到”)
- 在notify()方法后,当前线程不会马上释放该对象锁,要等到执行notify()方法的线程将程序执行完,也就是退出同步代码块之后才会释放对象锁。
代码演示 :

补充 : wait带参数的版本

到此我们知道了 wait 是 让线程等待 , notify 是唤醒等待的 线程,下面我们来完成一个小作业 .
写一段代码 , 分别打印 ABC 保证 三个线程 固定 按照 ABC 这样的顺序来打印。
图一 :

图二 :

最后来看一下 notifyAll()方法
notify方法只是唤醒某一个等待线程. 使用notifyAll方法可以一次唤醒所有的等待线程
代码演示 :

加深印象 : 通过 图片更好的记住 notify 和 notifyAll 的区别
notify 只唤醒等待队列中的一个线程. 其他线程还是乖乖等着

notifyAll 一下全都唤醒, 需要这些线程重新竞争锁