[C++: 引用】
To shine,not be illuminated.

目录
1 引用概念
2 引用特性
3 常引用
4 使用场景
4.1 引用做参数
4.2 做返回值
5 传值、传引用效率比较
6 引用和指针的区别
7 总结
1 引用概念
引用 不是新定义一个变量,而 是给已存在变量取了一个别名 ,编译器不会为引用变量开辟内存空间,它和它引用的变量 共用同一块内存空间。
比如:你的正式姓名和你的小名或者别名。
使用方法:
类型& 引用变量名(对象名) = 引用实体;
我们可以来举个例子:
int main()
{
int a = 10;
int& sa = a;
int b = 20;
int& sb = b;
return 0;
}
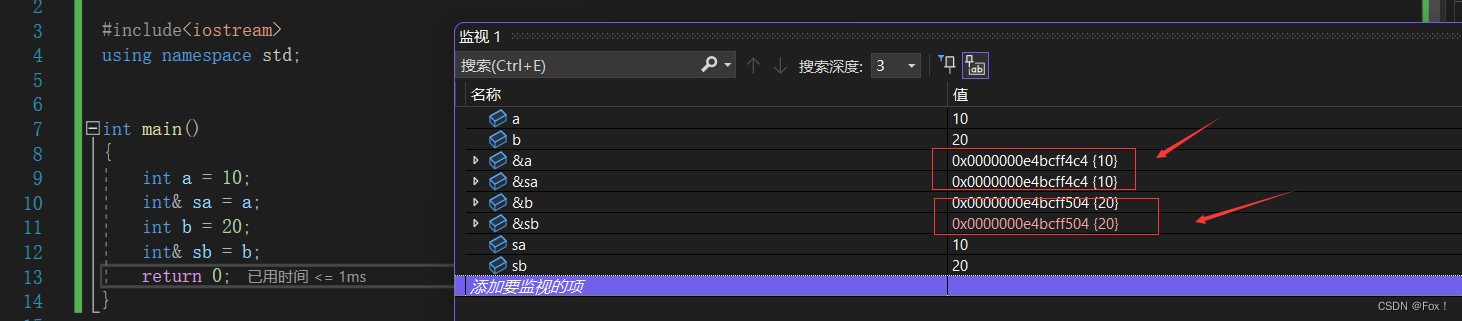
通过调试我们也能够发现a和sa其实共用的是同一块空间,这也就解释了为啥引用只是给变量取了一个新名字,并没有为引用变量开辟新的空间。
2 引用特性
- 1. 引用在定义时必须初始化
- 2. 一个变量可以有多个引用
- 3. 引用一旦引用一个实体,再不能引用其他实体
我们一个一个来看:
假如引用变量不初始化
int main()
{
int a = 10;
int& sa ;
return 0;
}
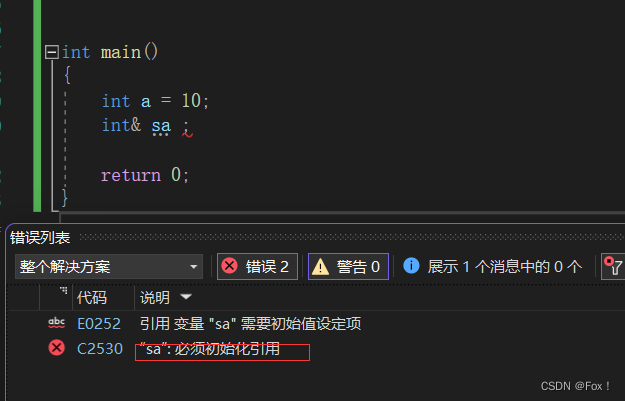
这种方式显然是会直接报错的:
一个引用变量可以有多个引用:
int main()
{
int a = 10;
int& b = a;
int& c = a;
return 0;
}
这里b和c都是a的别名,修改其中任何一个这3个的值都会发生改变。
假如拿一个已经引用过的实体再去引用其他实体:
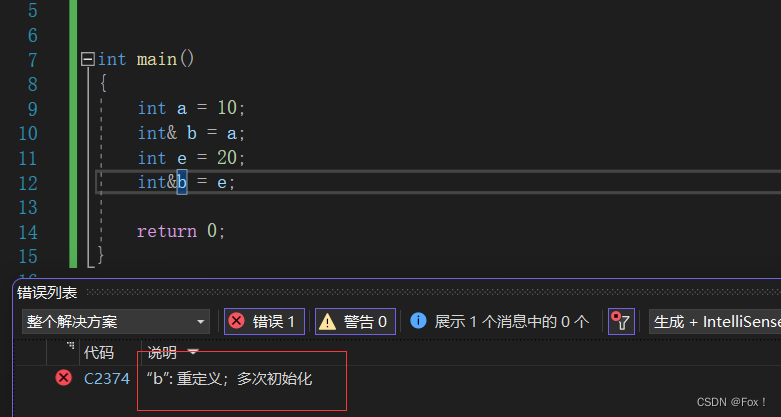
这样写直接就报错了,有人会想到换一种方式写呢:
int main()
{
int a = 10;
int& b = a;
int e = 20;
b = e;
return 0;
}
这里b还是e的引用吗?
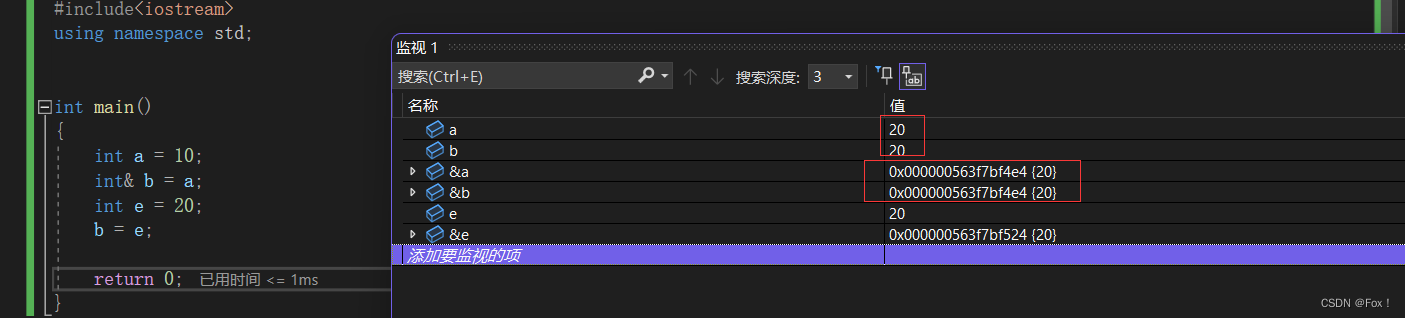
显然不是的,这里只是将e的值赋给了b,b还是a的引用,程序结束后a和b都应该为20,我们可以打开监视窗口看看:
3 常引用
我们来看下面这个栗子:
int main()
{
const int a = 10;
int& b = a;
return 0;
}
上述代码能够被编译通过吗?
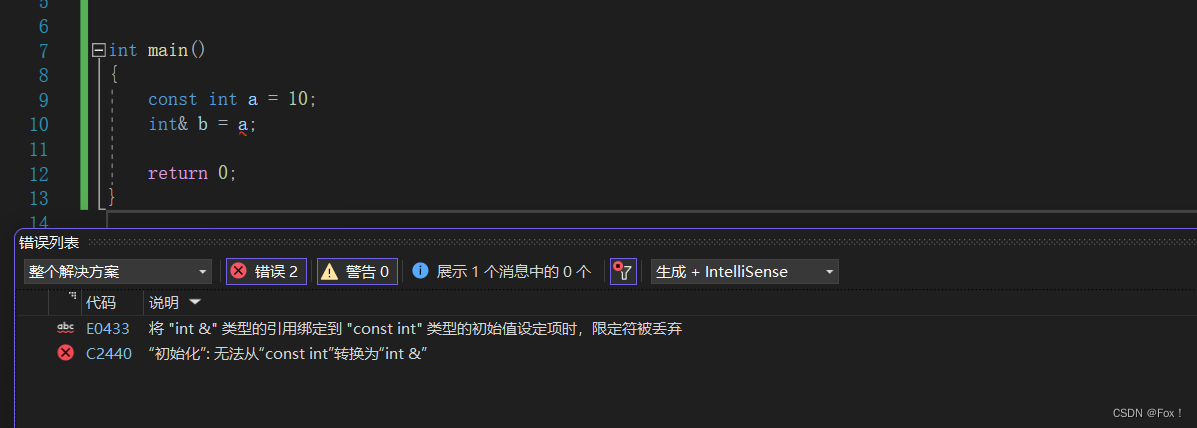
很明显这种写法是错误的,C++认为这种写法是不安全的,const int是只读权限,而int&却是既有读权限也有写权限,像这种权限放大C++是不支持的,权限缩小或者权限相等C++是支持的。
比如下面这两种写法都是合法的:
int main()
{
//权限相等
const int a = 10;
const int& b = a;
//权限缩小
int c = 20;
const int& d = c;
return 0;
}
再来看下面一段代码:
int main()
{
double d = 12.12;
int& i = d;
return 0;
}上面代码能够编译通过吗?
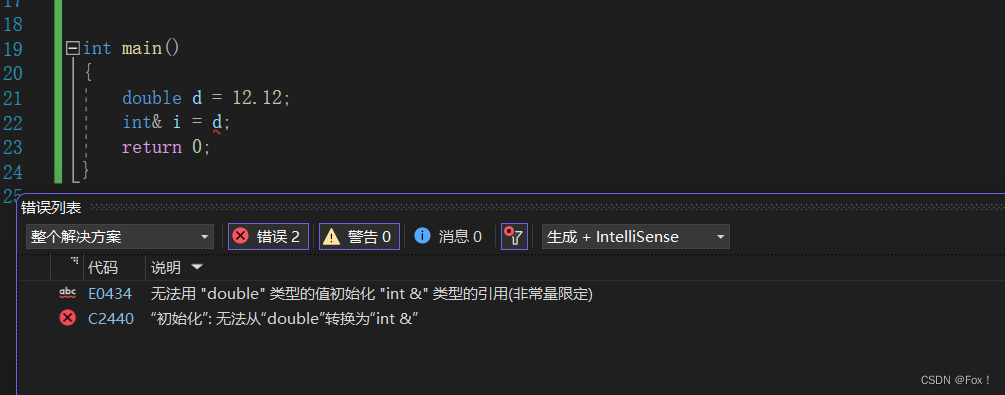
我们可能会想:引用类型和引用实体必须是同一种类型的,所以说就错误了呗。
引用类型和引用实体一定要是同一种类型的吗?
我们将程序再修改一下:
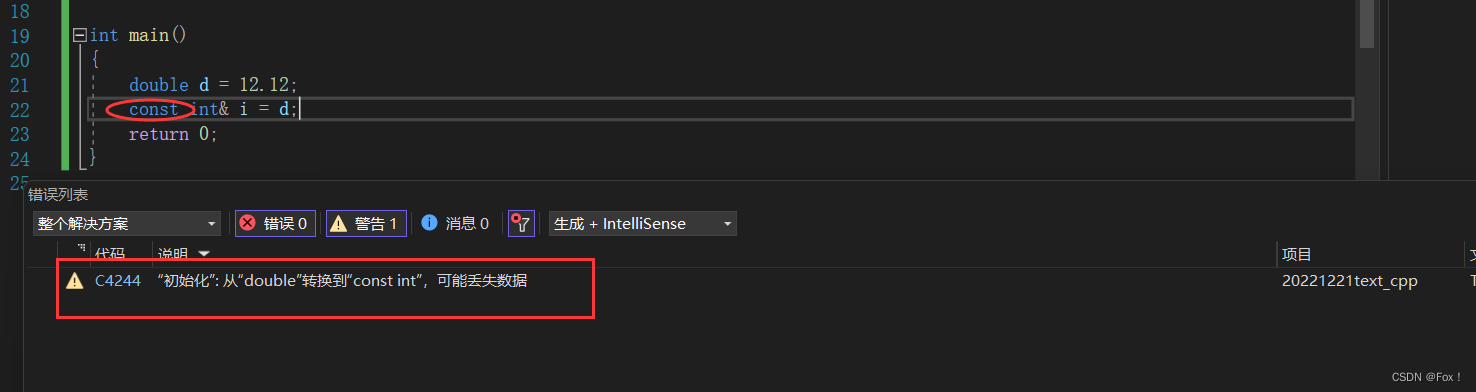
我们发现程序居然能够跑过,只是错误变成了一个警告,为什么呢?
通过C语言的知识我们知道:double类型的d如果要转换成int类型的i是会发生截断的,首先会用一个临时变量来保存被截断后的值,再将该值换一个新的名称,d本身是不会发生任何改变的。而这个临时变量是具有常数性的(这个很重要,后面也会反复的提及)不能被修改,也就是不能够写,只能够读。由于权限不能够升高,所以我们必须得加const才行。
我们再来回答上面的问题,引用类型和引用实体一定要是同一种类型的吗?
如果想要正确的使用,这句话显然没有什么毛病,但是并不是说引用类型和引用实体不是同一种类型程序一定就会报错。
建议:以后我们引用一个实体是如果不想改变这个实体,最好加上const.
4 使用场景
像上面举出来引用的栗子,实际工程之中基本上不会这样用,而引用的使用场景主要是下面这两方面:
- 1. 做参数
- 2. 做返回值
4.1 引用做参数
举一个最简单的例子,交换两个变量,以前我们是这样做的:
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}现在用引用就简单一些了:
void Swap(int& x, int& y)
{
int tmp = x;
x = y;
y = tmp;
}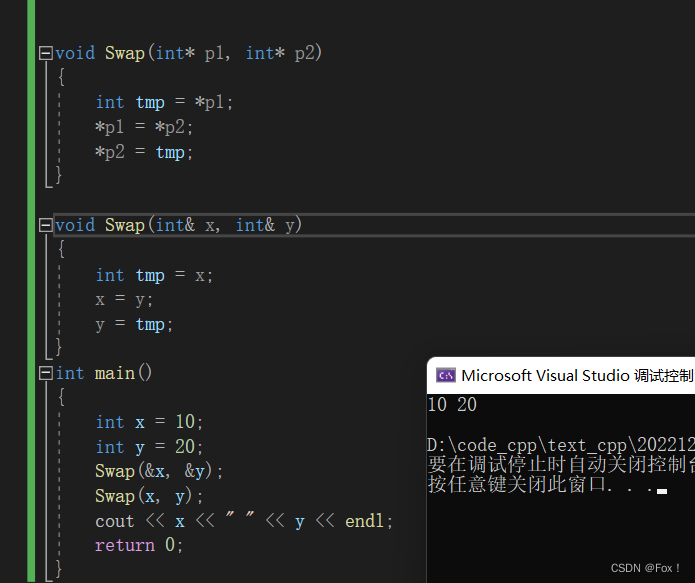
这两个函数是构成函数重载的。
另外大家还记得链表那里的二级指针吗?当初可是把我们坑惨了的,忘记了的话可以参考博主写的这篇博客:单链表
如果现在用引用那不得爽死,这里,我只给了其中一个接口,其他接口也是一样的道理:
void SLPushFront(SLNode*& phead, SLTDataType x)
{
SLNode* newNode = SLCreat(x);
newNode->next = phead;
phead = newNode;
}4.2 做返回值
我们来看下面的一个程序有没有问题:
int& fun()
{
int a = 10;
return a;
}
int main()
{
int ret = fun();
cout << ret << endl;
return 0;
}我们运行一下程序:
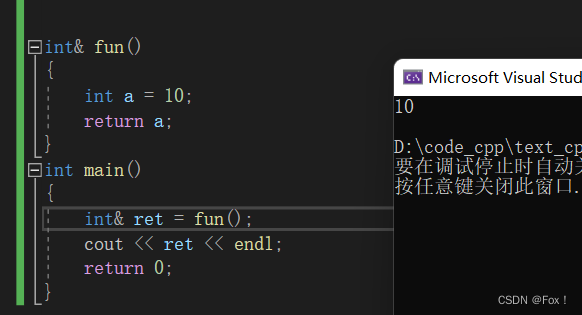
好像没有啥问题,但是我们再小小的修改一下程序:
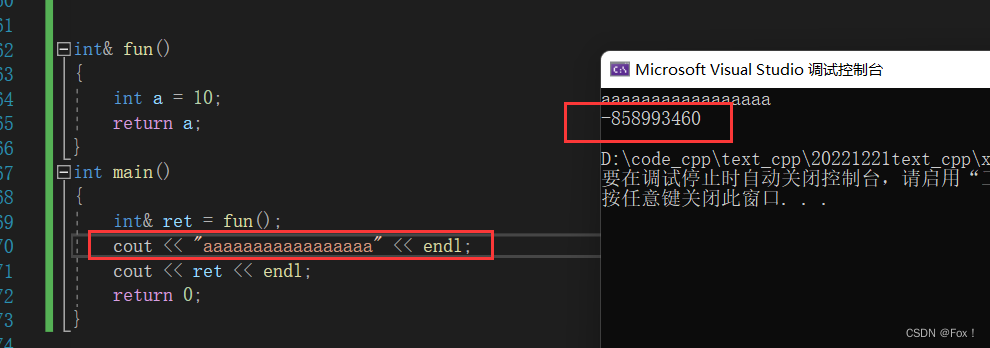
为啥我就加了一个cout输出一堆字符,但是我ret的结果就变成了一堆垃圾数了呢?
我们知道a是一个局部变量,出了作用域就要被销毁,再销毁前我们将a的引用用了一个临时引用变量来保存(假设这个临时变量为tmp(类型是int&)),我们发现tmp和ret都是变量a的别名,而a出了作用域就被释放了,没有加cout输出一堆字符时我们发现结果正确只是因为释放过了空间后a还没有被改变,当为cout重新建立栈帧的时候a已经被修改了,这种返回局部变量的引用是一件极其危险的事情。
但是这样修改一下就不会担心出现这种问题了:
int& fun()
{
static int a = 10;
return a;
}加一个static就不会出现这种问题了。
int At(int i)
{
static int a[10];
return a[i];
}
int main()
{
for (int i = 0; i < 10; i++)
{
At(i) = 10 + i;
}
for (int i = 0; i < 10; i++)
{
cout << At(i) << " ";
}
cout << endl;
return 0;
}这个程序有问题吗?我们运行一下:
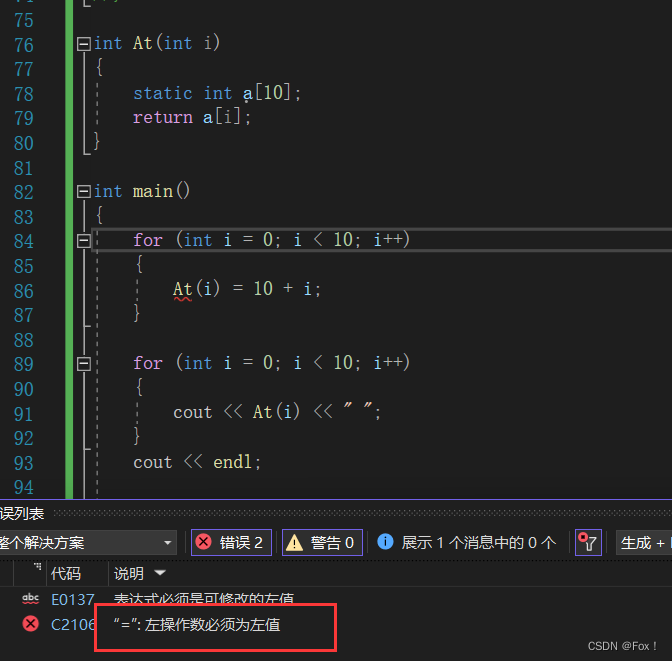
程序报错了,为啥呢?
通过C语言的学习我们知道,传值返回是返回的一个临时变量,该变量具有常属性(只能读,不能够被写)也就是只能够作为右值,不能够作为左值,上面的第一个for循环时对其进行写操作,当然会报错,正确的处理方式是用引用返回:
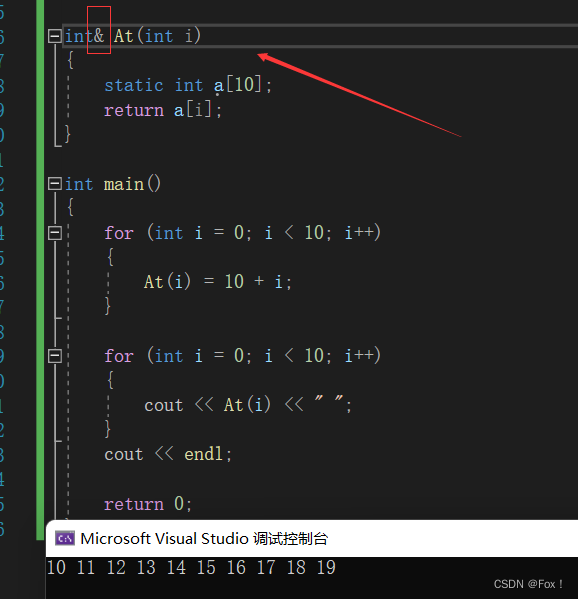
为啥引用返回是正确的呢?由于引用只是给a[i]取了一个别名,a[i]是具有读写功能的,所以就不会报错了。
5 传值、传引用效率比较
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是 当参数或者返回值类型非常大时,效率就更低。
我们可以来测试一下:
做参数:
#include <time.h>
struct A { int a[100000]; };
void TestFunc1(A a) {}
void TestFunc2(A& a) {}
void TestRefAndValue()
{
A a;
// 以值作为函数参数
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 以引用作为函数参数
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 分别计算两个函数运行结束后的时间
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}

做返回值:
struct A { int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a; }
// 引用返回
A& TestFunc2() { return a; }
void TestReturnByRefOrValue()
{
// 以值作为函数的返回值类型
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1();
size_t end1 = clock();
// 以引用作为函数的返回值类型
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2();
size_t end2 = clock();
// 计算两个函数运算完成之后的时间
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}

通过上述代码的比较,发现传值和指针在作为传参以及返回值类型上效率相差很大。
6 引用和指针的区别
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。
在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。
我们来看下引用和指针的汇编代码对比:

引用和指针的不同点:
|
1.
引用
在定义时
必须初始化
,指针没有要求
|
|
2.
引用
在初始化时引用一个实体后,就
不能再引用其他实体
,而指针可以在任何时候指向任何一个同类型实体
|
|
3.
没有
NULL
引用
,但有
NULL
指针
|
|
4.
在
sizeof
中含义不同
:
引用
结果为
引用类型的大小
,但
指针
始终是
地址空间所占字节个数
(32
位平台下占4
个字节
)
|
|
5.
引用自加即引用的实体增加
1
,指针自加即指针向后偏移一个类型的大小
|
|
6.
有多级指针,但是没有多级引用
|
|
7.
访问实体方式不同,
指针需要显式解引用,引用编译器自己处理
|
|
8.
引用比指针使用起来相对更安全
|
7 总结
本文主要介绍了引用的概念,怎样使用引用以及引用的使用场景,还举了很多容易出错的栗子来帮助理解引用,最后列举了引用和指针的区别。如果该文对你友帮助的话能不能3连支持已选博主呢?
