Pandas 详解
本文主要介绍python 数据分析模块 Pandas,并试图对其进行一个详尽的介绍。
通过阅读本文,你可以:
- 掌握 Anaconda 环境的安装及使用
- 了解什么是 Pandas
- 掌握 Series 对象基本操作
- 掌握 DataFrame 对象的基本操作
- 掌握缺值处理
- 掌握 Series 对象和 DataFrame 的拼接
- 掌握 merge 的使用
文章目录
- 前言
- 1 Pandas 开发环境搭建
- 1.1 Anaconda 下载和安装
- 2 Pandas 数据类型
- 2.1 Series 对象创建
- 2.2 DataFrame 对象创建
- 2.3 获取 Series 对象的值
- 2.4 获取 DataFrame 的值
- 1) 选择某一列/某几列
- 2) 选择连续的某几列
- 3) 选择某一行/某几行
- 4) 选择连续的某几行
- 5) 行列同时选择
- 2.5 Series 的方法
- 2.6 Series 的条件过滤
- 2.7 DataFrame 的条件过滤
- 3 处理缺失值
- 3.1 缺失值查看
- 3.2 缺失值删除
- 3.3 缺失值填充
- 4 拼接
- 5 merge 的使用
- 总结
前言
Pandas 是基于 Numpy 的一套数据分析工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas 提供了大量能使我们快速便捷地处理数据的函数和方法。它是使 Python 成为强大而高效的数据分析环境的重要因素之一。
1 Pandas 开发环境搭建
Pandas 是第三方程序库,所以在使用 Pandas 之前必须安装 Pandas 库。但是如果使用Anaconda Python 开发环境,那么 Pandas 已经集成到 Anaconda 环境中,不需要再安装。
1.1 Anaconda 下载和安装
Anaconda 已经自动的安装了Jupter Notebook 及其他工具,还有 python 中超过 180 个科学包及其依赖项。
Anaconda 的下载和安装可以参考: Anaconda下载及详细安装图文教程
Anaconda 安装好后,pandas也就一起被安装进来了。
2 Pandas 数据类型
Pandas 中两个重要的数据类型:Series 和 DataFrame。Series 表示数据列表,DataFrame表示二维数据集。
2.1 Series 对象创建
【示例 1】使用列表创建 Series 对象
import pandas as pd
data=pd.Series([4,3,5,6,1])
data

series 对象包装的是 numpy 中的一维数组,实际上是将一个一维数组与一个索引名称捆绑在一起了。
pandas 中两个重要的属性 values 和 index,values 是 Series 对象的原始数据。index 对应了 Series 对象的索引对象。
【示例 2】Series 对象中两个重要的属性 values 和 index
data.values
data.index

【示例 3】创建 Series 对象时候,指定 index 属性
data=pd.Series([5,4,6,3,1],index=['one','two','three','four','five'])
data

【示例 4】创建 Series 对象时候,使用 list 列表指定 index 属性
data=pd.Series([4,3,2,1],index=list('abcd'))
data

【示例 5】使用字典创建 Series 对象,默认将 key 作为 index 属性
population_dict={'bj':3000,'gz':1500,'sh':2800,'sz':1200}
population_series=pd.Series(population_dict)
population_series

【示例 6】使用字典创建 Series 对象,又指定了 index 属性值,如果 key 不存在,则值为 NaN
sub_series=pd.Series(population_dict,index=['bj','sh']) #如果存在取交集
sub_series

sub_series=pd.Series(population_dict,index=['bj','xa']) #如果不存在则值为 NaN
sub_series

【示例 7】标量与 index 属性创建 Series
data=pd.Series(10,index=[4,3,2,5])
data

2.2 DataFrame 对象创建
将两个 series 对象作为字典的值,就可以创建一个DataFrame 对象。
【示例 8】创建 DataFrame 对象
population_dict={'beijing':3000,'shanghai':1200,'guangzhou':1800}
area_dict={'beijing':300,'guangzhou':200,'shanghai':180}
import pandas as pd
population_series=pd.Series(population_dict)
area_series=pd.Series(area_dict)
citys=pd.DataFrame({'area':area_series,'population':population_series})
citys
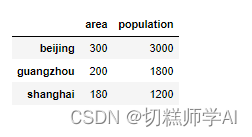
【示例 9】查看 DataFrame 对象的 values、index 和 columns 属性
citys.index

citys.values

citys.values

【示例 10】使用列表创建 DataFrame 对象
population_dict={'beijing':3000,'shanghai':1200,'guangzhou':1800}
area_dict={'beijing':300,'shanghai':180,'guangzhou':200}
data=pd.DataFrame([population_dict,area_dict])
print(data) #将‘beijing’ ‘shanghai’ ‘guangzhou’ 作为表头

【示例 11】创建 DataFrame 对象,指定 index 属性
population_dict={'beijing':3000,'guangzhou':1800,'shanghai':1200}
area_dict={'beijing':300,'shanghai':180,'guangzhou':200}
data=pd.DataFrame([area_dict,population_dict],index=['area','population'])
data
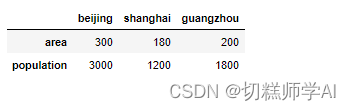
【示例 12】创建 DataFrame 对象,指定列索引 columns
population_series=pd.Series(population_dict)
pd.DataFrame(population_series,columns=['population'])
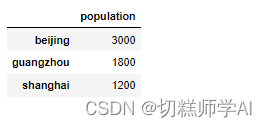
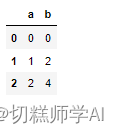
【示例 13】使用列表创建 Dataframe 对象
pd.DataFrame([{'a':i,'b':i*2} for i in range(3)])
【示例 14】使用一个二维数组并指定 columns 和 index 创建 DataFrame 对象
import numpy as np
pd.DataFrame(np.random.randint(0,10,(3,2)),columns=list('ab'),index=list('efg'))

2.3 获取 Series 对象的值
【示例 15】Series 对象的切片、索引
import numpy as np
import pandas as pd
data=pd.Series([4,3,25,2,3],index=list('abcde'))
display('根据 key 获取: ',data['a'])
display('切片获取: ',data['a':'d'])
display('索引获取: ',data[1])
display('索引切片: ',data[2:4])

可以看出 Series 与 ndarray 数组都可以通过索引访问元素,Series 对象的索引分为位置索引和标签索引。不同之处,标签索引进行切片时候是左闭右闭,而位置索引是左闭右开。
【示例 16】位置索引与标签索引相同的问题
data=pd.Series([5,6,7,8],index=[1,2,3,4])
data[1]

位置索引与标签索引有相同值 1, 这时候 data[1]就不知道是按哪个
来获取, 此时要使用 loc、 iloc。 其中 loc 表示的是标签索引, iloc 表示的是位置索引。
【示例 17】Series 对象中 loc 与 iloc 的使用
data=pd.Series([5,3,2,5,9],index=[1,2,3,4,5])
data

data.loc[1]

data.iloc[1]

2.4 获取 DataFrame 的值
1) 选择某一列/某几列
DataFrame 对象非常容易获取数据集中指定列的数据。只需要在表 df 后面的括号中指明要选择的列名即
可。如果要获取一列,则只需要传入一个列名;如果是同时选择多列,则传入多个列名即可,多个列名用一个 list 存放。
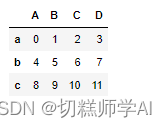
【示例 18】创建 DataFrame 对象
import numpy as np
import pandas as pd
data=pd.DataFrame(np.arange(12).reshape(3,4),index=list('abc'),columns=list('ABCD'))
data
【示例 19】获取 DataFrame 对象中某一列/某几列
print('获取‘B’ 列: ')
print(data['B'])
print('获取‘A’ ‘C’ 两列: ')
print(data[['A','C']])

DataFrame 对象获取列,除了传入具体的列名,还可以传入具体列的位置,通过传入位置来获取数据时需要用到 iloc 方法。
【示例 20】通过传入位置获取 DataFrame 对象中某一列/某几列
print('获取第 1 列: ')
print(data.iloc[:,0])
print('获取第 1 列和第 3 列: ')
print(data.iloc[:,[0,2]])

从上面的示例中可以看到,iloc 后的方括号中逗号之前的部分表示要获取的行的位置。只输入一个冒号,不输入任何数值表示获取所有的行;逗号之后的方括号表示要获取的列的位置,列的位置同样也是从 0 开始计数。
2) 选择连续的某几列
我们将通过列名选择数据的方式叫做普通索引,传入列的位置选择数据的方式叫做位置索引。获取连续的某几列,用普通索引和位置索引都可以做到。因为要获取的列是连续的,所以直接对列进行切片。
【示例 21】获取 DataFrame 对象中连续几列
print('获取 B C D 三列, 使用普通索引获取: ')
print(data.loc[:,'B':'D'])
print('获取 B C D 三列, 使用位置索引获取: ')
print(data.iloc[:,1:4])

从上面的示例可以看到,loc 和 iloc 后的方括号中逗号之前的表示选择的行,当只传入一个冒号时,表示选择所有行,逗号后面表示要选择列。data.loc[:,‘B’:‘D’]表示选择从 B 列开始到 D 列之间的值(包括 B 列也包括 D 列),data.iloc[:,1:4]表示选择第 2 列到第 5 列之间的值(包括第 1 列但不包括第 5 列)。
3) 选择某一行/某几行
获取行的方式主要有两种,一种是普通索引,即传入具体行索引的名称,需要用到 loc 方法;另外一种是
位置索引,即传入具体的行数,需要用到 iloc 方法。
【示例 22】DataFrame 对象中选择某一行/某几行
print('获取 a 行,普通索引获取: ')
print(data.loc['a'])
print('获取 a c 行,普通索引获取: ')
print(data.loc[['a','c']])
print('获取第 1 行, 位置索引获取: ')
print(data.iloc[0])
print('获取第 1 行第 3 行, 位置索引获取: ')
print(data.iloc[[0,2]])

4) 选择连续的某几行
选择连续的某几行和选择连续某几列类似,只要把连续行的位置用一个区间表示即可。
【示例 23】DataFrame 对象中选择某一行/某几行
print('选择 a 行 b 行, 使用普通索引: ')
print(data.loc['a':'b'])
print('选择第 1 行 第 2 行, 使用位置索引: ')
print(data.iloc[0:2])

5) 行列同时选择
【示例 24】同时选择连续的部分行和部分列
print('同时获取 a b 行,A B 列,使用普通索引:')
print(data.loc['a':'b','A':'B'])
print('同时获取 a b 行,A B 列,使用位置索引:')
print(data.iloc[0:2,0:2])

【示例 25】同时选择不连续的部分行和部分列
print('同时获取 a c 行, ABD 列, 使用普通索引: ')
print(data.loc[['a','c'],['A','B','D']])
print('同时获取 a c 行, ABD 列, 使用位置索引: ')
print(data.iloc[[0,2],[0,1,3]])

2.5 Series 的方法
Series 对象中有很多常用的方法可以对数据进行各种处理。例如,mean 方法可以对某一列数据取平均数,min 方法获取最小值,max 方法获取最大值,std 方法获取标准差。
【示例 26】使用 mean、min、max、std 等方法对数据集进行各种运算,最后对数据集进行排序操作
import pandas as pd
data = pd.DataFrame({
'Name':['zs','lisi','ww'],
'Sno':['1001','1002','1003'],
'Sex':['man','woman','man'],
'Age':[17,18,19],
'Score':[80,97,95]
},columns=['Sno','Sex','Age','Score'],index=['zs','lisi','ww'])
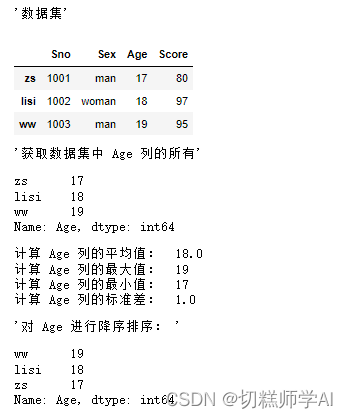
display('数据集',data)
ages = data['Age']
display('获取数据集中 Age 列的所有',ages)
print('计算 Age 列的平均值: ',ages.mean())
print('计算 Age 列的最大值: ',ages.max())
print('计算 Age 列的最小值: ',ages.min())
print('计算 Age 列的标准差: ',ages.std())
display('对 Age 进行降序排序: ',ages.sort_values(ascending=False))
2.6 Series 的条件过滤
Series 对象也可以像 SQL 语句一样,通过指定条件来过滤数据。
【示例 27】Series 对象指定条件来过滤数据
import pandas as pd
data = pd.DataFrame({
'Name':['zs','lisi','ww'],
'Sno':['1001','1002','1003'],
'Sex':['man','woman','man'],
'Age':[17,18,19],
'Score':[80,97,95]
},columns=['Sno','Sex','Age','Score'],index=['zs','lisi','ww'])
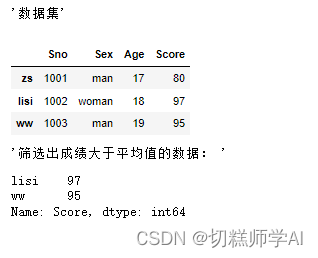
display('数据集',data)
scores = data['Score']
display('筛选出成绩大于平均值的数据: ',scores[scores>scores.mean()])
2.7 DataFrame 的条件过滤
DataFrame 与 Series 类似,也可以使用条件进行过滤。
【示例 28】DataFrame 对象指定条件来过滤数据
import pandas as pd
data = pd.DataFrame({
'Name':['zs','lisi','ww'],
'Sno':['1001','1002','1003'],
'Sex':['man','woman','man'],
'Age':[17,18,19],
'Score':[80,97,95]
},columns=['Sno','Sex','Age','Score'],index=['zs','lisi','ww'])
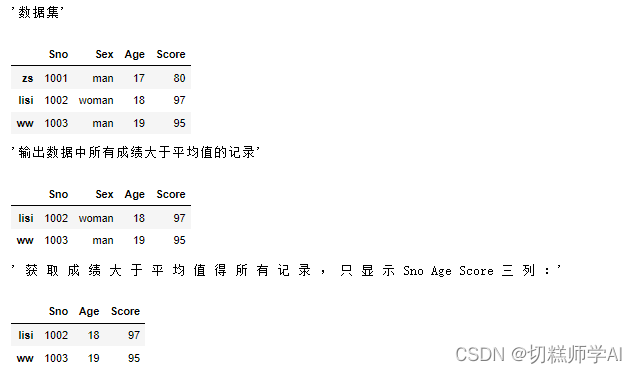
display('数据集',data)
scores = data['Score']
display('输出数据中所有成绩大于平均值的记录',data[scores>scores.mean()])
display(' 获 取 成 绩 大 于 平 均 值 得 所 有 记 录 , 只 显 示 Sno Age Score 三 列 :',data[scores>scores.mean()].loc[:,['Sno','Age','Score']])
3 处理缺失值
缺失值就是由某些原因导致部分数据为空,对于为空的这部分数据我们一般有两种处理方式,一种是删除,即把含有缺失值的数据删除;另外一种是填充,即把缺失的那部分数据用某个值代替。
3.1 缺失值查看
对缺失值进行处理,首先要把缺失值找出来,也就是查看哪列有缺失值。直接调用 info()方法就会返回每一列的缺失情况。
【示例 29】缺失值查看

Pandas 中缺失值用 NaN 表示,从用 info()方法的结果来看,索引 1 这一列是 1 2 non-null float64,表示这一列有 2 个非空值,而应该是 3 个非空值,说明这一列有 1 个空值。
还可以用 isnull()方法来判断哪个值是缺失值,如果是缺失值则返回 True,如果不是缺失值返回 False。
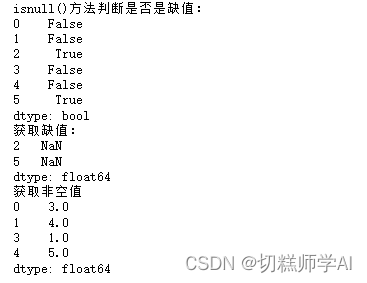
【示例 30】获取所有缺失值
data=pd.Series([3,4,np.nan,1,5,None])
print('isnull()方法判断是否是缺值: ')
print(data.isnull())
print('获取缺值: ')
print(data[data.isnull()])
print('获取非空值')
print(data[data.notnull()])
3.2 缺失值删除
缺失值分为两种,一种是一行中某个字段是缺失值;另一种是一行中的字段全部为缺失值,即为一个空白行。调用 dropna()方法删除缺失值,dropna()方法默认删除含有缺失值的行,也就是只要某一行有缺失值就把这一行删除。如果想按列为单位删除缺失值,需要传入参数axis=’columns’。
【示例 31】删除缺失值
df=pd.DataFrame([[1,2,np.nan],[4,np.nan,6],[5,6,7]])
print('默认为以行为单位剔除:')
display(df.dropna())
print('以列为单位剔除:')
display(df.dropna(axis='columns'))

如果想删除空白行,需要给 dropna()方法中传入参数 how=’all’即可,默认值是 any。
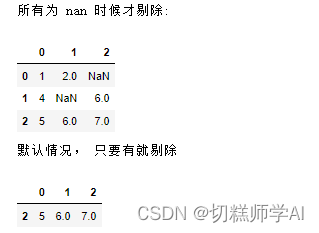
【示例 32】删除空白行
df=pd.DataFrame([[1,2,np.nan],[4,np.nan,6],[5,6,7]])
print('所有为 nan 时候才剔除:')
display(df.dropna(how='all'))
print('默认情况, 只要有就剔除')
display(df.dropna(how='any'))
3.3 缺失值填充
上面介绍了缺失值的删除,但是数据是宝贵的,一般情况下只要数据缺失比例不高(不大于 30%),尽量别删除,而是选择填充。
调用 fillna()方法对数据表中的所有缺失值进行填充,在 fillna()方法中输入要填充的值。还可以通过 method 参数使用前一个数和后一个数来进行填充。
【示例 33】Series 对象缺失值填充
data=pd.Series([3,4,np.nan,1,5,None])
print('以 0 进行填充:')
display(data.fillna(0))
print('以前一个数进行填充:')
display(data.fillna(method='ffill'))
print('以后一个数进行填充:')
display(data.fillna(method='bfill'))
print('先按前一个,再按后一个')
display(data.fillna(method='bfill').fillna(method='ffill'))

【示例 34】DataFrame 对象缺失值填充
df=pd.DataFrame([[1,2,np.nan],[4,np.nan,6],[5,6,7]])
print('使用数值 0 来填充: ')
display(df.fillna(0))
print('使用行的前一个数来填充: ')
display(df.fillna(method='ffill'))
print('使用列的后一个数来填充: ')
display(df.fillna(method='bfill' ,axis=1))

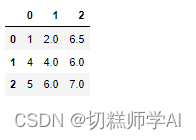
【示例 35】列的平均值来填充
df=pd.DataFrame([[1,2,np.nan],[4,np.nan,6],[5,6,7]])
for i in df.columns:
df[i]=df[i].fillna(np.nanmean(df[i]))
df
4 拼接
【示例 36】Series 对象拼接
ser1=pd.Series([1,2,3],index=list('ABC'))
ser2=pd.Series([4,5,6],index=list('DEF'))
pd.concat([ser1,ser2])

【示例 37】两个 df 对象拼接,默认找相同的列索引进行合并
def make_df(cols,index):
data={c:[str(c)+str(i) for i in index] for c in cols}
return pd.DataFrame(data,index=index)
df1=make_df('AB',[1,2])
df2=make_df('AB',[3,4])
pd.concat([df1,df2])

【示例 38】两个 df 对象拼接,添加 axis 参数
df1=make_df('AB',[1,2])
df2=make_df('AB',[3,4])
pd.concat([df1,df2],axis=1) #或者 pd.concat([df1,df2],axis='columns')
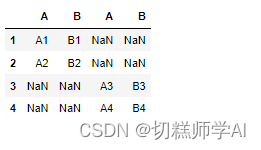
【示例 39】两个 df 对象拼接,索引重复问题
x=make_df('AB',[1,2])
y=make_df('AB',[1,2])
pd.concat([x,y])

【示例 40】两个 df 对象拼接,解决索引重复问题加 ignore_index 属性
x=make_df('AB',[1,2])
y=make_df('AB',[1,2])
pd.concat([x,y],ignore_index=True)

【示例 41】两个 df 对象拼接,解决索引重复问题,加 keys 属性
x=make_df('AB',[1,2])
y=make_df('AB',[1,2])
pd.concat([x,y],keys=list('xy'))

【示例 42】两个 df 对象拼接,join 内连接做交集
a=make_df('ABC',[1,2])
b=make_df('BCD',[3,4])
pd.concat([a,b],join='inner')

5 merge 的使用
pandas 中 的 merge 和concat 类似,但主要是用于两组有 key column 的数据,统一索引的数据。通常也被用在 Database 的处理当中。
合并时有 4 种方式 how = [‘left’, ‘right’, ‘outer’, ‘inner’],默认值 how=‘inner’。
【示例 43】merge 的使用,默认以 how=’inner’进行合并
left=pd.DataFrame({'key':['k0','k1','k2','k3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3'],
})
right=pd.DataFrame({'key':['k0','k1','k4','k3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3'],
})
result=pd.merge(left,right)
result

【示例 44】merge 的使用,参数 how=’outer’进行合并
left=pd.DataFrame({'key':['k0','k1','k2','k3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3'],
})
right=pd.DataFrame({'key':['k0','k1','k4','k3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3'],
})
pd.merge(left,right,how='outer')
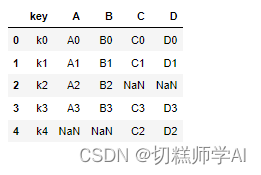
【示例 45】merge 的使用,参数 how=’left’进行合并
left=pd.DataFrame({'key':['k0','k1','k2','k3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3'],
})
right=pd.DataFrame({'key':['k0','k1','k4','k3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3'],
})
pd.merge(left,right,how='left')

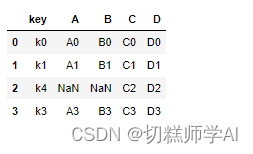
【示例 46】行索引不同, how=’right’进行合并
left=pd.DataFrame({'key':['k0','k1','k2','k3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3'],
})
right=pd.DataFrame({'key':['k0','k1','k4','k3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3'],
})
pd.merge(left,right,how='right')
总结
以上就是我对Pandas 数据分析库知识点的详细介绍。
本文是我学习Python基础的学习笔记,主要供自己以后温故知新,在此梳理一遍也算是二次学习。如对您有所帮助,不甚荣幸。若所言有误,十分欢迎指正。如有侵权,请联系作者删除。