前沿系列--Transform架构[架构分析+代码实现]
文章目录
- 前言
- 总体架构
- 总体
- 任务使用
- 输入部分
- Embedding
- Position Encoding
- why
- 实现
- 注意部分
- 注意力机制/自注意力
- 掩码
- 作用
- 如何工作
- 形状解释
- 完整实现
- 多头注意力实现
- Norm处理
- FeedForward 以及连接
- 编码器
- 解码器
- 中间层
- 组装
- 输出层
- 模型组装
- 总结
前言
Transform这玩意的大名我想就不用我多说了。那么我们今天要做的就是对Transform架构进行了解,并且使用Pytorch进行一个编写实现。(其实这边博文的话很早之前就差不多写好了,但是话我本人喜欢做一个系列就一直没发布)由于描述的是一种架构,因此好消息是,对于新的理论部分没有啥要求。但是坏消息是,需要一定的前期知识储备。我们这边还是拿到NLP任务来进行展开,虽然Transform这个玩意作为一个架构不仅仅在NLP领域进行应用在CV领域等等也在用,但是一开始的来源还是这个NLP这边来的,一条时间线可以注意一下就是2017提出了Transform,2018 Bert出来了,2020 GPT3都出来了。最近ChatGPT都杀疯了。只能说时代变化太快,从大二入坑差不多一年了,还在水里爬。OK,废话不多少我们开始吧,那么在开始之前的话,我们期望你已经阅读了这篇博文:还在调API写所谓的AI“女友”,唠了唠了,教你基于python咱们“new”一个(深度学习) 因为会有一些奇怪的比喻来自这里,当然如果对应Seq2Seq有一定了解或者做过类似的任务的话,那么welcome here!
总体架构
总体
首先Transform的总体架构的话其实非常清晰明了
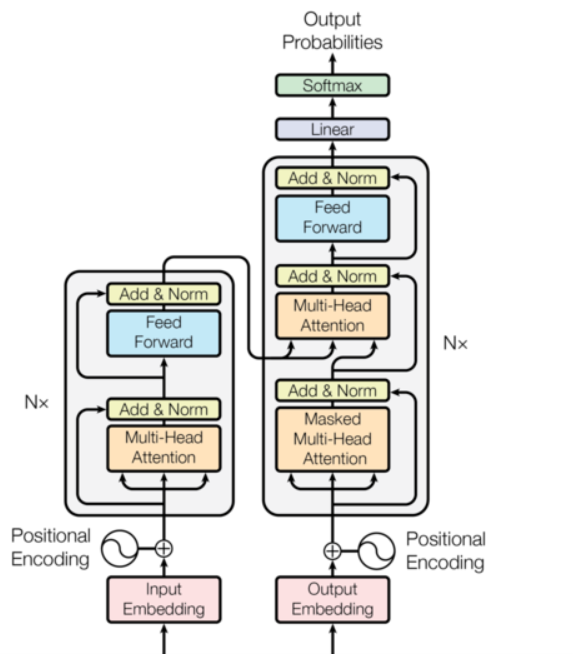
整个Transform架构的话其实和我们的Seq2Seq是类似的,都是通过Encoder到Decoder最后输出一组概率假设我们还是文本的一个生成任务的话,例如AI机器人,语言翻译,再或者说是从一个信号序列到另一个信号序列的转变。不过里面对于传入的参数的处理是不太一样的。同时相对我们原先构建的基于GRU搭建的SEQ2SEQ网络来说,其实实现的话会更简单一点,在原先最大的挑战在于对各个输出,输入维度的一个判断和编写,难点在于对循环神经网络的理解,因为调试的坑都在这边,也就是Decoder部分。但是在今天的Transform当中,会友好很多,难点在注意力机制的编写部分以及对它的一个理解。
任务使用
OK,那么我们现在对Transform进行了一个简单的预览,那么现在我们来看看我们如何使用Transform架构,如何使用这个模型。我们那个闲聊的机器人的来说吧,我们原来是这样的:

我们使用了两个循环神经网络来充当编码器,解码器,同时由于我们在解码的过程中需要逆向过程来一个词一个词的去生成句子,因此我们还需要手写decoder的一个循环过程,然后就是对里面参数的疯狂调整,最后在转化为一组概率,假设输入的句子是1x10并且假设有100种词,也就是不同的词语+标点有100个,那么最后我们得到的玩意是1x10x100的一个概率矩阵。然后我们通过概率矩阵去生成一个句子。这个是我们原来的一个流程。
那么在使用Transform的话,有什么区别呢?答,总体上来说其实区别不大。我们其实只是把Seq2Seq给换成了transform,更加准确一点其实是,我们把原来GRU给换成了transform当中的编码器和解码器。
也就是这两个家伙:
再形象一点就是,我们把GRU或者LSTM这种循环神经网络给换成了这种带有注意力机制的编解码器。并且我们对于编码器和解码器当中相互交融的位置也不太一样。那么这个时候我们可以引出我们本文当中的第一个问题了,那就是说,为什么我们可以使用到这个东西,来代替RNN结构。
输入部分
Embedding
OK,现在我们带着第一个问题来看到我们的输入部分:
首先我们可以看到一开始对于输入需要先进行Embedding操作,这个操作的话,是我们常规的一个操作,那么紧接着还有一个PositionEncoding的一个操作。那么对于Embedding的操作我们可以理解,目的就是为了能够把一个文本,例如一个句子10个词语构成,那么就变成10xembedding_dim的一个向量。具体的代码也简单是这样的:
class Embeddings(nn.Module):
def __init__(self,dim,vocab):
super(Embeddings,self).__init__()
self.em = nn.Embedding(vocab,dim)
self.dim = dim
def forward(self,x):
return self.em(x)*math.sqrt(self.dim)
Position Encoding
why
那么PositionEncoding是什么东西呢?OK,这里我们先来回顾一下如果我们使用RNN的话我们有什么特点,或者说我们原来为什么要使用GRU或者LSTM这种RNN结构呢?是因为,词语的位置之间是有关系的对吧。词和词之间不是独立的,而存在一种关系,例如“我爱你”和“你爱我”这是不同意思,前者可能是你作为舔狗,后者可能是别舔你。因此我们采用了RNN这种结构,主要是因为词语之间的一种联系。那么问题来了一定只有一种解决方案不?显然不是,如果我们有一种方法我们可以直接把词语之间的一种位置关系也直接表示出来的话,那么理论上来说我们可以替代到刚刚的RNN的效果。
那么PositionEncodeing显然看名字就知道做的就是这种事情。
实现
OK,我们这边先来看到是怎么实现的:
"""
负责实现对句子中每一个位置信息进行一个编码
编码之后的维度是[seq_len,dim]
"""
class PostitionEncoding(nn.Module):
def __init__(self,dim,dropout,max_len=5000):
super(PostitionEncoding,self).__init__()
"""
dropout让部分神经元失去作用(其实就是让某些
神经元的梯度消失,让输入中的X矩阵部分为0
"""
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len,dim)
#初始化绝对位置矩阵
postition = torch.arange(0,max_len).unsqueeze(-1)
#定义一个变幻矩阵
div_matrix = torch.exp(torch.arange(0,dim,2)*-(math.log(10000)/dim))
#进行奇数偶数位置的分别赋值
pe[:,0::2] = torch.sin(postition*div_matrix)
pe[:,1::2] = torch.cos(postition*div_matrix)
pe = pe.unsqueeze(0)
#pe,不参与模型的梯度运算,因此需要将pe注册为buffer
self.register_buffer('pe',pe)
def forward(self,x):
"""
:param x: embedding 后的x
:return:
"""
x = x+Variable(self.pe[:,:x.size(1)],requires_grad=False)
return self.dropout(x)
这部分的实现是这样的:
- 使用到一个位置信息矩阵pe,这个矩阵一开始我们设置的足够大,并且作为一个定量(不参与梯度计算)
- 定义一个变幻矩阵,目的是为了对pe的维度进行变幻
- 确定句子当中的词序,因为我们输入的东西是batch_size,seq_len,dim的一个句子,词本身在句子中就是有序的因此:postition = torch.arange(0,max_len).unsqueeze(-1) 就是词的一个序号(在句子中)
- 此时变幻矩阵和position矩阵进行运算,然后赋值给到pe,这个位置信息矩阵。
- 将位置信息和原来的embedding后的信息进行累加处理,让数据具备位置信息
这里的话可能第一个魔幻的地方来了,为什么这样处理之后就具备了位置信息。这里问题的话其实是整个神经网络算法的魔幻之处,我们这样处理的信息确实和位置有关系,但是具体是什么关系我们是不知道的,这个只能改到神经网络自己去“学习”表示,也就是常说的解释能力比较差的一种情况,只是说我们期望是这种效果,并且实验的表现上这种解释行得通。
那么在这里的话还需要注意的是这个,我们有两个地方是有这样的处理的:
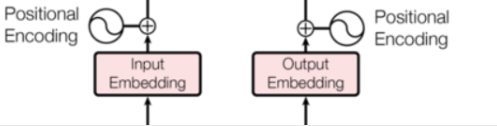
注意部分
之后的话我们来看到这个注意了机制部分:
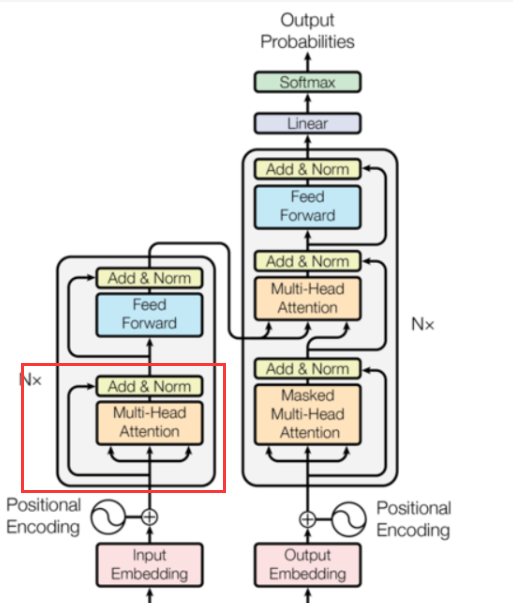
这个玩意看架构图也知道是整个transform当中比较重要的一个地方了,基本上一个架构全是注意力机制,然后疯狂传递。
注意力机制/自注意力
OK,现在我们来看到这个注意力机制。其实这个注意了机制的话,不要想得很复杂,它里面其实就三个东西:Query,Key,Value 然后通过特殊的计算之后得到一种权重,然后和我们输入的X进行一个计算,让X当中的某些值放大或者缩小,从而影响到我们神经网络里面的权重,因为我们现有的神经网络结构,都是对参数W进行一个计算求导的,影响W的是我们X的一个值。可以这样理解我们的注意力机制就是,X影响到了部分W,然后W再影响道下一个batch的X,然后在反过来影响到W,W不再是混乱的,W的缩放呈现处理一种分布所就是所谓的一种注意力的表现。反正大概是这种意思吧,我们不太需要关心这个。
那么我们先直接来看到这个公式还有架构吧:
首先它的计算公式是这样的:
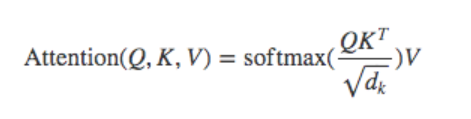
有四个变量,Q,K,V还有Dk。这几个是啥我们待会再来说,那么在我们的网络结构里面是这样的:
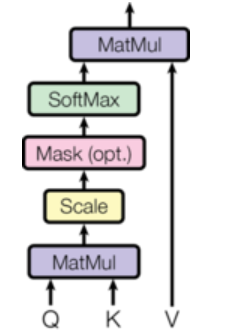
这个时候我们在来解释一下这个Q,K,V是啥。
Q:query,假设我们在做一个文本的特征提取,假设给一个文本,叫你提取出里面的关键词,那么Query就是我们输入的文本
K: key,是我们输入的一些关键信息。
V: value,是网络生成的
那么这块的话我们可以发现就是说Query和Key应该是知道的,Value是我们最终期望得到的。假设我们在做一个语文作业。我们的期望是AI可以做出来,于是我们输入Query,也就是题目,之后我们有一个参考答案Key,或者说是参考提示。现在在学习的过程中,我们是不知道怎么做的,最好的方式是找几个例题去做一下,于是我们拿到Query和Key,自己在生成Value也就是解题,然后在去对一下大概的答案,看看自己有没有get到题目的关键点。那么类比一下,get题目的关键点,不是题目的关键信息嘛,不就是文本中的主要要点呗,也就是关键特征呗,那么这个不就是注意力机制的目的呗。
这个的话,我们先直接看到代码:
@staticmethod
def attention(query,key,value,mask=None,dropout=None):
"""
:param query:
:param key:
:param value:
:param mask: 掩码
:param dropout: 传入dropout对象
:return:
"""
"""
当Q=K=V时,此时attention就是传说中的self-attention
"""
#这里的dim其实就是embedding里面的dim
dim = query.siez(-1)
#参照计算公式进行计算
sorces = torch.matmul(query,key.transpose(-2,-1)/math.sqrt(dim))
if(mask is not None):
"""
Q,K,V-->[batch_size,seq_len,embedding_dim]
与mask里面的0进行对应,如果是0,那么替换为很小的数字
在sorces的对应位置上
[seq_len,seq_len]
"""
sorces = sorces.masked_fill(mask==0,-1e9)
p_attn = F.softmax(sorces,dim=-1)
if(dropout is not None):
p_attn = dropout(p_attn)
#完成乘法,并反馈query的attention
return torch.matmul(p_attn,value),p_attn
(mask是啥,先不管)OK,现在我们知道了注意力机制,并且我们知道就是说,我们的Key和Value理论上来说应该要相等,或者尽可能相等,换一句话说,我们期望是输入的Key和我们的Value能够相等。那么自注意力机制是啥呢,其实很简单就是Q=K=V,啥玩意呢,就是Key按道理假设是按照刚刚的例子的话,Key是提示,是答案,那么如果没有给答案不就自己做了呗,答案就是题目也就是说没给提示,要自己做。大概就这样理解吧。
掩码
作用
之后的话,我们可以发现在代码当中还有mask,这种东西,那么这个是啥呢。
掩代表遮掩,码就是我们张量中的数值,它的尺寸不定,里面一般只有1和0的元素,代表位置被遮掩或者不被遮掩,至于是0位置被遮掩还是1位置被遮掩可以自定义,因此它的作用就是让另外一个张量中的一些数值被遮掩,也可以说被替换,它的表现形式是一个张量。
在transformer中,
掩码张量的主要作用在应用attention时,有一些生成的attention张量中的值计算有可能已知了未来信息而得到的,未来信息被看到是因为训练时会把整个输出结果都一次性进行Embedding,但是理论上解码器的的输出却不是一次就能产生最终结果的,而是一次次通过上一次结果综合得出的,因此,未来的信息可能被提前利用. 所以,我们会进行遮掩。
这个看起来比较抽象,我们直接来看到它的生成的代码怎么来的:
@staticmethod
def subsequent_mask(size):
attn_shape = (1,size,size)
subsequent_mask = np.triu(np.ones(attn_shape),k=1).astype('uint8')
return torch.from_numpy(1-subsequent_mask)
这个东西呢,就是用来生成掩码的东西,那么运行完之后的效果是啥呢,假设我们生成的是4x4的一个掩码,那么效果就是这样的:

其他的地方是0。那么这个玩意有作用,或者为啥长这个样子呢。
什么叫做未来的张量呢?未来的信息?
我们这里的话,我们来回到我们用GRU来生成句子的时候是怎么做的:
原来在生成句子的时候,我们是一步一步去生成的对吧,也就是说,当前的+上一个生成的词语来进行推导生成。也就是这样一步一步来生成的:
也就是说在生成当前的词语的时候,我们不可能拿到后面的词语的信息来进行生成。
但是现在是什么情况。现在我们没有这样的循环结构。我们是直接一个句子,一个句子所有的特征都给出来了,也就是我们是直接一个张量大小为[batch_size,seq_len,embedding_dim]的玩意过来去生成这样的词语的。但是不可否认的是在一次一次运算的过程中,我们是期望词语也是一个一个生成的,因为这样才合理啊,你不可能知道你还没有说的话吧,或者还没有想到的话吧,这个肯定是有次序的。那么掩码的作用此时就不言而喻了,为了这种次序性。换一句话说掩码用来模拟RNN结构的次序性质。至此,用RNN结构的对于词语的位置特征,词语的次序特征都进行了简要代替。
如何工作
OK,现在我们再来看到掩码大概是如何工作的,这个时候我们再回到attention的代码当中:
if(mask is not None):
"""
Q,K,V-->[batch_size,seq_len,embedding_dim]
与mask里面的0进行对应,如果是0,那么替换为很小的数字
在sorces的对应位置上
[seq_len,seq_len]
"""
sorces = sorces.masked_fill(mask==0,-1e9)
其实答案已经在注释了给出来了,QKV的维度正如咱们的这个注释所说,当进行运算之后的话,source的维度变成了[seq_len,seq_len],此时按照下三角矩阵,我们把mask当中为0的用很小的值来替换,这样的话,对应位置的信息就很小了。之后在进行矩阵运算
return torch.matmul(p_attn,value),p_attn
还原维度并且得到处理之后的X,和attn的一个权重。
形状解释
那么这个时候的话,我们也可以来解释另一个问题就是为什么,是有一个偏移的。我们假设只有一个句子进入,也就是假设现在都是二维的张量进入网络,之后我们进行运算之后我们的source大概应该是这样的:

假设这个现在是我们的source矩阵,假设恰好source运算完毕之后,下三角也是1,上三角是别的数值,但是和mask运算之后应该是这样的。它的大小是seq_len x seq_len。或者是max_len x max_len。
它的话这样理解,纵坐标是代表我们知道的词,就是输入,横坐标要的是我们要生成或者转换的信息,因为神经网络就是对信息不断转换提取码,对那个feature对吧。此时生成第一个的时候,第一个肯定是要已知的。生成第二个的时候,3,4未来的就看不到了,大概就是下图的效果:

这块的话其实也是模拟那种RNN按照次序提取信息的过程,后面的信息是逐步看到的。
完整实现
OK,现在我们来看到一个实现。这里的话我把这个玩意封装到了一个工具类当中,因为后面会使用到:
class Utils(object):
def __init__(self):
pass
@staticmethod
def subsequent_mask(size):
attn_shape = (1,size,size)
subsequent_mask = np.triu(np.ones(attn_shape),k=1).astype('uint8')
return torch.from_numpy(1-subsequent_mask)
@staticmethod
def attention(query,key,value,mask=None,dropout=None):
"""
:param query:
:param key:
:param value:
:param mask: 掩码
:param dropout: 传入dropout对象
:return:
"""
"""
当Q=K=V时,此时attention就是传说中的self-attention
"""
#这里的dim其实就是embedding里面的dim
dim = query.siez(-1)
#参照计算公式进行计算
sorces = torch.matmul(query,key.transpose(-2,-1)/math.sqrt(dim))
if(mask is not None):
"""
Q,K,V-->[batch_size,seq_len,embedding_dim]
与mask里面的0进行对应,如果是0,那么替换为很小的数字
在sorces的对应位置上
[seq_len,seq_len]
"""
sorces = sorces.masked_fill(mask==0,-1e9)
p_attn = F.softmax(sorces,dim=-1)
if(dropout is not None):
p_attn = dropout(p_attn)
#完成乘法,并反馈query的attention
return torch.matmul(p_attn,value),p_attn
@staticmethod
def clone(module,N):
"""
:param module: 目标网络
:param N: 克隆个数
:return:
"""
return nn.ModuleList(
[copy.deepcopy(module) for _ in range(N)]
)
多头注意力实现
之后的话就是我们多头注意力实现了,也就是这个破玩意:
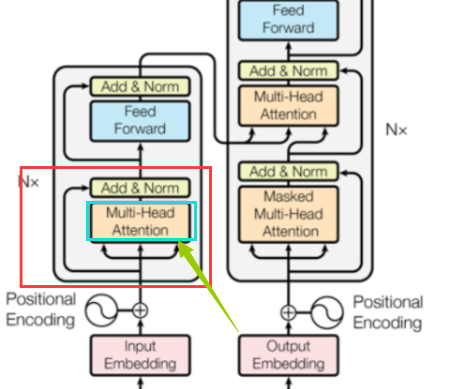
其实啥是多头注意力呢,其实很好理解,就是在基本注意力的基础上,我们把一个数据拆分为不同维度,对不同维度的数据进行分别注意力机制,然后做合并即可。
也就是说我们输入的数据是,一开始我们通过embedding和position encodinh之后,我们的数据应该是[batch_size,seq_len,embedding_dim],假设我们划分8个头,那么其实就是把这个数据划分为[batch_size,seq_len,head,embedding_dim//head],然后最后两个维度进入注意力机制呗。
代码实现是这样的:
class MultiHeadedAttention(nn.Module):
def __init__(self,head,dim,drop=0.3):
"""
:param head: 多少个头(其实就是dim划分多少份)
:param dim:
:param drop:
"""
super(MultiHeadedAttention,self).__init__()
assert dim%head==0,"head的数量设置不合理"
self.d_k = dim//head
self.head = head
self.dim = dim
self.liners = Utils.clone(nn.Linear(self.dim,self.dim),4)
self.attn = None
self.drop = nn.Dropout(drop)
def forward(self,query,key,value,mask=None):
if(mask is not None):
#扩充mask,因此此时加了一个头,张量多了一个维度
mask = mask.unsqueeze(1)
batch_size = query.size(0)
#进行计算,这个-1,其实是句子的每一个词
query,key,value = [
model(x).view(batch_size,-1,self.head,self.d_k).transpose(1,2)
for model,x in zip(self.liners,(query,key,value))
]
x,self.attn = Utils.attention(query,key,value,dropout=self.drop)
#此时做合并
x = x.transpose(1,2).contiguous().view(
batch_size,-1,self.dim
)
return self.liners[-1](x)
Norm处理
之后的话我们看到我们的结构还有这个:
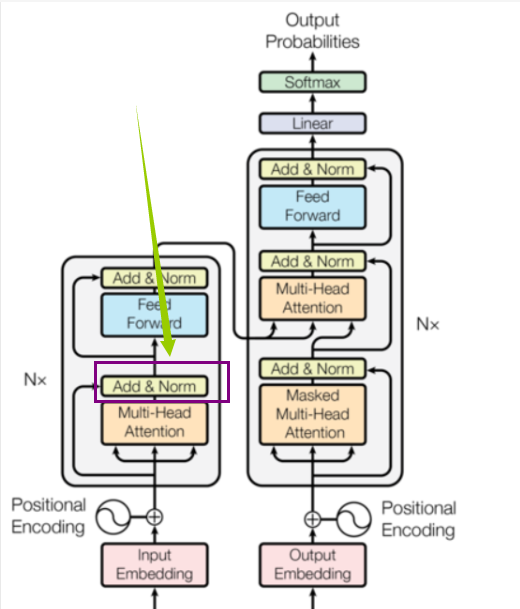
那么这个的话我们要实现一:
class LayerNorm(nn.Module):
def __init__(self,dim,eps=1e-6):
"""
:param dim: embedding_dim
:param eps: 放置除以0
"""
super(LayerNorm,self).__init__()
self.eps = eps
self.a = nn.Parameter(torch.ones(dim))
self.b = nn.Parameter(torch.zeros(dim))
def forward(self,x):
mean = x.mean(-1,keepdim=True)
std = x.std(-1,keepdim=True)
return self.a*(x-mean)/(std+self.eps)+self.b
那么到这里的话,我们的注意力部分其实就差不多了。
FeedForward 以及连接
之后我们再看到这个:
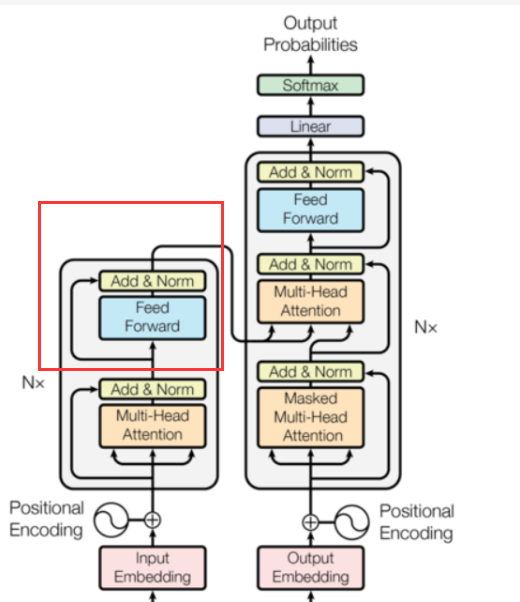
我们要把这个也实现了,然后我们就可以组装我们的编码器了。
这个其实好办:
这个是我们的FeedForward
class PositionwiseFeedForward(nn.Module):
def __init__(self,dim,d_h,drop=0.3):
super(PositionwiseFeedForward,self).__init__()
self.l1 = nn.Linear(dim,d_h)
self.l2 = nn.Linear(d_h,dim)
self.dropout = nn.Dropout(drop)
def forward(self,x):
x = F.leaky_relu(self.l1(x))
return self.l2(self.dropout(x))
之后是我们的连接部分,就是这些乱七八糟的线:
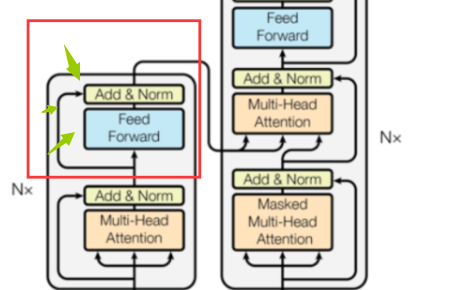
class SubLayerConnection(nn.Module):
def __init__(self,dim,dropout=0.3):
super(SubLayerConnection,self).__init__()
self.norm = LayerNorm(dim)
self.dropout = nn.Dropout(dropout)
def forward(self,x,sublayer):
return x+self.dropout(sublayer(self.norm(x)))
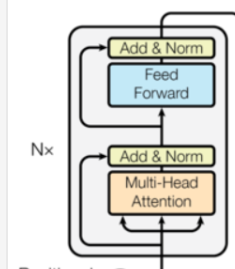
编码器
OK,现在我们基本的编码里面需要的组件就做好了,我们现在组装一下:
class Encoder(nn.Module):
def __init__(self,layer,N):
"""
:param layer: 多少层的编码器
:param N: 多少个编码器
"""
super(Encoder,self).__init__()
self.layers = Utils.clone(layer,N)
self.norm = LayerNorm(layer.dim)
def forward(self,x,mask):
for layer in self.layers:
x = layer(x,mask)
return self.norm(x)
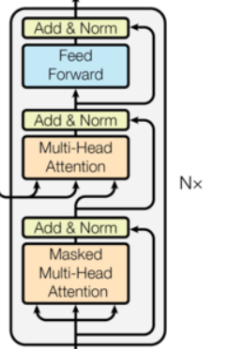
解码器
之后的话是我们的解码器,这个东西和我们的编码器其实有点类似,只是中间的输入。
中间层
这里我们先定义一下中间层,因为这个东西需要接受我们编码器传递过来的值:
class DecoderLayer(nn.Module):
def __init__(self,dim,self_attn,src_attn,feed_forward,dropout):
"""
:param dim:
:param self_attn: 自注意力机制 Q=K=V
:param src_attn: 常规注意力机制 Q!=K=V
:param feed_forward:
:param dropout:
"""
super(DecoderLayer,self).__init__()
self.dim = dim
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = Utils.clone(SubLayerConnection(dim,dropout),3)
def forward(self,x,memory,source_mask,target_mask):
"""
:param x: 上一层输入
:param memory: 编码层的语义(编码器输出)
:param source_mask: 数据源的掩码
:param target_mask: 目标数据的掩码
:return:
"""
m = memory
x = self.sublayer[0](x,lambda x:self.self_attn(x,x,x,target_mask))
x = self.sublayer[1](x,lambda x:self.src_attn(x,m,m,source_mask))
#最后一个连接结构
return self.sublayer[2](x,self.feed_forward)
组装
之后的话,我们在组装一下:
class Decoder(nn.Module):
def __init__(self,layer,N):
super(Decoder,self).__init__()
self.layers = Utils.clone(layer,N)
self.norm = LayerNorm(layer.dim)
def forward(self,x,memery,source_mask,target_mask):
for layer in self.layers:
x = layer(x,memery,source_mask,target_mask)
return self.norm(x)
输出层
最后是我们的输出层,也就是这个:
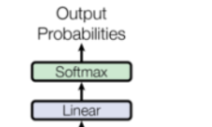
这个的话,我们叫它生成器,因为我们最后确实是需要它生成我们的句子,最后输出的也是概率嘛。
class Generator(nn.Module):
"""
没错最后也是做一个概率预测,选择最大的那一个,然后由词语组成句子输出
"""
def __init__(self,dim,vocab_size):
super(Generator,self).__init__()
self.l = nn.Linear(dim,vocab_size)
def forward(self,x):
return F.log_softmax(self.l(x),dim=-1)
至于生成句子的处理手段,这个咱们在那个开头AI小姐姐的博文说了,我们还有一种方式优化。
模型组装
最后来到我们对于模型部分的组装。没错就是这个大图:
这个的话就简单了,因为我们已经组装好了各个组件。
class Model(object):
@staticmethod
def make_model(source_vocab,target_vocab,N=6,
dim=512,d_ff=2048,head=8,max_len=5000,
dropout=0.30):
"""
:param source_vocab: 词汇数量
:param target_vocab: 词汇数量
:param N: 编码器/解码器多少个层
:param dim: embedding_dim
:param d_ff: 线性层多少个隐藏节点
:param head: 多头注意力机制多少个头
:param max_len: 句子的最大长度
:param dropout:
:return:
"""
co = copy.deepcopy
attn = MultiHeadedAttention(head,dim)
pf = PositionwiseFeedForward(dim,d_ff,dropout)
position = PostitionEncoding(dim,dropout,max_len)
model = EncoderDecoder(
Encoder(EncoderLayer(dim,co(attn),co(pf),dropout),N),
Decoder(DecoderLayer(dim,co(attn),co(attn),co(pf),dropout),N),
nn.Sequential(Embeddings(dim,source_vocab),co(position)),
nn.Sequential(Embeddings(dim,target_vocab),co(position)),
Generator(dim,target_vocab)
)
return model
到此我们整个模型就构建完成了,然后使用的话还是老规矩,当做Seq2Seq即可。当然同样的,作为一个饱受考验的模型,这个也是有实现好的第三方库的,没错不需要自己手写。
总结
okey~大概这个其实就是transform架构吧,总的来说,按照我的解读其实就是非常巧妙的对RNN能够带来的一些特征进行融合,并且效果还很好。当然整个架构给我的感觉其实就是“堆料,期望”。
堆料是啥意思呢:就是用了很多处理方案呗。
期望是啥意思,就是这些方案,解释性更多是用期望来表示。举个例子:
before:
我认为A和B之间还有一种关系我需要知道–>建立模型—>做实验,不断推导证明–>找出A和B之前确切的关系以及处理方案–>得到结论(可解释性的步骤+完整的数学模型+推导证明)
now:
我认为A和B之间存在一种关系我需要知道–>将A和B的数据进行处理连接整合(很粗略的模型)—>NN---->Expect could NN find some Relationships -->实验后效果好像达到了预期—>得到结论(这样做期望是这样实际上目前这样解释正确)
只是挑款没啥意思。