(GCC)STM32进阶详解之栈回溯
接上一篇:
函数调用
由上一篇大概了解了函数是如何被调用,中断或者说异常又是如何被调用,而这一篇相当于上一篇知识的一个应用,也是上一篇遗留的思考,即在hardfault中如何判断是从何处触发这个异常的。本来打算自己写demo,但是查到github上有一个开源的CmBacktrace,既然有大牛已经写了开源的库,就直接拿来分析印证吧。项目地址:
CmBacktrace
硬件我使用的是STM32F103ZET6最小系统板,demo是项目中提供的,直接下载即可。
1.原理分析
从串口1输出如下:

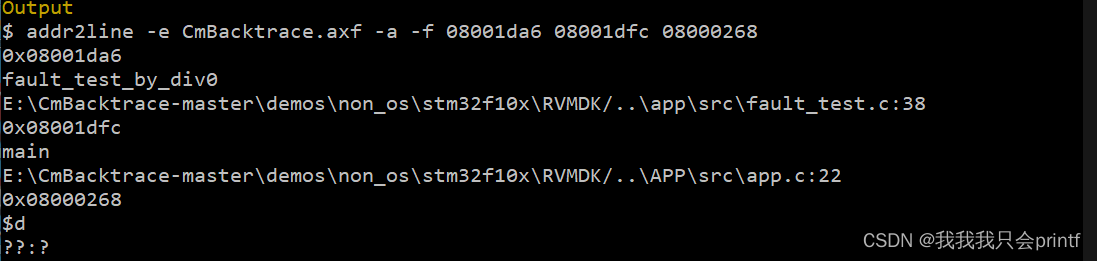
实际使用项目中提供的addr2line运行打印出来的地址时,输出如下:
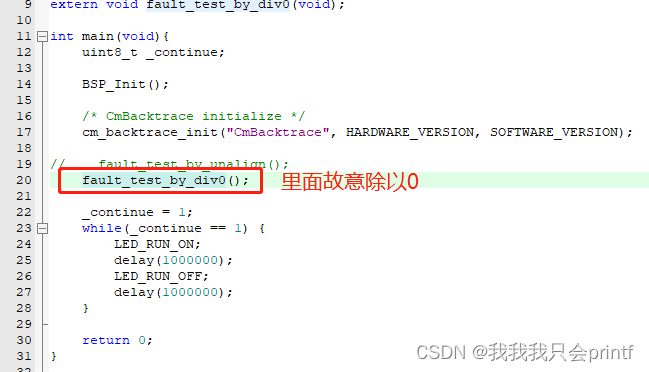
我们回过头来看一下demo,在app.c中的main里有调用fault_test_by_div0()这个函数,它里面故意做了除0运算:
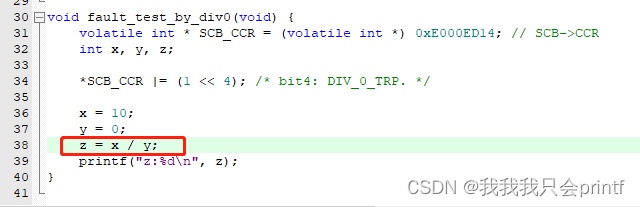
仔细对比addr2line的输出,我们可以看到,输出结果是完全正确的,包括行号(有空行的情况可能会有点偏差)。其实addr2line这个程序的作用是通过你输入的地址和.elf文件,输出这个地址在.elf文件中表示的函数。原理不难理解,elf文件中完美保留了每个函数的地址,以及每个函数对应的.c文件,自然可以去对应.c中查看该函数行号。可以参考我之前分析elf文件的博文:
(GCC)STM32进阶修炼之ELF文件剖析
所以这里的关键其实在于我们给addr2line传入的三个地址:
addr2line -e CmBacktrace.axf -a -f 08001da6 08001dfc 08000268
打开.axf文件可以看到以上三个地址分别对应的函数:
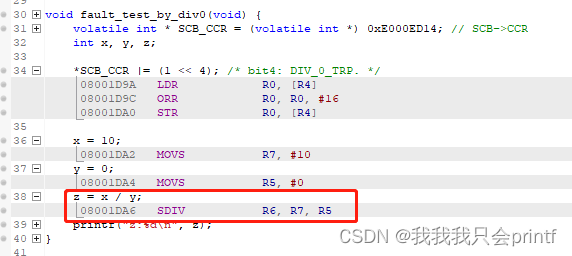
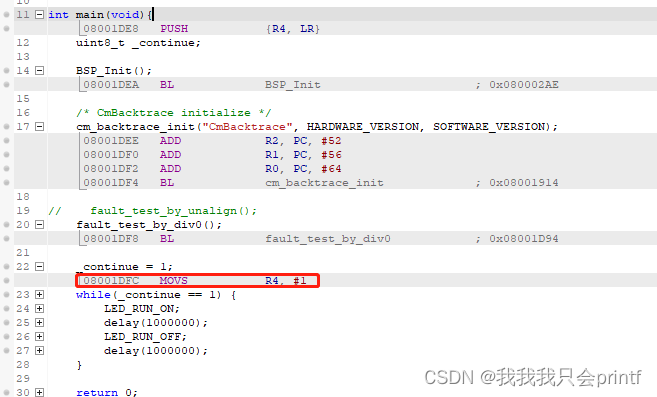
可以看到最后一个地址指向的08000268其实在源文件中是找不到的而且它保存的也不是某行代码,而是一个全局变量,所以addr2line打印的是问号,表示查找不到。
从这里可以看出,我们的关键就在于找到出错误代码的地址,以及调用这个出错误函数的地方,当然,实际可能有很多个函数层层嵌套调用,而只需要依次找到上一层调用地址,就可以一层一层的递进。
这里,我会再次分析整个函数调用流程,是对上一节内容的一个印证。请注意栈中保存数据在整个流程中的变化!
首先我们把断点打在main函数的起始位置,此时现场如下:
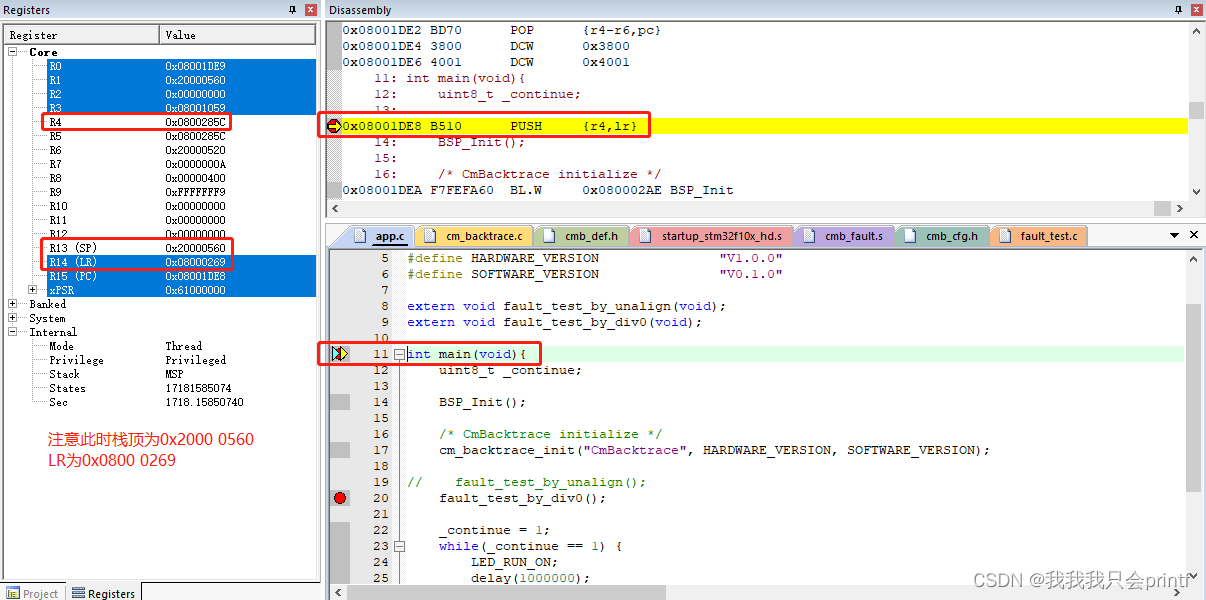
由上图我们可以知道几点:
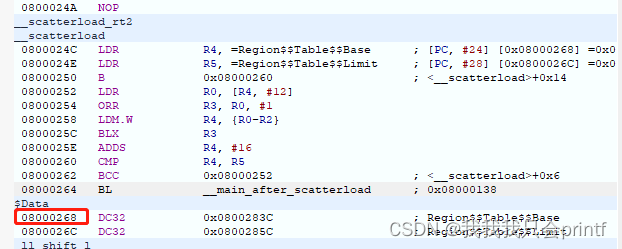
1.调用mian函数结束后, 我们返回到调用main函数的地方,并执行下一个指令,它的地址是0x08000268(为什么减一我前几章有说过),这个地址实际对应:

实际这个地址保存的根本不是可以执行的代码,那为什么还要指明从main执行完后回来执行它?
由上图可以看到,我们实际跳转main是0x08000264,这里使用的指令是BL,这个指令会自动装载下一个指令地址到LR(即执行时PC指向的地址),保证调用完函数后,可以很方便的直接用汇编指令:B LR返回到上层函数,然而实际这个工程中,main函数根本不会返回,所以这个地址即使是错的,也无所谓。
2.因为我们main函数中还要再使用汇编指令BL和寄存器R4,所以我们需要把它们保存在栈里,防止被覆盖,所以可以看到main函数第一行汇编就是把LR和R4保存在了栈里。而此时的栈顶是SP所指向的0x2000 0560,打开.map文件可以看到:
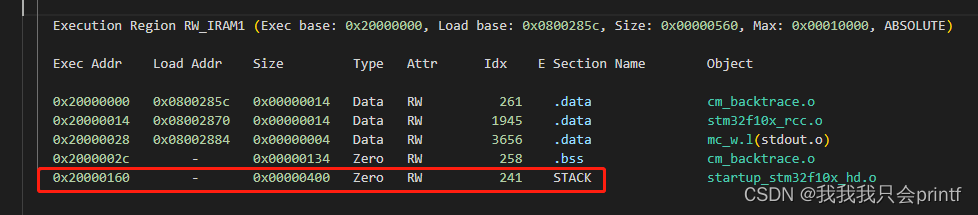
我们分配给栈的空间是从0x2000 0160开始,大小为0x400的空间,因为栈是从上到下生长的,所以栈顶一开始就是0x2000 0560。
我们再次推进断点位置,这次把断点打在进入fault_test_by_div0函数前,具体现场如下:
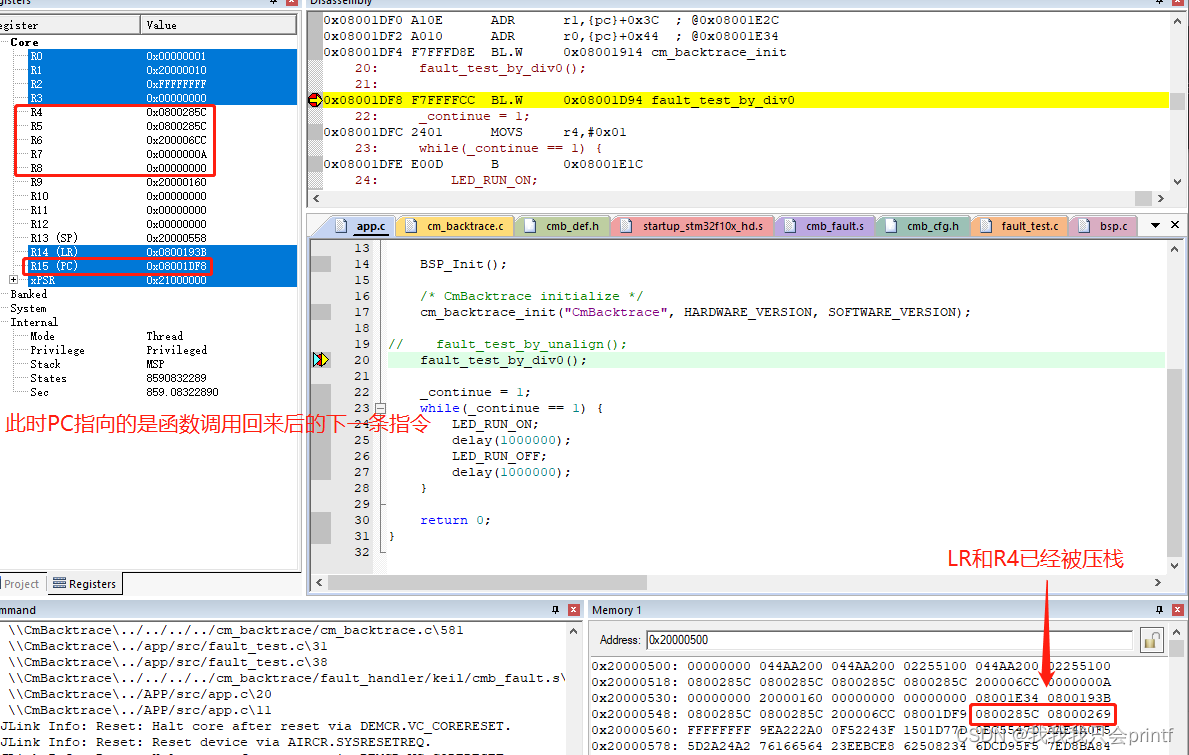
可以看到,根据上文的分析,LR和R4已经被压栈,此时栈顶已经变成了0x20000558,我们继续向下推进, 这次把断点打在fault_test_by_div0函数一开始的位置:
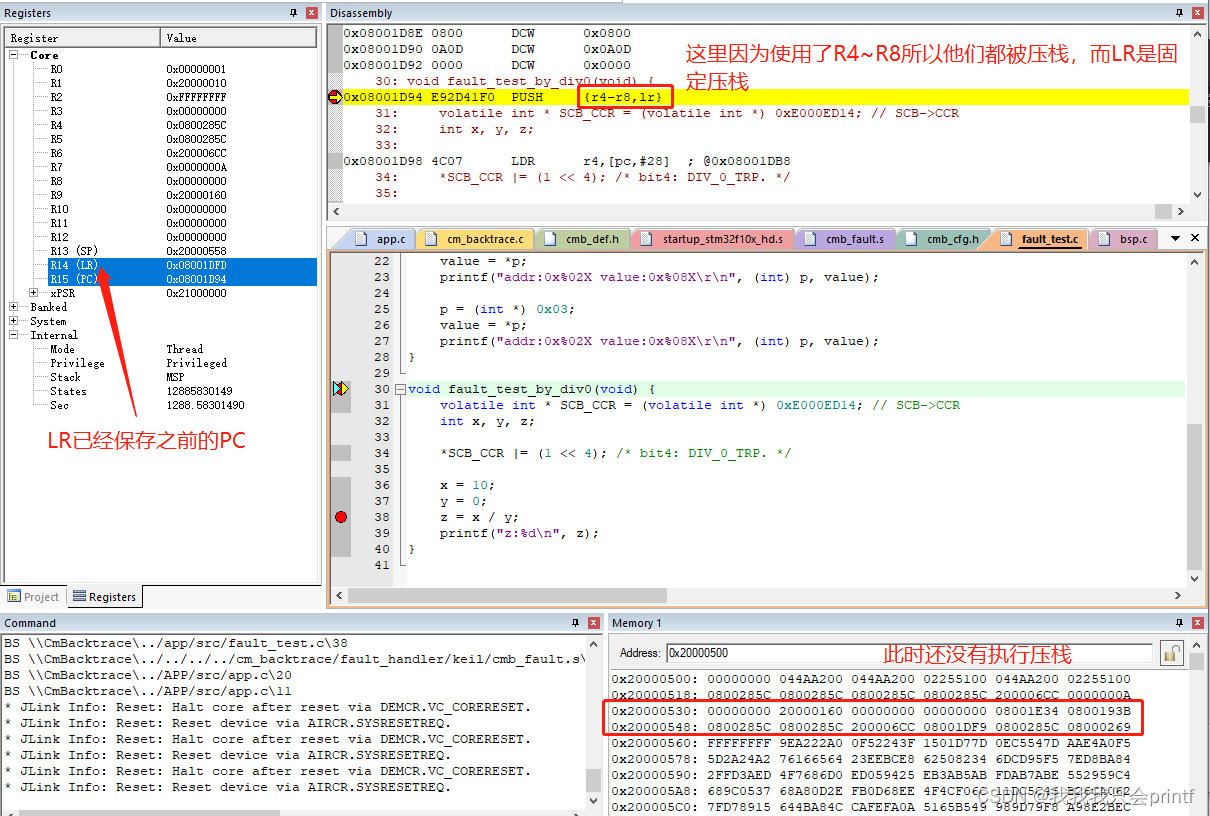
继续把断点打在出错的那一行函数,继续运行分析:
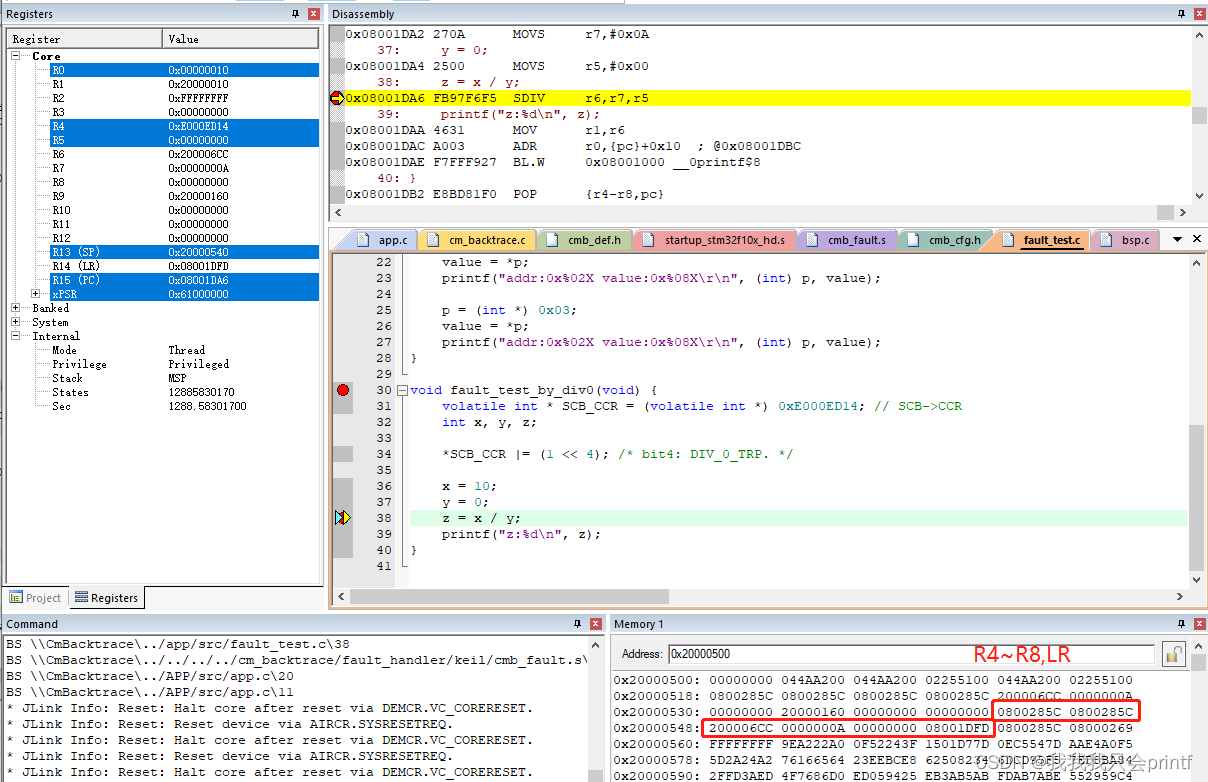
对比上面两张图可以看到,栈内数据和我们分析的一模一样,现在我们即将运行错误代码,我们知道,Cortex-M系列的MCU出现错误会跳往编号为3的中断:
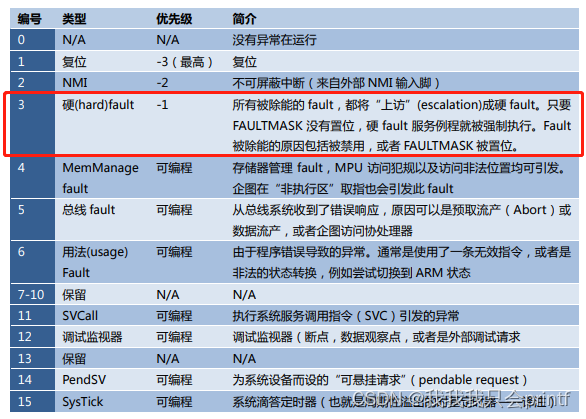
这里我们找到中断表,最后可以查到跳转到了HardFault_Handler函数,我们把下个断点打在这里:
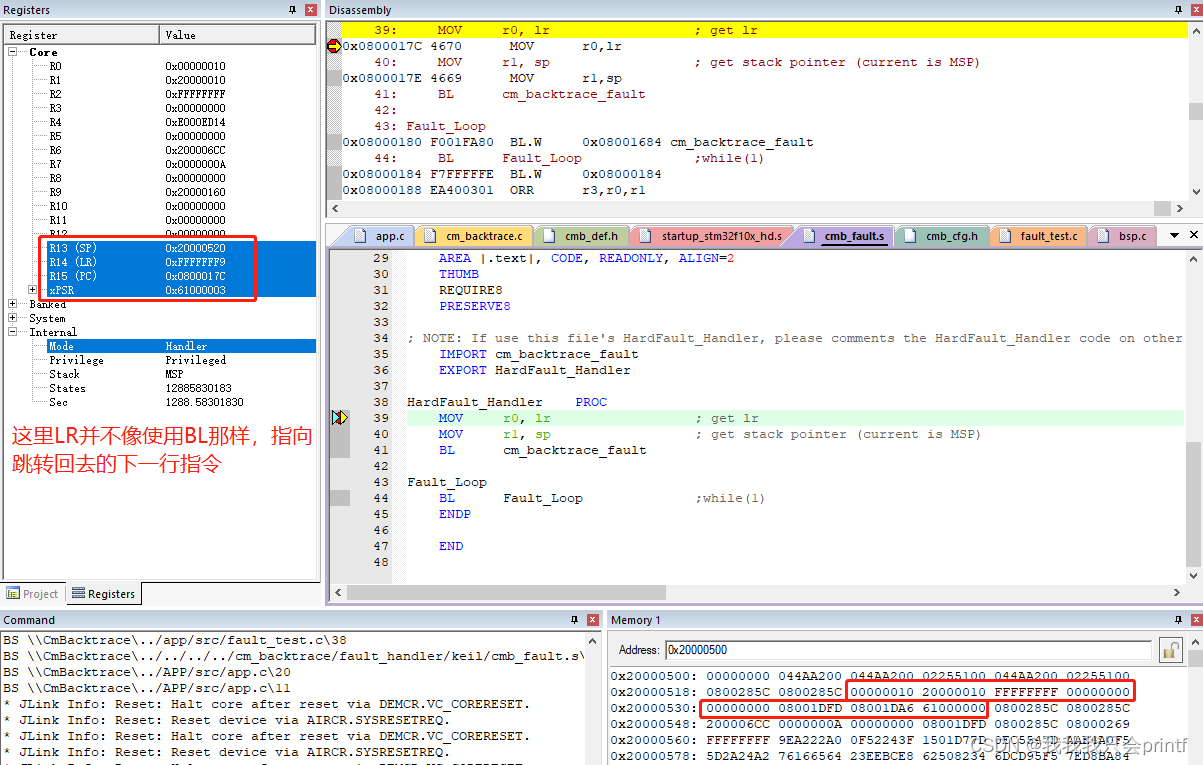
可以看到,出现错误后和我们预期一样,注意两个地方:
1.进入中断后,LR的值会被自动更新为特殊的EXC_RETURN,这个值的含义如下:
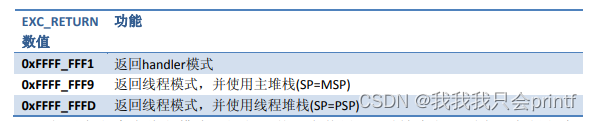
也就是它告诉了我们,这个中断执行完后,我们返回时该使用何种模式,和使用哪个堆栈指针。
2.正因为LR因为上述原因被占用了,导致我们没有办法再直接通过LR返回到中断被调用前的位置,所以进入中断后,一部分寄存器是硬件自动入栈的:
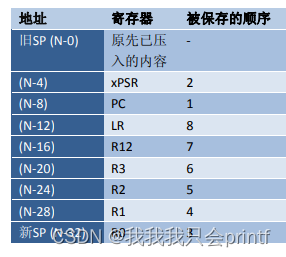
由进入HardFault_Handler后的现场图也可以看到,压栈的内容与寄存器是一一对应的。也就是说硬件替我们保存了一部分现场,你可能会问了,为何还有一部分寄存器没有被保存,万一在进入中断前我使用过它们比如R5,中断中被破坏了,代码从中断中出来后,再回去执行不是一样会出错吗?这在上一章有讲过,函数调用原则里有分哪些寄存器是需要调用者保护,哪些寄存器是需要被调用者保护的,这里除了硬件压栈的那部分,剩余的都应该由被调用者保护。
这样是不是一切都明了了?思考这样一个问题:
如果此时让你在HardFault_Handler中写一个函数,用它去寻找是由哪条指令执行后,导致进入了HardFault_Handler,而那个指令所在的函数又是被哪里所调用,你会写吗?
一切一切的关键又回到了那三个地址:
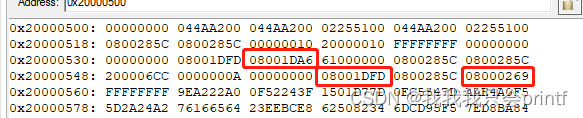
对,就是如何从栈中找到这三个地址!
至于为什么可以打印出错误类型是除0,那很简单,即使你没有移植任何代码,在keil中HardFault_Handler打上断点,进入后,查看:
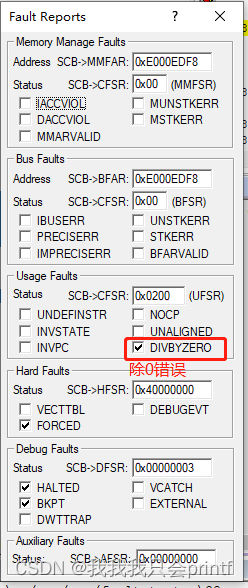
简单来说就是Cortex-M内核提供了一些寄存器,它们保存出错时,错误的大概类型。,只需在进入错误中断后查询相关寄存器即可。
听起来这一切都很简单是不是?但是想写好一个开源库却比想象中难。
2.代码分析
就以上文中demo里不使用OS的情况为例,分析整个代码流程。
首先看main函数,和CmBacktrace相关的初始化就一个函数:
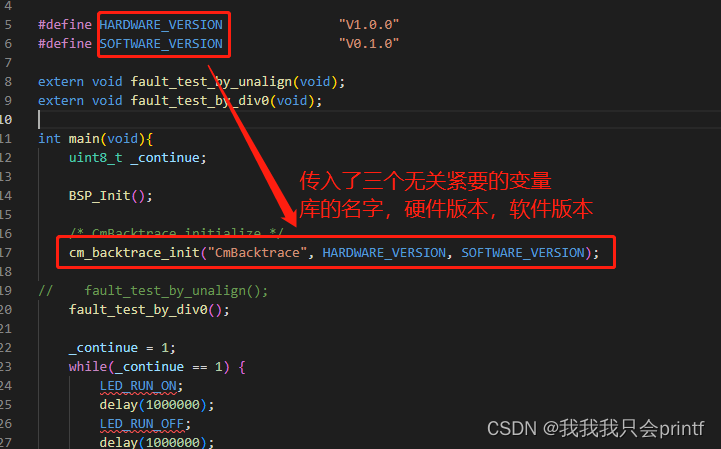
而这个函数里面很简单,仅仅是赋值了一些变量:
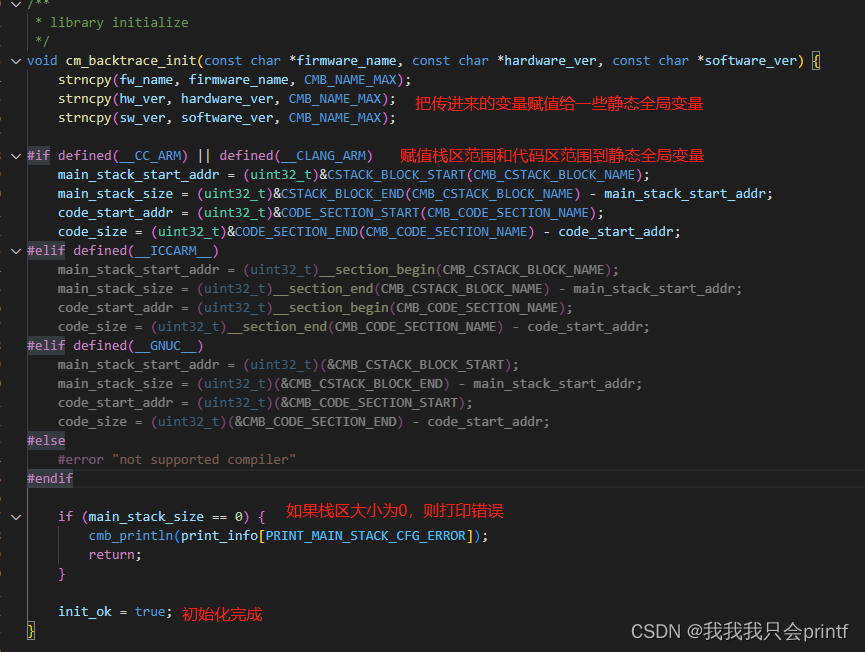
这些变量定义如下:
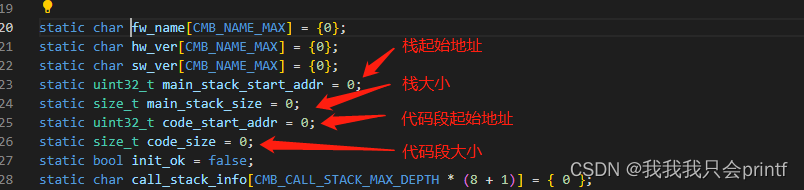
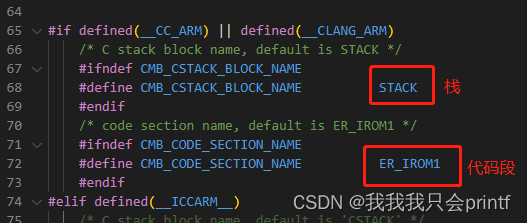
这里你需要知道一些MDK的知识。在MDK中,使用 AREA 关键字创建的数据段,通常在段名后加$$Base表示起始地址,加$$Limit表示结束地址,比如这里的STACK:

以及:


所以这里的这些宏定义起始就是为了取得其中两个段:
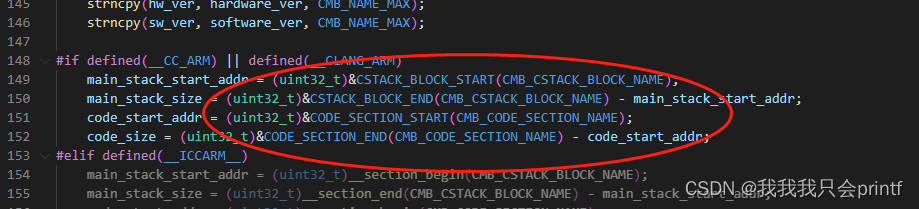
由最开始的解析我们知道,这里查找函数调用的思路就是从栈区找到属于代码段范围的地址。这也就是为什么我们一开始要知道栈区范围和代码段范围。初始化就这么简单就完成了,主要工作都在错误中断中:
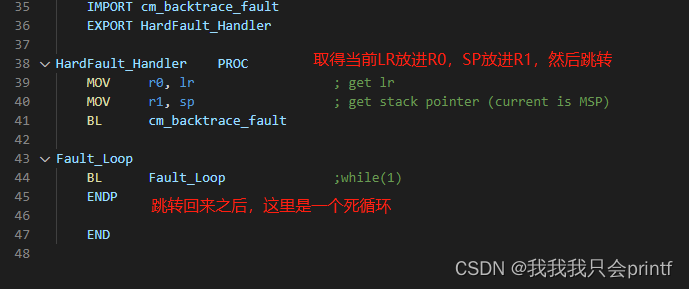
这里就是我上一章讲到的函数调用规则,当汇编调用C函数时,需要遵守这个规则。
现在进入到关键函数cm_backtrace_fault里:
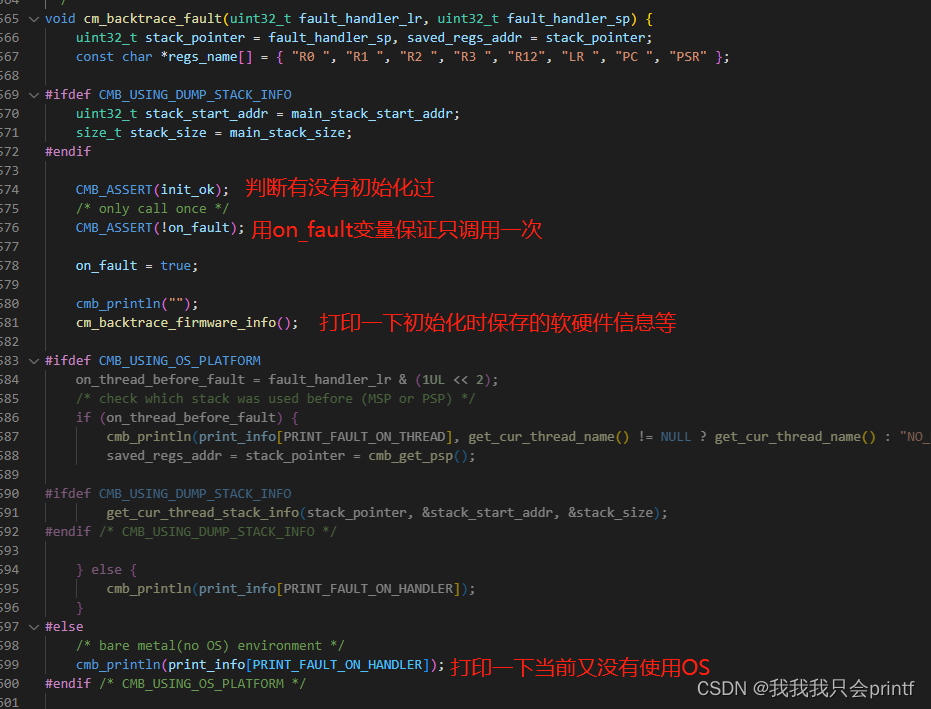
上述代码都是一些简单的判断与打印,不再详细展开, 看一下下面的打印栈区:
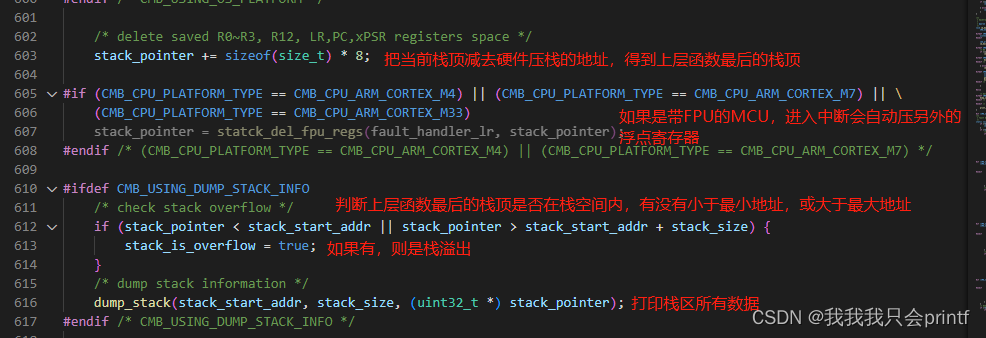
这里如果有堆栈溢出,且上层函数栈顶已经超过栈区最大地址,那什么也不会打印,具体打印数据逻辑如下:
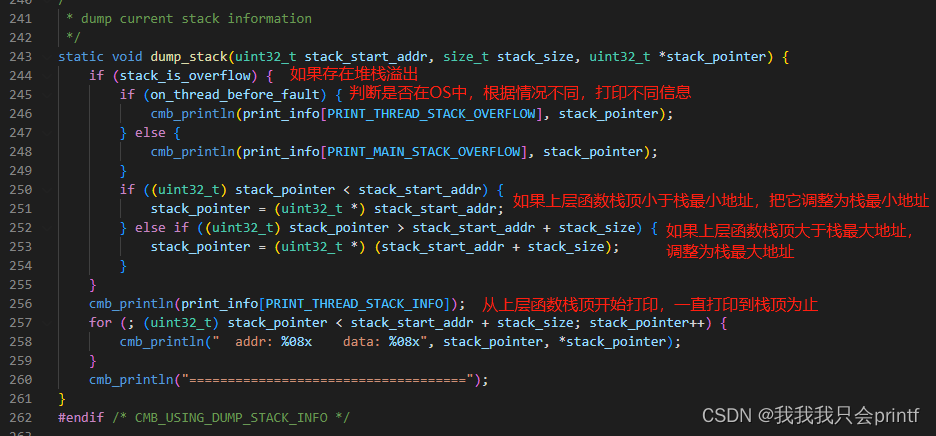
这里的相关打印,我再贴一下:
这和前文中原理分析相关内容,可以一一对应着去看。 下面则是打印的硬件压栈的那些寄存器数据:
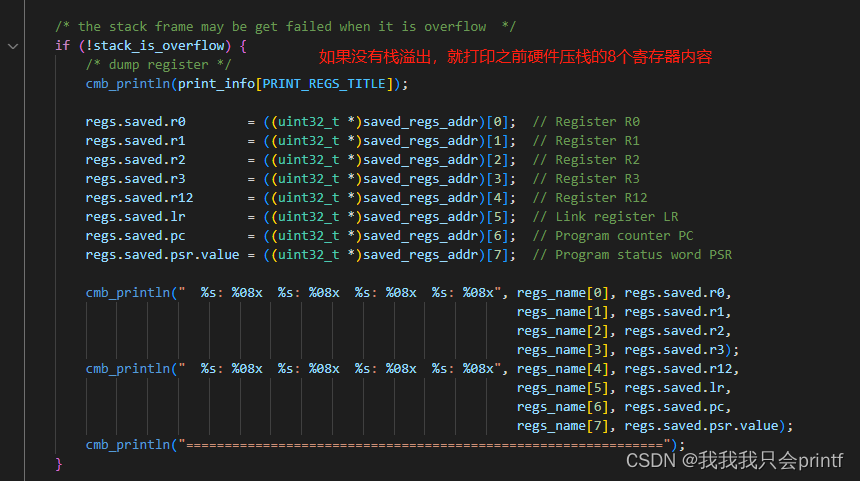
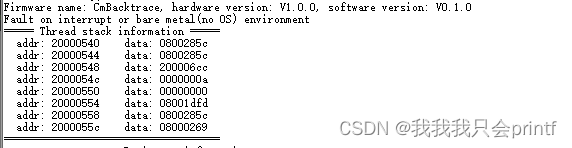
实际串口打印如下:
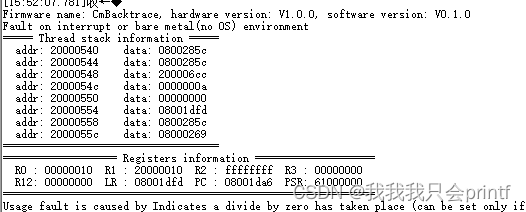
接下去就是我说的,通过查找寄存器对应的每个位,来判断当前故障的类型:
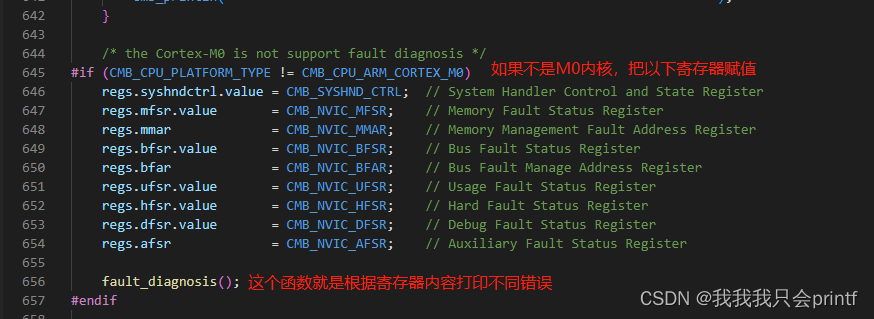
具体不再分析,想要知道细节的可以查看《Cortex-M3权威指南》表D.17之后的几个表。
最关键的函数留在了最后:
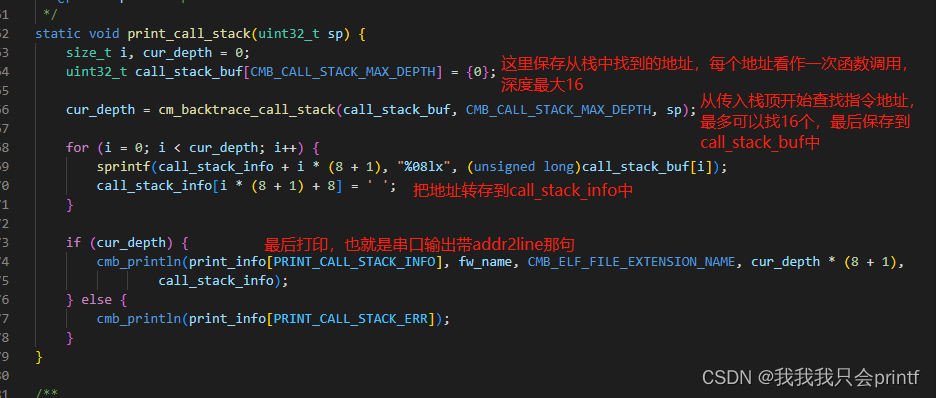
我们最后打印的就是:

所以关键在函数cm_backtrace_call_stack中:

在没有堆栈溢出的情况下,buffer里面会先保存两个值,一个是执行错误代码时的PC,在这个demo中是0x08001da6,然后又保存了执行错误代码时的LR-1,在这里是:0x08001dfd-1=0x08001dfc。
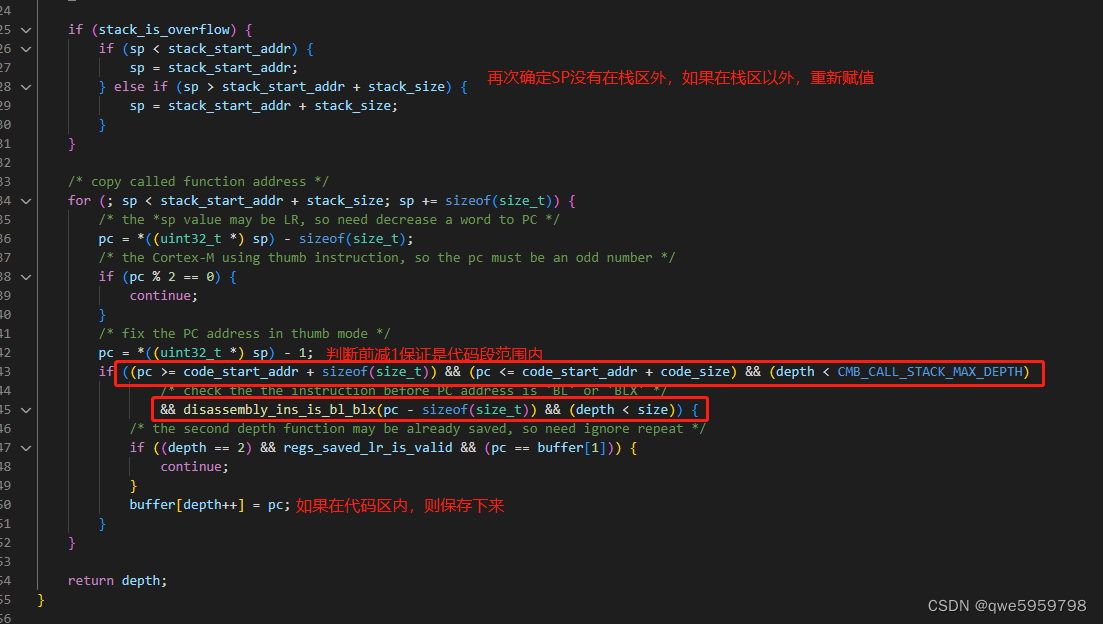
最后就是循环检测栈区,然后把符合的保存下来。