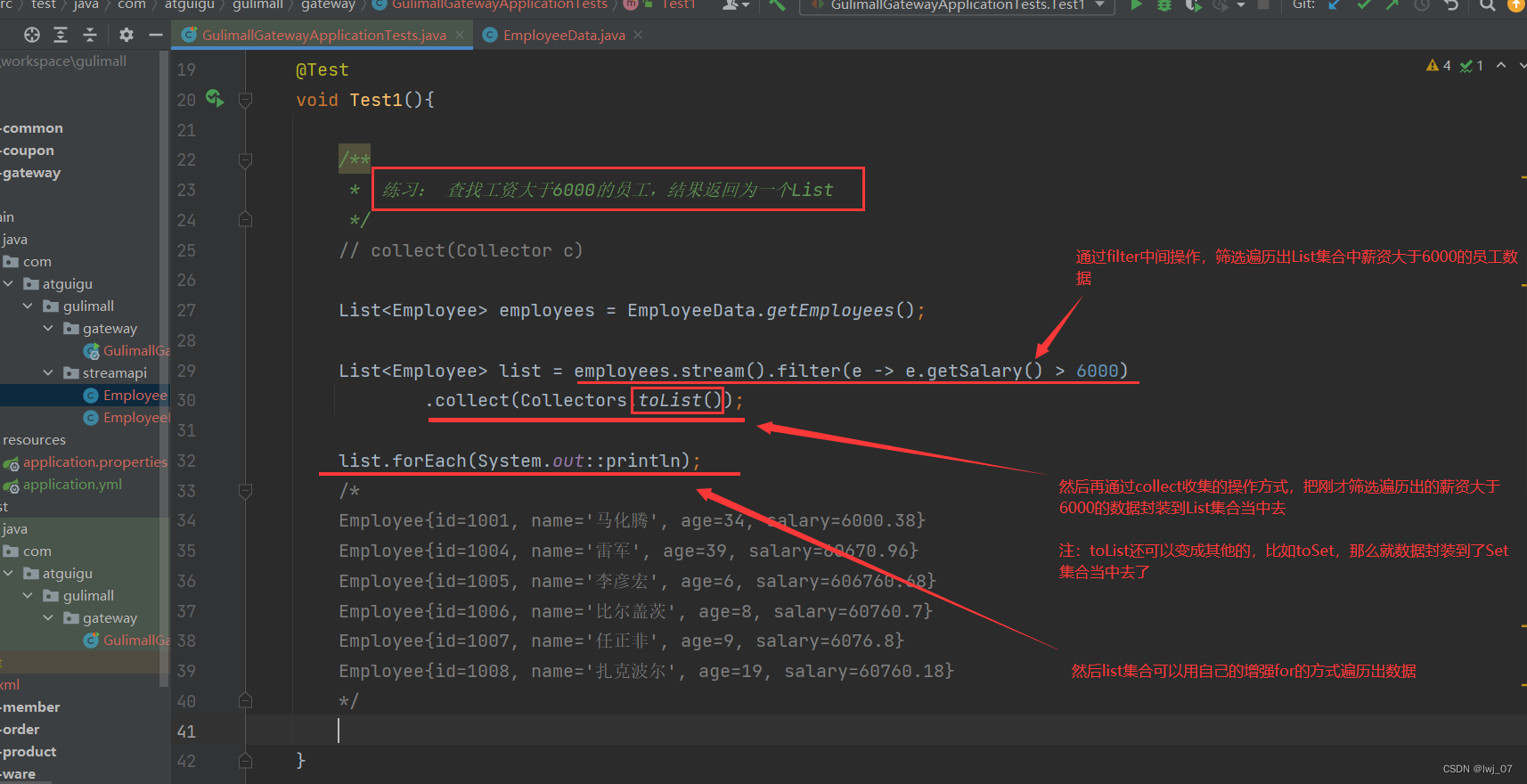
补知识点:Stream API
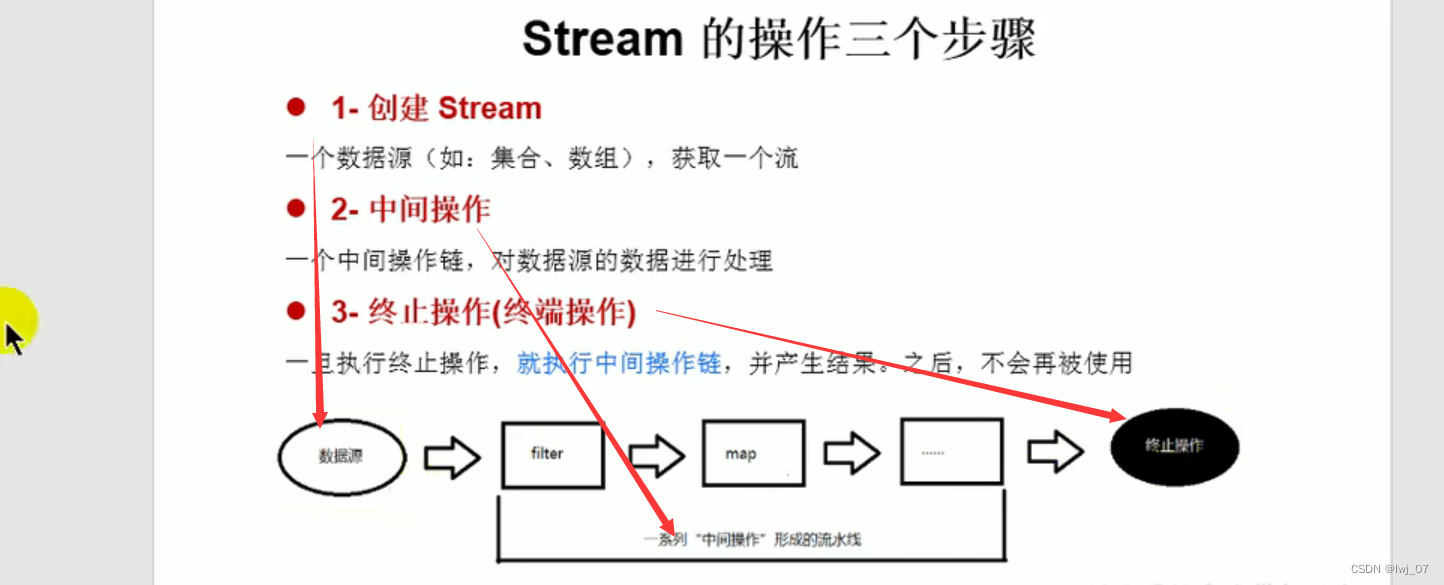
一、创建Stream
首先创建Stream的话,有四种创建方式:
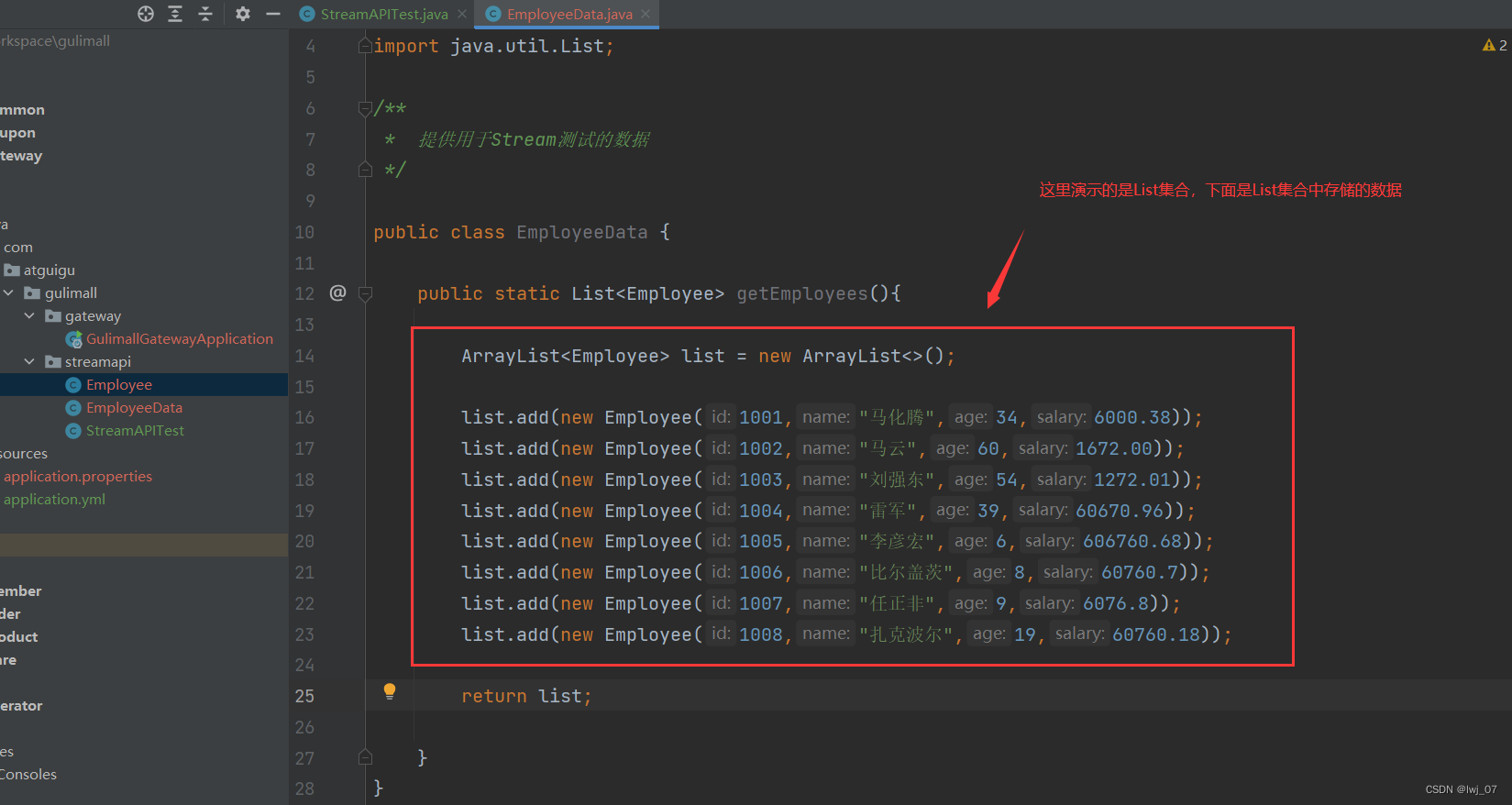
注: 第一种集合的方式是最常用的
package com.atguigu.gulimall.gateway;
import com.atguigu.gulimall.streamapi.Employee;
import com.atguigu.gulimall.streamapi.EmployeeData;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
import java.util.List;
import java.util.stream.IntStream;
import java.util.stream.Stream;
@SpringBootTest
class GulimallGatewayApplicationTests {
/**
* 第一种创建Stream的方式: 通过集合,调用stream方法,返回的是一个顺序流
*
* 返回的是一个顺序流 : 也就是说使用stream流遍历集合中的数据的时候,遍历出来时就是按照添加到集合中的
* 那个数据顺序遍历出来的
*/
@Test
void Test1(){
List<Employee> list = EmployeeData.getEmployees(); // 通过调用刚才那个类 就拿到刚才那个List集合了
Stream<Employee> stream = list.stream(); // 集合通过调用stream方法就创建出Stream了
}
/**
* 第一种创建Stream的方式: 也是通过集合
* 不过调用的不再是stream方法,而是 parallelStream方法,返回的是一个并行流
*
* 返回的是一个并行流: 也就是说遍历出来集合中的数据的时候,不是按照顺序遍历出来的,而是相当于线程,各跑各的
* 因此遍历出来的集合中的数据是没有顺序的
*/
@Test
void Test2(){
List<Employee> list = EmployeeData.getEmployees(); // 通过调用刚才那个类 就拿到刚才那个List集合了
Stream<Employee> stream = list.parallelStream(); // 集合通过调用stream方法就创建出Stream了
}
/**
* 第二种方式: 通过数组
*
* 直接用 Arrays.stream调用数组即可
*/
@Test
void Test3(){
int[] arr =new int[]{1,2,3,4,5,6};
IntStream stream = Arrays.stream(arr);
}
/**
* 第三种方式: 通过Stream的of()
*/
@Test
void Test4(){
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);
}
/**
* 第四种方式: 创建无限流 (不常用)
*/
}
二、中间操作
注意:不执行终止操作的话,中间操作是不会执行触发的。
下面的.forEach(System.out::println);就是终止操作,里面可以不是sout,可以是其他的。
也就是说通过上面的四种方式,Stream流就创建好了,然后就可以进行中间操作了:
中间操作的话,也分为三种情况:
第一种:筛选与切片
第二种:映射
第三种:排序
2.1、中间操作----筛选与切片

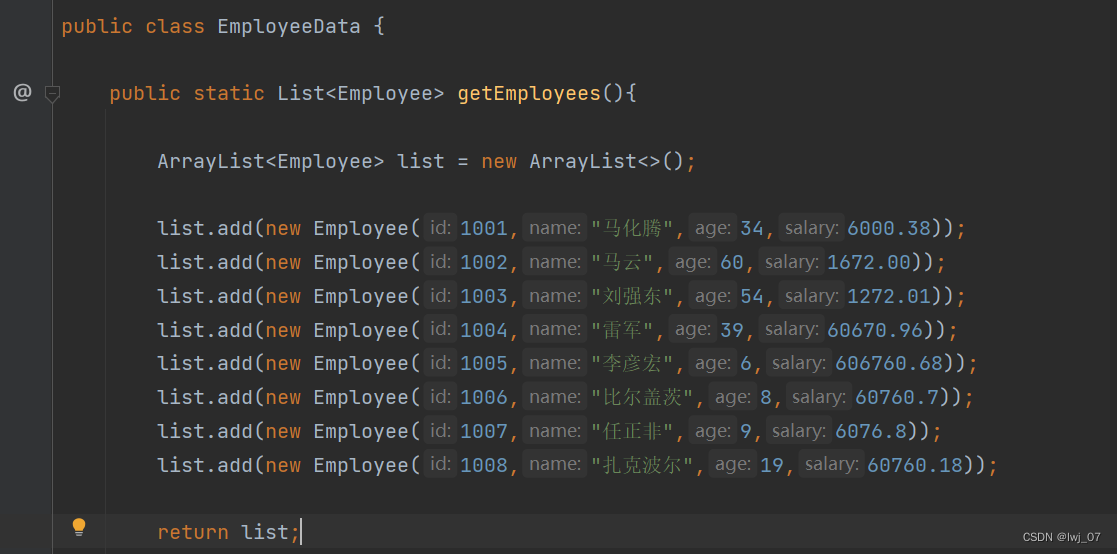
同理我们还是先把List集合中的数据展示出来:
filter:
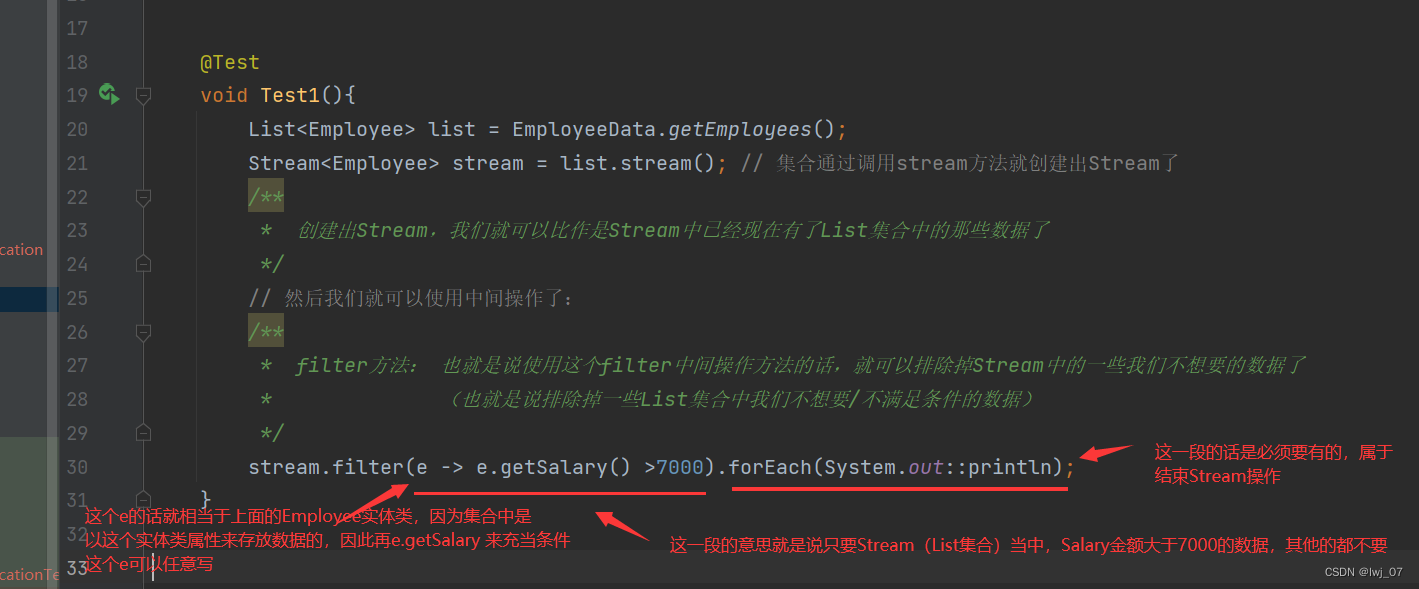
接受Lambda,从流中排除某些元素 (也就是说从集合中排除掉我们不想要的元素)
@Test
void Test1(){
List<Employee> list = EmployeeData.getEmployees();
Stream<Employee> stream = list.stream(); // 集合通过调用stream方法就创建出Stream了
/**
* 创建出Stream,我们就可以比作是Stream中已经现在有了List集合中的那些数据了
*/
// 然后我们就可以使用中间操作了:
/**
* filter方法: 也就是说使用这个filter中间操作方法的话,就可以排除掉Stream中的一些我们不想要的数据了
* (也就是说排除掉一些List集合中我们不想要/不满足条件的数据)
*/
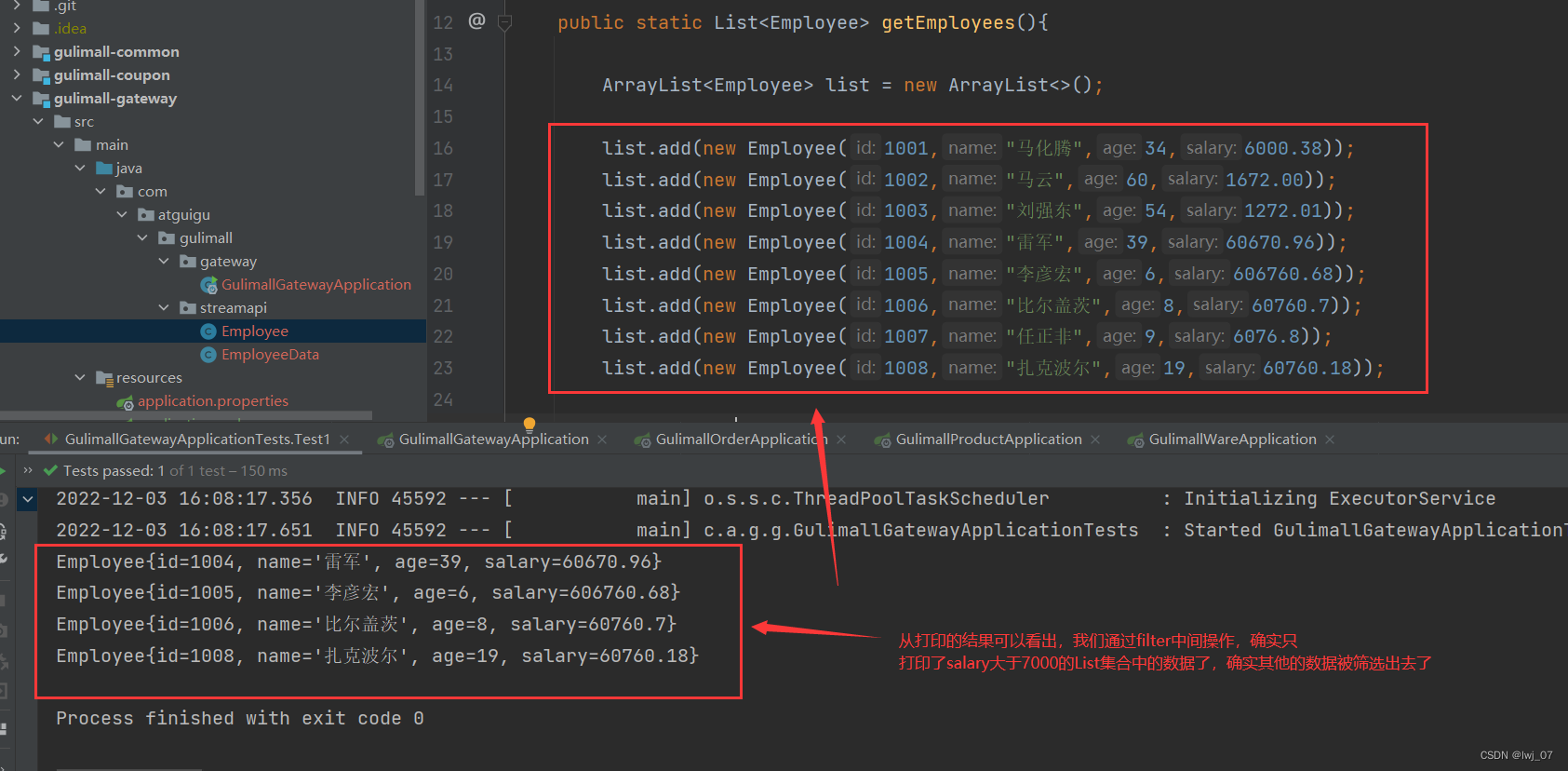
stream.filter(e -> e.getSalary() >7000).forEach(System.out::println);
}
limit:
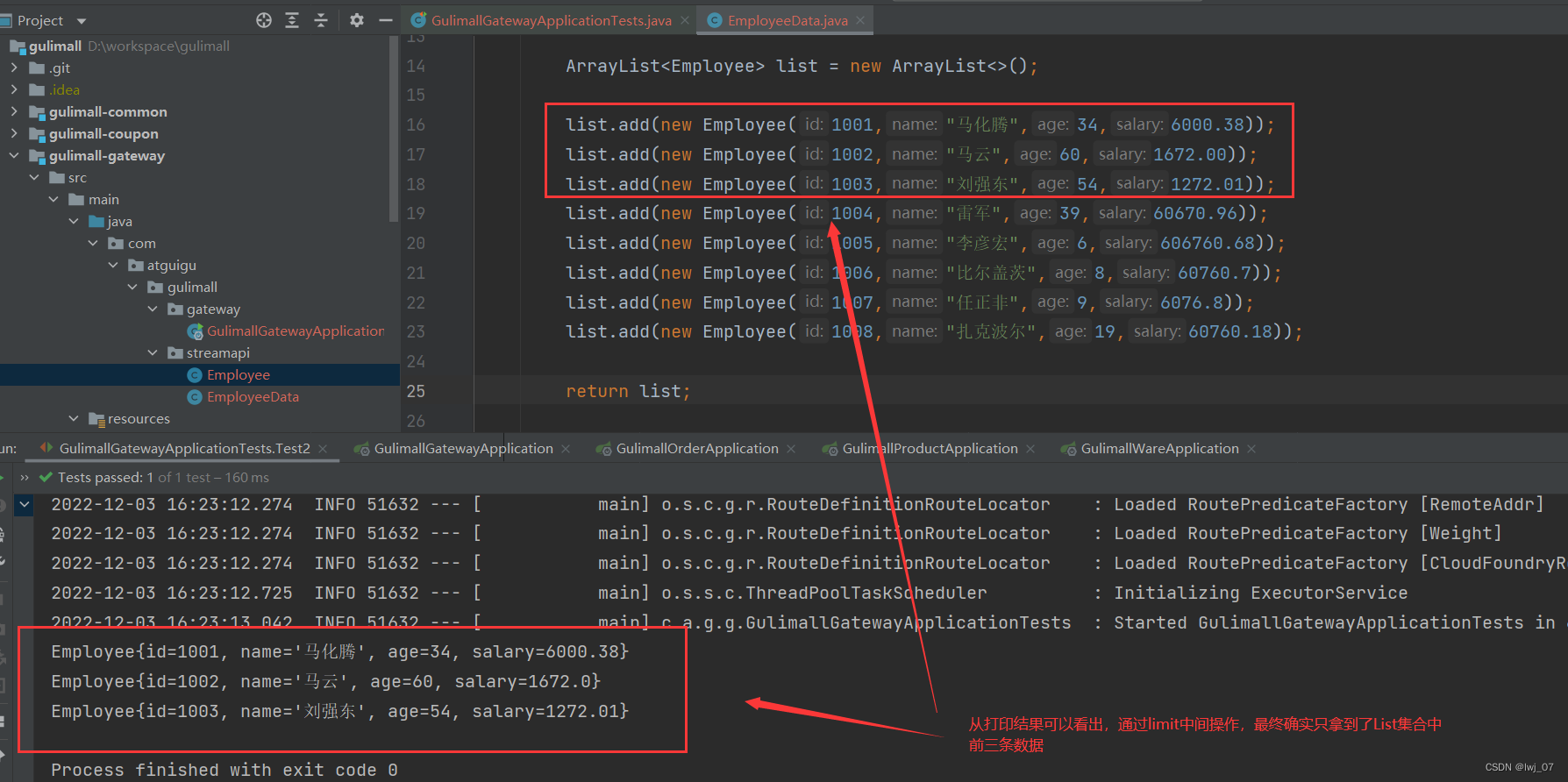
截断流,使其元素不超过给定数量
(大白话说:也就是说假定我们List集合(Stream)当中有60条数据,但是我们使用这个limit中间操作设定为6,那么我们这个Stream流就只遍历List集合中前6条数据)
@Test
void Test2(){
List<Employee> list = EmployeeData.getEmployees();
Stream<Employee> stream = list.stream(); // 同理,相当于现在Stream已经拿到了全部的List集合中的数据了
stream.limit(3).forEach(System.out::println); // 中间操作进行筛选,最后通过forEach终止操作进行打印结果
}
skip:
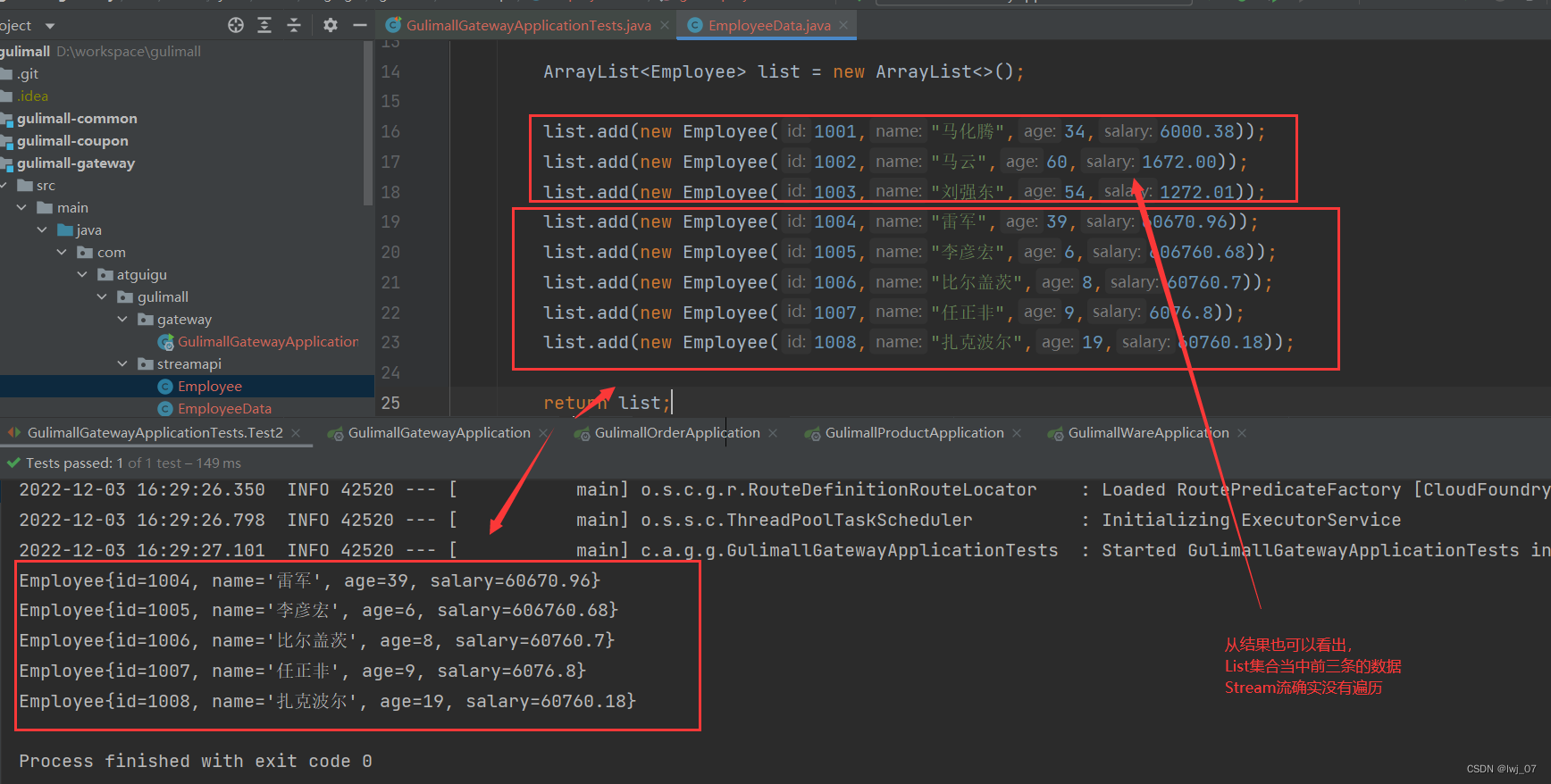
也就是说,我们通过给这个skip中间操作指定一个数字,比如指定3,那么我们Stream流遍历List集合中的元素数据的时候,就会跳过前三条数据,也就是说前三条数据不遍历出来了,只遍历前三条以外的其他的数据
@Test
void Test2(){
List<Employee> list = EmployeeData.getEmployees();
Stream<Employee> stream = list.stream(); // 同理,相当于现在Stream已经拿到了全部的List集合中的数据了
stream.skip(3).forEach(System.out::println);
}
distinct:
也就是说去重的意思,比如List集合当中存放的数据有几条是一模一样的,那么Stream流遍历List集合中的数据的时候,只要一条该数据就可以了,其他重复的数据直接去除掉。
@Test
void Test2(){
List<Employee> list = EmployeeData.getEmployees();
Stream<Employee> stream = list.stream(); // 同理,相当于现在Stream已经拿到了全部的List集合中的数据了
stream.distinct().forEach(System.out::println);
}注意: 表示的是对象内存地址一模一样的时候,才会去重,如果仅仅是数据一样那么有可能会去除不掉(是看内存地址的)
2.2、中间操作----映射
map: (常用)
map的话也是中间操作,和上面的筛选和切片的用法大致上是一样的,只不过作用不同。
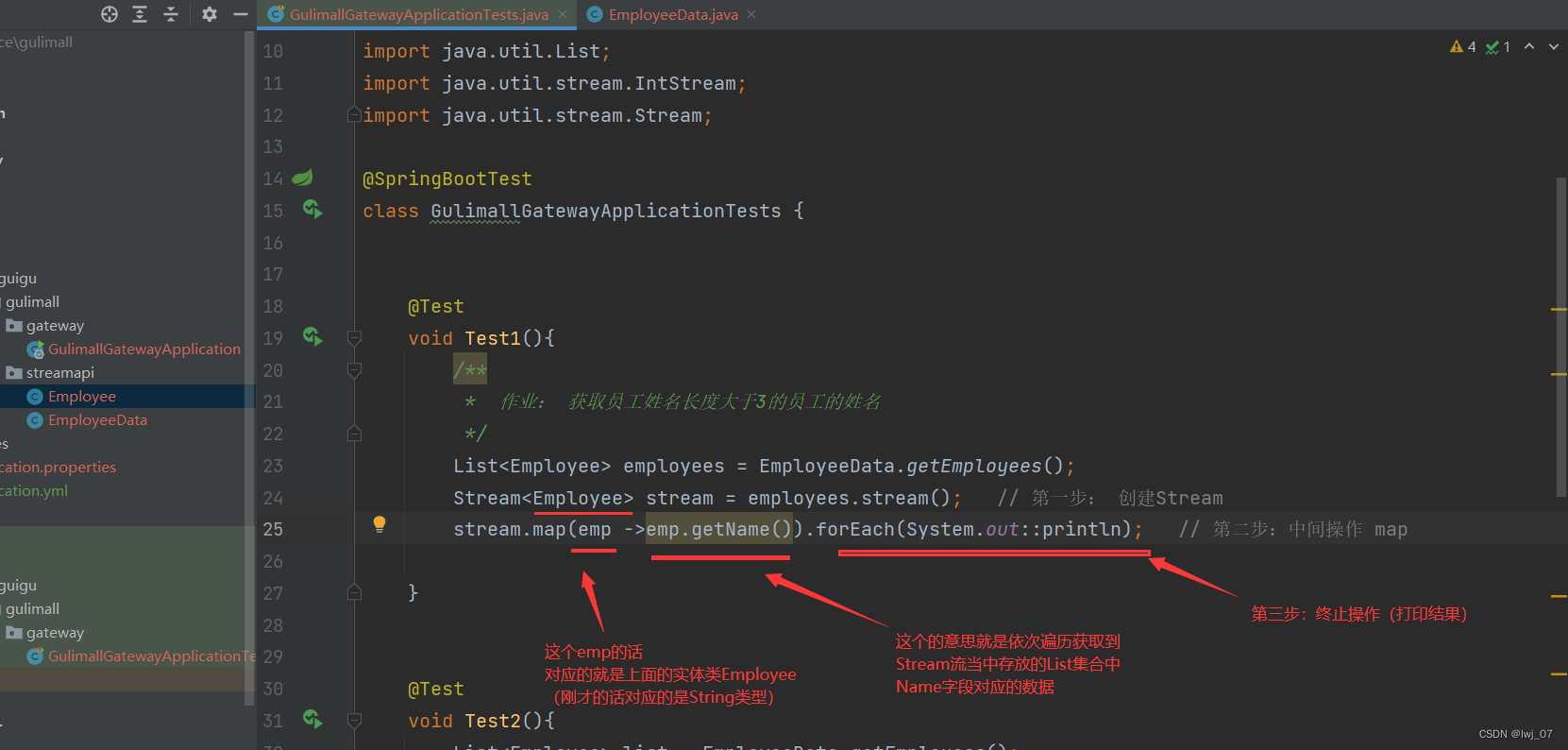
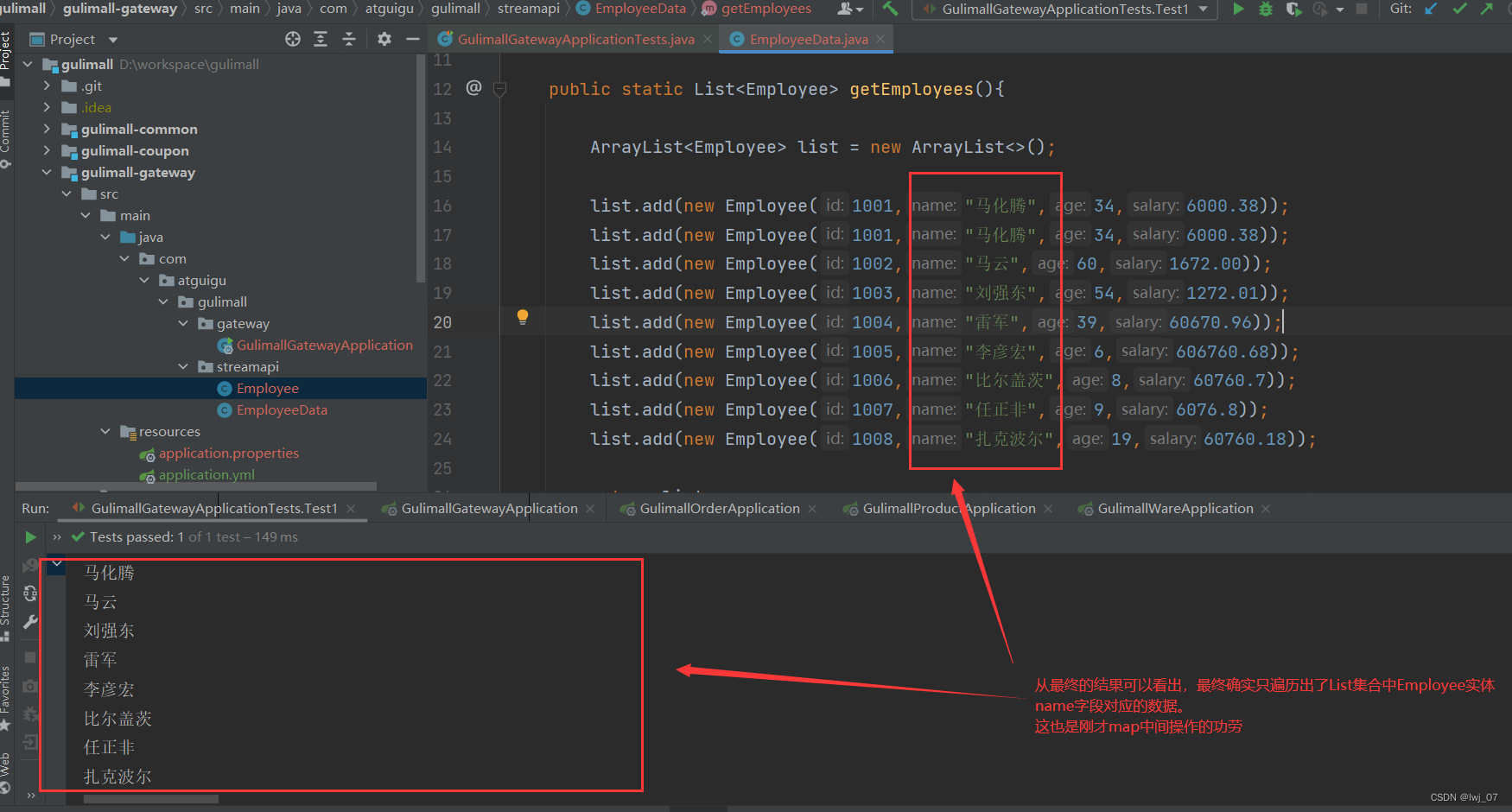
map的作用1: 就是说可以把集合中的数据,转换成其他的类型
map的作用2:可以把Stream流当中的List集合数据,单独的获取出来
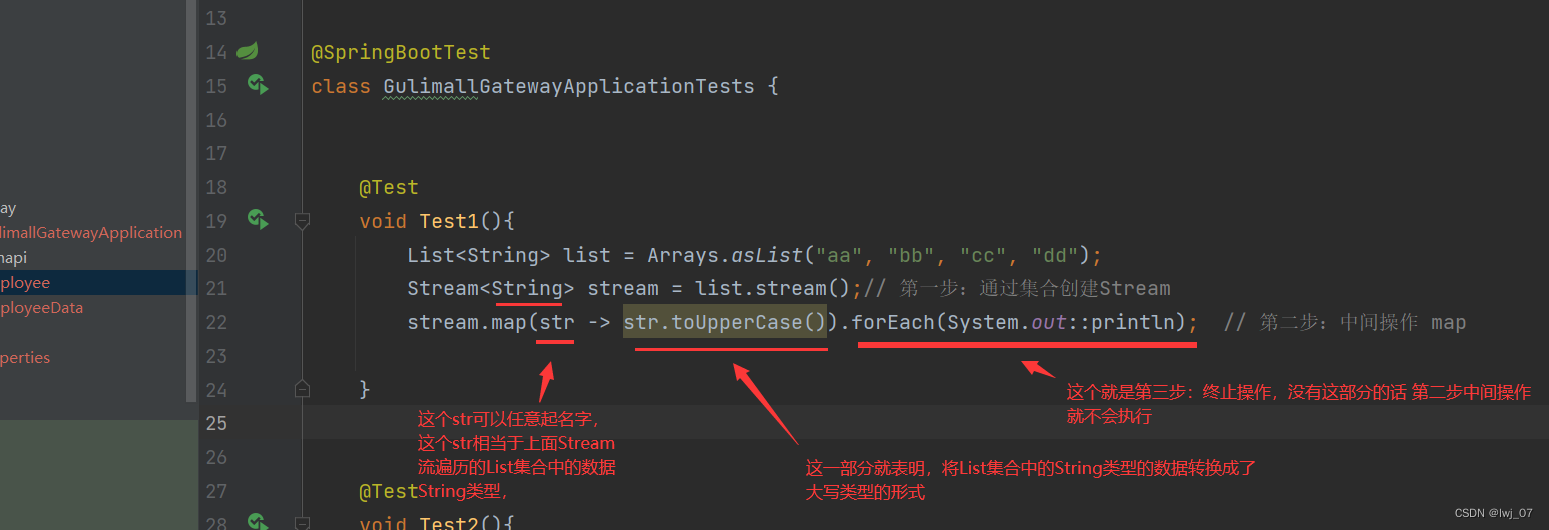
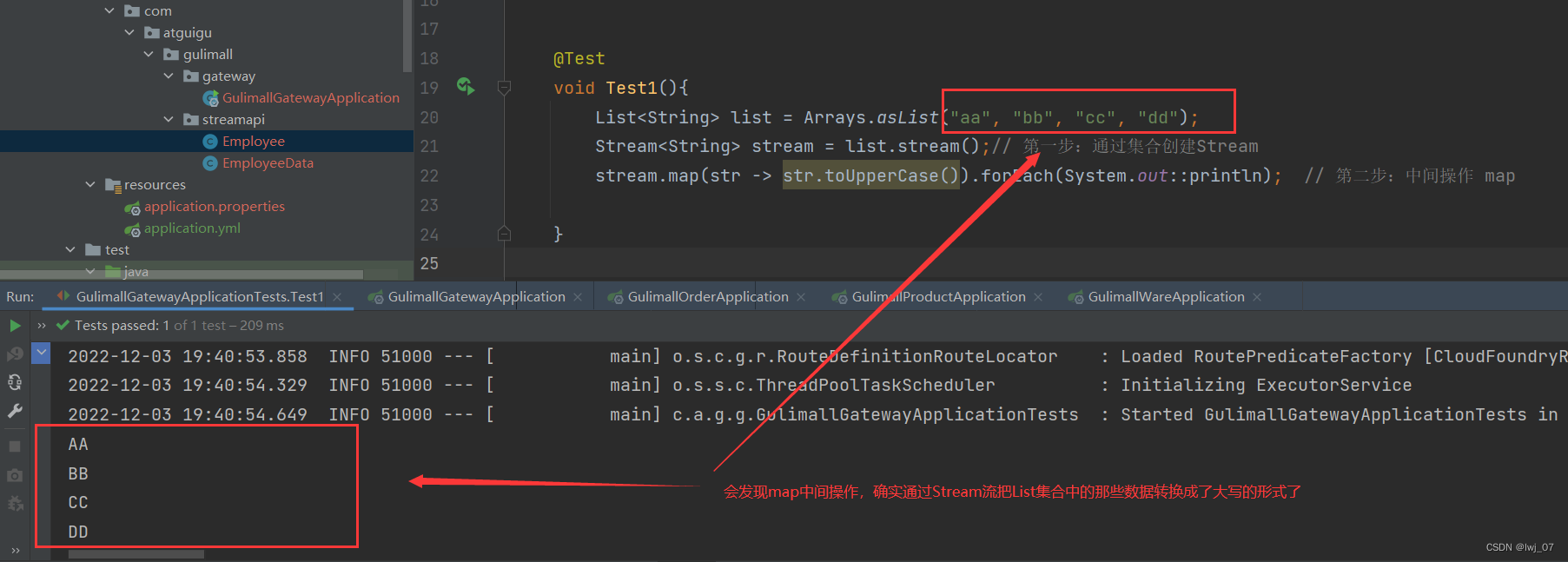
@Test
void Test1(){
List<String> list = Arrays.asList("aa", "bb", "cc", "dd");
Stream<String> stream = list.stream();// 第一步:通过集合创建Stream
stream.map(str -> str.toUpperCase()).forEach(System.out::println); // 第二步:中间操作 map
}
作用二演示:
例子演示(*****):
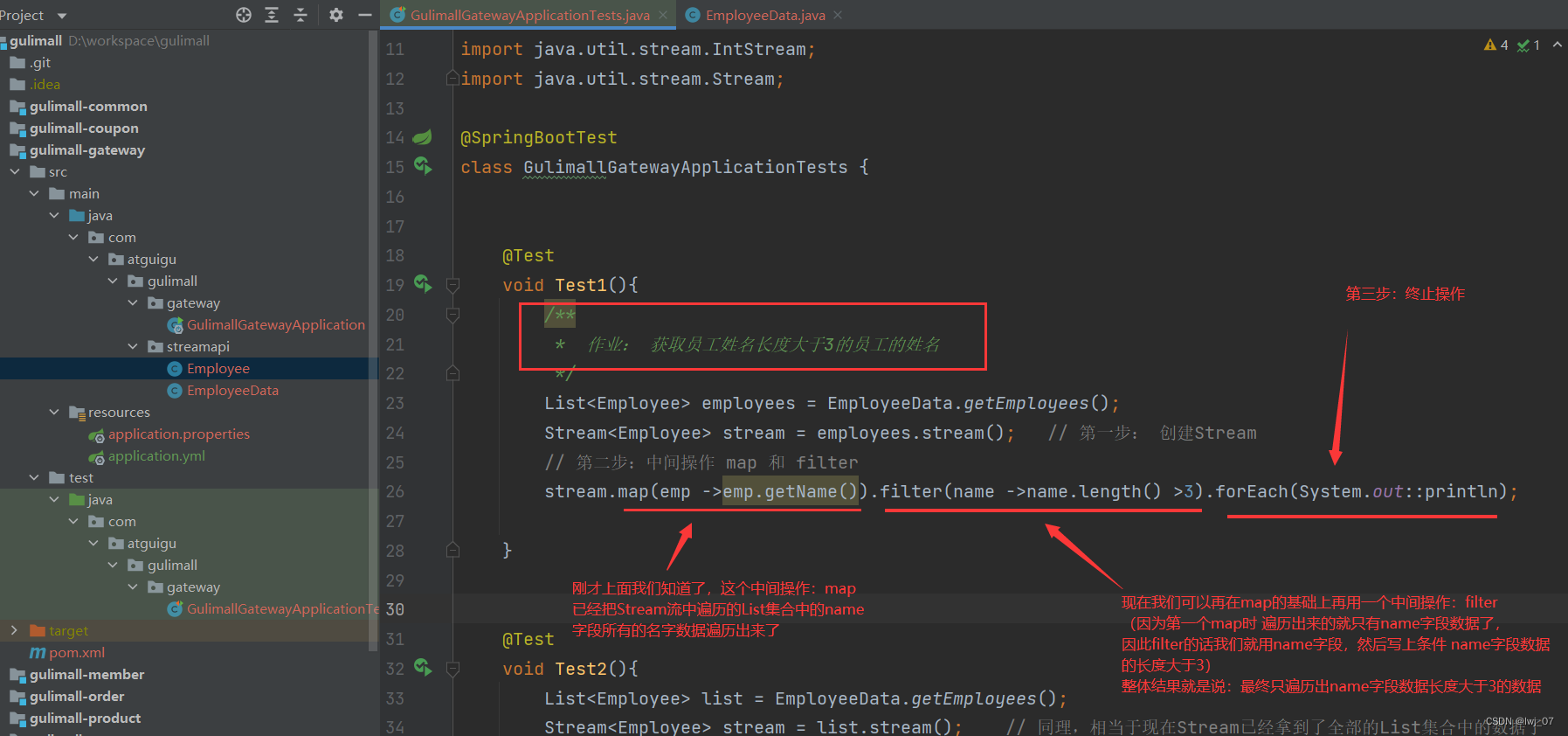
flatmap:
2.3、中间操作----排序
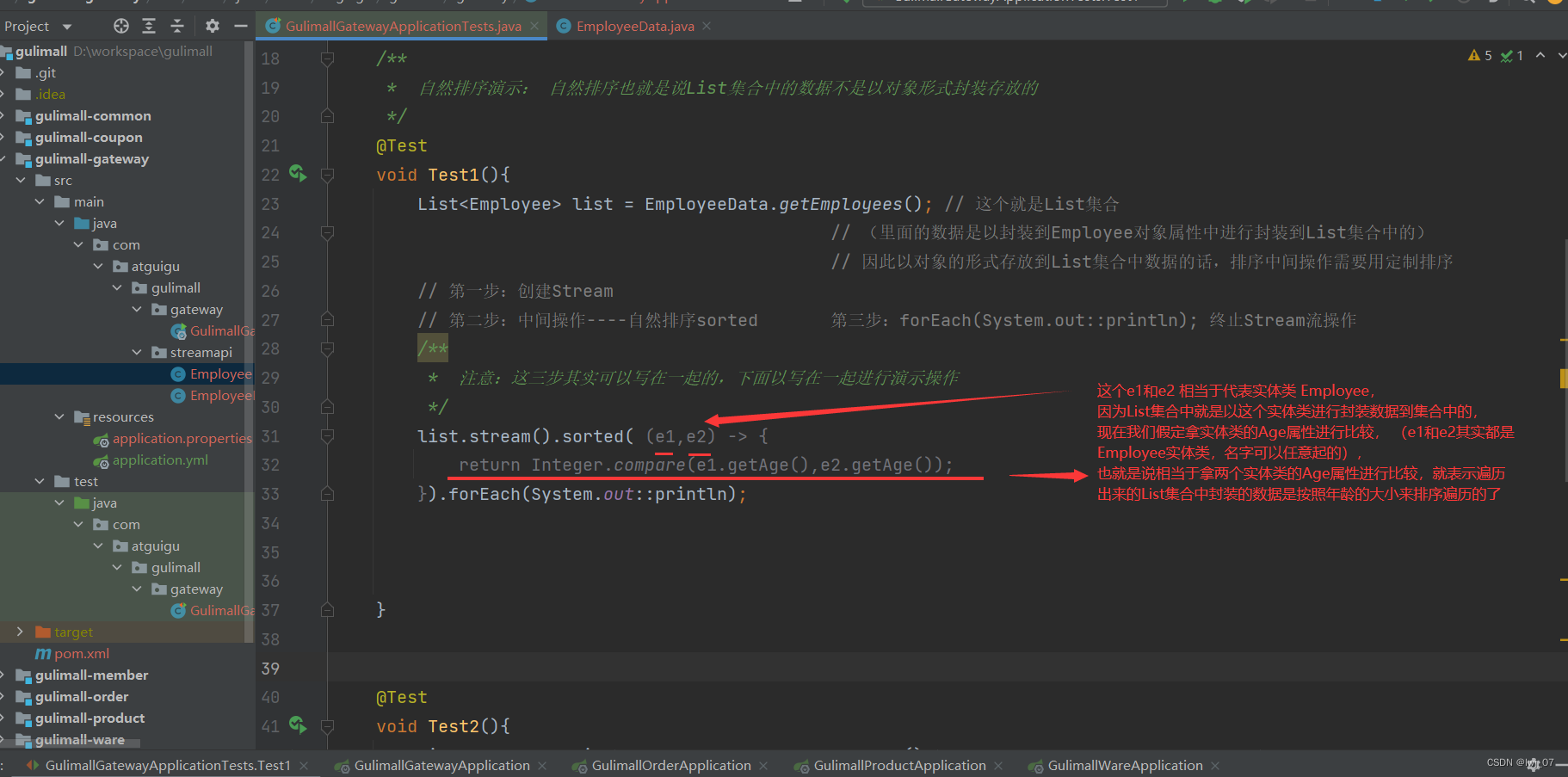
排序的话,分为 自然排序 和 定制排序。
自然排序:是对List集合中的不是以对象形式封装存放的数据进行排序的。
定制排序:如果List集合中存放的是以对象的形式进行存放数据到List集合中的话,那么就需要用定制排序了,要不然就会报错。
sorted()----自然排序:
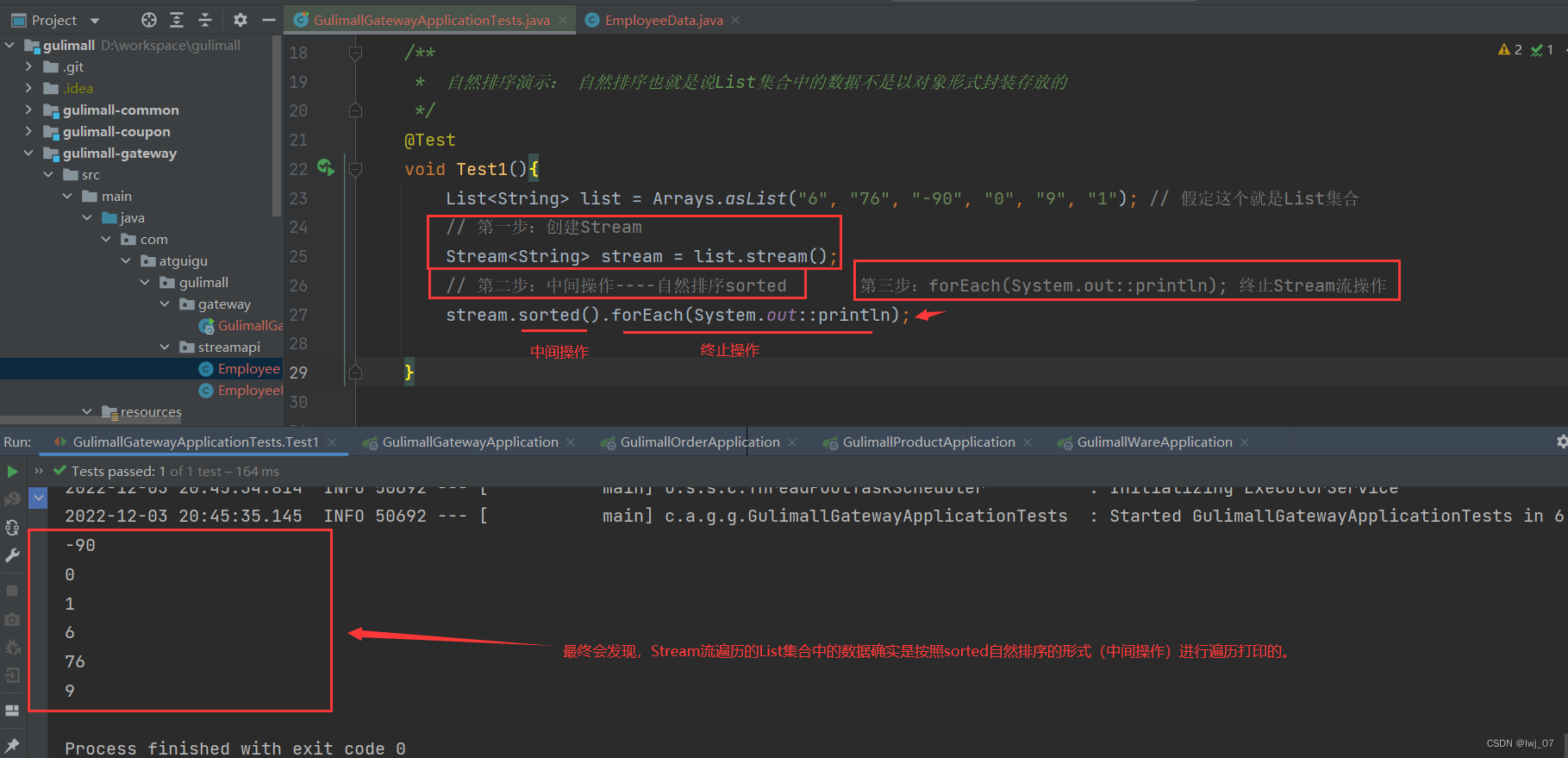
sorted()----定制排序:
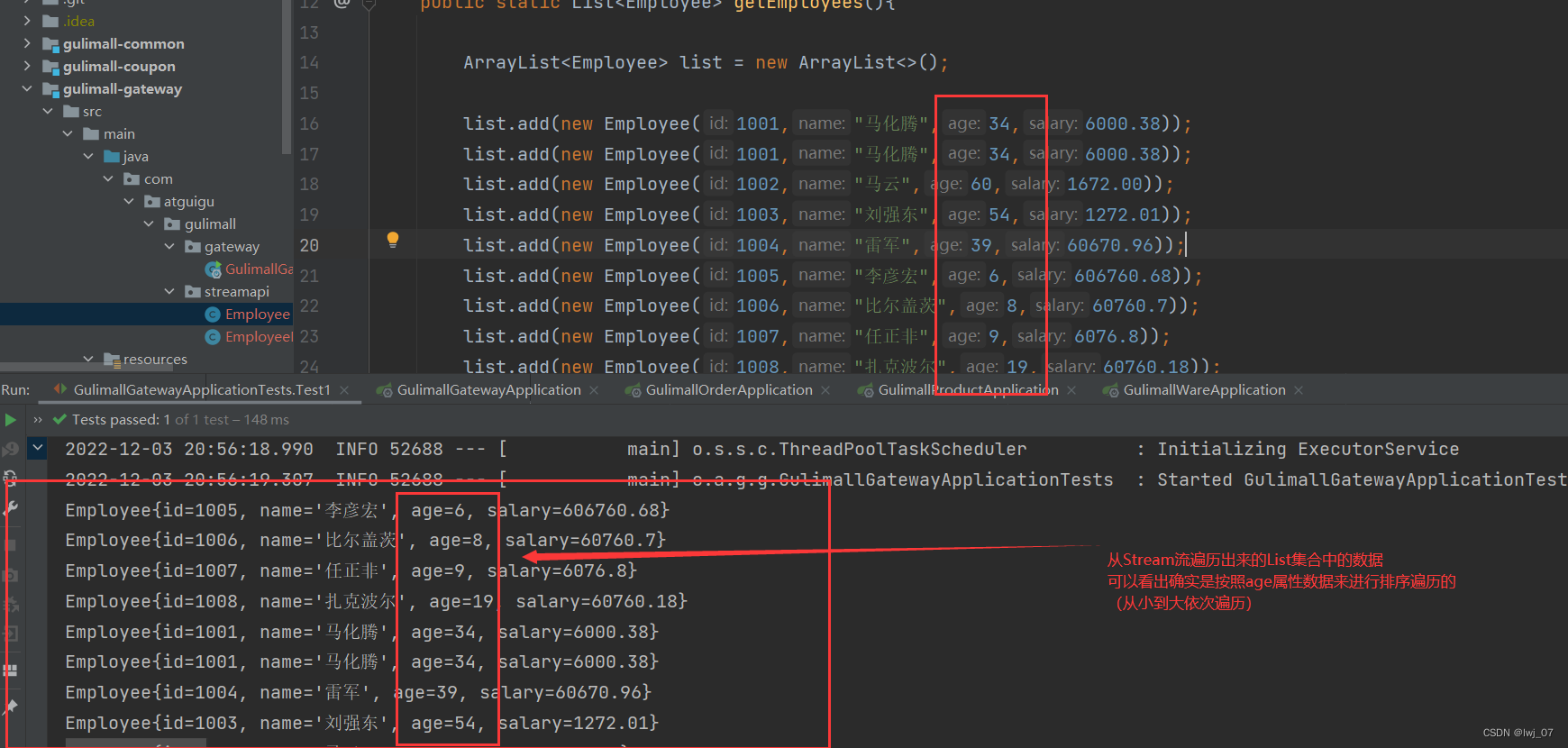
补充知识:
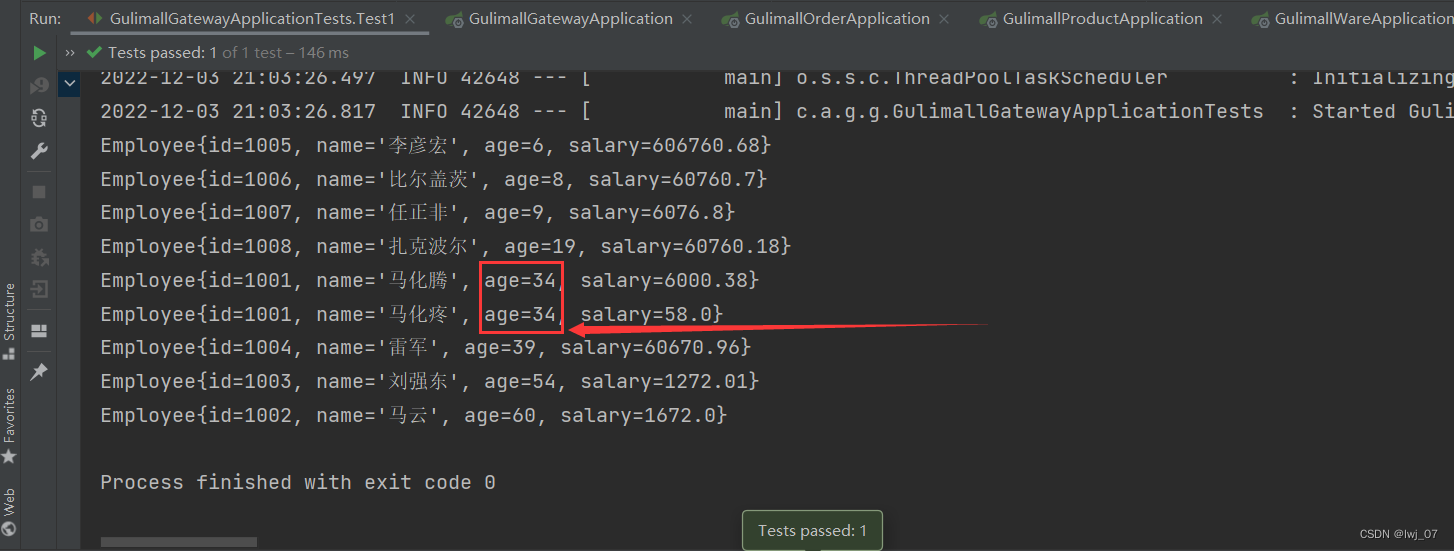
我们有可能会发现,上面通过排序Stream流遍历出List集合中的数据后,有可能我们根据age排序的时候,有的数据age是一样的,那么就不会再对这两个一样的进行排序先后位置了,那么我们该如何 再给如下:这两个age数据相同的数据进行一下排序呢 (整个先后顺序)?
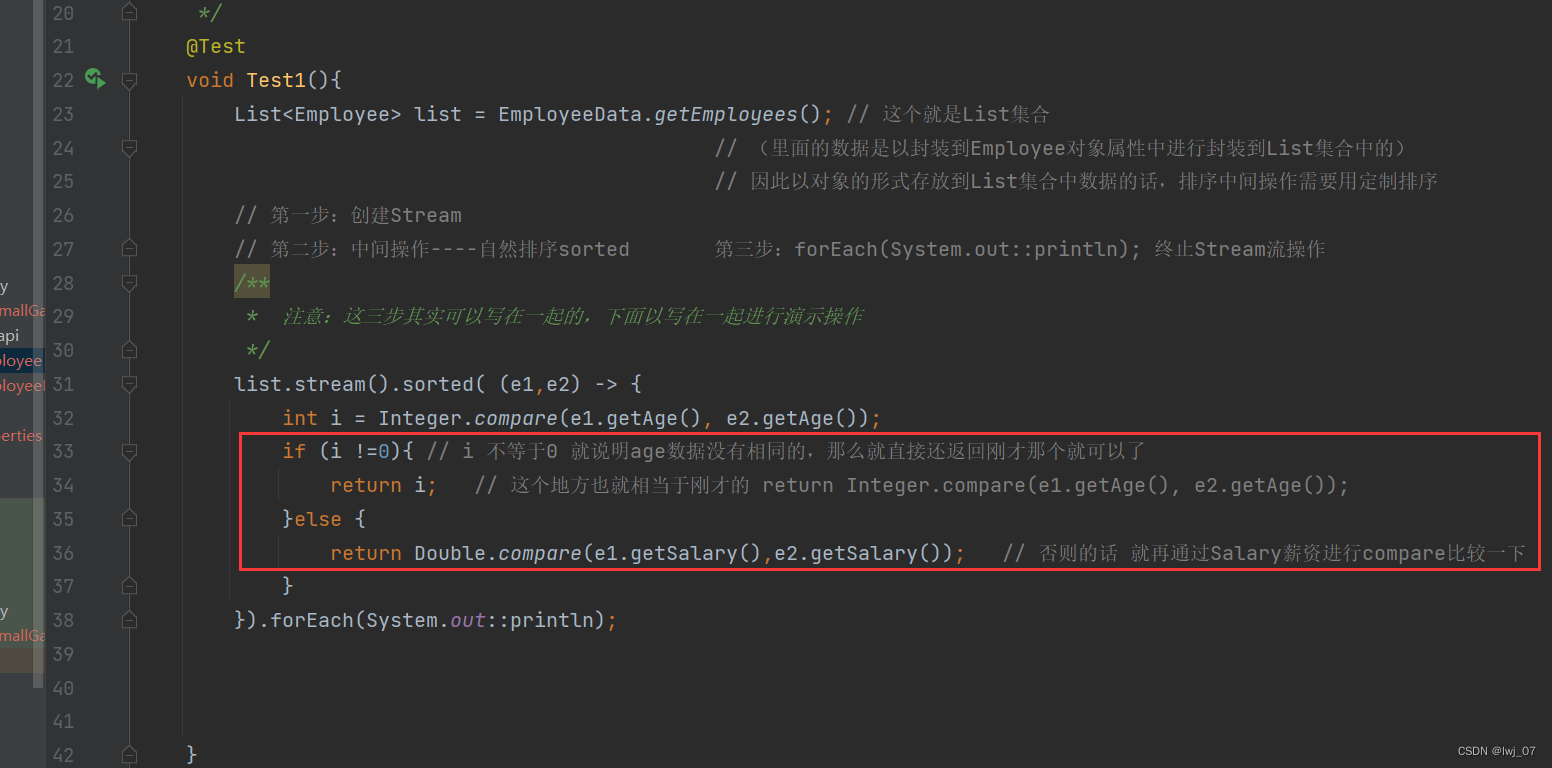
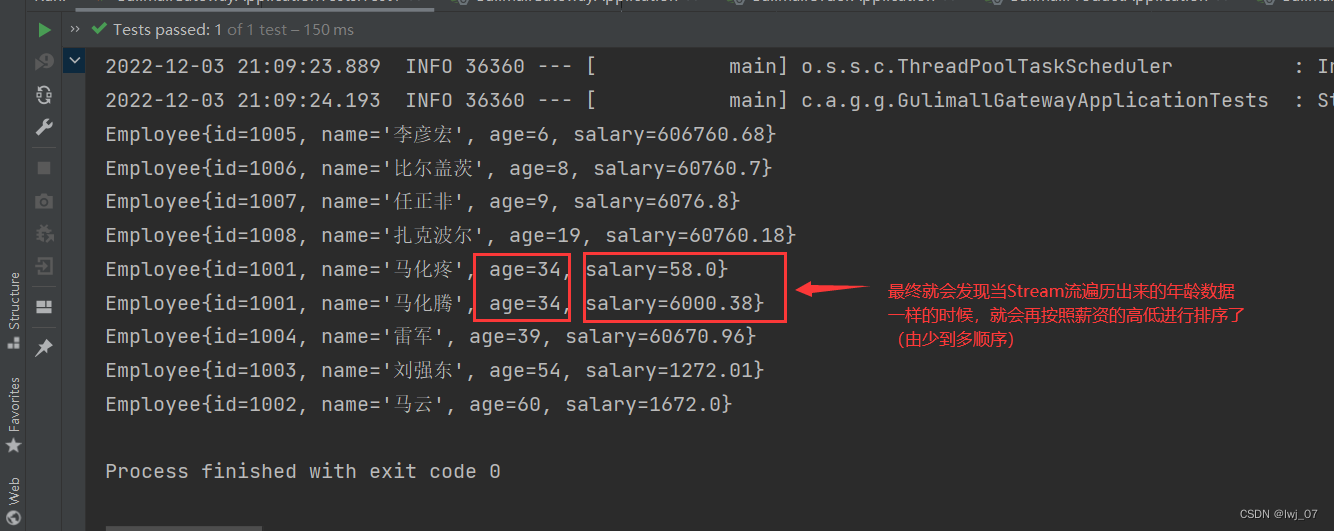
我们就可以让年龄相等的数据再按照薪资或者其他的数据进行排序(和数据库差不多一样)
三、终止操作
3.1、终止操作----匹配与查找
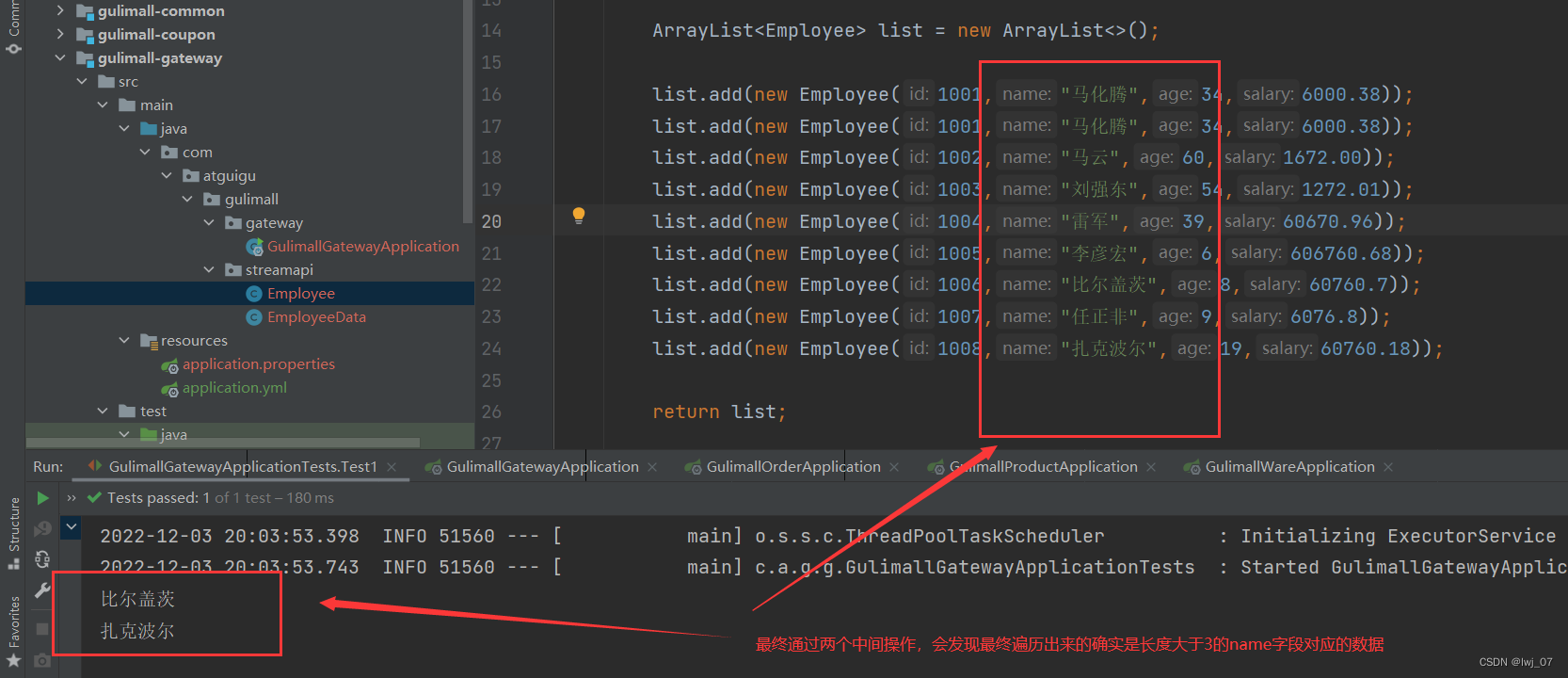
* 首先 List集合中的数据如下所示: * list.add(new Employee(1001,"马化腾",34,6000.38)); * list.add(new Employee(1001,"马化疼",34,58.0)); * list.add(new Employee(1002,"马云",60,1672.00)); * list.add(new Employee(1003,"刘强东",54,1272.01)); * list.add(new Employee(1004,"雷军",39,60670.96)); * list.add(new Employee(1005,"李彦宏",6,606760.68)); * list.add(new Employee(1006,"比尔盖茨",8,60760.7)); * list.add(new Employee(1007,"任正非",9,6076.8)); * list.add(new Employee(1008,"扎克波尔",19,60760.18));
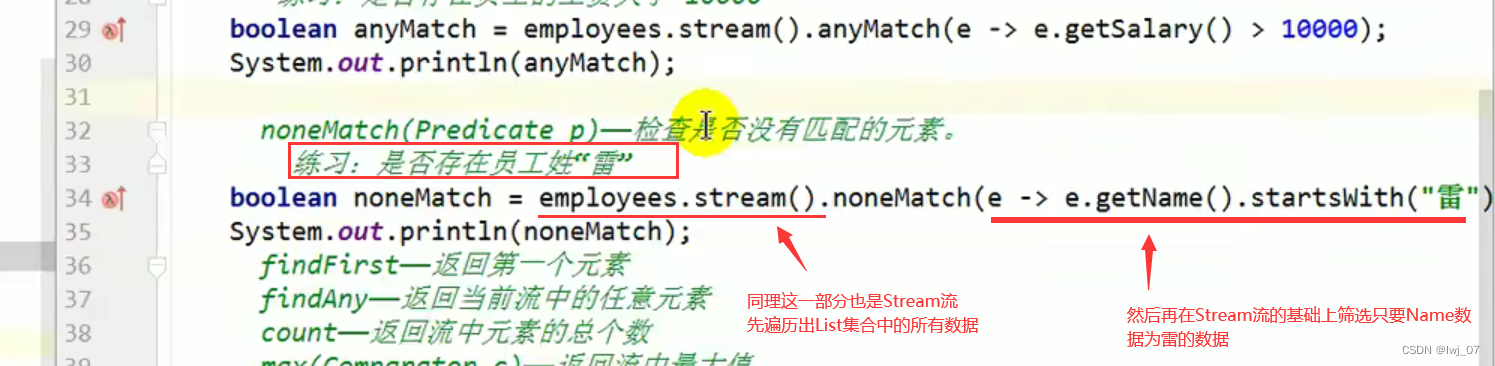
allMatch / anyMatch:

noneMatch:
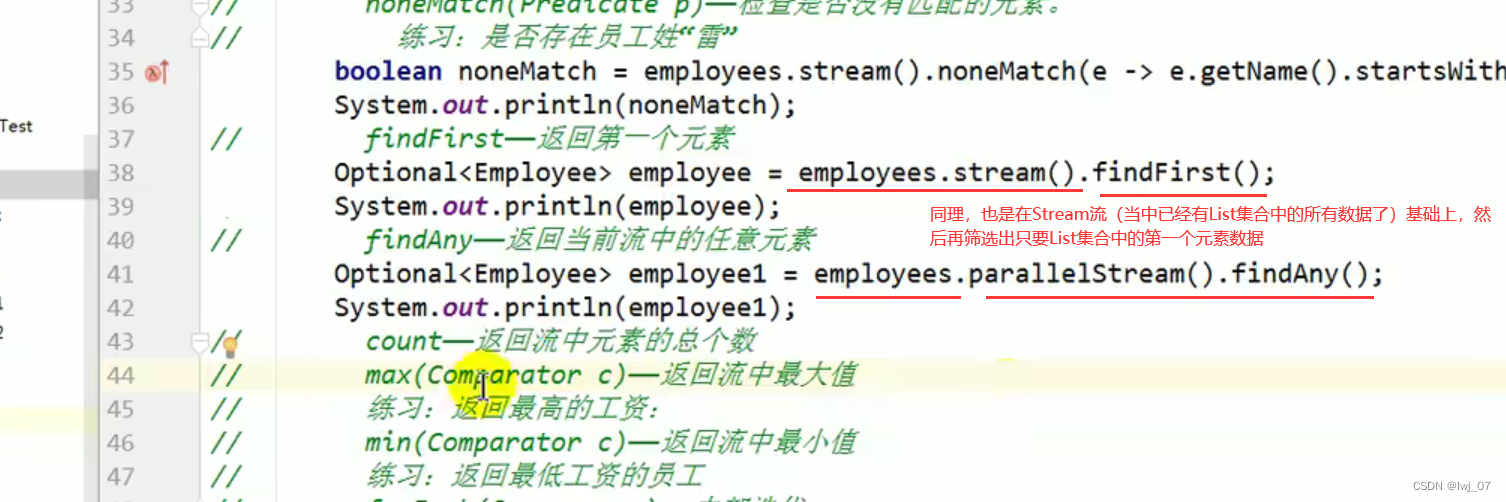
findFirst / findAny:
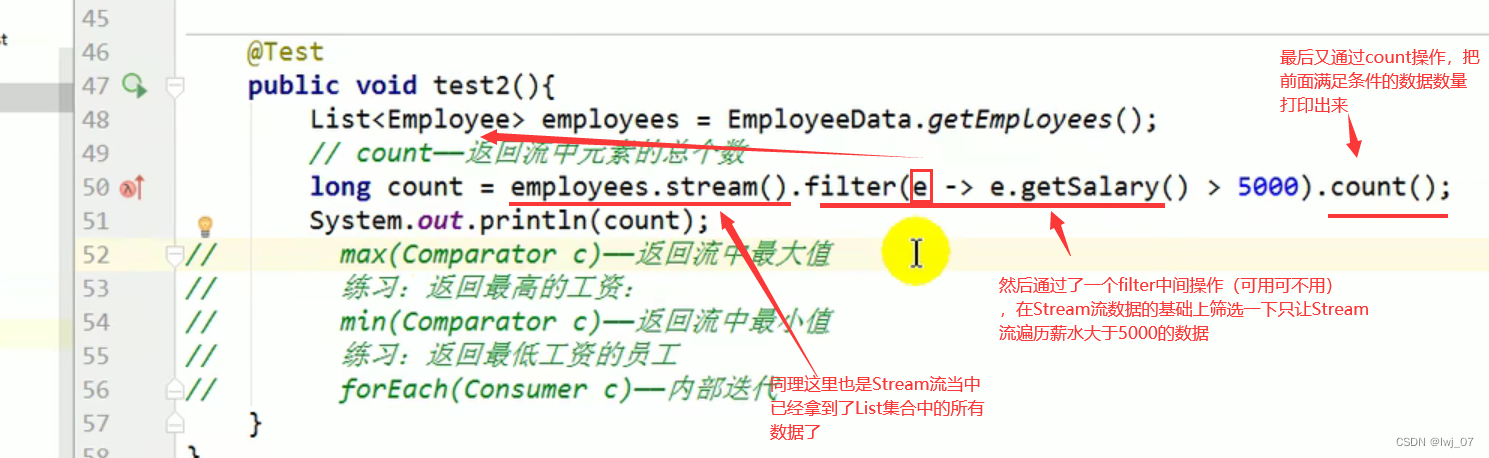
count:
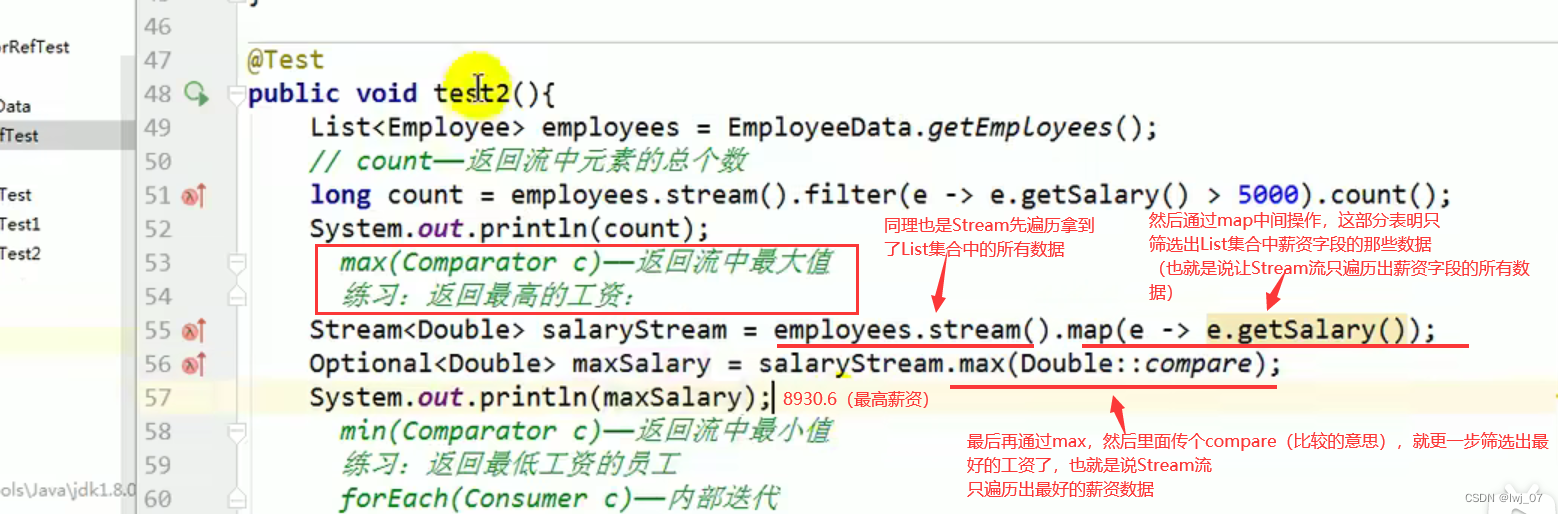
max:
min:
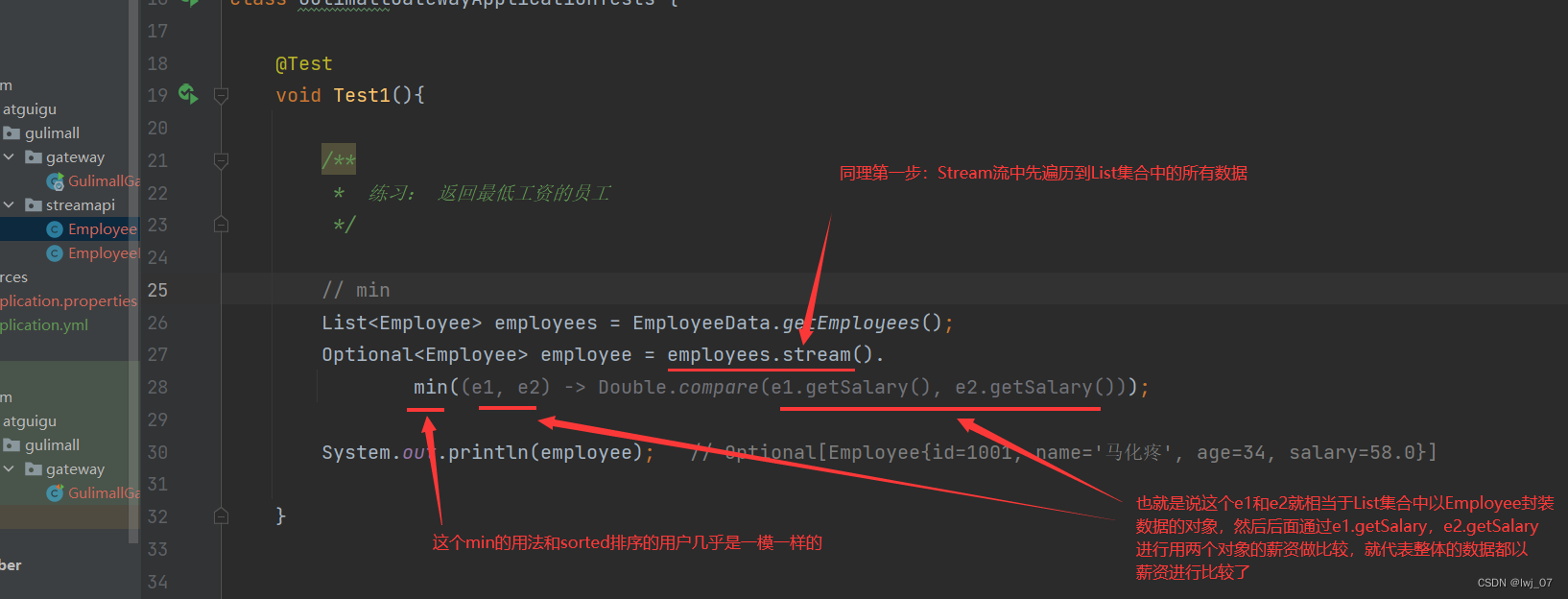
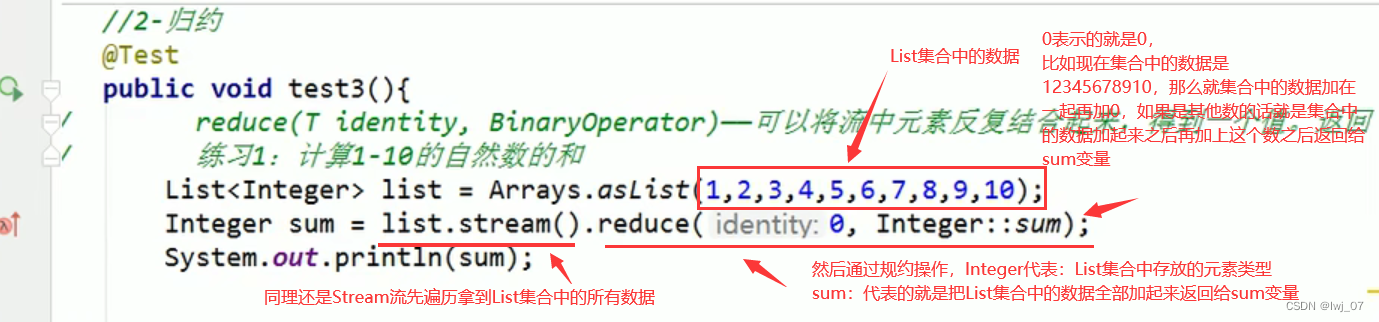
3.2、终止操作----归约
List集合中的数据如下所示:
list.add(new Employee(1001,"马化腾",34,6000.38)); list.add(new Employee(1001,"马化疼",34,58.0)); list.add(new Employee(1002,"马云",60,1672.00)); list.add(new Employee(1003,"刘强东",54,1272.01)); list.add(new Employee(1004,"雷军",39,60670.96)); list.add(new Employee(1005,"李彦宏",6,606760.68)); list.add(new Employee(1006,"比尔盖茨",8,60760.7)); list.add(new Employee(1007,"任正非",9,6076.8)); list.add(new Employee(1008,"扎克波尔",19,60760.18));
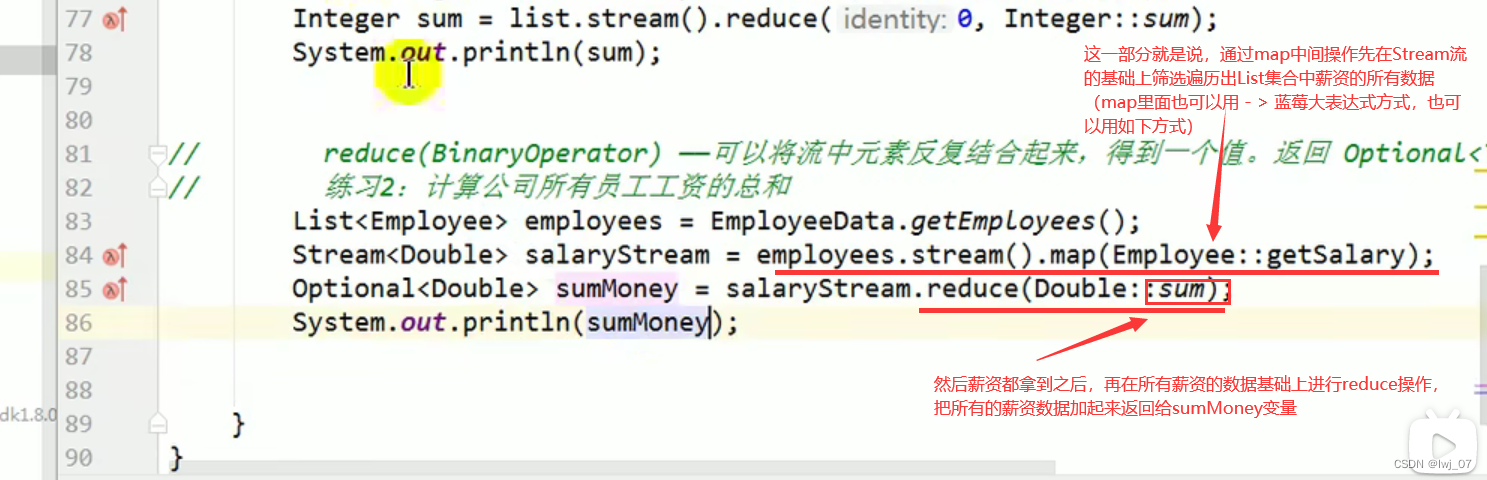
reduce:
reduce(BinaryOperator):
3.3、终止操作----收集 (常用)