C/C++ 算法基础
如果要真正掌握算法,必须要写代码的,那这时候就必须选择一门语言来进行,而具体的语言其实无所谓 ,C、C++、Java、Python,go甚至JavaScript、VB都可以,关键是自己要用的熟悉,面试时候能用,这里总结一下C和C++方面的基础。
由于我们不是语言课程,因此我们主要介绍与算法密切相关的技术问题。本文的重点是通过一些编程实例介绍程序设计中常用的思想方法和实现手段,不侧重介绍某种高级程序设计语言的语法细节。在这一章里,我们对将要使用的C/C++语言的相关内容做一个概要介绍。主要包括:变量、常量、表达式、赋值语句、分支语句、循环语句、数组、指针、函数等内容。
本书中的所有程序,都没有使用面向对象的编程方法。实际上,如果不涉及面向对象的部分,那么C++语言和C语言的语法90%以上是一样的,只不过略有扩充,用起来更为方便而已。因此,当提及的某项语法特性在C语言和C++语言中都适用时,我们就会说:“在C/C++语言中,......”
由于C/C++语言针对不同的平台有不同的特性,字段长度等在32位和64位机器上就不一样,本文大部分以32位为准。
国庆发布了这篇文章,没想到是最近浏览次数最多的文章,可见很多人还是希望刷算法之前先有个比较好的算法基础。
后面将很快发布《python算法基础》和《Java算法基础》。

目录
第一章C/C++语言概述
1.1 程序的基本框架
1.2变量
1.2.1变量的定义
1.2.2变量的赋值
1.2.3变量的引用
1.3 C/C++语言的数据类型
1.4 常量
1.5运算符和表达式
1.5.1算术运算符
1.5.2赋值运算符
1.5.3关系运算符
1.5.4逻辑运算符
1.5.5位运算符
1.6注释
1.7分支语句
1.7.1if语句
1.7.2 switch语句
1.8循环语句
1.8.1for语句
1.8.2while语句
1.8.3do-while语句
1.8.4break语句
1.8.5continue语句
1.9函数
1.9.1函数的定义
1.9.2函数的调用
1.9.3参数传递和返回值
1.9.4库函数和头文件
1.10标准输入输出
1.10.1printf函数(标准输出函数)
1.10.2 scanf函数(标准输入函数)
1.11全局变量和局部变量
1.12数组
1.12.1一维数组
1.12.2二维数组
1.12.3数组的初始化
1.12.4数组越界
1.13字符串
1.13.1字符串常量
1.13.2用字符数组存放的字符串
1.14指针
1.14.1指针的基本概念
1.14.2指针运算
1.14.3空指针
1.14.4指向指针的指针
1.14.5指针和数组
1.14.6字符串和指针
1.14.7void指针
1.14.8函数指针
1.14.9指针和动态内存分配
1.14.10误用无效指针
1.15结构
1.15.1“结构”的概念
1.15.2结构变量的定义
1.15.3访问结构变量的成员变量
1.15.4结构变量的初始化
1.15.5结构数组
1.15.6指向结构变量的指针
1.15.7动态分配结构变量和结构数组
1.16C语言标准库函数
1.16.1数学函数
1.16.2字符处理函数
1.16.3字符串和内存操作函数
1.16.4字符串转换函数
第一章C/C++语言概述
1.1 程序的基本框架
我们以简单程序Hello World为例说明程序的基本框架。此程序在屏幕上输出一行“Hello World!”:
#include <stdio.h>
int main()
{
printf("Hello World!\n");
}这段程序包括二个部分:
-
1.#include<stdio.h> #include是C语言的保留字,表示要把另一个文件中的内容包含在本文件中。<stdio.h>是被包含的文件的文件名。C语言中提供了一些可以被直接拿来使用、能够完成某些特定功能的库函数,分别声明于不同的头文件中。例如:stdio.h中定义了一些与输入输出有关的函数。printf就是一个能往屏幕上输出一串字符的库函数。
-
2.后面的三行是程序的主函数。每个程序都必须包含这个main()函数。程序运行时,从void main(){...}的第一个语句开始执行。用户编写的程序的主要框架写在main函数里。
-
3.printf("Hello World!\n");这条语句的作用是在屏幕上输出一串字符“Hello Word!”然后换行。“\n”的作用就是换行。换行后,如果以后再用printf语句来输出,那么输出的内容就会出现在屏幕的下一行。
1.2变量
变量是内存中的一块区域,在程序运行过程中可以修改这块区域中存放的数值。变量由两个要素构成:变量的名称和变量的类型。变量的名称是这个内存区域的唯一标识。变量的类型决定了这个内存区域的的大小、对所存储数值的类型要求。在程序中,有三种与变量有关的语句:变量的定义、变量的赋值和变量的引用。
1.2.1变量的定义
如下的语句定义了一个变量:
int number;这里‘number’是变量名,‘int’代表该变量是整数类型的变量,‘;’表示定义语句结束。
在目前流行的机器配置下,整型变量一般占4个字节的内存空间。变量的名字是由编写程序的人确定的,它一般是一个单词或用下划线连接起来的一个词组,说明变量的用途。在C/C++语言中变量名是满足如下规定的一个符号序列:
-
由字母、数字或(和)下划线组成;
-
第一个符号为字母或下划线。注意,同一个字母的大写和小写是两个不同的符号。所以,team和TEAM是两个不同的变量名。
定义变量时,也可以给它指定一个初始值。例如:
int numberOfStudents=80;对于没有指定初始值的变量,它里面的内容可能是任意一个数值。变量一定要先定义,然后才能使用。
1.2.2变量的赋值
给变量指定一个新值的过程称为变量的赋值,通过赋值语句完成。例如:
number=36; 表示把36写入变量number中。下面给出一些变量赋值语句的例子:
int temp;
int count;
temp=15;
count=temp;
count=count+1;
temp=count;1.2.3变量的引用
变量里存储的数据可以参与表达式的运算,或赋值给其它变量。这一过程称为变量的引用。例如:
int total=0;
int p1=5000;
int p2=300;
int p3=1000;
int p4=1000;
total=p1+p2+p3+p4;最后一个赋值语句表示把变量‘p1’,‘p2’,‘p3’和‘p4’的值取出来相加,得到的和赋给变量‘total’。最后一句执行后,‘total’的值变为7300。
1.3 C/C++语言的数据类型
前面我们介绍了变量的定义语句:
int nNumber;此处的“int”表示了变量nNumber的“数据类型”,它说明nNumber是一个“整型变量”,即nNumber中存放的是一个整数。“数据类型”能够说明一个变量表示什么样的数据(整数,浮点数,还是字符等)。不同数据类型的变量,占用的存储空间大小不同。除了“int”以外,C/C++中还有其他一些基本数据类型,现列举其中几个如下:
-
int:整型。int型变量表示一个整数,其范围是-2^31~2^31-1,占用4个字节。
-
long:长整型。和int类型一样,也占用4个字节。
-
short:短整型。short型变量表示一个整数,但它占用2个字节,因而能表示的数的范围是-2^15~2^15-1。
-
unsigned int:无符号整型。unsignedint类型的变量表示一个非负整数,占用4个字节。
-
unsigned long:和unsigned int一样。
-
unsigned short:无符号短整型。unsigned short类型的变量表示一个非负整数,占用2个字节,能表示的数的范围是:0-2^16-1,本书中,我们将上面几种类型统称为“整数类型”。
-
char:字符型。char类型的变量表示一个字符,如’a’,’0’等。占用1个字节。字符型变量存放的实际上是字符的Ascii码。比如’a’的Ascii码是97,即16进制的0x61,那么如果有:
charc=‘a’;则实际上c中就存放着16进制数0x61,或二进制数01100001。 unsigned char:无符号字符型。unsigned char类型的变量表示一个字符,占用1个字节。 -
float:单精度浮点型。float类型的变量表示一个浮点数(实数),占用4个字节。
-
double:双精度浮点型。double类型的变量也表示一个浮点数,但它占用8个字节,因而精度比float类型高。
以上的“int”、“double”、“short”、”unsignedchar”等标识符,都是“类型名”。C++中的“类型名”可以由用户定义,后文“结构”一节会进一步阐述。在赋值语句中,如果等号左边的变量类型为T1,等号右边的变量或常量类型为T2,T1和T2不相同,那么编译器会将等号右边的变量或常量的值,自动转换为一个T1类型的值,再将此值赋给等号左边的变量。这个过程叫做“自动类型转换”。自动类型转换不会改变等号右边的变量。能进行自动类型转换的前提是,T1和T2是两个兼容的类型。上面提到的所有类型,正好都是两两互相兼容的。但是后面会碰到一些类型,比如指针类型,结构类型,它们和上述所有的类型都不兼容。如果等号左边是个整型变量,等号右边是个“结构类型”的变量,这样的赋值语句在编译的时候就会报错。
下面以一个程序来说明上述数据类型之间的自动转换:
#include <stdio.h>
int main()
{
int n1 = 1378;
short n2;
char c = 'a';
double d1 = 7.809;
double d2;
n2 = c; //n2变为97
printf("c=%c,n2=%d\n", c, n2);
c = n1; //c 变为 ’b’
printf("c=%c,n1=%d\n", c, n1);
n1 = d1; //n1变为7
printf("n1=%d\n", n1);
d2 = n1; //d2变为7
printf("d2=%f", d2);
return 0;
}上面输出的结果是:
c=a,n2=97
c=b,n1=1378
n1=7
d2=7.000000思考题:1.3.1:
假定char类型的变量c中存放着一个’w’之前的小写字母,请写一条赋值语句,使得c变为其后的第4个字母(比如,将c从’a’变成’e’)。解答见后。
提示:小写字母的Ascii码是连续的。
1.4 常量
常量是程序需要访问的一个数据,它在程序的运行过程中不发生改变。常量有两种表现形式:直接写出值,或用#define语句为数据定义一个由符号组成的标识符,标识符的命名规则与变量的命名规则相同。不同的数据类型有不同形式的常量。例如:123,-56,0,38,-1是整数类型的常量;1.5,23.6,0.0,-0.6789,100.456是浮点类型的常量;'a','p','0','¥','#'是字符类型的常量;“abc”,“definitely”,“1234”,“0.6”,“AE4%(Ap)”等是字符串类型的常量。这些都是直接给出数据值的常量,它们的类型可以很容易地从数据形式上判断。另一种用#define语句,为需要访问的数据指定一个容易理解的名字(标识符),例如:
#include<stdio.h>
#define MAPLENGTH 100
#define MAPWIDTHTH 80
int main()
{
int mapSize;
mapSize=MAPLENGTH*MAPWIDTHTH;
printf("Themapsize is%d\n",mapSize);
}这段代码中MAPLENGTH是一个整数类型的常量,它的值是100。在定义语句之后,
所有出现符号MAPLENGTH的地方,都等效于出现数值100。同样地,MAPWIDTH也是一个整数类型的常量,它的值是80。这段程序的运行结果是输出一个整数8000。
C/C++语言中,整数类型常量还可以有八进制、十六进制的写法。
八进制常量以数字“0”开头的,比如0123就是八进制的123。0987是不合法的常量,因为以0开头代表是八进制数,而八进制数中是不能出现数字8和9的。
十六进制常量以“0x”开头。比如,0x12就是16进制的12,换算成十进制就是18。0xfd0678、0xff44f都是合法的十六进制常量。十六进制表示法中,用a代表10、b代表11、c代表12、d代表13、e代表14、f代表15。这几个字母大、小写均可。由于16进制中的每一位正好对应于二进制的4位,因此,十六进制常量用起来十分方便,也非常有用。
有一些字符常量的写法比较特殊,比如单引号应写为''',“\”应写为'\'。
思考题:
什么样的常量在程序运行期间会象变量一样,需要用一片内存空间来存放,什么样的常量不需要?
1.5运算符和表达式
C/C++语言中的“+”、“-”“*”“/”等符号,表示加、减、乘、除等运算,这些表示数据运算的符号称为“运算符”。运算符所用到的操作数个数,称为运算符的“目数”。比如,“+”运算符需要两个操作数,因此它是双目运算符。
将变量、常量等用运算符连接在一起,就构成了“表达式”。如“n+5”、“4-3+1”。实际上,单个的变量、常量也可以称为“表达式”。表达式的计算结果称为“表达式的值”。如表达式“4-3+1”的值就是2,是整型的。如果f是一个浮点型变量,那么表达式“f”的值就是变量f的值,其类型是浮点型。
C/C++语言的运算符有赋值运算符、算术运算符、逻辑运算符、位运算符等多类。常用的介绍如下。
1.5.1算术运算符
算术运算符用于数值运算。包括加(+)、减(-)、乘(*)、除(/)、求余数(%)、自增(++)、自减(--)共七种。
1.5.1.1模运算符
求余数的运算符“%”也称为模运算符。它是双目运算符,两个操作数都是整数类型的。a%b的值就是a除以b的余数。
1.5.1.2除法运算符
C/C++的除法运算符有一些特殊之处,即如果a、b是两个整数类型的变量或者常量,那么a/b的值是a除以b的商。比如,表达式“5/2”的值是2,而不是2.5。请看下面的程序片断div_test.c:
#include<stdio.h>
int main()
{
int a=10;
int b=3;
double d=a/b; //①
printf("%f\n",d);
d=5/2;//②
printf("%f\n",d);
d=5/2.0;//③
printf("%f\n",d);
d=(double)a/b;//④
printf("%f\n",d);
return0;
}上面程序的输出结果是:
3.000000
2.000000
2.500000
3.333333-
语句①中,由于a、b都是整型,所以表达式a/b的值也是整型,其值是3,因此d的值就变成3.0。
-
语句②和语句①类似,执行后d的值变为2.0。
-
语句③中,要求5除以2的精确值,为此要将5或者2表示成浮点数。除法运算中,如果有一个操作数是浮点数,那么结果就也会是较为精确的浮点数。因此表达式5/2.0的值是2.5。
-
语句④求a除以b的较为精确的小数形式的值。“(double)”的是一个“强制类型转换运算符”,它是一个单目运算符,能将其右边的操作数强制转换成double类型。用此运算符先将a的值转换成一个浮点数值,然后再除以b,此时算出来的结果就是较为精确的浮点型的了。
1.5.1.3自增自减运算符
自增运算符“++”用于将整型或浮点型变量的值加1。只有一个操作数,是单目运算符。它有两种用法:
用法1: 变量名++; 用法2: ++变量名; 这两种用法都能使得变量的值加1,但它们是有区别的,请看例子:
#include <stdio.h>
main()
{
int n1,n2=5;
n2++;//n2=6
++n2;//n2=7
n1=n2++;//①
n1=++n2;//②
}上面的①执行过程,是先将n2的值赋给n1,然后再增加n2的值,因此语句7执行后,n1的值是7,n2的值是8。也可以说,表达式“n2++”的值,就是n2加1以前的值;
语句②的执行过程,先将n2的值加1,然后再将n2的新值赋给n1。因此语句8执行后,n1的值是9,n2的值也是9。也可以说,表达式“++n2”的值,就是n2加1以后的值;
上面两个语句体现了“++”写在变量前面和后面所造成的不同。自减运算符“--”用于将整型或浮点型变量的值减1。它的用法和“++”相同,不再赘述。
1.5.2赋值运算符
赋值运算符用于对变量进行赋值,分为简单赋值(=)、复合算术赋值(+=,-=,*=,/=,%=)和复合位运算赋值(&=,|=,^=,>>=,<<=)三类共十一种。
表达式“a=b”的值就是a,类型和a的类型一样。因此,可以写: int a,b; a=b=5; 上面这条语句先将b的值赋为5;然后求得b=5这个表达式的值5,再赋值给a。a+=b等效于a=a+b,但是前者执行速度比后者快。
-=、*=、/=、%=的用法和+=类似。
1.5.3关系运算符
关系运算符用于数值的大小比较。包括大于(>)、小于(<)、等于(==)、大于等于(>=)、小于等于(<=)和不等于(!=)六种。他们都是双目运算符。
关系运算符运算的结果是整型,值只有两种:0或非0。0代表关系不成立,非0代表关系成立。
比如表达式“3>5”,其值就是0,代表该关系成不成立,即运算结果为假;表达式“3==3”,其值就是非0,代表该关系成立,即运算结果为真。至于这个非0值到底是多少,C/C++语言没有规定,我们编程的时候也不需要关心这一点。C/C++语言中,总是用0代表“假”,用非0代表“真”,在后面章节会看到其用法。
请看下面的例子:
#include<stdio.h>
main()
{
int n1=4,n2=5,n3;
n3=n1>n2;//n3的值变为0
n3=n1<n2;//n3的值变为某非0值
n3=n1==4;//n3的值变为某非0值
n3=n1!=4;//n3的值变为0
n3=n1==5;//n3的值变为0
}1.5.4逻辑运算符
逻辑运算符用于数值的逻辑操作。包括与(&&)、或(||)、非(!)三种。前二者是双目运算符,第三个是单目运算符。其运算规则如下:
当且仅当表达式exp1和表达式exp2的值都为真(非0)时,“exp1&&exp2”的值为真,其他情况,“exp1&&exp2”的值均为假。例如,如果n=4,那么“n>4&&n<5”的值就是假,“n>=2&&n<5”的值就是真。
当且仅当表达式exp1和表达式exp2的值都为假(就是0)时,“exp1||exp2”的值为假,其他情况,“exp1||exp2”的值均为真。例如,如果n=4,那么“n>4||n<5”的值就是真,“n<=2||n>5”的值就是假。
如果表达式exp的值为真,那么“!exp”的值就是假;如果exp的值为假,那么“!exp”的值就是真。比如,表达式“!(4<5)”的值就是假。
1.5.5位运算符
有时我们需要对某个整数类型变量中的某一位(bit)进行操作,比如,判断某一位是否为1,或只改变其中某一位,而保持其他位都不变。C/C++语言提供了“位运算”的操作,实现类似的操作。C/C++语言提供了六种位运算符来进行位运算操作:
& 按位与
| 按位或
^ 按位异或
~ 取反
<< 左移
>> 右移位运算的操作数是整数类型(包括long、int、short、unsigned int等)或字符型的,位运算的结果是无符号整数类型的。
1.5.5.1按位与运算符
按位与运算符"&"是双目运算符。其功能是,将参与运算的两操作数各对应的二进制位进行与操作。只有对应的两个二进位均为1时,结果的对应二进制位才为1,否则为0。
例如:表达式“21&18”的计算结果是16(即二进制数10000),因为:
21用二进制表示就是:00000000000000000000000000010101 18用二进制表示就是:00000000000000000000000000010010 二者按位与所得结果是:00000000000000000000000000010000 按位与运算通常用来将某变量中的某些位清0或保留某些位不变。例如,如果需要将int型变量n的低8位全置成0,而其余位不变,则可以执行:
n=n&0xffffff00;也可以写成:
n&=0xffffff00;如果n是short类型的,则只需执行:
n&=0xff00;如果要判断一个int型变量n的第7位(从右往左,从0开始数)是否是1,则只需看表达式“n&0x80”的值是否等于0x80即可。
1.5.5.2按位或运算符
按位或运算符"|"是双目运算符。其功能是将参与运算的两操作数各对应的二进制位进行或操作。只有对应的两个二进位都为0时,结果的对应二进制位才是0,否则为1。
例如:表达式“21|18”的值是23(即二进制数10111)。
按位或运算通常用来将变量中的某些位置1或保留某些位不变。例如,如果需要将int型变量n的低8位全置成1,而其余位不变,则可以执行:
n|=0xff;
1.5.5.3按位异或运算符
按位异或运算符"^"是双目运算符。其功能是将参与运算的两操作数各对应的二进制位进行异或操作。只有对应的两个二进位不相同时,结果的对应二进制位才是1,否则为0。
例如:表达式“21^18”的值是7(即二进制数111)。
异或运算的特点是:如果a^b=c,那么就有c^b==a以及c^a==b。此规律可以用来进行最简单的快速加密和解密。
思考:如何用异或运算对一串文字进行加密和解密?进一步,如果只使用一个字符做密钥,恐怕太容易被破解,如何改进?
1.5.5.4按位非运算符
按位非运算符"~"是单目运算符。其功能是将操作数中的二进制位0变成1,1变成0。例如,表达式“~21”的值是无符号整型数0xffffffea,下面的语句:
printf("%d,%u,%x",~21,~21,~21);
输出结果是:-22,4294967274,ffffffea
1.5.5.5左移运算符
左移运算符“<<”是双目运算符。其计算结果是将左操作数的各二进位全部左移若干位后得到的值,右操作数指明了要左移的位数。左移时,高位丢弃,左边低位补0。左移运算符不会改变左操作数的值。
例如,常数9有32位,其二进制表示是: 00000000000000000000000000001001
表达式“9<<4”就是将上面的二进制数左移4位,得到:
00000000000000000000000010010000
即为十进制的144。
实际上,左移1位,就等于是乘以2,左移n位,就等于是乘以2。而左移操作比乘法操作快得多。请看下面的例子程序:
#include<stdio.h>
main()
{
int n1=15;
short n2=15;
unsigned short n3=15;
unsigned char c=15;
n1<<=15;
n2<<=15;
n3<<=15;
c<<=6;
printf("n1=%x,n2=%d,n3=%d,c=%x,c<<4=%d",n1,n2,n3,c,c<<4);
}上面程序的输出结果是:n1=78000,n2=-32768,n3=32768,c=c0,c<<4=3072
-
n1<<=15;一行是对n1左移15位。将32位的n1用二进制表示出来后,即可得知新的n1值是0x78000。
-
n2<<=15;将n2左移15位。注意,n2是short类型的,只有16位,表示为二进制就是0000000000001111,因此左移15位后,一共从左边移出去了(丢弃了)3个1,左移后n2中存放的的二进制数就是1000000000000000。由于n2是short类型,此时n2的最高位是1,因此n2实际上表示的是负数,所以在语句12中输出为-32768。
-
n3<<=15;将n3左移15位。左移后n3内存放的二进制数也是1000000000000000,但由于n3是无符号的,表示的值总是非负数,所以在语句12中,n3输出为32768。
-
c<<=6;将c左移6位。由于c是unsignedchar类型的,一共只有8位,其二进制表示就是00001111,因此左移6位后,就变为11000000,在语句12中以16进制输出为c0。语句12中,表达式“c<<4”的计算过程是首先将c转换成一个int类型的临时变量(32位,用16进制表示就是00000000000000c0),然后将该临时变量左移4位,得到的结果是十六进制的0000000000000c00,换算成十进制就是3072。
-
表达式“c<<4”的求值过程不会改变c的值,就像表达式“c+4”的求值过程不会改变c的值一样。
1.5.5.6右移运算符
右移运算符“>>”是双目运算符。其计算结果是把“>>”的左操作数的各二进位全部右移若干位后得到的值,要移动的位数就是“>>”的右操作数。移出最右边的位被丢弃。
对于有符号数,如long、int、short、char类型变量,在右移时,符号位(即最高位)将一起移动,并且大多数C/C++编译器规定,如果原符号位为1,则右移时右边高位就补充1,原符号位为0,则右移时高位就补充0。
对于无符号数,如unsigned long、unsigned int、unsigned short、unsigned char类型的变量,右移时高位总是补0。
右移运算符不会改变左操作数的值。请看例子程序:
#include<stdio.h>
main()
{
int n1=15;
short n2=-15;
unsigned short n3=0xffe0;
unsigned char c=15;
n1=n1>>2;
n2>>=3;
n3>>=4;
c>>=3;
printf("n1=%x,n2=%d,n3=%x,c=%x",n1,n2,n3,c);
}上面的程序输出结果是:n1=3,n2=-2,n3=ffe,c=1
-
n1=n1>>2;一行,n1的值是0xf,右移2位后,变成0x3。
-
n2>>=3;一行,n2是有符号16位整数,而且原来值为负数,表示成二进制是1111111111110001。由于最高位(符号位)是1,右移时仍然在高位补充1,所以右移完成后其二进制形式是1111111111111110,对于一个有符号16位整数来说,这个二进制形式就代表-2。
-
n3>>=4;一行,n3是无符号的16位整数,原来其值为0xffe0。尽管最高位是1,但由于它是无符号整数,所以右移时在高位补充0,因此右移4位后,n3的值变为0xffe。
-
c>>=3;一行,c是无符号的,原来值为0xf,右移动3位后自然就变成1。实际上,右移n位,就相当于左操作数除以2n,并且将结果往小里取整。
思考题
有两个int型的变量a和n(0<=n<=31),要求写一个表达式,使该表达式的值和a的第n位相同。
1.5.5.7sizeof运算符
“sizeof”是C/C++语言中的保留字,也是一个运算符。它的作用是求某一个变量占用内存的字节数,有两种用法:
第一种用法: sizeof(变量名) 比如,表达式sizeof(n)的值是n这个变量占用的内存字节数。如果n是short类型的变量,那么sizeof(n)的值就是2。第二种用法:
sizeof(类型名) 比如,sizeof(int)的值是4,因为一个int类型的变量占用4个字节。
1.5.5.8类型强制转换运算符
强制类型转换运算符的形式是: (类型名) 比如,(int)、(double)、(char)等,都是强制类型转换运算符。它是单目运算符,功能是
将其右边的操作数的值转换得到一个类型为“类型名”的值,它不改变操作数的值。比如:
1.doublef=9.14
2.intn=(int)f;
3.f=n/2;
4.f=(double)n/2;上面的语句2将f的值9.14强制转换成一个int型的值,即转换成9,然后赋值给n。这条语句中是否使用(int)运算符结果都一样,因为编译器会自动转换。但是有时我们需要在类型不兼容的变量之间互相赋值,这时就需要在赋值时对等号右边的变量、常量或表达式进行强制类型转换,转换成和等号左边的变量类型相同的一个值。
上面的语句3执行后,f的值是4.0,因为表达式n/2的值是整型的,为4。
而语句4使用强制转换运算符(double)将n的值转换为一个浮点数,然后再除以2,那么得到的值就是一个浮点数。因此本语句执行后,f的值为4.5。2.5.1.2小节的例子程序的语句11,也说明了强制转换运算符的这种用法。
1.5.5.9运算符的优先级
一个表达式中可以有多个、多种运算符。不同的运算符优先级不同,优先级决定了表达式该先算哪部分、后算哪部分。
比如表达式4&2+5,由于“+”的优先级高于“&”,所以这个表达式是先算2+5,再算4&7,结果是4。
可以用括号来规定表达式的计算顺序,比如(4&2)+5的值是5,先算4&2。下表列出了大部分运算符的优先级:

1.6注释
有时我们会需要在程序中用自然语言写一段话,提醒自己或者告诉别人,某些变量代表什么,某段程序的逻辑是怎么回事,某几行代码的作用是什么,等等。当然,这部分内容不能被编译,不属于程序的一部分。这样的内容,称为“注释”。C++的注释有两种写法。第一种注释可以是多行的,以“/”开头,以“/”结尾。例如:
/**
*主函数
*/注释可以出现在任何地方,注释里的内容不会被编译的,因此,随便写什么都行。例如可以为某一行代码加:
int n1=15;/*定义变量n1*/第二种注释是单行的。写法是使用两个斜杠“//”。从“//”开始直到行末的内容,就都算是注释了。例如:
short n2=-15;//定义short类型变量n2注释非常重要。它的主要功能是帮助理解程序。一定不要认为程序是自己写的,自己当然能理解。只要程序稍长一些、或者变量名不够直观,那么写时能理解,并不意味着一个星期后自己还能理解。更何况,软件开发是团队工作,没有人希望在看别人的程序的时候如读天书,恨不得自己重写一个。所以,在程序中加入足够的、清晰易懂的注释,是程序员的基本修养。
1.7分支语句
在C/C++语言中,语句以“;”结束。某些情况下,一组语句在一起共同完成某一特定的功能,可以将它们用大括号括起来。我们称之为语句组。语句组可以出现在任何单个语句出现的地方。一般情况下,语句的出现顺序就是其执行顺序。但是在某些情况下,需要根据不同的运行情况而执行不同的语句组。这时可以选用分支语句。我们介绍两种分支语句:if和switch。
1.7.1if语句
if语句有两种形式:
if(表达式)
语句/语句组如果表达式的值为真(非零),则其后的语句/语句组被执行。如果表达式的值为假(等于零),则其后的语句/语句组被忽略。
if(表达式)
语句/语句组1
else
语句/语句组2如果表达式的值为真(非零),则其后的语句/语句组1被执行,语句/语句组2被忽略。如果表达式的值为假(等于零),则其后的语句/语句组1被忽略,语句/语句组2被执行。
下面是一个if语句的例子:
if(i>0)
y=x/i;
else{
x=i;
y=-x;
}在这个例子中,i,x,y是变量。如果i的值大于0,则y被赋值为x/i;如果i的值小于或等于0,则x被赋值为i,y被赋值为-x。当if语句后面只有一个语句时,可以不用大括号将其括起来。
if语句可以嵌套使用。在没有大括号来标识的情况下,else语句被解释成与它最近的if语句共同构成一句。例如:
if(i>0)/*没有大括号*/
if(j>i)
x=j;
else
x=i;如果上面的例子中else是与第一个if配对的,则应该写成如下格式:
if(i>0){/*加上括号*/
if(j>i)
x=j;
}else
x=i;1.7.2 switch语句
switch和case语句用来控制比较复杂的条件分支操作。switch语句的语法如下:
switch(表达式){
case常量表达式1:语句/语句组1
case常量表达式2:语句/语句组2
...
default:语句/语句组n
}switch语句可以包含任意数目的case条件,但是不能有两个case后面的常量表达式完全相同。进入switch语句后,首先表达式的值被计算、并与case后面的常量表达式逐一匹配,当与某一条case分支的常量表达式匹配成功时,则开始执行它后面的语句/语句组,然后顺序执行之后的所有语句,直到遇见一个整个switch语句结束,或者遇到一个break语句(break语句后面会有介绍)。如果表达式与所有的常量表达式都不相同,则从default后面的语句开始执行到switch语句结束。
各case分支后的“常量表达式”必须是整数类型或字符型的。
如果各个case分支后面的语句/语句组彼此独立,即在执行完某个case后面的语句/语句组后,不需要顺序执行下面的语句,可以用break语句将这些分支完全隔开。在switch语句中,如果遇到break语句,则整个switch语句结束。例如:
switch(表达式){
case常量表达式1:语句/语句组1;break;
case常量表达式2:语句/语句组2;break;
...
default:语句/语句组n
}default分支处理除了明确列出的所有常量表达式以外的情况。switch语句中只能有一个default分支,它不必只出现在最后,事实上它可以出现在任何case出现的地方。switch后面的表达式与case后面的常量表达式必须类型相同。象if语句一样,case语句也可以嵌套使用。
下面是一个switch语句的例子:
switch(c){
case 'A':
capa++;
case 'a':
lettera++;
default:
total++;
}因为没有break语句,如果c的值等于'A',则switch语句中的全部三条语句都被执行;如果c的值等于'a',则lettera和total的值加1。如果c的值不等于'a'或'A',则只有total的值加1。下面是一个加入了break语句的例子:
switch(i){
case -1:
n++;
break;
case 0:
z++;
break;
case 1:
p++;
break;
}在这个例子中,每个分支都加入了一个break语句,使得每种情况处理完之后,就结束switch语句。如果i等于–1,只有n加1;如果i等于0,只有z加1;如果i等于1,只有p加1。最后一个break不是必须的,因为程序已经执行了最后,保留它只是为了形上的统一。
如果有多种情况要执行的任务相同,可以用如下的方式表达:
case'a':
case'b':
case'c':
case'd':
case'e':
case'f':
x++;在这个例子中,无论表达式取值在'a'到'f'之间的哪个值,x的值都加1。
1.8循环语句
在有些程序中,需要反复执行某些语句。将n条相同的语句简单地复制会使程序变得不合理的冗长,因此高级语言中提供了支持程序重复执行某一段程序的循环控制语句。相关的语句有:for;while;dowhile;break;continue;等。
1.8.1for语句
for可以控制一个语句或语句组重复执行限定的次数。for的语句体可以执行零或多次,直到给定的条件不被满足。可以在for语句开始时设定初始条件,并在语句的每次循环中改变一些变量的值。for语句的语法如下:
for(初始条件表达式;循环控制表达式;循环操作表达式)语句/语句组执行一个for语句包括如下操作:
-
初始条件表达式被分析执行。这个条件可以为空。
-
循环控制表达式被分析执行。这一项也可以为空。循环控制表达式一定是一个数值表达式。在每次循环开始时,它的值都会被计算。计算结果有三种可能: 如果循环控制表达式为真(非零),语句/*语句组被执行;然后循环操作表达式被执行。循环操作表达式在每次循环结束时都会被执行。下面就是下一次循环开始,循环操作表达式被执行。
-
如果循环控制表达式被省略,它的值定义为真。一个for循环语句如果没有循环控制表达式,它只有遇到break或return语句时才会结束。
-
如果循环控制表达式为假(零),for循环结束,程序顺序执行它后面的语句。
break,goto,或return语句都可以结束for语句。continue语句可以把控制直接转移至for循环的循环控制表达式。当用break语句结束for循环时,循环控制表达式不再被执行。下面的语句经常被用来构造一个无限循环,只有break或return语句可以从这个循环中跳出来。
for(;;);
下面是一个for循环语句的例子:
for(i=n2=n3=0;i<=100;i++){
if(i%2==0)
n2++;
else if(i%3==0)
n3++;
}这个例子计算从0到100的整数中,有多少个数是偶数(包括0在内),有多少个数是3的整数倍。最开始i、n2和n3被初始化成0。然后把i与100做比较,之后for内部的语句被执行。根据i的不同取值,n2被加1、或者n3被加1、或者两者都不加。然后i++被执行。接下来把i与100做比较,之后for内部的语句被执行。如此往复直到i的值大于100。
1.8.2while语句
while语句重复执行一个语句或语句组,直到某个特定的条件表达式的值为假。它的语
法表示如下: while(表达式)语句/语句组 式中的表达式必须是数值表达式。while语句执行过程如下:
-
表达式被计算。
-
如果表达式的值为假,while下面的语句被忽略,程序直接转到while后面的语句执行。 如果表达式的值为真(非零),语句/*语句组被执行。之后程序控制转向1。
下面是一个while语句的例子:
int i=100;
int sum=0;
while(i>0){
sum=sum+i*i;
i--;
}上面的例子计算从1到100的平方和,结果保存在sum中。循环每次判断i是否大于0,如果i大于0,则进入循环,在sum上累加i的平方,将i的值减1,到此次循环结束。下一步重新判断i是否大于0。当某次判断i不大于0时,while语句结束。
1.8.3do-while语句
do-while语句重复执行一个语句或语句组,直到某个特定的条件表达式的值为假。下
面是它的语法表示:
do语句/语句组while(表达式);
do-while语句中,表达式是在语句/语句组被执行之后计算的。所以do后面的语句/语句组至少被执行一次。其中表达式必须是一个数值表达式。do-while语句的执行过程如下:
do后面的语句/*语句组被执行。
-
表达式被计算。如果其值为假,则do-while语句结束,程序继续执行
它后面的语句。如果表达式的值为真(非零),跳转回1重复执行do-while语句。
do-while语句同样可以通过break,goto,或return语句结束。
下面是一个do-while的例子:
int i=100;
int sum=0;
do{
sum=sum+i*i;
i--;
}while(i>0);这个do-while语句完成跟了上面的while相同的功能,即计算从1到100的平方和。前面两句定义了两个整型变量i和sum。在进入do-while语句后,i的平方被累加到sum中,之后i的值被减1。接下来判定i是否大于0,如果i大于0,则重复do后面的语句,否则do-while语句结束。
1.8.4break语句
break语句用来结束离它最近的do、for、switch、或while语句。
下面是一个break语句的例子:
for(i=0;i<10;i++){
for(j=1;j<=5;j++){
if((i+j)%5==0){
printf(“i=%dj=%d\n”,i,j);
break;
}
}
}这个例子中,i从0循环到9,每次j从1循环到5,如果有某个j值使得i+j是5的整数倍,则输出i和j的值,并跳出j循环,开始下一轮的i循环。
1.8.5continue语句
在do、for、或while语句中,continue语句使得其后的语句被忽略,直接回到循环的顶部,开始下一轮的循环。continue语句的语法表示如下:
continue;
do、for、或while语句的下一轮循环用如下方法确定:
-
对于do或while语句,下一轮循环从计算条件表达式的值开始。
-
对于for语句,下一轮循环从计算第一个循环控制条件表达式的值开始。
下面是一个continue语句的例子:
int i=100;
int x=0;
int y=0;
while(i>0){
i--;
x=i%8;
if(x==1)
continue;
y=y+x;
}这段程序计算i从99开始到0为止,累加除了8的倍数加1以外的所有数模8而得到的值。每次while循环开始,判断i的值是否大于0,如果i大于0,则进入循环体,先将i的值减1,然后将i模8的值赋给x,下面的if语句判断x是否等于1,如果x等于1,则回到while语句的开始,判断i是否大于0;如果x不等于1,则将x的值累加到y中。循环在x等于0时结束。
1.9函数
函数是C/C++语言中的一种程序组件单位。一个函数通常代表了一种数据处理的功能,由函数体和函数原型两部分组成。函数原型为这个数据处理功能指定一个标识符号(函数的名称)、说明被处理数据的组成及其类型、处理结果的类型。函数体由一组语句组成,具体实现数据处理的功能。这称为函数的定义。在某段程序中,一个函数可以被当作一个表达式来运行,称为函数的调用。函数的定义并不执行函数体中的语句,只是声明该函数包含这些语句、以及这些语句的运行顺序。函数在被调用之前,必须说明它的原型。被函数处理的数据一般作为函数的参数,在函数调用时确定它们的值。但是在函数体的语句中,可以直接访问函数的参数。函数运行后可以把它的结果返回给调用它的程序。
如果一个程序代码中需要多次实现同一种数据处理功能,通常将这个数据处理功能定义成一个函数,开发成一个单独程序组件。使得整个程序开起来更简洁。此外,当一个程序代码段实现的功能很复杂时,也常常将这个功能分解成若干个相对简单的子功能。每个子功能分别作为一个函数,用一个程序组件实现。
1.9.1函数的定义
函数的定义形式如下:
返回值类型函数名([参数1类型参数名*1*,参数2类型参数名*2*,......]){
语句1;//语句可能与参数有关
语句2;//语句可能与参数有关
......
return返回值;//如果返回值类型为void,则不用返回语句
}
其中,返回值类型表示该函数如果被调用,它执行完之后向调用它的程序返回何种数据类型的值。函数名是程序员自己定义的、能够表明函数用途的标识符号,命名规则与变量的命名规则相同。参数是可选的,有些函数没有参数,有些可以有一至多个参数。每个参数都应说明其类型,以便调用它的程序可以填入正确的参数值。小括号和大括号是必须的。语句中可以把参数当作变量来使用。下面是一个函数定义的例子:
int add(int x,int y){
return x+y;
}这个函数的函数名是add,它有两个参数分别是整数类型的x和整数类型的y;它的返回值类型也是整型,功能是计算两个整数的和,执行的结果是将计算出来的和返回给调用它的程序。两个参数x和y的值是调用它的函数给定的。
函数定义也可以分成两部分,即函数原型说明和函数体。函数原型说明必须在函数调用之前。函数体可以紧跟着函数原型说明,也可以放在程序中间的位置。例如:
int multiple(int x,int y);//函数说明
void main(){
int a=0,b=0;
scanf(“%d%d”,&a,&b);
printf(“%d\n”,multiple(a,b));//函数调用
}
int multiple(int x,int y){//函数体
return x*y;}1.9.2函数的调用
在一段程序中引用一个已经定义过的函数称为函数的调用。在调用函数时要给出每个参数的取值。如果函数有返回值,可以定义一个与返回值类型相同的变量,存储函数的返回值。下面是函数调用的例子:
int add(int x,int y){
returnx+y;
}
void main(){
int n1=5,n2=6,n3;
n3=add(n1,n2);
printf(“%d\n”,n3);
}这段程序,调用函数add计算n1加n2的值,并将计算结果存入n3。最后输出n3的值。
这里要注意的是:如果函数的返回值是整型的,则函数调用表达式本身可以被看作是一个整数,它可以出现在任何整数可以出现的地方。其它类型的返回值也是一样。
有返回值的函数调用可以出现在表达式中,比如n3=add(n1,n2)+7;也是合法的语句。
1.9.3参数传递和返回值
函数调用可以看作在程序组件A的执行过程中,跳出A的代码段,转去执行另外一段代码B,等B执行完之后,再回到A中函数调用的位置,继续执行后面的语句。在函数调用的过程中,程序组件A可以通过参数向程序组件B传送信息;程序组件B结束后,可以通过返回值将其执行结果传回程序组件A。
1.9.3.1参数传递
参数作为数值传递给被调用的函数,在函数内部等同于内部变量。下面是一个例子:
int max(int a,int b){
if(a>=b) return a;
else return b;
}
void main(){
int x=0,y=0,z=0;
x=20;
y=45;
int z=max(x,y);......
}在主函数开始执行之前系统为它分配了空间存放变量x,y,z。第一条赋值语句结束后,x的值修改为20;第二条赋值语句结束后,y的值修改为45;执行到第三条赋值语句时,“=”号右边是函数调用,于是装入函数max的代码。max函数所在的程序段,系统为参数a,b分配了空间(注意:参数的名字是独立于调用它的程序的),并将调用时的参数值填入分配的空间。也就是说调用函数时,将数值45和20传给被调用的函数。这时main暂时停止执行,max开始执行,它执行的结果是将参数b的值45通过return语句返回给main。main接收到max返回的45,并且把它赋值给变量z,此时z变量的内容修改为45。程序继续执行。这里需要注意的是:在max函数中对a,b的任何操作不影响x,y的值。
1.9.3.2返回值
函数执行完以后可以向调用它的程序返回一个值,表明函数运行的状况。很多函数的功能就是对参数进行某种运算,之后通过函数返回值给出运算结果。函数的返回值可以有不同的类型,返回值类型在函数定义时说明。下面是一些函数定义的例子:
-
int min(intx,inty);//返回值类型为int,有两个整型参数,函数名为min 。
-
double calculate(int a,double b);//返回值类型为double,有一个整型参数,一个double型参数,函数名为calculate
-
char judge(void);//返回值类型为char,没有参数,函数名为judge。
-
void doit(inttimes);//返回值类型为void,表示不返回任何值,有一个整型参数,函数名为doit
1.9.4库函数和头文件
C/C++语言标准中,规定了完成某些特定功能的一些函数,这些函数是不同厂商的C/C++语言编译器都会提供的,并且在用C/C++语言编程时可以直接调用的。这样的函数统称为C/C++标准库函数。比如,前面看到的printf函数就是一例。
函数必须先声明原型,然后才能调用。C/C++语言规定,不同功能的库函数,在不同的头文件里进行声明。头文件就是编译器提供的,包含许多库函数的声明,以及其他内容(比如用#define语句定义一系列标识符)的文件。头文件的后缀名是.h。编程时若要使用某个库函数,就需要用#include语句将包含该库函数原型声明的头文件,包含到程序中,否则编译器就会认为该函数没有定义。比如,printf函数就是在stdio.h这个头文件中声明的,因此若要使用该函数,那么就要在程序开头加入:
#include<stdio.h>
1.10标准输入输出
C/C++语言中,有一类库函数,称之为标准输入输出函数,可以用来从键盘读取键入的字符,以及将字符在屏幕上输出。这些函数的声明都包含在头文件stdio.h中。我们介绍以下两个主要的标准输入输出函数:printf和scanf。
1.10.1printf函数(标准输出函数)
printf函数的作用是将一个或多个字符按照程序员指定的格式输出到屏幕上。printf函数调用的一般形式为:
printf(“格式控制字符串”,待输出项1,待输出项2......)其中格式控制字符串用于指定输出格式,是用一对双引号括起来的。 例如: `printf(“x=%d”,50); 上面这条语句中,格式控制字符串就是“x=%d”,待输出项就是50。其输出结果是:x=50象”%d”这样由一个“%”和其后一个(或多个)字符组成的字符串,称为“格式控制符”。
它说明待输出项的类型、输出形式(比如以十进制还是二进制输出,小数点后面保留几位等等)。“%d”表示其对应的待输出项是整型。
“%”和特定的一些字符组合在一起,构成“格式控制符”。常见的格式控制符有:
%d要输出一个整数
%c要输出一个字符
%s要输出一个字符串
%x要输出一个十六进制整数
%u要输出一个无符号整数(正整数)
%f要输出一个浮点数。“格式控制字符串”中,“格式控制符”的个数应该和待输出项的个数相等,并且类型须一一对应。“格式控制字符串”中非格式控制符的部分,则原样输出。例如:
printf(“Nameis%s,Age=%d,weight=%fkg,性别:%c,code=%x”,“Tom”,32,71.5,‘M’,32);
输出结果是: NameisTom,Age=32,weight=71.500000kg,性别:M,code=20
最后的待输出项“32”对应的输出结果是“20”。因为它对应的输出控制符是“%x”,这就导致十进制数“32”被以十六进制的形式输出为“20”。如果就是想输出“%d”这样一个字符串,怎么办呢?做法是,想输出一个“%”,就要连写两个“%”。例如:
printf(“a%%d”); 输出结果是:a%d
如果想让输出换行,则需输出一个换行符“\n”。如:
printf(“What’sup?\nGreat!\nLet’sgo!”);
输出结果是:
What’sup?
Great!
Let’sgo1.10.2 scanf函数(标准输入函数)
scanf函数的一般形式为: scanf(“格式控制字符串”,变量地址1,变量地址2......); scanf函数的作用是从键盘接受输入,并将输入数据存放到变量中。“变量地址”的表
示方法是在变量前面加”&”字符。“格式控制字符串”说明要输入的内容有几项、以及这几项分别是什么类型的。函数执行完后,输入内容的每一项分别被存放到各个变量中。例如:
#include<stdio.h>main()
{
char c;
int n;
scanf("%c%d",&c,&n);
printf("%c,%d",c,n);
}scanf语句中的“%c%d”说明待输入的数据有两项,第一项是一个字符,第二项是一个整数。这两项之间可以用空格或换行进行分隔,也可以不分隔。scanf函数会等待用户从键盘敲入数据,用户输完后必须再敲回车,scanf函数才能继续执行,将两项输入数据存放到变量c和n中。上面的程序,不论敲入“t456回车”,还是“t空格456回车”还是“t回车456回车”,结果都是一样的。输出结果为:t,456。
即字符’t’被读入,存放在变量c中,”456”被读入,存放于变量n中。如果要输入的是两个整数,那么这两个整数输入的时候必须用空格或回车分隔。下面的程序,提示用户输入矩形的高和宽,然后输出其面积。
#include<stdio.h>
main()
{
int nHeight,nWidth;
printf("Please enter the height:\n");
scanf("%d",&nHeight);
printf("Please enter the width:\n");
scanf("%d",&nWidth);
printf("The area is:%d",nHeight*nWidth);
}试着运行一下,看一看结果。
1.11全局变量和局部变量
定义变量时,可以将变量写在一个函数内部,这样的变量叫局部变量;也可以将变量写在所有函数的外面,这样的变量叫全局变量。全局变量在所有函数中均可以使用,局部变量只能在定义它的函数内部使用。请看下面的程序:
int n1=5,n2=10;
void Function1()
{
int n3=4;
n2=3;
}
void Function2(){
int n4;
n1=4;
n3=5;//编译出错
}
int main()
{
int n5;
int n2;
if(n1==5){
int n6;
n6=8;
}
n1=6;
n4=1;//编译出错
n6=9;//编译出错
n2=7;
return 0;
}上面的程序中,n1、n2是全局变量,所以在所有的函数中均能访问,例如语句5、10、21;n3是在函数Function1里定义的,在其他函数中不能访问,因此语句11会导致“变量没定义”的编译错误;语句22也是一样。
一个局部变量起作用的范围(称为“作用域”),就是从定义该变量的语句开始,到包含该变量定义语句的第一个右大括号为止,因此语句19定义的变量n6,其作用域就是从语句19开始直到语句20的位置。在语句23中试图访问n6,导致“变量没定义”的编译错误。
如果某局部变量和某个全局变量的名字一样,那么在该局部变量的作用域中,起作用的是局部变量,全局变量不起作用。例如语句16定义的局部变量n2和全局变量n2同名,那么语句24改变的就是局部变量n2的值,不会影响全局变量n2。
1.12数组
1.12.1一维数组
想想如何编写下面的程序: 接收键盘输入的100个整数,然后将它们按从小到大的顺序输出。要编写这个程序,首先要解决的问题就是:如何存放这100个整数?直观的想法是定义
100个int型变量,n1,n2,n3......n100,用来存放这100个整数。可这样的想法真让人受不了。
幸好,C/C++语言中“数组”的概念,为我们解决上述问题提供了很好的办法。实际上,几乎所有的程序设计语言,都支持数组,用来表达同类型数据元素的集合。在C/C++中,数组的定义方法如下:
类型名数组名[元素个数];
其中“元素个数”必须是常数或常量表达式,不能是变量,而且其值必须是正整数。元素个数也称作“数组的长度”。例如:
intan[100];
上面的语句就定义了一个名字为an的数组,它有100个元素,每个元素都是一个int型变量。我们可以用an这个数组来存放上述程序所需要存储的100个整数。
一般地,如果我们写:
T array[N];
上面的T可以是任何类型名,如char,double,int等。N是一个正整数,或值为正整数的常量表达式。
那么,我们就定义了一个数组,这个数组的名字是array。array数组里有N个元素,每个元素都是一个类型为T的变量。这N个元素在内存里是一个挨一个连续存放的。array数组占用了一片连续的、大小总共为N×sizeof(T)字节的存储空间。
如何访问数组中的元素呢?实际上,每个数组元素都是一个变量,数组元素可以表示为以下形式:
数组名[下标]
其中下标可以是任何值为整型的表达式,该表达式里可以包含变量、函数调用。下标如为小数时,编译器将自动去尾取整。例:如果array是一个数组的名字,i,j都是int型变量,那么以下都是合法的元素
array[5] array[i+j] array[i++]
在C/C++语言中,数组的“下标”是从0开始的。也就是说,如果有数组:
T array[N];
那么array[N]中的N个元素,按地址从小到大的顺序,依次是array[0],array[1],array[2]......array[N-1]。arrayi就是一个T类型的变量。如果array[0]存放在地址n,那么array[i]就被存放在地址n+i*sizeof(T)。
好了,现在让我们来看看如何编写程序,接收键盘输入的100个整数,并排序后从小到大输出。先将100个整数输入到一个数组中,然后对该数组进行排序,最后遍历整个数组,逐个输出其元素。对数组排序有很多种方法,这里我们采用一种最直观的方法,叫做“选择排序”,其基本思想是:如果有N个元素需要排序,那么首先从N个元素中找到最小的那个(称为第0小的)放在第0个位子上,然后再从剩下的N-1个元素中找到最小的放在第1个位子上,然后再从剩下的N-2个元素中找到最小的放在第2个位子上......直到所有的元素都就位。
#include<stdio.h>
#define MAX_NUM 100
int main()
{
int i,j;
int an[MAX_NUM];
//下面两行输入100个整数
for(i=0;i<MAX_NUM;i++)
scanf("%d",&an[i]);
//下面对整个数组进行从小到大排序
for(i=0;i<MAX_NUM-1;i++){//第i次循环后就将第i小的数组元素放好
int nTmpMin=i;//用来记录从第i个到第MAX_NUM-1个元素中,最小的
//那个元素的下标
for(j=i;j<MAX_NUM;j++){
if(an[j]<an[nTmpMin])
nTmpMin=j;
}
//将第i小的元素放在第i个位子上,并将原来占着第i个位子的那个元素挪到//后面
intnTmp=an[i];
an[i]=an[nTmpMin];
an[nTmpMin]=nTmp;
}
//下面两行将排序好的100个元素输出
for(i=0;i<MAX_NUM;i++)
printf("%d\n",an[i]);
return0;
}思考题请自己想想,用另外一种算法来编写排序程序。
本节中提到的数组,其元素都是用数组名加一个下标就能表示出来。这样的数组称为一维数组。实际上,C/C++还支持二维数组乃至多维数组。二维数组中的每个元素,需要用两个下标才能表示。
1.12.2二维数组
如果需要存储一个矩阵,并且希望只要给定行号和列号,就能立即访问到矩阵中的元素,该怎么办?一个直观的想法是矩阵的每一行都用一个一维数组来存放,那么矩阵有几行,就需要定义几个一维数组。这个办法显然很麻烦。C/C++语言支持“二维数组”,能很好的解决这个问题。
如果我们写:T array[N][M];此处T可以是任何类型名,如char,double,int等。M、N都是正整数,或值为正整数的常量表达式。那么,我们就定义了一个二维数组,这个数组的名字是array。array数组里有N×M个元素,每个元素都是一个类型为T的变量。这N×M个元素在内存里是一个挨一个连续存放的。array数组占用了一片连续的、大小总共为N×M×sizeof(T)字节的存储空间。
array数组中的每个元素,都可以表示为:数组名[行个标][列下标]
行下标和列下标都是从0开始的。
我们也可以称上面的二维数组array是N行M列的。其每一行都有M个元素,第i行的元素就是array[i][0]、array[i][1]......array[i][M-1]。同一行的元素,在内存中是连续存放的。而第j列的元素的元素,就是array[0][j]、array[1][j]......array[N-1][j]。
array[0][0]是数组中地址最小的元素。如果array[0][0]存放在地址n,那么array[i][j](i,j为整数)存放的地址就是n+iMsizeof(T)+j*sizeof(T)。
下图显示了二维数组inta[2][3]在内存中的存放方式。假设a[0][0]存放的地址是100,那么a[0][1]的地址就是104,以此类推。

从上图可以看出,二维数组的每一行,实际上都是一个一维数组。对上面的数组inta[2][3]来说,a[0],a[1]都可以看作是一个一维数组的名字,不需要另外声明,就能直接使用。二维数组用于存放矩阵特别合适。一个N行M列的矩阵,恰好可以用一个N行M列的二维数组进行存放。遍历一个二维数组,将其所有元素依次输出的代码如下:
#define ROW 20
#define COL 30
int a[ROW][COL];
for(inti=0;i<ROW-1;i++){
for(intj=0;j<COL-1;j++)
printf(“%d”,a[i][j]);
printf(“\n”);;
}上面的代码将数组a的元素按行依次输出,即先输第0行的元素,然后再输出第1行的元素、第2行的元素......
思考题
如果要将数组a的元素按列依次输出,即先输出第0列,再输出第1列......,该如何编写?
1.12.3数组的初始化
在定义一个一维数组的同时,就可以给数组中的元素赋初值。具体的写法是:
类型名数组名[常量表达式]={值,值......值};
其中在{}中的各数据值即为各元素的初值,值之间用逗号间隔。例如:
int a[10]={0,1,2,3,4,5,6,7,8,9}; 相当于a[0]=0;a[1]=1...a[9]=9;
数组初始化时,{}中值的个数可以少于元素个数。此时,相当只给前面部分元素赋值,而后面的元素,其存储空间里的每个字节都被写入二进制数0。
例如: int a[10]={0,1,2,3,4}; 表示只给a[0]~a[4]5个元素赋值,而后5个元素自动赋0值。在定义数组的时候,如给全部元素赋值,则可以不给出数组元素的个数。例如: int a[]={1,2,3,4,5}; 是合法的,a就是一个有5个元素的数组。
二维数组也可以进行初始化。例如对于数组inta[5][3],可用如下方式初始化:
int a[5][3]={{80,75,92},{61,65,71},{59,63,70},{85,90},{76,77,85}};
每个内层的{},初始化数组中的一行。例如,{80,75,92}就对数组第0行的元素进行初始化,结果使得a[0][0]=80,a[0][1]=75,a[0][2]=92。
1.12.4数组越界
数组元素的下标,可以是任何整数,可以是负数,也可以大于数组的元素个数。如果出现这种情况,编译的时候是不会出错的。例如:
1.int an[10];
2.an[-2]=5;
3.an[200]=10;
4.an[10]=20;
5.int m=an[30];这些语句的语法都没有问题,编译的时候都不会出错。那么,a[-2]是什么含义呢?如果数组a的起始地址是n,那么a[-2]就代表位于地址n+(-2)*size(int)处的一个int型变量。即位于地址n-8处的一个int型变量。编译器就是这样理解的。因此语句2的作用就是往地址n–8处写入数值5(写入4个字节)。地址n–8处,有可能存放的是其他变量,也有可能存放的是指令,往该处写入数据,就有可能意外更改了其他变量的值,甚至更改了程序的指令。程序继续运行就可能会出错。有时,n-8处的地址可能是操作系统不允许程序进行写操作的,碰到这种情况,程序执行到语句2就会立即出错。因此,语句2是不安全的。
象语句2这样,要访问的数组元素并不在数组的存储空间内,这种现象就叫“数组越界”。
语句3、4、5都会导致数组越界。要特别注意,an有10个元素,有效的元素是an[0]到an[9],an[10]已经不在数组an的地址空间内了。这是初学者经常会忽略的。语句5会导致m被赋了一个不可预料的值。在有的操作系统中,程序的某些内存区域是不能读取的,如果an[30]正好位于这样的区域,执行到语句5就会立即引发错误。
除非有特殊的目的,一般我们不会写出象an[-2]=5这样明显越界的语句。但是我们经常会用含有变量的表达式作为数组元素的下标使用。该表达式的值有可能会变成负数,或大于等于数组的长度。这就会导致数组越界。
数组越界是实际编程中常见的错误,而且这类错误往往难以捕捉。因为越界语句本身并不一定导致程序立即出错,但是它埋下的隐患可能在程序运行一段时间后才发作。甚至,运气好的话,虽然由于数组越界,意外改写的别的变量或者指令,但是在程序后续沿某个分支运行时并没有用到这些错误的变量或指令,那么程序就不会出错。
如果在跟踪调试程序的时候,发现某个变量变成了一个不正确的值,然而却想不出为什么这个变量会变成该值,就要考虑一下是否是由于某处的数组越界,导致该变量的值被意外修改了。尤其是定义该变量的附近,也定义了数组的时候。因为在一起定义的一些变量,它们的储存空间一般也是相邻的。
如果由于数组越界导致指令被修改的话,甚至会发生在调试器里调试的时候,程序不按照应当的次序运行的怪现象。比如,单步调试程序的时候,明明碰到一个条件为真的if语句,却就是不执行为真的那个分支。
1.13字符串
C/C++中,字符串有两种形式。第一种形式就是字符串常量,如"CHINA",“Cprogram”。
第二种形式的字符串,存放于字符数组中。该字符数组中包含一个’\0’字符,代表字符串的结尾。我们不妨将用来存放字符串的字符数组,称为“字符串变量”。
C/C++中有许多用于处理字符串的函数,它们都可以用字符串常量或字符数组的名字作为参数。请参见2.17.3小节“字符串和内存操作函数”。
1.13.1字符串常量
字符串常量是由一对双引号括起的字符序列。例如:"CHINA",“C program”,"$12.5" ,“a”等都是合法的字符串常量。
一个字符串常量占据的内存字节数等于字符串中字符数目加1。多出来的那个字节位于字符串的尾部,存放的是字符’\0’。字符’\0’的Ascii码就是二进制数0。C/C++中的字符串,都是以’\0’结尾的。
例如: 字符串"C program"在内存中的布局表示为:

""也是合法的字符串常量。该字符串里没有字符,称为“空串”,但是仍然会占据一个字节的存储空间,就是用来存放代表结束位置的’\0’。如果字符串常量中包含双引号,则双引号应写为“"”。而“\”字符在字符串中出现时,须连写两次,变成“\”。例如: printf("He said:\"I am a stu\\dent.\"");
该语句的输出结果是: He said:"I am a stu\dent."
1.13.2用字符数组存放的字符串
字符数组的形式与前面介绍的整型数组相同。例如:
char szString[10];
字符数组的每个元素占据一个字节。可以用字符数组来存放字符串,此时数组中须包含一个‘\0’字符,代表字符串的结尾。因而字符数组的元素个数,应该不少于被存储字符串的字符数目加1。前面提到,不妨将存储字符串的数组称为“字符串变量”,那么,字符串变量的值,可以在初始化时设定,也可以用一些C/C++库函数进行修改,还可以用对数组元素赋值的办法任意改变其中的某个字符。
下面通过一个例子程序来说明字符串变量的用法。
#include<stdio.h>
#include<string.h>
intmain(){
char szTitle[]="Prison Break";//①
char szHero[100]="Michael Scofield";//②
char szPrisonName[100];
char szResponse[100];
printf("What's the name of the prison in %s?\n", szTitle);//③
scanf("%s",szPrisonName);//④
if(strcmp(szPrisonName,"Fox-River")==0){//⑤
printf("Yeah! Do you love %s?\n", szHero);
}
else{
strcpy( szResponse, "It seems you haven't watched it!\n");//⑥
printf(szResponse);
}
szTitle[0]='t';
szTitle[3]=0;//等效于szTitle[3]=‘\0’;
printf(szTitle);//⑦
return 0;
}-
语句①:定义了一个字符数组szTitle,并进行初始化,使得其长度自动为13(字符串"PrisonBreak"中的字符个数再加上结尾的’\0’)。初始化后szTitle的内存布局图为:
-

-
语句②:定义了一个有100个元素的字符数组szHero,并初始化其前17个元素(”MichealScofield”再加上结尾的’\0’)。
-
语句③:输出:
What's the name of the prison in Prison Break? -
语句④:等待用户输入监狱的名字,并将用户的输入存放到szPrisonName数组中,在输入字符串的末尾自动加上’\0’。如果用户输入超过了99个字符,那么加上’\0’后,就会发生数组越界。scanf函数的格式字符串中,“%s”表示要输入的是一个字符串。要注意,用scanf输入字符串时,输入的字符串中不能有空格,否则被读入的就是空格前面的那部分。例如,如果在本程序运行时输入“Fox River”再敲回车,那么szPrisonName中就会存入“Fox”而不是“Fox River”。
如果想要将将用户输入的包含一个甚至多个空格的一整行,都当作一个字符串读入到szPrisonName中,那么语句④应改成:
gets(szPrisonName);
此时如果用户输入“FoxRiver”然后敲回车,则szPrisonName中就会存放着“Fox River”。
gets是一个标准库函数,它的原型是:
char*gets(char*s);
功能就是将用户键盘输入的一整行,当作一个字符串读入到s中。当然,会自动在s后面添加’\0’。
-
语句⑤:调用string.h中声明的字符串比较库函数strcmp和标准答案进行比较,如果该函数返回值为0,则说明比较结果一致。
-
语句⑥:调用字符串拷贝库函数strcpy将"It seems you haven't watched it!"拷贝到数组szResponse中。使用字符串拷贝函数的时候一定要看看,数组是否能装得下要拷贝的字符串。要特别注意,该拷贝函数会在数组中自动多加一个表示结尾的’\0’
执行到⑦后,szTitle的内存图变为:
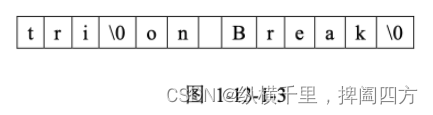
最后,由于在C/C++中对字符串进行处理时,碰到’\0’就认为字符串结束了,因此本条语句输出:
tri
上面说的是用一维字符数组来存放字符串。实际上,二维字符数组也可以用来存放字符串。比如:
charszFriends[6][30]={"Joey","Phoebe","Monica","Chandler","Ross","Rachel"};
则:
printf(szFriends[0]);会输出:Joey
printf(szFriends[5]);会输出:Rachel
思考题
编写一个函数intMyItoa(char*s);其功能是将s中以字符串形式存放的非负整数,转换成相应整数返回。例如,如果s中存放字符串“1234”,则该函数的返回值就是1234。假设s中的字符全是数字,且不考虑s是空串或s太长的情况。
1.14指针
1.14.1指针的基本概念
程序运行时,每个变量都被存放在从某个内存地址开始的若干个字节中。所谓“指针”,也称作“指针变量”,是一种大小为4个字节的变量,其内容代表一个内存地址。大家应该还记得,内存地址的编排,是以字节为单位的。通过一个指针,我们能够对该指针所代表的内存地址开始的若干个字节进行读写。指针的定义方法是:
类型名 *指针变量名;
例如:int p;//p是一个指针,变量p的类型是int
例如:char pc;//pc是一个指针,变量pc的类型是char
例如:float pf;//pf是一个指针,变量pf的类型是float
下面的语句经过强制类型转换,将数值10000赋值给一个指针:int*p=(int*)10000;
此时,p这个指针的内容,就代表内存地址10000。我们也可以说,p指向内存地址10000。请注意:在后文中,为了描述方便,如果p是一个指针,那么我们将“p指向的内存地址”简称为“地址p”。上面的语句执行后,如果我们想对内存地址10000起始的若干个字节进行读写,就可以通过表达式“p”来进行。因为表达式“p”就代表地址p开始的若干字节。请看下面连续执行的两条语句的作用:
*p=5000;//往内存地址10000处起始的若干个字节的内存空间里写入数值5000 int n=*p;//将内存地址10000处起始的若干字节的内容赋值给n,实际效果是使得n=5000
显然,从等号两边的表达式类型应该兼容,可以推想出,表达式“*p”的类型应该是int。
前面的几行文字多次提到了“若干字节”,这个“若干字节”到底是多少字节呢?具体到int*p的这个例子,这个“若干字节”就是4个字节,因为,sizeof(int)=4。
总结一下一般的规律: 如果定义:
T *p;T可以是任何类型的名字,比如int,double,char等等。下文中碰到的“T”也都是这个意思.那么变量p就是一个“指针变量”(简称“指针”),p的类型是T,表达式“p”的类型是T。而通过表达式“*p”,我们就可以读写从地址p开始的sizeof(T)个字节。
通俗地说,就是可以认为,“p”这个表达式,等价于存放在地址p处的一个T类型的变量。表达示“p”中的“”,被称作“间接引用运算符”。 需要记住的是,不论T表示什么类型,sizeof(T)的值都是4。也就是说,所有指针变量,不论它是什么类型的,其占用的空间都是4个字节。因为,指针表示的是地址,而当前流行的CPU的内存寻址范围一般都是4G,即232,所以一个地址正好用32位,即4字节来表示。也许当64位的计算机普及后,新的C/C++编译器会将指针处理成8个字节。
在实际编程中,我们极少需要象前面的“int p=(int)10000”那样,直接给指针赋一个常数地址值。实际上直接读写某个常数地址处的内容,常常会导致程序出错,因为象10000这个地址里存放的是什么,谁也不知道,往10000这个地址里写数据,也许会造成一些破坏。指针的通常用法是:将一个T类型的变量x的地址,赋值给一个类型为T的指针p(俗称“让p指向x”),此后表达式“p”即代表p所指向的变量(即x),通过“*p”就能读取或修改变量x的值。请看下面的程序片段:
char ch1=’A’;//(1)
char *pc=&ch1;//(2)使得pc指向变量ch1
*pc=’B’;//(3)执行效果是使得ch1=’B’
char ch2=*pc;//(4)执行效果是使得ch2=ch1
pc=&ch2;//(5)使得pc指向变量ch2。同一指针在不同时刻可以指向不同变量
*pc=’D’;//语句6,执行效果是使得ch2=’D’上面的语句(2),所做的操作,是将变量ch1的地址写入指针pc中。通俗的说法,就是让指针pc指向变量ch1。“&”符号,在此处被称作“取地址运算符”,功能是取得其操作数的地址。显然,“取地址运算符”是一个单目运算符。
请记住:对于类型为T的变量x,表达式“&x”就表示变量x的地址,表达式“&x”的类型是T*。
语句(3)的作用,是往pc指向的地方写入字符’b’。由于pc指向的地方就是存放变量ch1的地方,“pc”等效于变量ch1,因此语句(3)的作用就是往变量ch1里写入字符’b’。同样,在语句(4)中,pc等效于变量ch1,因此语句4等效于用ch1对ch2进行赋值。
也许有同学会问:如果我们需要修改一个变量的值,直接使用该变量就可以了,不需要通过指向该变量的指针来进行吧?那么指针到底有什么用呢?的确,并不是所有的程序设计语言都有“指针”的概念,Basic,Java都没有。但是“指针”在C/C++中是十分重要的概念,有了指针,用C/C++编写程序可以更加灵活,更加高效。同时,需要注意的是,指针的灵活性带来的副作用就是,大量使用指针的程序更容易出错。下面举一个例子来说明指针用途的一个方面:
假设需要编写一个函数swap,执行swap(a,b)的效果是将a,b两个变量的值互换。如果没有指针,那么在C语言中是无法实现这个功能的(在C++中可以通过“引用”实现)。为什么呢?我们来看,假定a,b都是int型,那么有了下面的swap函数:
void swap(int n1,intn 2){
int nTmp=n1;
n1=n2;
n2=nTmp;
}执行swap(a,b)能够实现交换a、b的值吗?答案显然是否定的。因为在函数内部,n1、n2分别是a、b的一个拷贝,n1,n2的值改变了,不会影响到a、b。
正确的swap函数的C语言实现方法,需要使用指针。代码如下:
void swap(int*pn1,int*pn2){
int nTmp=*pn1;//将pn1指向的变量的值,赋给nTmp
*pn1=*pn2;//将pn2指向的变量的值,赋给pn1指向的变量
*pn2=nTmp;//将nTmp的值赋给pn2指向的变量。
}由于“&a”即是a的地址(其类型是int),因此,swap函数执行期间,pn1的值即为a的地址,也可以说,pn1指向a。那么“pn1”就等价于a,同理,pn2指向b,“*pn2”就等价于b。因此上面的函数能够实现交换a、b的值。
不同类型的指针,如果不经过强制类型转换,是不能直接互相赋值的。请看下面的程序片段:
int *pn,char *pc,char c=0x65;
pn=pc;//(1)
pn=&c;//(2)
pn=(int*)&c;//(3)
intn=*pn;//(4)
*pn=0x12345678;//(5)语句(1)和(2)都会在编译的时候报错,错误信息是类型不兼容。因为在这两条语句中,等号左边的类型是int,而等号右边的类型是char。语句(3)则没有问题,虽然表达式“&c”的类型是char*,但是其值经过强制类型转换后,赋值给pn是可以的。语句(3)执行的效果是使得pn指向c的地址。
思考题
语句(4)的执行结果,是使得n的值变为0x65吗?语句(5)编译会不会出错?如果不出错,执行后会有什么结果?会不会有问题?
1.14.2指针运算
指针变量可以进行以下运算:
1)两个同类型的指针变量,可以比较大小
2两个同类型的指针变量,可以相减。
3)指针变量可以和整数类型变量或常量相加。
4)指针变量可以和减去一个整数类型变量或常量。
5)指针变量还可以自增、自减。
比较大小的意思是:p1、p2是两个同类型的指针,那么,如果地址p1<地址p2,则表达式“p1<p2”的值就为真,反之亦然。p1>p2,p1==p2的意义也同样很好理解。
指针相减的定义是:如果有两个T*类型的指针p1和p2,那么表达式“p1–p2”的类型就是int,其值可正可负,其值的绝对值表示在地址p1和p2之间能够存放多少个T类型的变量。写成公式就是:
p1–p2=(地址p1–地址p2)/sizeof(T) 指针和整数相加的定义是:如果p是一个T类型的指针,而n是一个整型变量或常量,那么表达式“p+n”就是一个类型为T的指针,该指针指向的地址是:
地址p+n×sizeof(T)
“n+p”的意义与“p+n”相同。
指针减去整数的定义是:如果p是一个T类型的指针,而n是一个整型变量或常量,那么表达式“p-n”就是一个类型为T的指针,该指针指向的地址是:
地址p-n×sizeof(T) 当然,按照上面的定义,(p+n),(p–n)都是有意义的了。请同学们自己思考其含义。
思考题如果p是一个T*类型的指针,那么p++、++p、p--、--p分别是什么意思呢?
下面通过一个具体的实例来说明指针运算的用法。
#include<stdio.h>
int main()
{
int *pn1,*pn2;
int n=4;
char *pc1,*pc2;
pn1=(int*)100;//地址pn1为100
pn2=(int*)200;//地址pn2为200
printf("%d\n",pn2-pn1);///输出25,因为(200-100)/sizeof(int)=100/25=4
pc1=(char*)pn1;//地址pc1为100
pc2=(char*)pn2;//地址pc2为200
printf("%d\n",pc1-pc2);//输出-100,因为(100-200)/sizeof(char)=-100
printf("%d\n",(pn2+n)-pn1);//①输出29
int *pn3=pn2+n;//pn2+n就是一个指针,当然可以用它给pn3赋值
printf("%d\n",pn3-pn1);//输出29
printf("%d",(pc2-10)-pc1);//思考,这里输出什么
return0;
}在语句①中,表达式“pn2+n”实际上是一个int*类型的指针,其值为:
地址pn2+n×sizeof(int)=200+4×4=216 (pn2+n)-pn1实际上就是两个int*类型的指针相减,结果是:
(216-100)/sizeof(int)=116/4=29
1.14.3空指针
在C/C++中,可以用“NULL”关键字对任何类型的指针进行赋值。值为NULL的指针,被称作空指针。空指针指向地址0。一般来说,程序不需要,也不能够在地址0处进行读写。
如:int pn=NULL;charpc=NULL;
1.14.4指向指针的指针
如果一个指针里存放的是另一个指针的地址,则称这个指针为指向指针的指针。前面提到的指针定义方法是:
T *p;
这里的T可以是任何类型的名字。实际上,“char”,“int”也都是类型的名字。因此,
int **p;
这样的写法也是合法的,它定义了一个指针p,变量p的类型是int*。“p”则表示一个类型为int的指针变量。在这种情况下,我们说,p是“指针的指针”,因为p指向的是个类型为int的指针,即可以认为p指向的地方存放着一个类型为int*的指针变量。
总结一般的规律,如果定义: T **p;//此处T可以是任何类型名 那么p就被称作“指针的指针”。p这个指针,其类型是T*,而表达式“p”的类型是T,“p”表示一个类型为T的指针。 同理,int ***p;int ****p;int *****p;等,不论中间有多少个“”,都是合法的定义。
再次强调一下,不论T表示什么类型,sizeof(T*)的值都是4。也就是说,所有指针变量,不论它是什么类型的,其占用的空间都是4个字节。
我们还可以定义指针数组,如:
int*array[5]; 那么array数组里的每个元素都是一个类型为int*的指针。
1.14.5指针和数组
一个数组的名字,实际上就是一个指针,该指针指向这个数组存放的起始地址。即,如果我们定义数组Tarray[N];
那么标识符“array”的类型就是T。可以用array给一个T类型的指针赋值,但是,array实际上是编译时其值就确定了的常量,对array进行赋值。例如,如果定义:
int array[5];
那么array的类型就是int*。如果定义:
int *array[5]; 那么array的类型就是int**。请看下面的程序:
#include<stdio.h>
int main(){
int an[200];
int *p;
p=an;//p指向数组an的起始地址,亦即p指向了an[0]
*p=10;//使得an[0]=10
*(p+1)=20;//使得an[1]=20
p[0]=30;//p[i]和*(p+i)是等效的,此句使得an[0]=30
p[4]=40;//使得a[4]=40
for(inti=0;i<10;i++)//通过一个循环对数组an的前10个元素进行赋值
*(p+i)=i;
p++;//p指向a[1]
printf("%d\n",p[0]);//输出a[1]的值,即1。p[0]等效于*p
p=an+6;//p指向a[6]
printf("%d\n",*p);//输出6
return 0;
}上面程序的输出结果是:
1 6
在上述代码中,回顾前面学过的指针运算,表达式“p+1”就是一个int类型的指针,而该指针指向的地址就是:地址p+sizeof(int),而此时p指向a[0],那么p+1自然就指向a[1]了。语句9的注释提到:p[i]和(p+i)是等效的。这是C/C++语法的规定,任何情况下都是如此,不论p是否指向一个数组。 下面的例程中编写了一个对数组进行排序的函数BubbleSort,该函数的第一个参数对应于数组起始地址,第二个参数对应于数组的元素个数。
#include<stdio.h>
void BubbleSort(int*pa,intnNum){
for(inti=nNum-1;i>0;i--)
for(intj=0;j<i;j++)
if(pa[j]>pa[j+1]){
int nTmp=pa[j];
pa[j]=pa[j+1];
pa[j+1]=nTmp;
}
}
#defineNUM5
int main(){
int an[NUM]={5,4,8,2,1};
BubbleSort(an,NUM);//将数组an从小到大排序
for(inti=0;i<NUM;i++)
printf("%d\n",an[i]);
return 0;
}在上面这个例程中,排序的算法称做“起泡排序”。其过程是:先让pa[0]和pa[1]比较,如果pa[0]>pa[1],那么就交换pa[0]和pa[1];然后pa[1]和pa[2]比较,如果pa[1]>pa[2],则交换pa[1]和pa[2]......一直做到pa[nNum-2]和pa[nNum-1]比较,如果pa[nNum-2]>pa[nNum-1],则交换pa[nNum-2]和pa[nNum-1]。经过这一轮的比较和交换,最大的那个元素就会被排在数组末尾,像气泡逐渐浮出水面一样。接下来再从头进行第二轮的比较和交换,让次大的元素浮出到次末尾的位置。一轮轮进行下去,最终将整个数组排好序。
上面的BubbleSort函数定义,写成:voidBubbleSort(intpa[],intnNum)而其他地方都不变,也是一样的。
上面讲述的是指针和一维数组的关系。对于二维数组来说,如果我们定义:
Tarray[M][N];
那么,arrayi就是一个一维数组,所以array[i]的类型是T*。array[i]指向的地址,等于:数组array的起始地址+i×N。因此array的起始地址,实际上就是array[0]。
假定有数组:
intarray[4][5];
那么如下调用上面那个例程中的函数:
BubbleSort(array[1],5);
就能将array数组的第1行排序。而执行BubbleSort(array[0],3)则能将第0行的前3个元素排序。
思考题编写一个函数,参数是int型二维数组的起始地址以及行数、列数,函数将此二维数组逐行输出。
1.14.6字符串和指针
字符串常量的类型就是char。字符数组名的类型当然也是char。因此可以用一个字符串,或一个字符数组名,给一个char*类型的指针赋值。例如:
#include<stdio.h>
#include<string.h>
int main(){
char *p="Tom\n";
char szName[20];
char *pName=szName;
scanf("%s",pName);//①
printf(p);
printf("Name is %s",pName);
return0;
}上面的程序等待用户输入一个字符串,如果用户输入“Jack”那么输出结果就是:
Tom Name is Jack
可见,在printf,scanf函数的输入输出格式字符串中,“%s”所对应的项目,一定是一个类型为char*的表达式。
语句①执行时,将用户输入写入到pName指向的地方,即szName数组。如果用户输入的字符超过19个,则会发生szName数组越界。
一种初学者常犯的错误如下:
char *p; scanf(“%s”,p);
scanf语句会将用户输入写入到p指向的地方。可是此时p指向哪里呢?不确定。往一个不知是哪里的地方写入数据,是不安全的,很可能导致程序的异常错误。
1.14.7void指针
void *p;
上面的语句定义了一个指针p,其类型是void*。这样的指针称之为void指针。可以用任何类型的指针对void指针进行赋值。例如:
double d=1.54; void *p=&d;
但是,由于sizeof(void)是没有定义的,所以对于void类型的指针p,表达式“p”也没有定义,而且所有前面所述的指针运算对p也不能进行。
void指针主要用于内存拷贝。将内存中某一块的内容拷贝到另一块去,那么源块和目的块的地址就都可以用void指针表示。C/C++中有以下标准库函数:
void*memcpy(void*dest,constvoid*src,unsignedintn);
它在头文件string.h和mem.h中声明,作用就是将地址src开始的n字节内容,拷贝到地址dest。返回值就是dest。
下面的程序片段,能将数组a1的内容拷贝到数组a2中去。结果就是a2[0]=a1[0],a2[1]=a1[1]......a2[9]=a1[9]:
int a1[10]; int a2[10]; memcpy(a2,a1,10*sizeof(int));
如果我们自己编写一个这样的内存拷贝函数MyMemcpy,那么可以如下编写:
void*MyMemcpy(void*dest,const void* src,int n){
char *pDest=(char*)dest;
char *pSrc=(char*)src;
for(int i=0;i<n;i++){//逐个字节拷贝源块的内容到目的块
*(pDest+i)=*(pSrc+i);}
return dest;
}思考题上面的MyMemcpy函数是有缺陷的,在某些情况下不能得到正确结果。缺陷在哪里?如何改进?
1.14.8函数指针
程序运行期间,每个函数的函数体都会占用一段连续的内存空间。而函数名就是该函数体所占内存区域的起始地址(也称“入口地址”)。我们可以将函数体的入口地址赋给一个指针变量,使该指针变量指向该函数。然后通过指针变量就可以调用这个函数。这种指向函数的指针变量称为“函数指针”。
函数指针定义的一般形式为:
类型名(*指针变量名)(参数类型1,参数类型2,......);
其中“类型名”表示被指函数的返回值的类型。“(参数类型1,参数类型2,......)”中则依次列出了被指函数的所有参数及其类型。例如:
int(*pf)(int,char);
表示pf是一个函数指针,它所指向的函数,返回值类型应是int,该函数应有两个参数,第一个是int类型,第二个是char类型。
可以用一个原型匹配的函数的名字给一个函数指针赋值。要通过函数指针调用它所指向的函数,写法为:
函数指针名(实参表);
下面的程序说明了函数指针的用法:
#include<stdio.h>
void PrintMin(int a,int b){
if(a<b)
printf("%d",a);
else
printf("%d",b);
}
int main(){
void(*pf)(int,int);//定义函数指针pf
int x=4,y=5;
pf=PrintMin;//用PrintMin函数对指针pf进行赋值
pf(x,y);//调用pf指向的函数,即PrintMin
return 0;
}上面的程序输出结果是:
4
C/C++中有一个快速排序的标准库函数qsort,在stdlib.h中声明,其原型为:
void qsort(void*base,int nelem,unsigned int width,int(*pfCompare)(const void*,const void*));
使用该函数,可以对任何类型的一维数组排序。该函数参数中,base是待排序数组的起始地址,nelem是待排序数组的元素个数,width是待排序数组的每个元素的大小(以字节为单位),最后一个参数pfCompare是一个函数指针,它指向一个“比较函数”。排序就是一个不断比较并交换位置的过程。qsort如何在连元素的类型是什么都不知道的情况下,比较两个元素并判断哪个应该在前呢?答案是,qsort函数在执行期间,会通过pfCompare指针调用一个“比较函数”,用以判断两个元素哪个更应该排在前面。这个“比较函数”不是C/C++的库函数,而是由使用qsort的程序员编写的。在调用qsort时,将“比较函数”的名字作为实参传递给pfCompare。程序员当然清楚该按什么规则决定哪个元素应该在前,哪个元素应该在后,这个规则就体现在“比较函数”中。
qsort函数的用法规定,“比较函数”的原型应是:
int函数名(const void*elem1,const void*elem2);
该函数的两个参数,elem1和elem2,指向待比较的两个元素。也就是说,elem1和elem2就是待比较的两个元素。该函数必须具有以下行为:
1)如果*elem1应该排在*elem2前面,则函数返回值是负整数(任何负整数都行)。 2)如果*elem1和*elem2哪个排在前面都行,那么函数返回0 3)如果*elem1应该排在*elem2后面,则函数返回值是正整数(任何正整数都行)。
下面的程序,功能是调用qsort库函数,将一个unsignedint数组按照个位数从小到大进行排序。比如8,23,15三个数,按个位数从小到大排序,就应该是23,15,8:
#include<stdio.h>
#include<stdlib.h>
int MyCompare(const void*elem1,const void*elem2){
unsigned int*p1,*p2;
p1=(unsigned int*)elem1;//语句①
p2=(unsigned int*)elem2;
return(*p1%10)-(*p2%10);//语句②
}
#define NUM5
int main()
{
unsigned int an[NUM]={8,123,11,10,4};
qsort(an,NUM,sizeof(unsignedint),MyCompare);
for(int i=0;i<NUM;i++)
printf("%d",an[i]);
return0;
}上面程序的输出结果是:
101112348
qsort函数执行期间,需要比较两个元素哪个应在前面时,就以两个元素的地址作为参数,调用MyCompare函数。如果返回值小于0,则qsort就得知第一个元素应该在前,如果返回值大于0,则第一个元素应该在后。如果返回值等于0,则哪个在前都行。
对语句①解释如下:由于elem1是constvoid类型的,是void指针,那么表达式“elem1”是没有意义的。elem1应指向待比较的元素,即一个unsignedint类型的变量,所以要经过强制类型转换,将elem1里存放的地址赋值给p1,这样,*p1就是待比较的第一个元素了。语句7同理。
语句②体现了排序的规则。如果p1的个位数小于p2的个位数,那么就返回负值。其他两种情况不再赘述。
思考题如果要将an数组从大到小排序,那么MyCompare函数该如何编写?
思考题请自己写一个和qsort原型一样的通用排序函数MySort,使得上面的程序如果不调用qsort,而是调用MySort,结果也一样(当然MySort函数需被添加到上面的程序中)。对排序的算法和效率没有要求。
1.14.9指针和动态内存分配
在数组一章中,曾介绍过数组的长度是预先定义好的,在整个程序中固定不变。C/C++不允许定义元素个数不确定的数组。例如:
int n; int a[n];//这种定义是不允许的。
但是在实际的编程中,往往会发生所需的内存空间大小,取决于实际要处理的数据多少,在编程时无法确定的情况。如果总是定义一个尽可能大的数组,又会造成空间浪费。何况,这个“尽可能大”到底是多大才够?
为了解决上述问题,C++提供了一种“动态内存分配”的机制,使得程序可以在运行期间,根据实际需要,要求操作系统临时分配给自己一片内存空间用于存放数据。此种内存分配是在程序运行中进行的,而不是在编译时就确定的,因此称为“动态内存分配”。在C++中,通过“new”运算符来实现动态内存分配。new运算符的第一种用法如下:
P=newT;
T是任意类型名,P是类型为T*的指针。这样的语句,会动态分配出一片大小为sizeof(T)字节的内存空间,并且将该内存空间的起始地址赋值给P。比如:
int *pn;
pn= new int;//(1)
*pn=5;语句(1)动态分配了一片4个字节大小的内存空间,而pn指向这片空间。通过pn,可以读写该内存空间。
new运算符还有第二种用法,用来动态分配一个任意大小的数组:
P=new T[N];T是任意类型名,P是类型为T*的指针,N代表“元素个数”,它可以是任何值为正整数的表达式,表达式里可以包含变量、函数调用。这样的语句动态分配出N×sizeof(T)个字节的内存空间,这片空间的起始地址被赋值给P。例如:
int *pn;
int i=5;
pn=new int[i*20];
pn[0]=20;
pn[100]=30;//(1)语句(1)编译时没有问题。但运行时会导致数组越界。因为上面动态分配的数组,只有100个元素,pn[100]已经不在动态分配的这片内存区域之内了。
如果要求分配的空间太大,操作系统找不到足够的内存来满足,那么动态内存分配就会失败。保险做法是在进行较大的动态内存分配时,要判断一下分配是否成功。
判断的方法是:如果new表达式返回值是NULL,则分配失败,否则分配成功。例如:
int*pn=new int[200000];
if(pn==NULL)
printf(“内存分配失败”);
else
printf(“内存分配成功”);程序从操作系统动态分配所得的内存空间,使用完后应该释放,交还操作系统,以便操作系统将这片内存空间分配给其他程序使用。C++提供“delete”运算符,用以释放动态分配的内存空间。
delete运算符的基本用法是:
delete指针;
该指针必须是指向动态分配的内存空间的,否则运行时很可能会出错。例如:
int *p=new int;
*p=5;
delete p;
delete p;//本句会导致程序异常上面的第一条delete语句,正确地释放了动态分配的4个字节内存空间。第二条delete语句会导致程序出错,因为p所指向的空间已经释放,p不再是指向动态分配的内存空间的指针了。
再例如:
int *p=new int;
int *p2=p;
delete p2;
delete p1;上面这段程序,同样是第一条delete语句正确,第二条delete语句会导致出错。
如果是用new的第二种用法分配的内存空间,即动态分配了一个数组,那么,释放该数组的时候,应以如下形式使用delete运算符:
delete[]指针;
例如:
int *p=new int[20];
p[0]=1;
delete[]p;同样要求,被delete的指针p必须是指向动态分配的内存空间的指针,否则会出错。如果动态分配了一个数组,但是却用“delete指针”的方式释放,则编译时没有
问题,运行时也一般不会发现异常,但实际上会导致动态分配的数组没有被完全释放。
请牢记,用new运算符动态分配的内存空间,一定要用delete运算符予以释放。否则即便程序运行结束,这部分内存空间仍然不会被操作系统收回,从而成为被白白浪费掉的内存垃圾。这种现象也称为“内存泄漏”。
如果一个程序不停地进行动态内存分配而总是忘了释放,那么可用内存就会被该程序大量消耗,即便该程序结束也不能恢复。这就会导致操作系统运行速度变慢,甚至无法再启动新的程序。当然,不用太担心,只要重新启动计算机,症状就会消失了。
编程时如果进行了动态内存分配,那么一定要确保其后的每一条执行路径都能释放它。
1.14.10误用无效指针
指针提供了灵活强大的功能,但也是程序bug、尤其是难以捕捉的bug的罪魁祸首。许多错误就是因为在指针指向了某个不安全的地方,甚至指针为NULL的时候,还依然通过该指针读写其指向的内存区域而引起的。这样的错误导致的现象和上一章中“数组越界”导致的现象几乎完全一样。
例如,新手常写出以下错误的代码:
char *p; scanf(“%s”,p);//希望将一个字符串从键盘读入,存放到p指向的地方
p并没有经过赋值,不知道指向哪里,此时用scanf语句往p指向的地方读入字符串,当然是不安全的。
1.15结构
1.15.1“结构”的概念
在现实问题中,常常需要用一组不同类型的数据来描述一个对象。比如一个学生的学号、姓名和绩点。一个工人的姓名、性别、年龄、工资、电话。如果编程时要用多个不同类型的变量来描述一个这样的对象,当要描述的对象较多的时候,就很麻烦,程序容易写错了。当然希望只用一个变量就能代表一个“学生”这样的对象。
C/C++允许程序员自己定义新的数据类型。因此我们可以定义一种新的数据类型,比如该类型名为Student,那么一个Student类型的变量就能描述一个学生的全部信息。我们还可以定义另一种新的数据类型,比如名为Worker,那么一个Worker类型的变量就能描述一个工人的全部信息。如何定义这么好用的“新类型”呢?
C/C++中有“结构”(也称为“结构体”)的概念,支持在已有基本数据类型的基础上定义复合的数据类型。用“struct”关键字来定义一个“结构”,也就定义了一个新的数据类型。定义“结构”的具体写法是:
struct结构名{
成员类型名 成员变量名;
成员类型名 成员变量名;
成员类型名 成员变量名;......
};例如:
struct Student{
unsignedID;
char szName[20];
float fGPA;
};在上面这个结构定义中,结构名为Student。结构名可以作为数据类型名使用。定义了一个结构,亦即定义了一种新的数据类型。在上面,我们就定义了一种新的数据类型,名为Student。一个Student结构的变量是一个复合型的变量,由3个成员组成。第一个成员变量ID是unsigned型的,用来表示学号;第二个成员变量szName是字符数组,用来表示姓名;第三个成员变量fGPA是float型的,表示绩点。不要忘了结构定义一定是以一个分号结束。
象Student这样通过struct关键字定义出来的数据类型,一般统称为“结构类型”。由结构类型定义的变量,统称为“结构变量”。
1.15.2结构变量的定义
定义了一个结构类型后,就能定义该结构的变量了。在C++中,定义方法就是:
结构名变量名;
例如,如果定义了结构:
struct Student{unsignedID;
chars zName[20];
float fGPA;
};那么,Student stu1,stu2;就定义了两个结构变量stu1和stu2。这两个变量的类型都是Student。还可以直接写:
struct Student{
unsigned ID;
chars zName[20];
float fGPA;
}stu1,stu2;也能定义出stu1,stu2这两个Student类型的变量。 显然,象stu1这样的一个变量,就能描述一个学生的基本信息。两个同类型的结构变量,可以互相赋值。如:stu1=stu2;一般来说,一个结构变量所占的内存空间的大小,就是结构中所有成员变量大小之和。
所以sizeof(Student)=28。结构变量中的各个成员变量在内存中一般是连续存放的,定义时在前面的成员变量,地址也在前面。比如,一个Student类型的变量,共占用28字节,其内存布局图如下:

一个结构的成员变量可以是任何类型的,包括可以是另一个结构类型。比如,定义了一个结构:
struct Date{
int nYear;
int nMonth;
int nDay;
};之后,我们还可以再定义一个更详细的包括生日的StudentEx结构:
struct StudentEx{
unsigned ID;
char szName[20];
float fGPA;
Date Birthday;
};后文中还会用到StudentEx结构,为节省篇幅在后文里对StudentEx就不再说明了。
思考题StudentEx变量的内存布局图是什么样的?
1.15.3访问结构变量的成员变量
一个结构变量的成员变量,可以完全和一个普通变量一样来使用,也可以取得其地址。
访问结构变量的成员变量的一般形式是:
结构变量名.成员变量名
假设已经定义了前面的StudentEx结构,那么我们就可以写:
Student Exstu;
scanf(“%f”,&stu.fGPA);
stu.ID=12345;
strcpy(stu.szName,”Tom”);
printf(“%f”,stu.fGPA);
stu.Birthday.nYear=1984;
unsigned*p=&stu.ID;//p指向stu中的ID成员变量1.15.4结构变量的初始化
结构变量可以在定义时进行初始化。例如对前面提到的StudentEx类型,其变量可以用
如下方式初始化:
Student Exstu={1234,”Tom”,3.78,{1984,12,28}};
初始化后,stu所代表的学生,学号是1234,姓名为“Tom”,绩点是3.78,生日是1984年12月28日。
1.15.5结构数组
数组的元素也可以是结构类型的。在实际应用中,经常用结构数组来表示具有相同属性的一个群体。如一个班的学生等。
定义结构数组的方法是:结构名数组名[元素个数];
例如:
Student ExMyClass[50];
就定义了一个包含50个元素的结构数组,用来记录一个班级的学生信息。数组的每个元素都是一个StudentEx类型的变量。标识符“MyClass”的类型就是StudentEx*。
对结构数组也可以进行初始化。如:
Student ExMyClass[50]={
{1234,”Tom”,3.78,{1984,12,28}},
{1235,”Jack”,3.25,{1985,12,23}},
{1236,”Mary”,4.00,{1984,12,21}},
{1237,”Jone”,2.78,{1985,2,28}}
};用这种方式初始化,则数组MyClass后面的46个元素,其存储空间里的每个字节都被写入二进制数0。
定义了MyClass后,以下语句都是合法的:
MyClass[1].ID=1267;
MyClass[2].Birthday.nYear=1986;
intn=MyClass[2].Birthday.nMonth;
scanf(“%s”,MyClass[0].szName);1.15.6指向结构变量的指针
可定义指向结构变量的指针,即所谓“结构指针”。定义的一般形式为:
结构名*指针变量名;
例如:
Student Ex*pStudent;
Student ExStu1;
pStudent=&Stu1;
Student ExStu2=*pStudent;通过指针,访问其指向的结构变量的成员变量,写法有两种:
指针->成员变量名
或为:
(*指针).成员变量名
例如:pStudent->ID;或者:
(*pStudent).ID;
下面的程序片段通过指针对一个StudentEx变量赋值,然后输出其值。
StudentEx Stu;
StudentEx *pStu;
pStu=&Stu;
pStu->ID=12345;
pStu->fGPA=3.48;
printf(“%d”,Stu.ID);//输出12345
printf(“%f”,Stu.fGPA);//输出3.48结构指针还可以指向一个结构数组,这时结构指针的值是整个结构数组的起始地址。结构指针也可指向结构数组的一个元素,这时结构指针的值是该数组元素的地址。
设ps为指向某结构数组的指针,则ps指向该结构数组的0号元素,ps+1指向1号元素,ps+i则指向i号元素。这与普通数组的情况是一致的。
结构变量可以作为函数的参数。如:
void PrintStudentInfo(StudentExStu);
StudentExStu1;
PrintStudentInfo(Stu1);当调用上面的PrintStudentInfo函数时,参数Stu会是变量Stu1的一个拷贝。如果StudentEx结构的体积较大,那么这个拷贝操作就会耗费不少的空间和时间。可以考虑使用结构指针作为函数参数,这时参数传递的只是4个字节的地址,从而减少了时间和空间的开销。例如:
void PrintStudentInfo(StudentEx*pStu);
Student ExStu1;
PrintStudentInfo(&Stu1);那么在PrintStudentInfo函数执行过程中,pStu指向Stu1变量,通过pStu一样可以访问到Stu1的所有信息。
下面的例程调用qsort函数,将一个Student结构数组先按照绩点从小到大排序输出,再按照姓名字典顺序排序输出。
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#defineNUM4
struct Student{
unsigned ID;
chars zName[20];
float fGPA;
};
Student MyClass[NUM]={
{1234,"Tom",3.78},
{1238,"Jack",3.25},
{1232,"Mary",4.00},
{1237,"Jone",2.78}
};
int CompareID(const void*elem1,const void*elem2)
{
Student*ps1=(Student*)elem1;
Student*ps2=(Student*)elem2;
return ps1->ID-ps2->ID;
}
int CompareName(const void*elem1,const void*elem2)
{
Student*ps1=(Student*)elem1;
Student*ps2=(Student*)elem2;
return strcmp(ps1->szName,ps2->szName);
}
int main(){
int i;
qsort(MyClass,NUM,sizeof(Student),CompareID);
for(i=0;i<NUM;i++)
printf("%s",MyClass[i].szName);
printf("\n");
qsort(MyClass,NUM,sizeof(Student),CompareName);
for(i=0;i<NUM;i++)
printf("%s",MyClass[i].szName);
return 0;
};上面的程序输出结果是:
Mary Tom Jone Jack Jack Jone Mary Tom
1.15.7动态分配结构变量和结构数组
结构变量、结构数组都是可以动态分配存储空间的,如:
Student Ex*pStu=newStudentEx;
pStu->ID=1234;
delete pStu;
pStu=new StudentEx[20];
pStu[0].ID=1235;
delete[]pStu;1.16C语言标准库函数
C语言中有大量的标准库函数,根据功能不同,声明于不同的头文件中。这些库函数在C++中也能使用。下面分类列举了一些C语言常用库函数,由于篇幅所限,只列出函数名字及其作用。
1.16.1数学函数
数学库函数声明在math.h中,主要有:
abs(x)//求整型数x的绝对值
cos(x)//x(弧度)的余弦
fabs(x)//求浮点数x的绝对值
ceil(x)//求不小于x的最小整数
floor(x)//求不大于x的最小整数
log(x)//求x的自然对数
log10(x)//求x的对数(底为10)
pow(x,y)//求x的y次方
sin(x)//求x(弧度)的正弦
sqrt(x)//求x的平方根1.16.2字符处理函数
在ctype.h中声明,主要有:
int isdigit(intc)//判断c是否是数字字符
int isalpha(intc)//判断c是否是一个字母
int isalnum(intc)//判断c是否是一个数字或字母
int islower(intc)//判断c是否是一个小写字母
int islower(intc)//判断c是否是一个小写字母
int isupper(intc)//判断c是否是一个大写字母
int toupper(intc)//如果c是一个小写字母,则返回其大写字母
int tolower(intc)//如果c是一个大写字母,则返回其小写字母1.16.3字符串和内存操作函数
字符串和内存操作函数声明在string.h中,在调用这些函数时,可以用字符串常量或字符数组名,以及char类型的变量,作为其char类型的参数。字符串函数常用的有:
char *strchr(char*s,intc) 如果s中包含字符c,则返回一个指向s第一次出现的该字符的指针,否则返回NULL
char *strstr(char*s1,char*s2)
如果s2是s1的一个子串,则返回一个指向s1中首次出现s2的位置的指针,否则返回NULL char *strlwr(char*s)
将s中的字母都变成小写
char *strupr(char*s)
将s中的字母都变成大写 char *strcpy(char*s1,char*s2)
将字符串s2的内容拷贝到s1中去 char *strncpy(char*s1,char*s2,intn)
将字符串s2的内容拷贝到s1中去,但是最多拷贝n个字节。如果拷贝字节数达到n,那么就不会往s1中写入结尾的’\0’ char *strcat(char*s1,char*s2)
将字符串s2添加到s2末尾 int strcmp(char*s1,char*s2)
比较两个字符串,大小写相关。如果返回值小于0,则说明s1按字典顺序在s2前面;返回值等于0,则说明两个字符串一样;返回值大于0,则说明s1按字典顺序在s2后面。 int stricmp(char*s1,char*s2)
比较两个字符串,大小写无关。其他和strcmp同。
int strlen(constchar*string)
计算字符串的长度
char* strncat(char*strDestination,constchar*strSource,size_tcount) 将字符串strSource中的前count个字符添加到字符串strDestination的末尾
int strncmp(constchar*string1,constchar*string2,size_tcount)
分别取两个字符串的前count个字符作为子字符串,比较它们的大小
char *strrev(char*string)
将字符串string前后颠倒。
void *memcpy(void*s1,void*s2,intn)
将内存地址s2处的n字节内容拷贝到内存地址s1
void *memset(void*s,intc,intn)
将内存地址s开始的n个字节全部置为c
1.16.4字符串转换函数
有几个函数,可以完成将字符串转换为整数、或将整数转换成字符串等这类功能。它们定义在stdlib.h中:
int atoi(char*s) 将字符串s里的内容转换成一个整型数返回。比如,如果字符串s的内容是“1234”,
那么函数返回值就是1234 double atof(char*s)
将字符串s中的内容转换成浮点数。 char *itoa(int value,char*string,intradix);
将整型值value以radix进制表示法写入string。比如:
char szValue[20]; itoa(32,szValue,10);则使得szValue的内容变为“32”
itoa(32,szValue,16);则使得szValue的内容变为“20”