每天五分钟机器学习:基于正则化方法解决算法模型的过拟合问题
为什么会出现过拟合?过拟合的模型正是由于假设函数中那些高次项导致的,如果那些高次项没有(也就是高次项的系数为0或者足够小),那么算法就能得到一个比较不错的模型了,也就不会出现过拟合问题了。
所以我们要做的就是使用一种方法在一定程度上减小这些高次项的系数θ的值,这就是正则化的基本思想。
正则化是如何进行的呢?举一个例子:
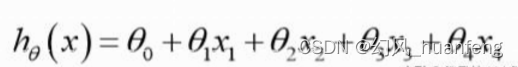
此时算法的优化目标,也就是最小化代价函数:
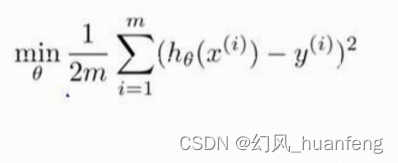
现在假如为了防止模型过拟合,我们要对特征x3和特征x4进行惩罚,也就是说我们要减少特征x3和特征x4的系数,也就是θ3和θ4 的大小。
如何才能在训练过程中使得θ3和θ4变小呢?
我们可以尝试将这个惩罚纳入代价函数中,这样就会使得算法模型选择较小一些的θ3和θ4,所以此时修改后的代价函数如下:
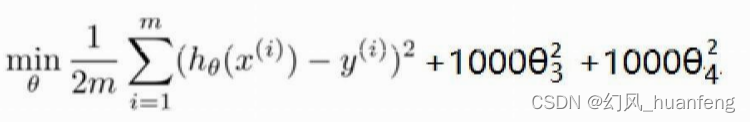
我们可以看出θ3²和θ4²都乘以了1000,那么θ3²和θ4²只要稍微大一点都会使得代价函数很大,所以为了最小化这个代价函数,算法只能让θ3和θ4足够小,也就是θ3≈0、θ4≈0,这样得到的假设能够恰当的拟合数据,最终得到很好的一个二次函数