基于Python+Echarts+Pandas 搭建一套图书分析大屏展示系统(附源码)
今天给大家分享的是基于 Flask、Echarts、Pandas 等实现的图书分析大屏展示系统。
项目亮点
-
采用 pandas、numpy 进行数据分析
-
基于 snownlp、jieba 进行情感分析
-
后端接口选用 RESTful 风格,构建 Swagger 文档
-
基于 Flask、Echarts 构建 Web 服务,采取前后端分离的开发模式
-
结合 redis 提高访问速度
-
采用 docker-compose 构建项目
-
使用 gitee、github 进行代码版本管理
-
前端采用 Promise、async、await 进行异步请求
在线演示地址
-
主页:https://python.sinwer.cn/
-
数据接口:https://python.sinwer.cn/v1/
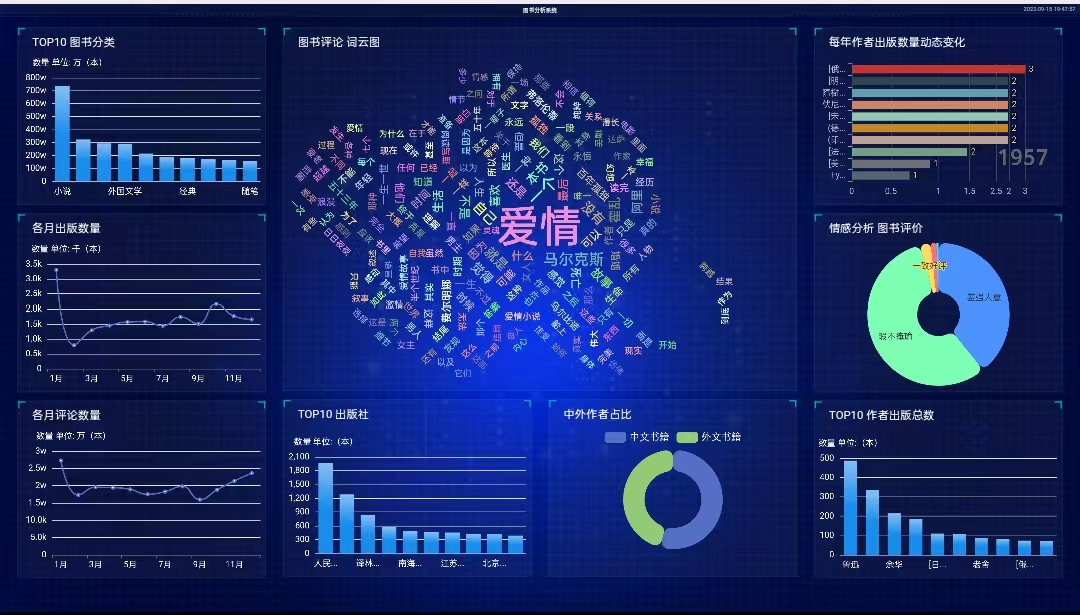
效果截图
图片太大,不清晰。
项目本地启动
docker-compose up
项目本地访问
localhost:8080
源码

本文由技术群粉丝投稿分享,项目源码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
方式①、添加微信号:dkl88191,备注:来自CSDN +研究方向
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:图书分析大屏
部分代码展示
wsgi.py
import sys
WIN = sys.platform.startswith('win')
from gevent import monkey
if WIN:
monkey.patch_all(contextvars=False)
else:
monkey.patch_all()
# gc.disable()
# gc.set_debug(gc.DEBUG_LEAK)
import os
from dotenv import load_dotenv, find_dotenv
from werkzeug.middleware.proxy_fix import ProxyFix
from BookAnalysis import create_app
load_dotenv(find_dotenv())
app = create_app(os.environ.get('FLASK_ENV', 'production'))
app.wsgi_app = ProxyFix(app.wsgi_app)
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Software: PyCharm
import jieba
import pandas as pd
from BookAnalysis.analysis.base import Base
class Analysis(Base):
def __init__(self, filename=None):
if filename is None:
filename = 'bookComment.csv'
super().__init__(filename)
def getData(self):
# 选取评论数量最多的图书
url = self.df['url'].value_counts().idxmax()
df: pd.DataFrame = self.df.loc[self.df['url'] == url]
# print(df.head())
# print(df.shape)
# print(df.columns)
comments = df['comment'].astype(str).tolist()
counts = {}
# 统计评论
for comment in comments:
words = jieba.cut(comment, use_paddle=True)
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
# _ans = []
# for key, value in counts.items():
# _ans.append({
# "name": key,
# "value": value
# })
# print(counts)
# print(_ans)
# 按照 value 进行排序 dict
counts = sorted(counts.items(), key=lambda item: item[1], reverse=True)
_ans = []
for key, value in counts:
# 获取前 200 个分词,减少网络传输压力
if len(_ans) > 200:
break
_ans.append({
"name": key,
"value": value
})
return _ans
if __name__ == '__main__':
print(Analysis().getData())