搞定 Redis 数据存储原理,别只会 set、get 了
我的核心模块如图 1-10。
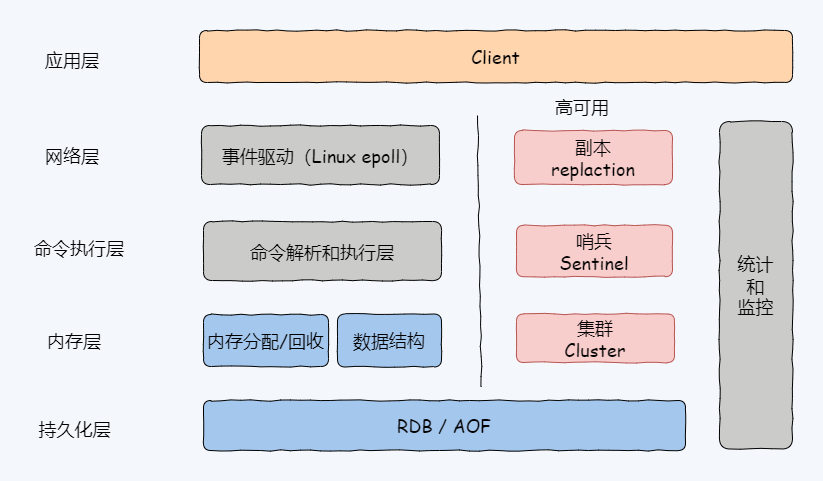
图 1-10
-
Client 客户端,官方提供了 C 语言开发的客户端,可以发送命令,性能分析和测试等。
-
网络层事件驱动模型,基于 I/O 多路复用,封装了一个短小精悍的高性能 ae 库,全称是
a simple event-driven programming library。-
在 ae 这个库里面,我通过
aeApiState结构体对epoll、select、kqueue、evport四种 I/O 多路复用的实现进行适配,让上层调用方感知不到在不同操作系统实现 I/O 多路复用的差异。 -
Redis 中的事件可以分两大类:一类是网络连接、读、写事件;另一类是时间事件,也就是特定时间触发的事件,比如定时执行 rehash 操作。
-
-
命令解析和执行层,负责执行客户端的各种命令,比如
SET、DEL、GET等。 -
内存分配和回收,为数据分配内存,提供不同的数据结构保存数据。
-
持久化层,提供了 RDB 内存快照文件 和 AOF 两种持久化策略,实现数据可靠性。
-
高可用模块,提供了副本、哨兵、集群实现高可用。
-
监控与统计,提供了一些监控工具和性能分析工具,比如监控内存使用、基准测试、内存碎片、bigkey 统计、慢指令查询等。
掌握了整体架构和模块后,接下来进入 src 源码目录,使用如下指令执行 redis-server可执行程序启动 Redis。
./redis-server ../redis.conf
每个被启动的服务我都会抽象成一个 redisServer,源码定在server.h 的redisServer 结构体。
这个结构体包含了存储键值对的数据库实例、redis.conf 文件路径、命令列表、加载的 Modules、网络监听、客户端列表、RDB AOF 加载信息、配置信息、RDB 持久化、主从复制、客户端缓存、数据结构压缩、pub/sub、Cluster、哨兵等一些列 Redis 实例运行的必要信息。
结构体字段很多,不再一一列举,部分核心字段如下。
truct redisServer {
pid_t pid; /* 主进程 pid. */
pthread_t main_thread_id; /* 主线程 id */
char *configfile; /*redis.conf 文件绝对路径*/
redisDb *db; /* 存储键值对数据的 redisDb 实例 */
int dbnum; /* DB 个数 */
dict *commands; /* 当前实例能处理的命令表,key 是命令名,value 是执行命令的入口 */
aeEventLoop *el;/* 事件循环处理 */
int sentinel_mode; /* true 则表示作为哨兵实例启动 */
/* 网络相关 */
int port;/* TCP 监听端口 */
list *clients; /* 连接当前实例的客户端列表 */
list *clients_to_close; /* 待关闭的客户端列表 */
client *current_client; /* 当前执行命令的客户端*/
};
1.2.1 数据存储原理
其中redisDb *db指针非常重要,它指向了一个长度为 dbnum(默认 16)的 redisDb 数组,它是整个存储的核心,我就是用这玩意来存储键值对。
redisDb
redisDb 结构体定义如下。
typedef struct redisDb {
dict *dict;
dict *expires;
dict *blocking_keys;
dict *ready_keys;
dict *watched_keys;
int id;
long long avg_ttl;
unsigned long expires_cursor;
list *defrag_later;
clusterSlotToKeyMapping *slots_to_keys;
} redisDb;
dict 和 expires
-
dict 和 expires 是最重要的两个属性,底层数据结构是字典,分别用于存储键值对数据和 key 的过期时间。
-
expires,底层数据结构是 dict 字典,存储每个 key 的过期时间。
❝MySQL:“为什么分开存储?”
好问题,之所以分开存储,是因为过期时间并不是每个 key 都会设置,它不是键值对的固有属性,分开后虽然需要两次查找,但是能节省内存开销。
blocking_keys 和 ready_keys
底层数据结构是 dict 字典,主要是用于实现 BLPOP 等阻塞命令。
当客户端使用 BLPOP 命令阻塞等待取出列表元素的时候,我会把 key 写到 blocking_keys 中,value 是被阻塞的客户端。
当下一次收到 PUSH 命令执时,我会先检查 blocking_keys 中是否存在阻塞等待的 key,如果存在就把 key 放到 ready_keys 中,在下一次 Redis 事件处理过程中,会遍历 ready_keys 数据,并从 blocking_keys 中取出阻塞的客户端响应。
watched_keys
用于实现 watch 命令,存储 watch 命令的 key。
id
Redis 数据库的唯一 ID,一个 Redis 服务支持多个数据库,默认 16 个。
avg_ttl
用于统计平均过期时间。
expires_cursor
统计过期事件循环执行的次数。
defrag_later
保存逐一进行碎片整理的 key 列表。
slots_to_keys
仅用于 Cluster 模式,当使用 Cluster 模式的时候,只能有一个数据库 db 0。slots_to_keys 用于记录 cluster 模式下,存储 key 与哈希槽映射关系的数组。
dict
Redis 使用 dict 结构来保存所有的键值对(key-value)数据,这是一个散列表,所以 key 查询时间复杂度是 O(1) 。
所谓散列表,我们可以类比 Java 中的 HashMap,其实就是一个数组,数组的每个元素叫做哈希桶。
dict 结构体源码在 dict.h 中定义。
struct dict {
dictType *type;
dictEntry **ht_table[2];
unsigned long ht_used[2];
long rehashidx;
int16_t pauserehash;
signed char ht_size_exp[2];
};
dict 的结构体里,有 dictType *type,**ht_table[2],long rehashidx三个很重要的结构。
-
type 存储了 hash 函数,key 和 value 的复制等函数;
-
ht_table[2],长度为 2 的数组,默认使用 ht_table[0] 存储键值对数据。我会使用 ht_table[1] 来配合实现渐进式 reahsh 操作。
-
rehashidx 是一个整数值,用于标记是否正在执行 rehash 操作,-1 表示没有进行 rehash。如果正在执行 rehash,那么其值表示当前 rehash 操作执行的 ht_table[1] 中的 dictEntry 数组的索引。
-
pauserehash 表示 rehash 的状态,大于 0 时表示 rehash 暂停了,小于 0 表示出错了。
-
ht_used[2],长度为 2 的数组,表示每个哈希桶存储了多少个 键值对实体(dictEntry),值越大,哈希冲突的概率越高。
-
ht_size_exp[2],每个散列表的大小,也就是哈希桶个数。
重点关注 ht_table 数组,数组每个位置叫做哈希桶,就是这玩意保存了所有键值对,每个哈希桶的类型是 dictEntry。
❝MySQL:“Redis 支持那么多的数据类型,哈希桶咋保存?”
他的玄机就在 dictEntry 中,每个 dict 有两个 ht_table,用于存储键值对数据和实现渐进式 rehash。
dictEntry 结构如下。
typedef struct dictEntry {
void *key;
union {
// 指向实际 value 的指针
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// 散列表冲突生成的链表
struct dictEntry *next;
void *metadata[];
} dictEntry;
-
*key指向键值对的键的指针,指向一个 sds 对象,key 都是 string 类型。 -
v 是键值对的 value 值,是个 union(联合体),当它的值是 uint64_t、int64_t 或 double 数字类型时,就不再需要额外的存储,这有利于减少内存碎片。(为了节省内存操碎了心)当值为非数字类型,就是用
val指针存储。 -
*next指向另一个 dictEntry 结构, 多个 dictEntry 可以通过 next 指针串连成链表, 从这里可以看出, ht_table 使用链地址法来处理键碰撞:当多个不同的键拥有相同的哈希值时,哈希表用一个链表将这些键连接起来。
哈希桶并没有保存值本身,而是指向具体值的指针,从而实现了哈希桶能存不同数据类型的需求。
redisObject
dictEntry 的 *val 指针指向的值实际上是一个 redisObject 结构体,这是一个非常重要的结构体。
我的 key 只能是字符串类型,而 value 可以是 String、Lists、Set、Sorted Set、散列表等数据类型。
键值对的值都被包装成 redisObject 对象, redisObject 在 server.h 中定义。
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
} robj;
-
type:记录了对象的类型,string、set、hash 、Lis、Sorted Set 等,根据该类型来确定是哪种数据类型,使用什么样的 API 操作。
-
encoding:编码方式,表示 ptr 指向的数据类型具体数据结构,即这个对象使用了什么数据结构作为底层实现保存数据。同一个对象使用不同编码实现内存占用存在明显差异,内部编码对内存优化非常重要。
-
lru:LRU_BITS:LRU 策略下对象最后一次被访问的时间,如果是 LFU 策略,那么低 8 位表示访问频率,高 16 位表示访问时间。
-
refcount :表示引用计数,由于 C 语言并不具备内存回收功能,所以 Redis 在自己的对象系统中添加了这个属性,当一个对象的引用计数为 0 时,则表示该对象已经不被任何对象引用,则可以进行垃圾回收了。
-
ptr 指针:指向对象的底层实现数据结构,指向值的指针。
如图 1-11 是由 redisDb、dict、dictEntry、redisObejct 关系图:
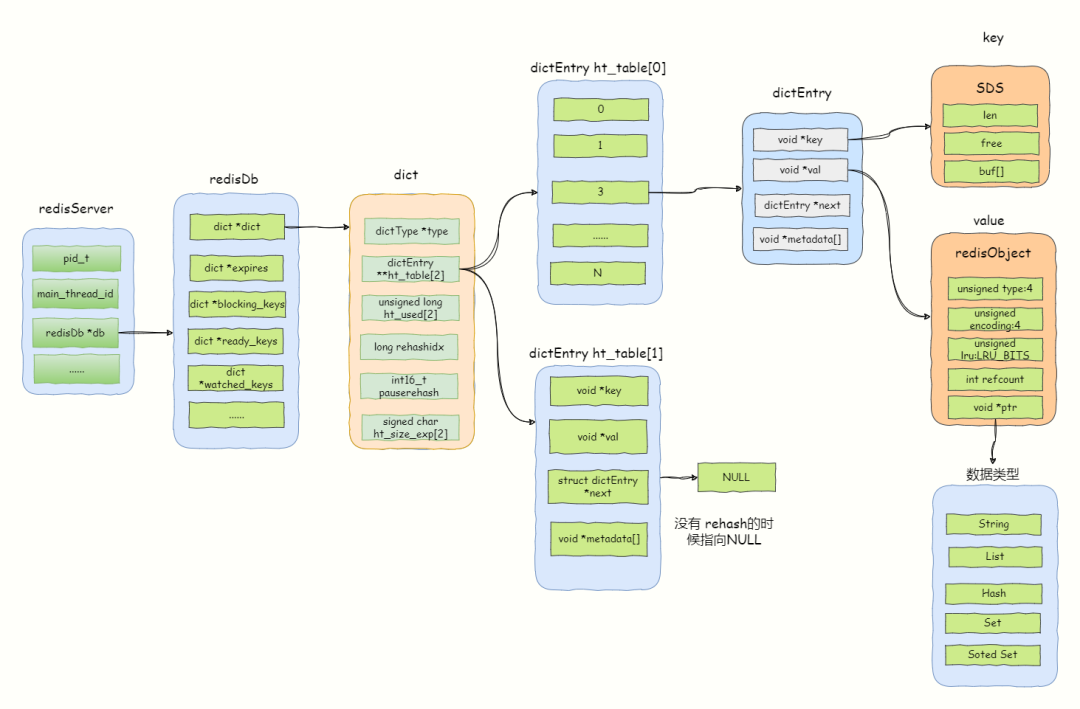
图 1-11
注意,一开始的时候,我只使用 ht_table[0] 这个散列表读写数据,ht_table[1] 指向 NULL,当这个散列表容量不足,触发扩容操作,这时候就会创建一个更大的散列表 ht_table[1]。
接着我会使用渐进式 rehash 的方式将 ht_table[0] 的数据迁移到 ht_table[1] 上,全部迁移完成后,再修改下指针,让 ht_table[0] 指向扩容后的散列表,回收掉原来的散列表,ht_table[1] 再次指向 NULL。