【关于时间序列的ML】项目 6 :机器学习中使用 LSTM 的时间序列
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
什么是时间序列预测?
什么是长短期记忆?
使用 LSTM 预测时间序列
LSTM 的时间序列
常见的机器学习面试问题
神经网络可能是一个难以理解的概念。我认为这主要是因为它们可以用于很多不同的事情,比如分类、识别或只是回归。在本文中,我将向您介绍如何设置一种使用 LSTM 模型预测时间序列的简单方法。
在开始使用 LSTM 预测时间序列的编码部分之前,首先让我们为正在阅读本文的所有初学者介绍一些涉及的主要概念。
什么是时间序列预测?
时间序列预测是一种通过时间序列预测事件的技术。该技术被用于许多研究领域,从地质学到行为学再到经济学。技术通过分析过去的趋势来预测未来事件,假设未来趋势与历史趋势保持相似。
什么是长短期记忆?
LSTM 代表短期长期记忆。它是扩展递归神经网络记忆的模型或架构。通常,递归神经网络具有“短期记忆”,因为它们使用持久的过去信息用于当前神经网络。本质上,先前的信息用于当前任务。这意味着我们没有可用于神经节点的所有先前信息的列表。
使用 LSTM 预测时间序列
我希望您已经了解时间序列预测的含义以及什么是 LSTM 模型。现在,我将着手创建一个机器学习模型,以在机器学习中使用 LSTM 预测时间序列。
对于使用 LSTM 预测时间序列的任务,我将从导入我们需要的所有必要包开始:
import numpy
import matplotlib.pyplot as plt
import pandas
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
# fix random seed for reproducibility
numpy.random.seed(7)现在让我们加载数据并准备数据,以便我们可以在 LSTM 模型上使用它,您可以从这里下载我在此任务中使用的数据集:
# load the dataset
dataframe = pandas.read_csv('airline-passengers.csv', usecols=[1], engine='python')
dataset = dataframe.values
dataset = dataset.astype('float32')
# normalize the dataset
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)现在,我将把数据分成训练集和测试集:
# split into train and test sets
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
print(len(train), len(test))96 48LSTM 的时间序列
现在在 LSTM 模型上训练数据之前,我们需要准备数据以便我们可以将其拟合到模型上,为此我将定义一个辅助函数:
# convert an array of values into a dataset matrix
def create_dataset(dataset, look_back=1):
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back), 0]
dataX.append(a)
dataY.append(dataset[i + look_back, 0])
return numpy.array(dataX), numpy.array(dataY)现在,我们需要在将数据应用到 LSTM 模型之前对其进行整形:
# reshape into X=t and Y=t+1
look_back = 1
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
# reshape input to be [samples, time steps, features]
trainX = numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = numpy.reshape(testX, (testX.shape[0], 1, testX.shape[1]))现在所有关于数据准备以适应 LSTM 模型的任务都已完成,是时候将数据适应模型并让我们训练模型了:
# create and fit the LSTM network
model = Sequential()
model.add(LSTM(4, input_shape=(1, look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)现在,让我们使用 python 中的 matplotlib 包进行预测并可视化时间序列趋势:
# make predictions
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
# invert predictions
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
# calculate root mean squared error
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
# shift train predictions for plotting
trainPredictPlot = numpy.empty_like(dataset)
trainPredictPlot[:, :] = numpy.nan
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict
# shift test predictions for plotting
testPredictPlot = numpy.empty_like(dataset)
testPredictPlot[:, :] = numpy.nan
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict
# plot baseline and predictions
plt.plot(scaler.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()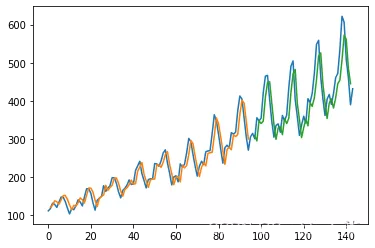
我希望你喜欢这篇关于使用 LSTM 模型预测时间序列的文章。
常见的机器学习面试问题
如果您的模型在训练数据上表现良好但对新实例的泛化能力很差,会发生什么?你能说出三种可能的解决方案吗?
如果一个模型在训练数据上表现良好但对新实例的泛化能力很差,则该模型可能过度拟合训练数据(或者我们在训练数据上非常幸运)。过度拟合的可能解决方案是获取更多数据、简化模型(选择更简单的算法、减少使用的参数或特征的数量,或正则化模型)或减少数据中的噪声。训练。
假设您正在使用多项式回归。你画了学习曲线,你注意到学习错误和验证错误之间有很大的差距。怎么了?解决这个问题的三种方法是什么?
如果验证误差远高于训练误差,这很可能是由于您的模型过度拟合了训练集。尝试解决此问题的一种方法是降低多项式次数:自由度越低的模型越不容易过度拟合。您可以尝试的另一件事是对模型进行正则化——例如,向成本函数添加 ℓ2(Ridge)惩罚或 ℓ1(Lasso)惩罚。这也会降低模型的自由度。最后,您可以尝试增加训练集的大小。
SVM 分类器在对实例进行分类时能否生成置信度得分?还有概率?
SVM 分类器可以显示测试实例和决策限之间的距离,您可以将其用作置信度分数。但是,这个分数不能直接转换为类别概率的估计。如果在 Scikit-Learn 中创建 SVM 时设置 probability = True,则训练后它将使用逻辑回归对 SVM 的分数进行校准(由对训练数据的额外五次交叉验证驱动)。这会将 Predict_proba() 和 Predict_log_proba() 方法添加到 SVM。
如果决策树不适合训练集,尝试缩放输入特征是否是个好主意?
决策树不关心训练数据是按比例缩放还是居中;这是他们的优点之一。因此,如果决策树小于训练集,缩放输入特征将只是浪费时间。
硬投票分类器和软投票分类器有什么区别?
硬投票分类器简单地计算集合中每个分类器的选票,并选择获得最多选票的类别。软投票分类器计算每个类别的估计中产阶级概率,并选择概率最高的类别。这会给高置信度的投票更多的权重并且通常表现得更好,但它只有在每个分类器都可以估计类别概率的情况下才有效。
如何评估数据集上降维算法的性能?
直观地说,如果降维算法从数据集中消除大量维度而不丢失太多信息,则它会很好地工作。衡量这一点的一种方法是应用逆变换并衡量重建误差。
然而,并非所有的降维算法都提供逆变换。或者,如果您使用降维作为另一种机器学习算法(例如,随机森林分类器)之前的预处理步骤,您可以简单地测量第二种算法的性能;如果降维没有丢失太多信息,那么该算法应该和使用原始数据集时一样有效。
异常检测和新颖性检测有什么区别?
许多人互换使用异常检测和新颖性检测这两个术语,但它们并不相同。在异常检测中,算法在可能包含异常值的数据集上进行训练,目标通常是识别那些异常值(在训练集中)以及值。新实例中的异常。
在新颖性检测中,算法在一组被假定为“干净”的数据上进行训练,目标是在新实例中严格检测新颖性。一些算法更适合异常检测(例如 Isolation Forest),而其他算法更适合新颖性检测(例如 SVM 到类)。
为什么通常使用逻辑回归分类器比使用经典的感知器更好?如何修改感知器使其等同于逻辑回归分类器?
经典的感知器只有在数据集线性可分时才会收敛,并且无法估计类别概率。相反,即使数据集不是线性可分的,逻辑回归分类器也会收敛到一个好的解决方案,并且会产生类别概率。
如果将 Perceptron 的激活函数更改为逻辑激活(如果有多个神经元,则更改为 softmax 激活),并且如果使用梯度下降(或其他一些最小化成本函数的优化算法,通常是交叉熵)对其进行训练,则它等同于逻辑回归分类器。
TensorFlow 是 NumPy 的即时替代品吗?两者之间的主要区别是什么?
虽然 TensorFlow 提供了 NumPy 提供的大部分功能,但由于多种原因,它并不是即时替代品。首先,函数的名称并不总是相同的(例如,tf.reduce_sum () 与 np.sum ())。其次,一些函数的行为并不相同(例如,tf.trans pose() 创建一个张量的转置副本,而 NumPy 的 T 属性创建一个转置视图,而不实际复制任何数据)。最后,与 TensorFlow 张量不同,NumPy 数组是可变的。
如果你的 GPU 在训练 CNN 时内存不足,你可以尝试哪五种方法来解决这个问题?
如果您的 GPU 在训练 CNN 时内存不足,您可以尝试通过以下五种方法来解决问题(除了购买内存更大的 GPU 之外):
- 1. 减少迷你批次的大小。
- 2.通过在一层或多层中使用更大的步幅来降低维度。
- 3.移除一层或多层。
- 4.使用 16 位浮点数而不是 32 位浮点数。
- 5.跨多个设备分发 CNN
- 3.移除一层或多层。