Python爬虫教你爬取csdn作者排行榜
(一)两种爬取方式介绍
1.自动化测试工具
安装好驱动(以前的selenium文章有教程),然后进行元素定位,最后数据提取,用xls表格进行持久化存储
2.requests库
利用基本方法发起请求,获得json数据进行持久化存储
本篇文章先讲解第二种,后续出第一种方法
(二)代码及思路分享
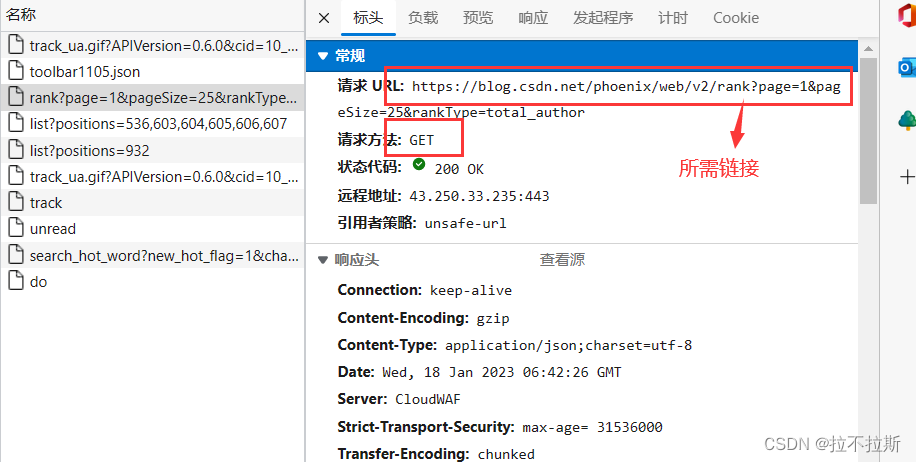
1.获取请求链接
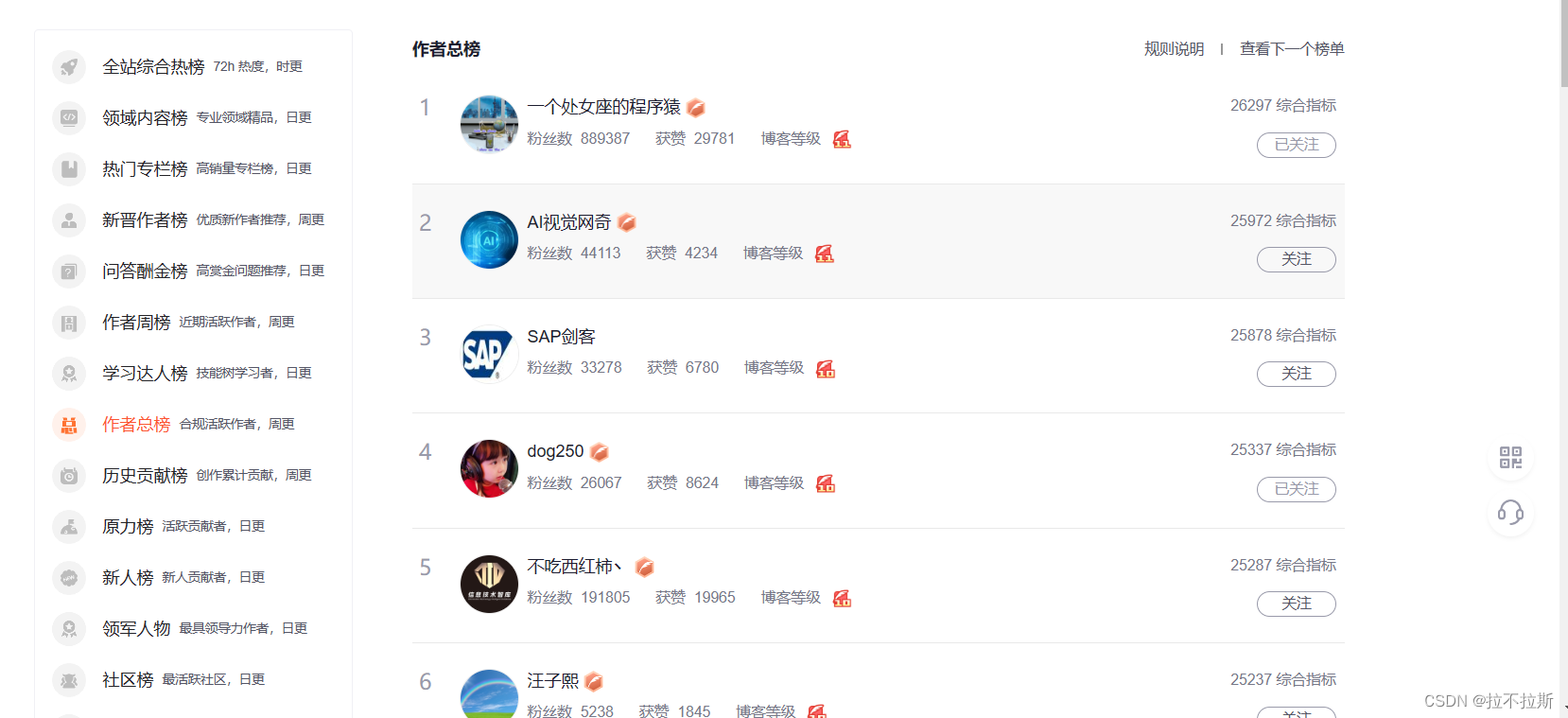
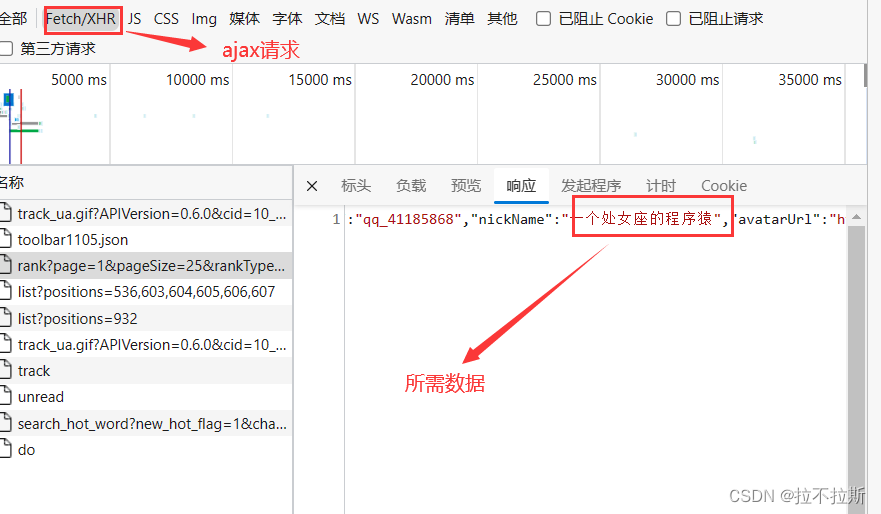
对比网页源代码及网页数据,发现源代码中不含所需数据,因此利用抓包工具获取ajax请求进行链接获取
抓包工具获取链接
2.分析参数
链接:https://blog.csdn.net/phoenix/web/blog/allRank?page=1&pageSize=20
参数page为第几页
参数pageSize为一页展示的个数
两个参数都可以手动传入
3.效果展示(部分数据):
4.全部代码:
import requests
from bs4 import BeautifulSoup
from lxml import etree
import xlwt
import csv
headers={
"user-agent":"chrom/10"
}
List=[]
data0=["用户名","粉丝数","获赞数","博客等级","综合指标"]
List.append(data0)
for i in range(0,5):
url = f"https://blog.csdn.net/phoenix/web/blog/allRank?page={i}&pageSize=20"
r=requests.get(url=url,headers=headers,timeout=100)
r.encoding="utf-8"
if(r.status_code==200):
t=r.json()
for j in range(0,20):
data=[]
data.append(t["data"]["allRankListItem"][j]["nickName"])
data.append(t["data"]["allRankListItem"][j]["fansCount"])
data.append(t["data"]["allRankListItem"][j]["diggCount"])
data.append(t["data"]["allRankListItem"][j]["level"])
data.append(t["data"]["allRankListItem"][j]["hotRankScore"])
List.append(data)
writer=xlwt.Workbook()
sheet=writer.add_sheet("sheet01")
for m in range(len(List)):
for n in range(len(List[0])):
sheet.write(m,n,List[m][n])
writer.save("博客排行榜.xls")
r.close()