[YOLOv7/YOLOv5系列改进NO.40]融入适配GPU的轻量级 G-GhostNet
文章目录
- 前言
- 一、解决问题
- 二、基本原理
- 三、添加方法
- 四、总结
前言
作为当前先进的深度学习目标检测算法YOLOv7,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv7的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。由于出到YOLOv7,YOLOv5算法2020年至今已经涌现出大量改进论文,这个不论对于搞科研的同学或者已经工作的朋友来说,研究的价值和新颖度都不太够了,为与时俱进,以后改进算法以YOLOv7为基础,此前YOLOv5改进方法在YOLOv7同样适用,所以继续YOLOv5系列改进的序号。另外改进方法在YOLOv5等其他算法同样可以适用进行改进。希望能够对大家有帮助。
具体改进办法请关注后私信留言!关注免费领取深度学习算法学习资料!
一、解决问题
之前出了很多轻量化网络的方法,包括C-GhostNet网络融入,替换原yolo算法中的主干特征提取网络,都或多或少取得一定效果,本次博客分享将G-GhostNet网络融入,GhostNet 可以在准确性和 GPU 延迟之间获得更好的权衡,实现轻量化实时快速检测的目的。
二、基本原理
由于内存和计算资源有限,在移动设备上部署卷积神经网络(CNN)很困难。我们的目标是通过利用特征图中的冗余,为包括CPU和GPU在内的异构设备设计高效的神经网络,这在神经架构设计中很少被研究。对于类似CPU的设备,我们提出了一种新的CPU高效Ghost(C-Ghost)模块,以从廉价操作中生成更多的特征图。基于一组内在特征图,我们以低廉的成本应用一系列线性变换来生成许多重影特征图,这些重影特征可以充分反映内在特征的信息。提出的C-Ghost模块可以作为即插即用组件来升级现有的卷积神经网络。C-Ghost瓶颈被设计为堆叠C-Ghost模块,然后可以轻松地构建轻量级C-GhostNet。我们进一步考虑GPU设备的高效网络。在构建阶段不涉及太多GPU低效操作(例如,深度卷积)的情况下,我们建议利用阶段特征冗余来模拟GPU高效Ghost(g-Ghost)阶段结构。一个阶段中的特征分为两部分,其中第一部分使用原始块进行处理,其中用于生成固有特征的输出通道较少,另一部分通过利用阶段冗余使用廉价操作生成。在基准测试上进行的实验证明了所提出的C-Ghost模型和G-Ghost阶段的有效性。

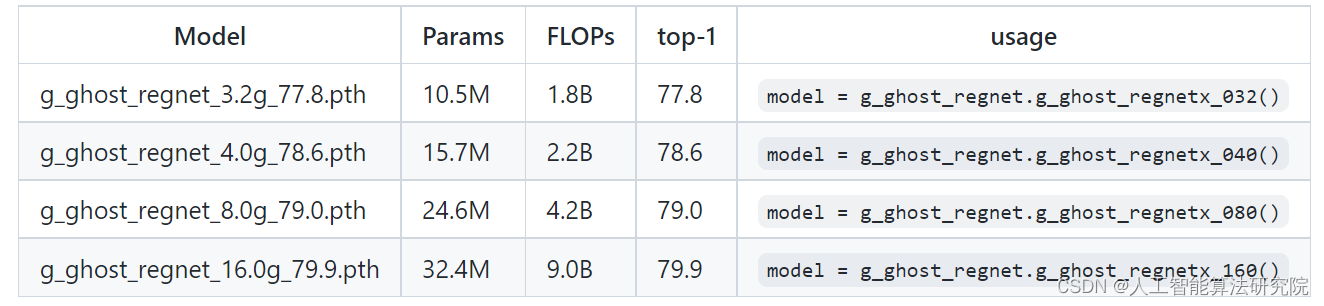
三、添加方法
第一步:确定添加的位置,作为即插即用的注意力模块,可以添加到YOLOv7网络中的任何地方。
第二步:common.py构建模块。部分代码如下,关注文章末尾,私信后领取。
class GGhostRegNet(nn.Module):
def __init__(self, block, layers, widths, num_classes=1000, zero_init_residual=True,
group_width=1, replace_stride_with_dilation=None,
norm_layer=None):
super(GGhostRegNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 32
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False, False]
if len(replace_stride_with_dilation) != 4:
raise ValueError("replace_stride_with_dilation should be None "
"or a 4-element tuple, got {}".format(replace_stride_with_dilation))
self.group_width = group_width
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=2, padding=1,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self._make_layer(block, widths[0], layers[0], stride=2,
dilate=replace_stride_with_dilation[0])
self.inplanes = widths[0]
if layers[1] > 2:
self.layer2 = Stage(block, self.inplanes, widths[1], group_width, layers[1], stride=2,
dilate=replace_stride_with_dilation[1], cheap_ratio=0.5)
else:
self.layer2 = self._make_layer(block, widths[1], layers[1], stride=2,
dilate=replace_stride_with_dilation[1])
self.inplanes = widths[1]
self.layer3 = Stage(block, self.inplanes, widths[2], group_width, layers[2], stride=2,
dilate=replace_stride_with_dilation[2], cheap_ratio=0.5)
self.inplanes = widths[2]
if layers[3] > 2:
self.layer4 = Stage(block, self.inplanes, widths[3], group_width, layers[3], stride=2,
dilate=replace_stride_with_dilation[3], cheap_ratio=0.5)
else:
self.layer4 = self._make_layer(block, widths[3], layers[3], stride=2,
dilate=replace_stride_with_dilation[3])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.2)
self.fc = nn.Linear(widths[-1] * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes, stride),
norm_layer(planes),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.group_width,
previous_dilation, norm_layer))
self.inplanes = planes
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, group_width=self.group_width,
dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x):
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.dropout(x)
x = self.fc(x)
return x
def forward(self, x):
return self._forward_impl(x)
第三步:yolo.py中注册GGhost模块。
第四步:修改yaml文件,本文以修改backbone为例,将原C3模块后加入该模块。
第五步:将train.py中改为本文的yaml文件即可,开始训练。
四、总结
结 果:本人在遥感数据集上进行实验,有涨点效果。需要请关注留言。
预告一下:下一篇内容将继续分享深度学习算法相关改进方法。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦
PS:该方法不仅仅是适用改进YOLOv5,也可以改进其他的YOLO网络以及目标检测网络,比如YOLOv7、v6、v4、v3,Faster rcnn ,ssd等。
最后,有需要的请关注私信我吧。关注免费领取深度学习算法学习资料!
YOLO系列算法改进方法 | 目录一览表
💡🎈☁️1. 添加SE注意力机制
💡🎈☁️2.添加CBAM注意力机制
💡🎈☁️3. 添加CoordAtt注意力机制
💡🎈☁️4. 添加ECA通道注意力机制
💡🎈☁️5. 改进特征融合网络PANET为BIFPN
💡🎈☁️6. 增加小目标检测层
💡🎈☁️7. 损失函数改进
💡🎈☁️8. 非极大值抑制NMS算法改进Soft-nms
💡🎈☁️9. 锚框K-Means算法改进K-Means++
💡🎈☁️10. 损失函数改进为SIOU
💡🎈☁️11. 主干网络C3替换为轻量化网络MobileNetV3
💡🎈☁️12. 主干网络C3替换为轻量化网络ShuffleNetV2
💡🎈☁️13. 主干网络C3替换为轻量化网络EfficientNetv2
💡🎈☁️14. 主干网络C3替换为轻量化网络Ghostnet
💡🎈☁️15. 网络轻量化方法深度可分离卷积
💡🎈☁️16. 主干网络C3替换为轻量化网络PP-LCNet
💡🎈☁️17. CNN+Transformer——融合Bottleneck Transformers
💡🎈☁️18. 损失函数改进为Alpha-IoU损失函数
💡🎈☁️19. 非极大值抑制NMS算法改进DIoU NMS
💡🎈☁️20. Involution新神经网络算子引入网络
💡🎈☁️21. CNN+Transformer——主干网络替换为又快又强的轻量化主干EfficientFormer
💡🎈☁️22. 涨点神器——引入递归门控卷积(gnConv)
💡🎈☁️23. 引入SimAM无参数注意力
💡🎈☁️24. 引入量子启发的新型视觉主干模型WaveMLP(可尝试发SCI)
💡🎈☁️25. 引入Swin Transformer
💡🎈☁️26. 改进特征融合网络PANet为ASFF自适应特征融合网络
💡🎈☁️27. 解决小目标问题——校正卷积取代特征提取网络中的常规卷积
💡🎈☁️28. ICLR 2022涨点神器——即插即用的动态卷积ODConv
💡🎈☁️29. 引入Swin Transformer v2.0版本
💡🎈☁️30. 引入10月4号发表最新的Transformer视觉模型MOAT结构
💡🎈☁️31. CrissCrossAttention注意力机制
💡🎈☁️32. 引入SKAttention注意力机制
💡🎈☁️33. 引入GAMAttention注意力机制
💡🎈☁️34. 更换激活函数为FReLU
💡🎈☁️35. 引入S2-MLPv2注意力机制
💡🎈☁️36. 融入NAM注意力机制
💡🎈☁️37. 结合CVPR2022新作ConvNeXt网络
💡🎈☁️38. 引入RepVGG模型结构
💡🎈☁️39. 引入改进遮挡检测的Tri-Layer插件 | BMVC 2022
💡🎈☁️40. 轻量化mobileone主干网络引入
💡🎈☁️41. 引入SPD-Conv处理低分辨率图像和小对象问题
💡🎈☁️42. 引入V7中的ELAN网络
💡🎈☁️43. 结合最新Non-local Networks and Attention结构