Databend 内幕大揭秘第一弹 - minibend 简介
minibend ,一个从零开始、使用 Rust 构建的查询引擎。这里是 minibend 系列技术主题分享的第一期,来自 @PsiACE 。
前排指路视频和 PPT 地址
视频(哔哩哔哩):https://www.bilibili.com/video/BV1Ne4y1x7Cn
PPT:https://psiace.github.io/databend-internals/minibend/ppt/minibend-001-basic-intro.pdf
minibend: what, why, how
minibend 是什么
minibend 是一款从零开始、使用 Rust 构建的查询引擎。
查询引擎是数据库系统的一个重要组件,需要具备以下几点能力:
- 访问数据
- 提供查询接口
- 返回查询结果
通常我们会使用 SQL 也就是结构化查询语言进行交互。
minibend 同时也是 Databend Internals,或者说 Databend 内幕大揭秘 这个手册的实战部分。Databend 内幕大揭秘 将会透过 Databend 的设计与实现,为你揭开面向云架构的现代数据库的面纱。
为什么要设计 minibend

特别是在团队已经孵化出 Databend 这个现代开源云数仓的前提下,为什么还需要这样一个项目?
先回到 Databend 内幕大揭秘 的初衷,设立这个项目是为了吸引更多人参与到 Databend 的学习、开发和生态建设中,所以目标受众定位在:
- 高校计算机专业的学生。
- 想从事数据库研发的开发者。
- 对数据库整体运作原理感兴趣的朋友。
但是,Databend 的更新迭代速度、代码量都意味着对刚开始接触 Rust 并尝试参与研发的新朋友会面临一个比较高的门槛。
从现存的教程上看,或多或少存在一些问题:
- 不是 Rust 实现(切换语言和生态需要一些努力)
- 缺乏 step by step 的体验(细节上需要更深入和艰苦的挖掘)
- 从设计思想到实现逻辑上可能与 Databend 有比较明显的差异(存算分离、面向云,这些可能都会有一些抉择)。
所以开启一个新的项目作为连接新开发者和 Databend 之间的纽带就成为一种自然的选择。
P.S. minibend 致力于解决这些问题,但可能很难完全解决,但至少,先开始运作起来。
minibend 这个项目计划怎样进行
首先,minibend 会提供视频、文章和代码三种材料。文章和代码将会同步到 Databend 内幕大揭秘 的 Repo 中,而视频则会发布到 Databend 的 B 站官方帐号下。欢迎大家持续关注。
Databend 内幕大揭秘:https://psiace.github.io/databend-internals/
Databend(哔哩哔哩):https://space.bilibili.com/275673537
更新频率大概是每个月一到两期。内容上会包含必要的相关知识导读、设计和实现相关的说明、并进行回顾和展望。当然,也会不定期精选一部分论文摘要供大家进一步研讨和学习。
数据库基础概念
在这个部分,我们不会深入数据库的细节,只是从部分组件的视角上进行观察。
存储
存储解决的是两个问题,存在哪 以及 怎么存 。
对于“怎么存”,不同背景的朋友可能会考虑到一些不同的细节,但大多数时候,可以想象到一个基本的模式是:数据以特定格式写入到某几类文件中,比如 Parquet 甚至 CSV 。
但是“存在哪”呢?
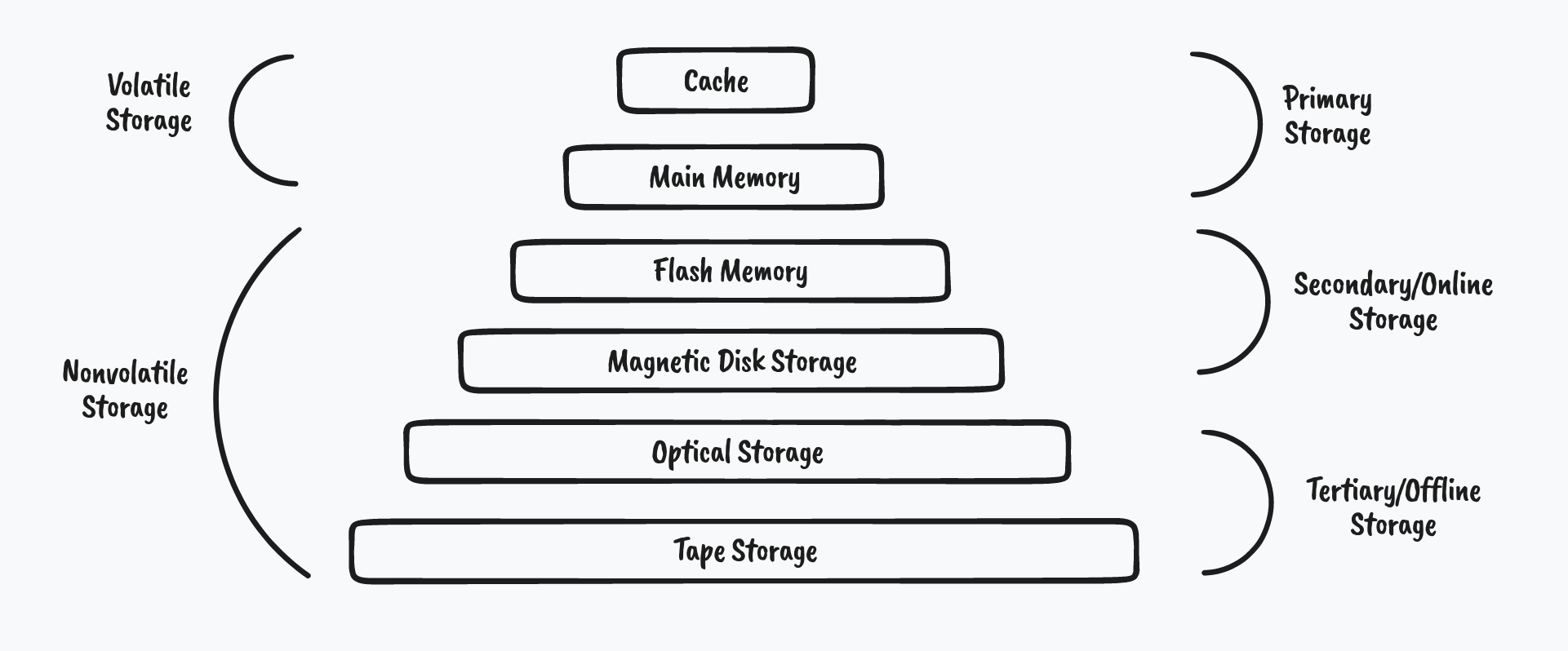
过去的一些存储方案更加关注上图所示的存储体系结构,将需要在线处理的数据存放在闪存和硬盘中,用于备份的数据放入光盘和磁带。
云存储的兴起和网络带宽的不断提高带来了一些新的变化:云存储能够支持远程保存数据和文件,并通过网络连接进行访问。不仅可以节约拓展物理器件所带来的人力物力消耗,并能够提供更好的弹性以便于即时增减容量,还支持按需按量付费从而做到更好的成本管理与控制。
Databend 早期的实现是包含一套分布式文件系统的,但到现在,存储的重心完全转移到云厂商提供(AWS S3, Azure Blob 等)或者自托管(MinIO 等)的云存储之上。
尽管云存储越来越重要,但原有的经验和见解依然有效,我们仍然可以使用缓存和并行技术来改善性能,利用冗余来提高可靠性。
索引
引入索引的好处在于加快数据查询的速度,而缺点则在于构建和维护索引同样需要付出代价。
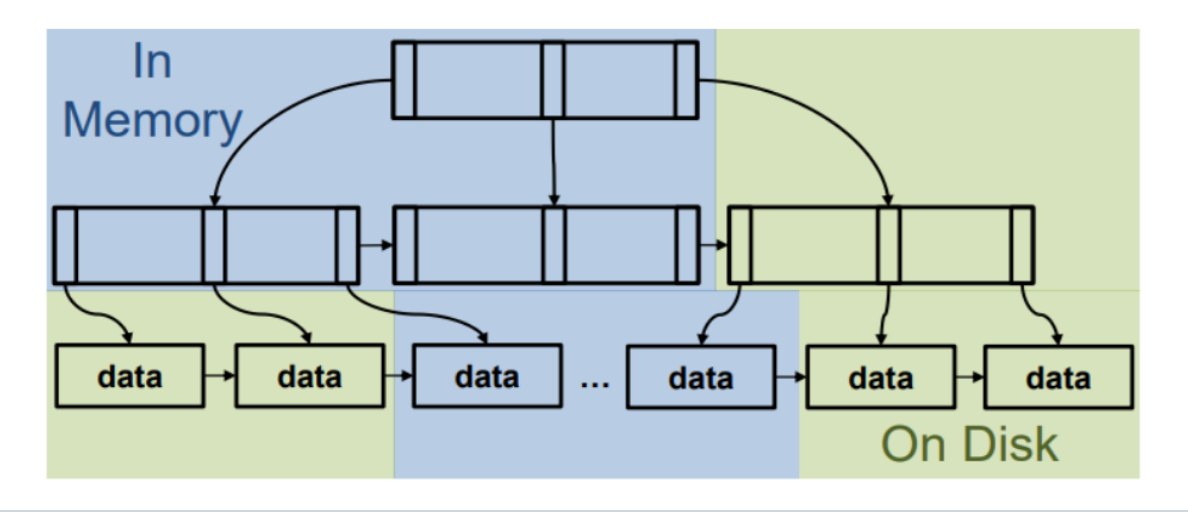
不同的索引可以针对不同的场景提供优化,B Tree 能够加速范围查询,而等值查询就可以使用 Hash 索引,BitMap(或者说更常用的 Bloom 索引)可以方便判断数据是否存在。
Databend 的索引无需人为创建,由部署的实例自行维护。同时也采用了像 Xor 索引 这样的新技术来进一步加速查询并提高空间利用率。
查询执行
尽管有各种各样的查询引擎,但具体到查询执行的环节大同小异,这里以 Databend 为例,简单讲一下过程。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Uz4mJ9E8-1673837073166)(https://psiace.github.io/databend-internals/the-basics/executor-in-query-process/01-query-steps.png)]
- 解析 SQL 语法,形成 AST(抽象语法树)。
- 通过 Binder 对其进行语义分析,并且生成一个初始的 Logical Plan(逻辑计划)。
- 得到初始的 Logical Plan 后,优化器会对其进行改写和优化,最终生成一个可执行的 Physical Plan 。
- 通过 Optimizer 生成 Physical Plan 后,将其翻译成可执行的 Pipeline 。
- Pipeline 则会交由 Processor 执行框架进行计算。
那么近年来新兴数据库大多受到 Morsel-Driven Parallelism 这篇论文的启发,在运行时确定任务的并行度,按流水线的方式执行操作,并通过调度策略来尽量保证数据的本地化,在实现 load banlance 的同时最小化跨域数据访问。
同时,引入列式存储和向量化执行的技术,可以避免不必要的缓存和 I/O 资源浪费,同时,节约处理数据时需要传递的数据量,为进一步优化提供更多空间。
查询优化
查询执行的路径并非一成不变,不同的执行计划在不同场景下性能也存在差异,如何为查询选择合适的计划就是查询优化需要关注的内容。
- 更快的速度(更低的延迟)。
- 在 OLTP 场景下,则更强调性价比。
- 而对于 OLAP 场景,则追求更的高吞吐量。
下面的图片展现的是一种典型的查询优化,对 JOIN 进行重排。
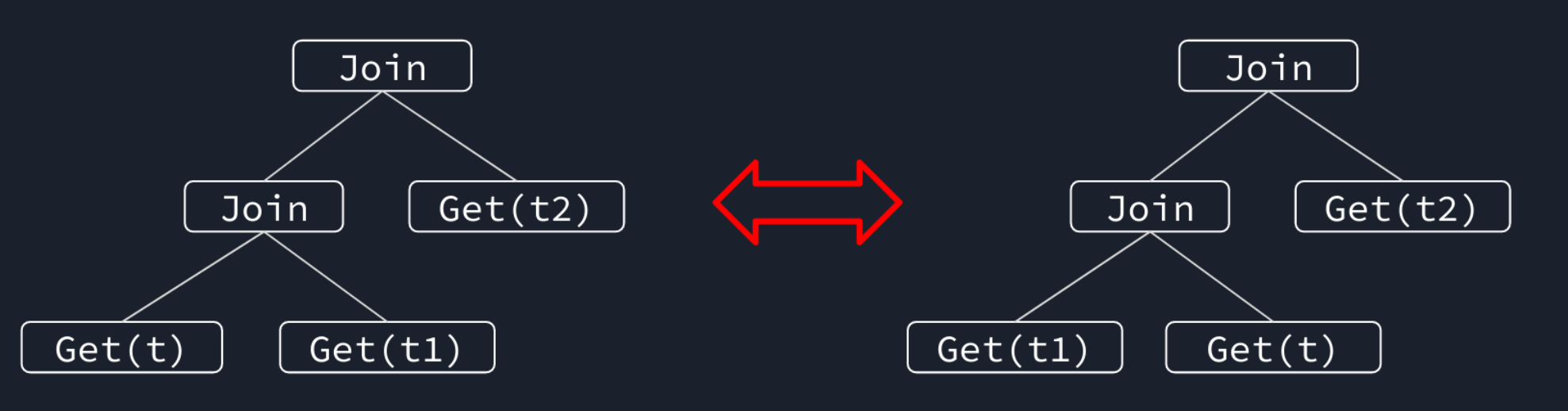
目前有两种主要的查询优化方案,一种是基于关系代数和算法的等价优化方案,一种是基于评估成本的优化方案。根据命名,不难看出优化的灵感来源和这两种方案在优化上的取舍。
那么如何进行查询优化呢?查询优化通常包含以下四个步骤:
- 构建框架来列举可能的计划
- 编写转换规则
- 引入成本模型来评估不同的计划
- 选择最理想的计划
Databend 引入了基于规则的 Cascades 优化器,通过自顶向下探索、模式匹配以及记忆化来提供更好的查询优化能力。
大规模并行处理
大规模并行处理是大数据计算引擎的一个重要特性,可以提供高吞吐、低时延的计算能力。那么,当我们在讨论大规模并行处理时,究竟在讨论什么?

大规模并行处理(MPP,Massively Parallel Processing)意味着可以由多个计算节点(处理器)协同处理程序的不同部分,而每个计算节点都可能具备独立的系统资源(磁盘、内存、操作系统)。
计算节点将工作拆分成易于管理、调度和执行的任务执行,通过添加额外的计算节点可以完成水平拓展。随着计算节点数目的增加,对数据的查询处理速度就越快,从而减少大数据集上处理复杂查询所需的时间。
在近些年,MPP 和分布式设计往往会同时出现在同一套系统中。
分布式

从某种视角上看,分布式系统与 MPP 系统有着惊人的相似。比如:通过网络连接、对外作为整体提供服务、计算节点拥有资源等。但是这两种架构仍然会有一些不同。
- 从设计目标上看,分布式系统致力于改善系统的可靠性和可用性,而 MPP 系统需要充分利用计算节点的并行能力从而提高整体性能。
- 具体到实现上,分布式系统降低了对网络的需求,采用局域网或广域网相连,拓展性进一步增强。而 MPP 系统为了充分利用计算节点的处理能力,依赖高速网络进行通讯。
- 同时,由于节点地位不同,分布式系统除了协同执行任务之外,还具有自治执行任务的能力;而 MPP 系统则专注于任务的协同执行。
Rust 不完全指南
刚刚介绍了数据库相关的一些基本概念,现在让我们将目光转向 Rust ,来一同了解这个正在走向流行的编程语言。
The Rust Programming Language

Rust 官方宣传语是:Rust 是一门赋予每个人构建可靠且高效软件能力的语言,现在距离它第一个版本发布也已经过去10年。
Rust 没有运行时和垃圾回收,速度快且内存利用率高,几乎可以与 C 和 C++ 竞争。
Rust 的类型系统和所有权模型为内存安全和线程安全提供保障,在编译期就能够消除各种各样的错误。
特别值得一提的是,Rust 工具链内置很多实用工具,可以切实改善生产力:包管理器、构建工具、格式化程序、用于代码审计的 Clippy 等等。
函数
#[allow(dead_code)]
// Functions
// `i32` is the type for 32-bit signed integers
fn add2(x: i32, y: i32) -> i32 {
// Implicit return (no semicolon)
x + y
}
上面函数是两个 32 位整数相加,返回值也是一个 32 位整数。值得注意的是,我们需要标注返回值类型,而函数体中的 x + y 是一种隐式返回,所以不需要添加 return 关键字,当然,也不需要在末尾添加分号。只添加末尾分号的话,则会将其视为普通语句执行,就没有返回值了(报错)。
// This is the main function
fn main() {
// Statements here are executed when the compiled binary is called
// Print text to the console
println!("Hello World!");
}
经典的 Hello World 程序,大家应该会感觉到熟悉。main 函数也是 Rust 程序的入口点。通过调用 println! 这个宏,可以输出文本到终端。
类型
// Struct
struct Point {
x: i32,
y: i32,
}
// A struct with unnamed fields, called a ‘tuple struct’
struct Point2(i32, i32);
// Enum with fields
enum OptionalI32 {
AnI32(i32),
Nothing,
}
// Generics //
struct Foo<T> { bar: T }
// Traits (known as interfaces or typeclasses in other languages) //
trait Frobnicate<T> {
fn frobnicate(self) -> Option<T>;
}
impl<T> Frobnicate<T> for Foo<T> {
fn frobnicate(self) -> Option<T> {
Some(self.bar)
}
}
除了基本的字符串、整数、浮点数、布尔类型之外,Rust 还支持结构体和枚举类型,代码片段提供了一个基本的例子。为这些类型可以实现特定的方法,以支持各种各样的操作,通用的接口可以使用 trait 关键字进行定义。
模式匹配
let foo = OptionalI32::AnI32(1);
match foo {
OptionalI32::AnI32(n) => println!("it’s an i32: {}", n),
OptionalI32::Nothing => println!("it’s nothing!"),
}
// Advanced pattern matching
struct FooBar { x: i32, y: OptionalI32 }
let bar = FooBar { x: 15, y: OptionalI32::AnI32(32) };
match bar {
FooBar { x: 0, y: OptionalI32::AnI32(0) } =>
println!("The numbers are zero!"),
FooBar { x: n, y: OptionalI32::AnI32(m) } if n == m =>
println!("The numbers are the same"),
FooBar { x: n, y: OptionalI32::AnI32(m) } =>
println!("Different numbers: {} {}", n, m),
FooBar { x: _, y: OptionalI32::Nothing } =>
println!("The second number is Nothing!"),
}
模式是 Rust 中特殊的语法,它用来匹配类型中的结构,看起来有点像 switch,但要更加强大和简洁。无论类型是简单还是复杂,结合使用模式和 match 表达式以及其他结构可以提供更多对程序控制流的支配权。通过将一些值与模式相比较来使用它。如果模式匹配这些值,就可以对值的部分进行相应处理。
控制流
// for and ranges
for i in 0u32..10 {
print!("{} ", i);
}
println!("");
// prints `0 1 2 3 4 5 6 7 8 9 `
// `if` as expression
let value = if true {
"good"
} else {
"bad"
};
// `while` loop
while 1 == 1 {
println!("The universe is operating normally.");
// break statement gets out of the while loop.
// It avoids useless iterations.
break
}
// Infinite loop
loop {
println!("Hello!");
// break statement gets out of the loop
break
}
上面是一些常见的控制流语法,for 循环和范围迭代看起来和其他语言很相似;而通过 let - if 语句,可以轻松将 if 当作表达式来使用;当然,Rust 同样支持 while 循环和无限 loop 循环。
内存安全与指针
// Owned pointer – only one thing can ‘own’ this pointer at a time
// This means that when the `Box` leaves its scope, it can be automatically deallocated safely.
let mut mine: Box<i32> = Box::new(3);
*mine = 5; // dereference
// Here, `now_its_mine` takes ownership of `mine`. In other words, `mine` is moved.
let mut now_its_mine = mine;
*now_its_mine += 2;
println!("{}", now_its_mine); // 7
// println!("{}", mine); // this would not compile because `now_its_mine` now owns the pointer
Owned Pointer,一次只能有一个对象“拥有”此指针,这意味着当 Box 离开其作用域时,它可以安全地自动释放。
// Reference – an immutable pointer that refers to other data
// When a reference is taken to a value, we say that the value has been ‘borrowed’.
// While a value is borrowed immutably, it cannot be mutated or moved.
// A borrow is active until the last use of the borrowing variable.
let mut var = 4;
var = 3;
let ref_var: &i32 = &var;
println!("{}", var); // Unlike `mine`, `var` can still be used
println!("{}", *ref_var);
// var = 5; // this would not compile because `var` is borrowed
// *ref_var = 6; // this would not either, because `ref_var` is an immutable reference
ref_var; // no-op, but counts as a use and keeps the borrow active
var = 2; // ref_var is no longer used after the line above, so the borrow has ended
Reference – 引用其他数据的不可变指针。当引用某个值时,我们称该值已被 “借用” 。当一个值被不可变借用时,它不能被修改或移动。借用直到在最后一次使用借用变量之前会一直处于活跃状态。
// Mutable reference
// While a value is mutably borrowed, it cannot be accessed at all.
let mut var2 = 4;
let ref_var2: &mut i32 = &mut var2;
*ref_var2 += 2; // '*' is used to point to the mutably borrowed var2
println!("{}", *ref_var2); // 6 , // var2 would not compile.
// ref_var2 is of type &mut i32, so stores a reference to an i32, not the value.
// var2 = 2; // this would not compile because `var2` is borrowed.
ref_var2; // no-op, but counts as a use and keeps the borrow active until here
可变引用,如果你有一个对该变量的可变引用,你就不能再创建对该变量的引用。
上面的这些 Rust 片段节选自 Learn X in Y minutes ,只进行了一些粗浅的介绍。
如果想要进一步学习,建议查阅以下资料:
- The Rust Programming Language 。
- Databend 早期关于 Rust 的系列视频。
- Rust 新手入门系列课程
- Rust 培养提高计划
前进四:回顾与展望
回顾
首先我们介绍了 minibend 这个系列课程,一方面,这会是一个从零开始、使用 Rust 构建的查询引擎;另一方面,它会参考 Databend 的设计,并致力于降低数据库内核开发的门槛。
而在数据库相关基础知识的部分,云存储为现代数据库设计带来了一些新变化,而不同的索引又可以为不同的查询场景带来性能优化,接着是查询执行和查询优化的相关知识,以及对大规模并行处理和分布式技术的介绍。
Rust 不完全指南里,从函数、类型、模式匹配、控制流、内存安全与指针进行了一个简单的介绍,为阅读 Rust 代码提供了一个简单的基础。
展望
下一期,我们将会介绍 Apache Arrow - 一种列式存储的内存格式规范,以及查询引擎中的类型系统,然后试着写一些关于数据源的代码。
阅读材料
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kS6TBWLI-1673837073168)(https://psiace.github.io/databend-internals/minibend/001-basic-intro/minibend-001-basic-intro_22.png)]
本期课程推荐两本书给大家:
一本是 The Rust Programming Language ,这是 rust 官方出品的 Rust 书籍,一般被称作 the book 。
另一本是 How Query Engines Work ,Andy 同时也是 Datafusion 和 Ballista 的作者,不过这本书使用的是 kotlin 。