java 三级缓存
🏆今日学习目标:
🍀java 三级缓存
✅创作者:林在闪闪发光
⏰预计时间:30分钟
🎉个人主页:林在闪闪发光的个人主页
🍁林在闪闪发光的个人社区,欢迎你的加入: 林在闪闪发光的社区
目录
1 什么是缓存
2.缓存作用
1 高性能情况
2 高并发场景
4.缓存分类
4.1本地缓存
4.2分布式缓存
4.3多级缓存
1 什么是缓存
就是把访问量较高的热点数据从传统的关系型数据库中加载到内存中,当用户再次访问热点数据时是从内存中加载,减少了对数据库的访问量,解决了高并发场景下容易造成数据库宕机的问题
2.缓存作用
缓存主要是为了提高数据的读取速度。因为服务器和应用客户端之间存在着流量的瓶颈,所以读取大容量数据时,使用缓存来直接为客户端服务,可以减少客户端与服务器端的数据交互,从而大大提高程序的性能。
以前实现数据的缓存有很多种方法,有客户端的Cookie,有服务器端的Session和Application。其中Cookie是保存在客户端的一组数据,主要用来保存用户名等个人信息。Session则保存对话信息。Application则是保存在整个应用程序范围内的信息,相当于全局变量。通常使用最频繁的是Session,缓存也是有限的,会自动清除之前的旧数据。其中redis的读取速度最快,并且是在内存中进行读取,当内存不够时可以扩大内存,还有就是 .net提供的Cache缓存.
3.为什么要用缓存
1 高性能情况
用户第一次访问数据时,缓存中没有数据,要从数据库中获取数据,因为是从磁盘中拿数据,读取数据的过程比较慢。拿到数据后将数据存储在缓存中,用户第二次访问数据时,可以从缓存中直接获取,因为缓存是直接操作内存的,访问数据速度比较快。
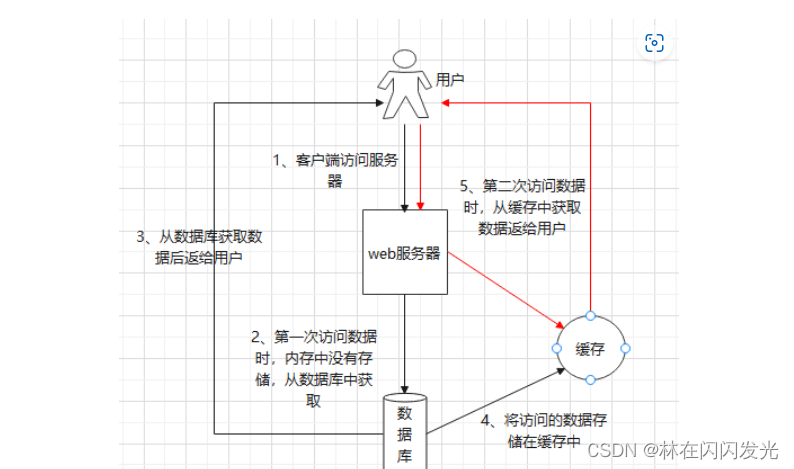
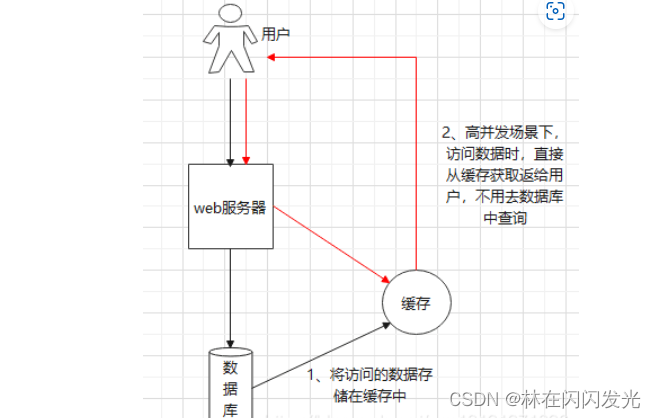
2 高并发场景
操作缓存能够承受的并发访问量是远远大于访问数据库的,比如redis,它的读的速度是110000次/s,写的速度是81000次/s。所以说将数据库中访问量高的数据存储到缓存中,用户请求的时候直接访问数据库,不必访问数据库,提高应用程序的并发量。
4.缓存分类
分为三类:本地缓存、分布式缓存、多级缓存。
根据缓存和应用程序是否属于同一个进程,将缓存分为本地缓存和分布式缓存。基于本地缓存和分布式缓存都有各自的优点和缺点,后面又出现了多级缓存的概念
4.1本地缓存
本地缓存:是指和应用程序在同一个进程内的内存空间去存储数据,数据的读写都是在同一个进程内完成的。
优点:读取速度快,但是不能进行大数据量存储。
本地缓存不需要远程网络请求去操作内存空间,没有额外的性能消耗,所以读取速度快。但是由于本地缓存占用了应用进程的内存空间,比如java进程的jvm内存空间,故不能进行大数据量存储。
缺点:
应用程序集群部署时,会存在数据更新问题(数据更新不一致)
本地缓存一般只能被同一个应用进程的程序访问,不能被其他应用程序进程访问。在单体应用集群部署时,如果数据库有数据需要更新,就要同步更新不同服务器节点上的本地缓存的数据来保证数据的一致性,但是这种操作的复杂度高,容易出错。可以基于redis的发布/订阅机制来实现各个部署节点的数据同步更新。
数据会随着应用程序的重启而丢失
因为本地缓存的数据是存储在应用进程的内存空间的,所以当应用进程重启时,本地缓存的数据会丢失。
实现:
缓存存储的数据一般都是key-value键值对的数据结构,在java语言中,常用的字典实现包括 HashMap 和 ConcurretHashMap。
除了上面说的实现方式以外,也可以用Guava、Ehcache以及Caffeine等封装好的工具包来实现本地缓存。
4.2分布式缓存
分布式缓存:分布式缓存是独立部署的服务进程,并且和应用程序没有部署在同一台服务器上,所以是需要通过远程网络请求来完成分布式缓存的读写操作,并且分布式缓存主要应用在应用程序集群部署的环境下。
优点:
支持大数据量存储
分布式缓存是独立部署的进程,拥有自身独自的内存空间,不需要占用应用程序进程的内存空间,并且还支持横向扩展的集群方式部署,所以可以进行大数据量存储。
数据不会随着应用程序重启而丢失
分布式缓存和本地缓存不同,拥有自身独立的内存空间,不会受到应用程序进程重启的影响,在应用程序重启时,分布式缓存的存储数据仍然存在。
数据集中存储,保证数据的一致性
当应用程序采用集群方式部署时,集群的每个部署节点都有一个统一的分布式缓存进行数据的读写操作,所以不会存在像本地缓存中数据更新问题,保证了不同服务器节点的数据一致性。
数据读写分离,高性能,高可用
分布式缓存一般支持数据副本机制,实现读写分离,可以解决高并发场景中的数据读写性能问题。而且在多个缓存节点冗余存储数据,提高了缓存数据的可用性,避免某个缓存节点宕机导致数据不可用问题。
缺点:
数据跨网络传输,读写性能不如本地缓存
分布式缓存是一个独立的服务进程,并且和应用程序进程不在同一台机器上,所以数据的读写要通过远程网络请求,这样相对于本地缓存的数据读写,性能要低一些。
分布式缓存的实现:典型实现包括 MemCached 和 Redis。
4.3多级缓存
基于本地缓存和分布式缓存的优缺点,多级缓存应运而生,在实际的业务开发中一般也是采用多级缓存。注意:本地缓存一般存储更新频率低,访问频率高数据,分布式缓存一般存储更新频率很高的数据。
多级缓存的请求流程:本地缓存作为一级缓存,分布式缓存作为二级缓存。当用户获取数据时,先从一级缓存中获取数据,如果一级缓存有数据则返回数据,否则从二级缓存中获取数据。如果二级缓存中有数据则更新一级缓存,然后将数据返回客户端。如果二级缓存没有数据则去数据库查询数据,然后更新二级缓存,接着再更新一级缓存,最后将数据返回给客户端

多级缓存的实现:可以使用Guava或者Caffeine作为一级缓存,Redis作为二级缓存。
注意:在应用程序集群部署时,如果数据库的数据有更新的情况,一级缓存的数据更新容易出现数据不一致的情况。因为是集群部署,多个部署节点实现一级缓存数据更新难度比较大,不过我们可以通过Redis的消息发布/订阅机制来实现多个节点缓存数据一致性问题。