【学习笔记】《Python深度学习》第一章:什么是深度学习
文章目录
- 1 人工智能、机器学习与深度学习
- 1.1 人工智能
- 1.2 机器学习
- 1.3 从数据中学习表示
- 1.4 深度学习之“深度”
- 1.5 用三张图理解深度学习的工作原理
- 2 机器学习简史
- 2.1 概率建模
- 2.2 早期神经网络
- 2.3 核方法
- 2.4 决策树、随机森林与梯度提升机
- 2.5 回到神经网络
- 2.6 深度学习的不同
1 人工智能、机器学习与深度学习
1.1 人工智能
人工智能:努力将通常由人类完成的智力任务自动化。
符号主义人工智能:程序员编写足够多的明确规则来处理知识,就可以实现与人类水平相当的人工智能。
1.2 机器学习
1.定义:利用输入数据和从这些数据中预期得到的答案,经过训练后输出规则。
2.机器学习的三要素:
- 输入数据点
- 预期输出的示例
- 衡量算法效果好坏的方法
3.机器学习的技术定义:在预先定义好的可能性空间中,利用反馈信号的指引来寻找输入数据的有用表示。
1.3 从数据中学习表示
1.表示:以不同的方式来查看数据(即表征数据或将数据编码),让数据更接近预期输出。
例如,彩色图像可以编码为RGB格式,也可以编码成HSV格式。
2.机器学习的学习指的是,寻找更好数据表示的自动搜索过程。
机器学习在寻找变换的时候,仅仅是遍历一组预先定义好的操作,这组操作叫做假设空间。
1.4 深度学习之“深度”
1.深度:指一系列连续的表示层,它们通过神经网络从训练数据中自动学习。
2.深度学习的技术定义:学习数据表示的多级方法。
1.5 用三张图理解深度学习的工作原理
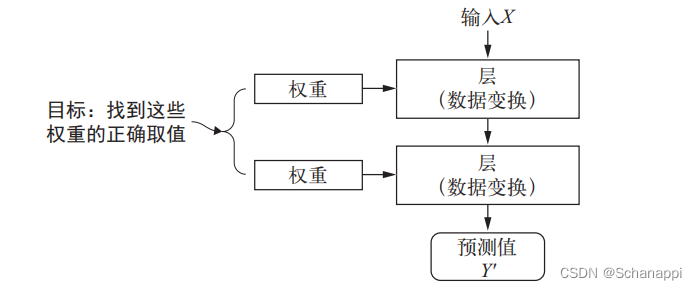
1.权重/参数:保存神经网络每层对输入数据所作的具体操作。
每层实现的变化都由权重来参数化。
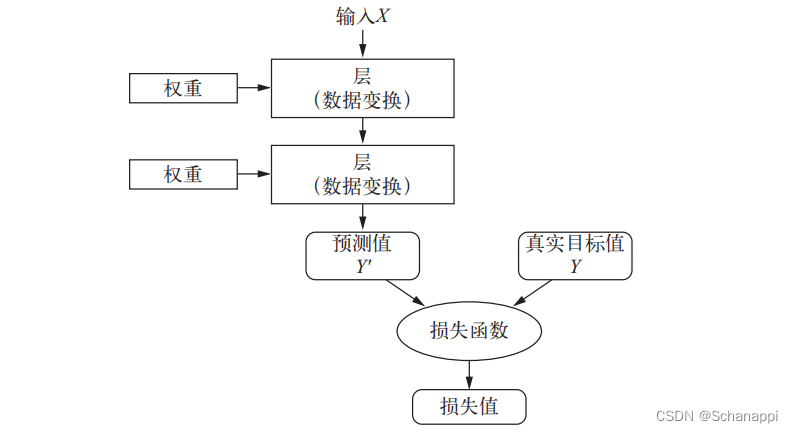
2.损失函数/目标函数:通过网络预测值与真实目标值计算得到一个距离值,衡量神经网络的效果。
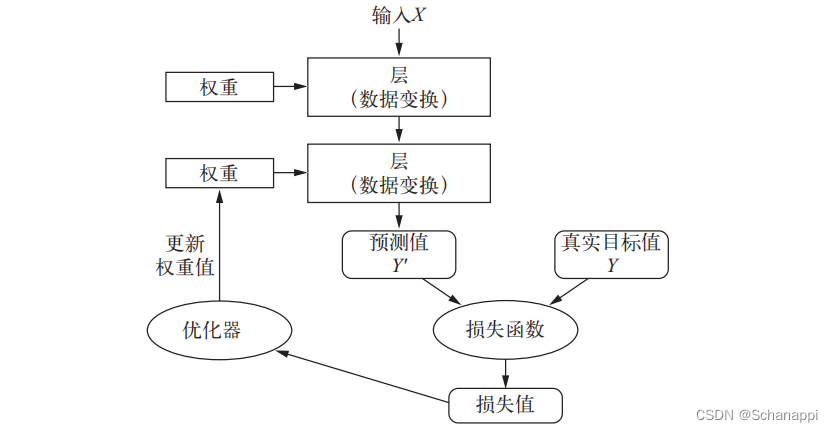
3.优化器:利用损失函数计算的距离值作为反馈信号,对权重值进行微调,实现反向传播。
2 机器学习简史
2.1 概率建模
-
朴素贝叶斯算法
朴素贝叶斯是一类基于应用贝叶斯定理的机器学习分类器,假设输入数据的特征都是独立的。 -
logistic回归(简称logreg),一种分类算法。
2.2 早期神经网络
- 贝尔实验室于1989年第一次成功实现了神经网络的实践应用,当时Yann LeCun将卷积神经网络的早期思想与反向传播算法相结合,并将其应用于手写数字分类问题,由此得到名为LeNet的网络。
2.3 核方法
核方法是一组分类算法,其中最有名的是支持向量机(SVM)。
- 支持向量机
1.目标:在属于两个不同类别的两组数据点之间找到良好决策边界。
2.实现:
(1)将数据映射到一个新的高维表示;
(2)让超平面与每个类别最近的数据点之间的距离最大化,从而计算出良好的决策边界。
3.核技巧思想:只需要在新空间中利用核函数计算点对之间的距离,就可以在新空间中找到良好的决策超平面。
4.优点:SVM刚刚出现的时候,在简单分类问题上表现出了最好的性能,并且得到了理论支持,适用于严肃的数学分析。
5.缺点:很难扩展到大型数据集,并且在图像分类等感知问题上的效果也不好。
2.4 决策树、随机森林与梯度提升机
-
决策树,类似于流程图。
-
随机森林,构建许多决策树,将它们的输出集成到一起。
-
梯度提升机,使用了梯度提升方法,通过迭代训练新模型来专门解决之前模型的弱点,改进任何机器学习模型的效果。
2.5 回到神经网络
- 深度卷积神经网络,已经成为所有计算机视觉任务的首选算法,在所有感知任务上都有效。
2.6 深度学习的不同
深度学习将特征工程自动化。